CPU,一般認為寫C/C++的才需要了解,寫高級語言的(Java/C#/pathon…)並不需要了解那麼底層的東西。我一開始也是這麼想的,但直到碰到LMAX的Disruptor,以及馬丁的博文,才發現寫Java的,更加不能忽視CPU。經過一段時間的閱讀,希望總結一下自己的閱讀後的感悟。本文主要談談CPU緩存對Java編程的影響,不涉及具體CPU緩存的機制和實現。
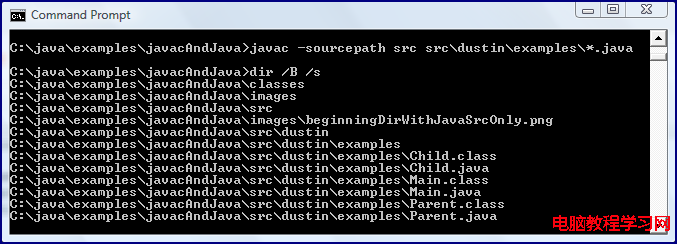
現代CPU的緩存結構一般分三層,L1,L2和L3。如下圖所示:

級別越小的緩存,越接近CPU, 意味著速度越快且容量越少。
L1是最接近CPU的,它容量最小,速度最快,每個核上都有一個L1 Cache(准確地說每個核上有兩個L1 Cache, 一個存數據 L1d Cache, 一個存指令 L1i Cache);
L2 Cache 更大一些,例如256K,速度要慢一些,一般情況下每個核上都有一個獨立的L2 Cache;
L3 Cache是三級緩存中最大的一級,例如12MB,同時也是最慢的一級,在同一個CPU插槽之間的核共享一個L3 Cache。
當CPU運作時,它首先去L1尋找它所需要的數據,然後去L2,然後去L3。如果三級緩存都沒找到它需要的數據,則從內存裡獲取數據。尋找的路徑越長,耗時越長。所以如果要非常頻繁的獲取某些數據,保證這些數據在L1緩存裡。這樣速度將非常快。下表表示了CPU到各緩存和內存之間的大概速度:
從CPU到 大約需要的CPU周期 大約需要的時間(單位ns)
寄存器 1 cycle
L1 Cache ~3-4 cycles ~0.5-1 ns
L2 Cache ~10-20 cycles ~3-7 ns
L3 Cache ~40-45 cycles ~15 ns
跨槽傳輸 ~20 ns
內存 ~120-240 cycles ~60-120ns
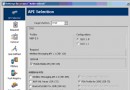
利用CPU-Z可以查看CPU緩存的信息:

在linux下可以使用下列命令查看proc文件系統或者sys下的設備描述。
有了上面對CPU的大概了解,我們來看看緩存行(Cache line)。緩存,是由緩存行組成的。一般一行緩存行有64字節(由上圖”64-byte line size”可知)。所以使用緩存時,並不是一個一個字節使用,而是一行緩存行、一行緩存行這樣使用;換句話說,CPU存取緩存都是按照一行,為最小單位操作的。
這意味著,如果沒有好好利用緩存行的話,程序可能會遇到性能的問題。可看下面的程序:
public class L1CacheMiss {
private static final int RUNS = 10;
private static final int DIMENSION_1 = 1024 * 1024;
private static final int DIMENSION_2 = 6;
private static long[][] longs;
public static void main(String[] args) throws Exception {
Thread.sleep(10000);
longs = new long[DIMENSION_1][];
for (int i = 0; i < DIMENSION_1; i++) {
longs[i] = new long[DIMENSION_2];
for (int j = 0; j < DIMENSION_2; j++) {
longs[i][j] = 0L;
}
}
System.out.println("starting....");
long sum = 0L;
for (int r = 0; r < RUNS; r++) {
final long start = System.nanoTime();
//slow
// for (int j = 0; j < DIMENSION_2; j++) {
// for (int i = 0; i < DIMENSION_1; i++) {
// sum += longs[i][j];
// }
// }
//fast
for (int i = 0; i < DIMENSION_1; i++) {
for (int j = 0; j < DIMENSION_2; j++) {
sum += longs[i][j];
}
}
System.out.println((System.nanoTime() - start));
}
}
}
以我所使用的Xeon E3 CPU和64位操作系統和64位JVM為例,如這裡所說,假設編譯器采用行主序存儲數組。
64位系統,Java數組對象頭固定占16字節(未證實),而long類型占8個字節。所以16+8*6=64字節,剛好等於一條緩存行的長度:

如32-36行代碼所示,每次開始內循環時,從內存抓取的數據塊實際上覆蓋了longs[i][0]到longs[i][5]的全部數據(剛好64字節)。因此,內循環時所有的數據都在L1緩存可以命中,遍歷將非常快。
假如,將32-36行代碼注釋而用25-29行代碼代替,那麼將會造成大量的緩存失效。因為每次從內存抓取的都是同行不同列的數據塊(如longs[i][0]到longs[i][5]的全部數據),但循環下一個的目標,卻是同列不同行(如longs[0][0]下一個是longs[1][0],造成了longs[0][1]-longs[0][5]無法重復利用)。運行時間的差距如下圖,單位是微秒(us):

最後,我們都希望需要的數據都在L1緩存裡,但事實上經常事與願違,所以緩存失效 (Cache Miss)是常有的事,也是我們需要避免的事。
一般來說,緩存失效有三種情況:
1. 第一次訪問數據, 在cache中根本不存在這條數據, 所以cache miss, 可以通過prefetch解決。
2. cache沖突, 需要通過補齊來解決(偽共享的產生)。
3. cache滿, 一般情況下我們需要減少操作的數據大小, 盡量按數據的物理順序訪問數據