在上篇博文《Web版RSS閱讀器(三)——解析在線Rss訂閱》中,已經提到了遇到的問題,這裡再詳細說一下。
在解析rss格式的訂閱時,遇到的最主要的問題是,出現了“Server returned HTTP response code: 403 for URL: http://xxxxxx”的錯誤,百度一下就知道,這是在網站訪問中很常見的一個錯誤,服務器理解客戶的請求,但拒絕處理它。即拒絕訪問!接著查資料,得知某些服務器(比如CSDN博客)拒絕java作為客戶端進行對其的訪問,所以在解析時,會拋異常。
不讓訪問怎麼辦,別怕,我們上有政策,下有對策。通過設置User-Agent來欺騙服務器,從而訪問服務器。
connection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)"); //用UA偽裝訪問連接對象
但是折騰了半天,發現只有修改rsslib4j.jar才能給連接對象設置UA。只好找源碼修改一下了,N久之後,在Google Code上獵取到一個開源的項目newrsslib4j,它是在rsslib4j的基礎上修改而來的,項目開源主頁:http://code.google.com/p/newrsslib4j/。滿懷欣喜的下載下來,結果發現,依舊有403的問題。一狠心,自己來做一個rsslib,然後就checkout了newrsslib4j的源碼,自己動手改動。
1. 修改403 forbidden問題。
修改org.gnu.stealthp.rsslib包中的RssParser類的setXmlResource()方法,給URLConnection對象,添加UA。
/**
* Set rss resource by URL
* @param ur the remote url
* @throws RSSException
*/
public void setXmlResource(URL ur) throws RSSException{
try{
URLConnection con = u.openConnection();
//-----------------------------
//添加時間:2013-08-14 21:00:17
//人員:@龍軒
//博客:http://blog.csdn.net/xiaoxian8023
//添加內容:由於服務器屏蔽java作為客戶端訪問rss,所以設置User-Agent
con.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
//-----------------------------
con.setReadTimeout(10000);
String charset = Charset.guess(ur);
is = new InputSource (new UnicodeReader(con.getInputStream(),charset));
if (con.getContentLength() == -1 && is == null){
this.fixZeroLength();
}
}catch(IOException e){
throw new RSSException("RSSParser::setXmlResource fails: "+e.getMessage());
}
}
修改org.mozilla.intl.chardet包中的Charset類的guess()方法,注釋掉原來的InputStream對象,創建URLConnection,設置User-Agent,通過URLConnection對象創建InputStream :
//judge from url
public static String guess(URL url) throws IOException {
//-----------------------------
//修改時間:2013-08-14 21:00:17
//人員:@龍軒
//博客:http://blog.csdn.net/xiaoxian8023
//修改內容:注釋InputStream,創建URLConnection,設置User-Agent,通過URLConnection對象創建InputStream
//InputStream in = url.openStream();
URLConnection con = url.openConnection();
con.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
InputStream in = con.getInputStream();
//-----------------------------
return guess(in);
}
2. 添加獲取文章摘要的方法
測試以後,發現Rss格式的訂閱,居然沒有提供一個獲取內容摘要的方法。所以,繼續修改。修改org.gnu.stealthp.rsslib包中的RssObject類,添加一個getSummary()方法,用來獲取內容摘要:
//-----------------------------------
//添加時間:2013-08-14 19:32:15
//人員:@龍軒
//添加內容:添加getSummary()方法,返回文章摘要信息
/**
* Get the element's summary
* @return the summary
*/
public String getSummary(){
String summary = getDescription();
if (summary.length() >= 300) {
summary = summary.substring(0, 300);
}
String regEx_html = "\\s|<[^>]+>|&\\w{1,5};"; // 定義HTML標簽和特殊字符的正則表達式
Pattern pattern = Pattern.compile(regEx_html,Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(summary);
summary = matcher.replaceAll(""); // 過濾script標簽
if (summary.length() >= 100) {
summary = summary.substring(0, 100);
}
summary = summary + "...";
return summary;
}
//添加結束-----------------------------------------------
3. 解決解析不完全問題
網易博客可以很好的解析出博客的link,language等節點,但是csdn、某些新聞資訊網站則不行。花了很長的時間去找問題,終於在不經意間,發現網易的博客節點的排列順序與別的不一樣,link,language等節點排在image節點上面的,而csdn則是在image的下面(如圖),程序在解析時,先解析channel下的節點,寫入到channel中,讀取到image,則標記解析channel的變量為false,然後開始解析image節點下的內容。解析完畢以後,又要去解析channel節點下的link時,channel標記已經為false了,不能再繼續解析,所以總是返回null。
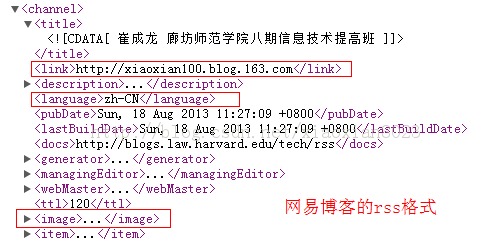
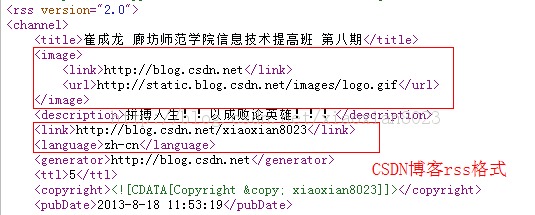
修改方案也很簡單,就是所有標記解析channel為false的節點,在解析完畢該節點後,重新標記解析channel為true,這樣就可以繼續解析channel節點下的其他值 。具體修改操作:查看org.gnu.stealthp.rsslib包的RSSHandler類的startElement()方法,看看誰執行了 reading_chan = false; 這句代碼。然後在endElement()方法中,重新設置 reading_chan = true; 即可:
/**
* Receive notification of the end of an element
* @param uri The Namespace URI, or the empty string if the element has no Namespace URI or if Namespace processing is not being performed.
* @param localName The local name (without prefix), or the empty string if Namespace processing is not being performed
* @param qName The qualified name (with prefix), or the empty string if qualified names are not available
*/
public void endElement(String uri,
String localName,
String qName){
String data = buff.toString().trim();
if (qName.equals(current_tag)){
data = buff.toString().trim();
buff = new StringBuffer();
}
if (reading_chan)
processChannel(qName,data);
if (reading_item)
processItem(qName,data);
if (reading_image)
processImage(qName,data);
if (reading_input)
processTextInput(qName,data);
if (tagIsEqual(qName,CHANNEL_TAG)){
reading_chan = false;
chan.setSyndicationModule(sy);
}
if (tagIsEqual(qName,ITEM_TAG)){
reading_item = false;
//-----------------------------------------
//
至此,修改的就差不多了,打開一下org.javali.util.test包的RssNewsFetcher類,修改一下測試列表和方法:
package org.javali.util.test;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import org.gnu.stealthp.rsslib.RSSChannel;
import org.gnu.stealthp.rsslib.RSSException;
import org.gnu.stealthp.rsslib.RSSHandler;
import org.gnu.stealthp.rsslib.RSSItem;
import org.gnu.stealthp.rsslib.RSSParser;
public class RssNewsFetcher {
/**
* rss訂閱列表
*/
private final static String[] rssArr = new String[] {
//"http://news.baidu.com/n?cmd=1&class=civilnews&tn=rss",
"http://xiaoxian100.blog.163.com/rss",
"http://blog.csdn.net/xiaoxian8023/rss/list"
};
/**
* 測試解析rss訂閱
* @throws IOException
*/
public void testFetchRssNews() throws IOException {
for (int i = 0; i < rssArr.length; i++) {
try {
//獲取rss訂閱地址
URL url = new URL(rssArr[i]);
RSSHandler handler = new RSSHandler();
//解析rss
//

已經修改的差不多了,下一步就是做成jar,以供本項目使用。步驟很簡單。右鍵項目,選擇“導出”→“Java”→“jar文件”,下一步,把右側的勾全去掉,然後設定一下jar的生成路徑,點擊“完成”即可。javadoc生成方式差不多,可以參考這裡。
手癢了麼?快來試試看吧。當然,現在做的myrsslib4j 跟rsslib4j一樣,僅僅支持rss格式的博客。下篇博客給大家奉獻修改過的rome——myrome,它很好的支持了rss和atom 2種格式的博客。此閱讀器會以myrome來解析在線的訂閱信息,敬請期待吧。
加句題外話,為了更好的與大家分享,我在Google Code中上傳了myrsslib4j的源代碼。項目主頁:https://code.google.com/p/myrsslib4j/ 。個人能力所限,難免會有瑕疵,歡迎大家多多指正。