LinkedList簡介
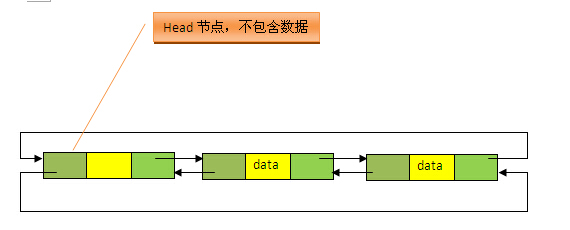
LinkedList是基於雙向循環鏈表(從源碼中可以很容易看出)實現的,除了可以當做鏈表來操作外,它還可以當做棧、隊列和雙端隊列來使用。
LinkedList同樣是非線程安全的,只在單線程下適合使用。
LinkedList實現了Serializable接口,因此它支持序列化,能夠通過序列化傳輸,實現了Cloneable接口,能被克隆。
LinkedList源碼剖析
LinkedList的源碼如下(加入了比較詳細的注釋):
package java.util;
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
// 鏈表的表頭,表頭不包含任何數據。Entry是個鏈表類數據結構。
private transient Entry<E> header = new Entry<E>(null, null, null);
// LinkedList中元素個數
private transient int size = 0;
// 默認構造函數:創建一個空的鏈表
public LinkedList() {
header.next = header.previous = header;
}
// 包含“集合”的構造函數:創建一個包含“集合”的LinkedList
// 本欄目
1、從源碼中很明顯可以看出,LinkedList的實現是基於雙向循環鏈表的,且頭結點中不存放數據,如下圖;
2、注意兩個不同的構造方法。無參構造方法直接建立一個僅包含head節點的空鏈表,包含Collection的構造方法,先調用無參構造方法建立一個空鏈表,而後將Collection中的數據加入到鏈表的尾部後面。
3、在查找和刪除某元素時,源碼中都劃分為該元素為null和不為null兩種情況來處理,LinkedList中允許元素為null。
4、LinkedList是基於鏈表實現的,因此不存在容量不足的問題,所以這裡沒有擴容的方法。
5、注意源碼中的Entry<E> entry(int index)方法。該方法返回雙向鏈表中指定位置處的節點,而鏈表中是沒有下標索引的,要指定位置出的元素,就要遍歷該鏈表,從源碼的實現中,我們看到這裡有一個加速動作。源碼中先將index與長度size的一半比較,如果index<size/2,就只從位置0往後遍歷到位置index處,而如果index>size/2,就只從位置size往前遍歷到位置index處。這樣可以減少一部分不必要的遍歷,從而提高一定的效率(實際上效率還是很低)。
6、注意鏈表類對應的數據結構Entry。如下;
// 雙向鏈表的節點所對應的數據結構。
// 包含3部分:上一節點,下一節點,當前節點值。
private static class Entry<E> {
// 當前節點所包含的值
// 本欄目
8、要注意源碼中還實現了棧和隊列的操作方法,因此也可以作為棧、隊列和雙端隊列來使用。