從 initialValue 說起
問題的發現源自對 JPA 中 TableGenerator 的測試。測試的環境有這樣幾個條件:
為方便查詢的測試,Employee 表格在初始化時會導入部分記錄,這部分記錄的主鍵在初始腳本中手動寫好,比如 1、2、3、4。(參看文章所附示例代碼中的import_data.sql 文件)。
Employee 實體使用 TableGenerator 主鍵生成器,initialValue 的值設置為 10。
在單元測試中添加新的 Employee 記錄。
Employee 實體類的代碼參看清單 1:
清單 1. Employee 實體類
@Entity @Table(name="emp3")
public class Employee3 {
@TableGenerator(name="id_gen",table="id_gen",initialValue=10) @Id
@GeneratedValue(strategy=TABLE,generator="id_gen")
private long id;
private String firstName;
private String lastName;
......
}
@TableGenerator 的配置參數 initialValue 指的是主鍵生成列的初始值,這在 @TableGenerator 的 API 文檔中寫得很清楚。現在 initialValue 值設置為 10, 那麼在單元測試中用 JPA 添加新的 Employee 記錄時,新記錄的主鍵會從 11 開始,不會與已有的數據發生沖突(參看文章所附示例代碼中 src/java/test/sample/case3/OldInitialValue.java)。執行的結果出乎意料,測試報錯,說是主鍵重復。錯誤信息如清單 2 所示:
清單 2. 主鍵重復錯誤信息
11:23:40,220 ERROR SqlExceptionHelper:144 - Duplicate entry '1' for key 'PRIMARY'
這實在令人困惑。如果 initialValue 的含義不是初始值,那還能是什麼呢?
問題其實出在程序所用的 JPA 提供者(Hibernate)上面。如果改用其他 JPA 提供者,估計不會出現上面的問題(未驗證)。Hibernate 之所以會出現這種情況,並非無知,也不是不尊重標准,而有它自身的原因,這在文章後面會提到。現在,為了把問題講清楚, 有必要先談談 JPA 主鍵生成器選型的問題,了解一下 @TableGenerator 在 JPA 中的特殊地位。
JPA 主鍵生成器選型
JPA 提供了四種主鍵生成器,參看表 1:

SequenceStyleGenerator
Hibernate 的 SequenceStyleGenerator 允許在不支持 Sequence 對象的數據庫中模擬使用 SEQUENCE 主鍵生成器,這種模擬的 SEQUENCE 主鍵生成器本質上其實還是 TABLE 生成器。默認情況下不啟用該生成器。具體配置與新 TableGenerator 相似。參考資源中有相關資料。
一般來說,支持 IDENTITY 的數據庫,如 MySQL、SQL Server、DB2 等,AUTO 的效果與 IDENTITY 相同。IDENTITY 主鍵生成器最大的特點是:在表中插入記錄以後主鍵才會生成。這意味著,實體對象只有在保存到數據庫以後,才能得到主鍵值。用 EntityManager 的 persist 方法來保存實體時必須在數據庫中插入紀錄,這種主鍵生成機制大大限制了 JPA 提供者優化性能的可能性。在 Hibernate 中通過設置 FlushMode 為 MANUAL,可以將記錄的插入延遲到長事務提交時再執行,從而減少對數據庫的訪問頻率。實施這種系統性能提升方案的前提就是不能使用 IDENTITY 主鍵生成器。
SEQUENCE 主鍵生成器主要用在 PostgreSQL、Oracle 等自帶 Sequence 對象的數據庫管理系統中,它每次從數據庫 Sequence 對象中取出一段數值分配給新生成的實體對象,實體對象在寫入數據庫之前就會分配到相應的主鍵。
上面的分析中,我們把現實世界中的關系數據庫分成了兩大類:一是支持 IDENTITY 的數據庫,二是支持 SEQUENCE 的數據庫。對支持 IDENTITY 的數據庫來說,使用 JPA 時變得有點麻煩:出於性能考慮,它們在選用主鍵生成策略時應當避免使用 IDENTITY 和 AUTO,同時,他們不支持 SEQUENCE。看起來,四個主鍵生成器裡面排除了三個,剩下唯一的選擇就是 TABLE。由此可見,TABLE 主鍵生成機制在 JPA 中地位特殊。它是在不影響性能情況下,通用性最強的 JPA 主鍵生成器。
本欄目
TableGenerator 有新舊之分?
TableGenerator 注解和 TableGenerator 類
這裡反復提到的 TableGenerator 有兩種,一是 JPA 中的注解,另一個是 Hibernate 中的實現類,閱讀時需要注意區別。TableGenerator 注解是 JPA 規范中的注解,用於確定 TABLE 主鍵生成器的各個參數。Hibernate 中的兩個 TableGenerator 類實現了 TABLE 主鍵生成器的功能,它們是類,不是注解。
JPA 的 @TableGenerator 只是通用的注解,具體的功能要由 JPA 提供者來實現。Hibernate 中實現該注解的類有兩個,一是原有的 TableGenerator,類名為 org.hibernate.id.TableGenerator,這是默認的 TableGenerator。二是新 TableGenerator,指的是 org.hibernate.id.enhanced.TableGenerator。當用 Hibernate 來提供 JPA 時,需要通過配置參數指定使用何種 TableGenerator 來提供相應功能。
在 4.1 版本的 Hibernate Reference Manual 關於配置參數的章節中(網址可從參考資源中找到)可以找到如下說明:
我們建議所有使用 @GeneratedValue 的新工程都配置 hibernate.id.new_generator_mappings=true 。因為新的生成器更加高效,也更符合 JPA2 的規范。不過,要是已經使用了 table 或 sequence 生成器,新生成器與之不相兼容。
還可以再參考一下 HHH-4884 和 HHH-4690 ,裡面有 Hibernate 開發人員對這些問題的看法。
綜合這些資源,可以得到如下結論:
如果不配置 hibernate.id.new_generator_mappings=true,使用 Hibernate 來提供 TableGenerator 時,JPA 中 @TableGenerator 注解的 initialValue 參數是無效的。
Hibernate 開發人員原本希望用新 TableGenerator 替換掉原有的 TableGenerator,但這麼做會導致已經使用舊 TableGenerator 的 Hibernate 工程在升級 Hibernate 後,新生成的主鍵值可能會與原有的主鍵沖突,導致不可預料的結果。為保持兼容,Hibernate 默認情況下使用舊 TableGenerator 機制。
沒有歷史負擔的新 Hibernate 工程都應該使用 hibernate.id.new_generator_mappings=true 配置選項。
現在回到清單 1 所示的問題,要解決這個問題只需在 persistence.xml 文件中添加如下一行配置即可:
清單 3. 添加新的配置行
<property name="hibernate.id.new_generator_mappings" value="true" />
使用新 TableGenerator 後就可以放心地在 JPA 中使用 initialValue 參數了,不過,這只是新 TableGenerator 的一個好處,我們接下來還可以看看新 TableGenerator 帶來的更多用法。
新 TableGenerator 的更多用法
新 TableGenerator 除了實現 JPA TableGenerator 注解的全部功能外,還有其他 JPA 注解沒有包含的功能,其配置參數共有 8 項。新 TableGenerator 的 API 文檔詳細解釋了這 8 項參數的含義,但很奇怪的是,Hibernate API 文檔中給出的是 Java 常量的名字,在實際使用時還需要通過這些常量名找到對應的字符串,非常不方便。用對應字符串替換常量後,可以得到下面的配置參數表:

在描述各個參數的含義時,表中多次提到了“序列”,在這個表裡的意思相當於 sequence,也相當於 segment。這裡反映出術語的混亂,如果在 Hibernate文檔中把兩個英文單詞統一起來,閱讀的時候會更加清楚。新 TableGenerator 的 8 個參數可分為兩組,前 5 個參數描述的是輔助表的結構,後 3個參數用於配置主鍵生成算法。
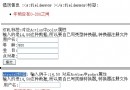
先來看前 5 個參數,下圖是本文示例程序用於主鍵生成的輔助表,把圖中的元素和新 TableGenerator 前 4 個配置參數一一對應起來,它們的含義一目了然。
圖 1. 輔助表
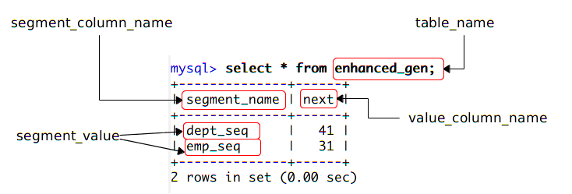
第 5 個參數 segment_value_length 是用來確定序列名稱所在列的長度,即序列名所能使用的最大字符數。從這 5 個參數的含義可以看出,新TableGenerator 支持在同一個表中放下多個主鍵生成器,從而避免數據庫中為生成主鍵而創建大量的輔助表。
後面 3 個參數用於描述主鍵生成算法。第 6 個參數指定初始值。第 7 個參數 increment_size 確定了步長。最關鍵的是第 8 個參數optimizer。optimizer 的默認值一欄寫的是“依 increment_size 的取值而定”,到底如何確定呢?
為搞清楚這個問題,需要先來了解一下 Hibernate 自帶的 Optimizer。
本欄目
Hibernate 自帶的 Optimizer
Optimizer 可以翻譯成優化器,使用優化器是為了避免每次生成主鍵時都會訪問數據庫。從 Hibernate 官方文檔中找不到優化器的說明,需要查閱源碼,在 org.hibernate.id.enhanced.OptimizerFactory 類中可以找到這些優化器的名字及對應的實現類,其中優化器的名字就是新TableGenerator 中 optimizer 參數中能夠使用的值:

Hibernate 自帶了 5 種優化器,那麼現在就可以加到上一節提到的問題了:默認情況下,新 TableGenerator 會選擇哪個優化器呢?
又一次,在 Hibernate 文檔中找不到答案,還是要去查閱源碼。通過分析 TableGenerator,可以看到 optimizer的選擇策略。具體過程可用下圖來描述:
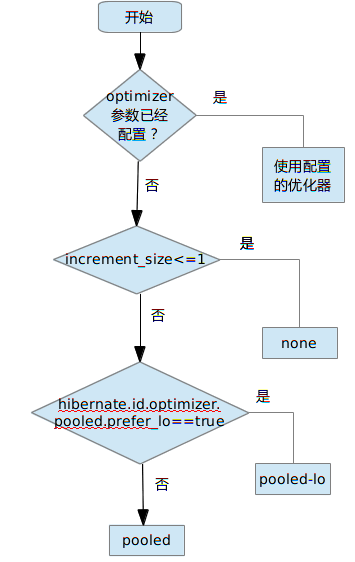
JPA 的 @TableGenerator 注解有一個參數 allocationSize,如果用 Hibernate 來提供 JPA,並且開啟new_generator_mapping 參數,那麼 allocationSize 的值就會是這裡的 increment_size。經常可以在網絡上看到把allocationSize 設置成 1 的例子,這種行為無異於應用程序的自殘。這種情況下還不如使用 AUTO。值得慶幸的是 allocationSize的默認值為 50。
可以看出,hilo 和 legacy-hilo 兩種優化器,除非指定,一般不會在實踐中出現。接下來很重要的一步就是判斷 increment_size 的值,如果increment_size 不做指定,使用默認的1,那麼最終選擇的優化器會是“none”。選中了“none”也就意味著沒有任何優化,每次主鍵的生成都需要訪問數據庫。這種情況下 TableGenerator的優勢喪失殆盡,如果再用同一張表生成多個實體的主鍵,構造出來的系統在性能上會是程序員的噩夢。
在 increment_size 值大於 1 的情況下,只有 pooled 和 pooled-lo 兩種優化器可供選擇,選擇條件由布爾型參數hibernate.id.optimizer.pooled.prefer_lo 確定,該參數默認為 false,這也意味著,大多數情況下選中的優化器會是pooled。
我們不去討論 none 和 legacy-hilo,前者不應該使用,後者的名字看上去像是古董。剩下 hilo、pooled 和 pooled-lo其實是同一種算法,它們的區別在於主鍵生成輔助表的數值。
本欄目
在表 3 中提到 hilo 優化器在輔助表中的數值是 bucket 的序號。這裡 bucket可以翻譯成“桶”,也可翻譯成“塊”,其含義就是一段連續可分配的整數,如:1-10,50-100 等。桶的容量即是 increment_size 的值,假定increment_size 的值為 50,那麼桶的序號和每個桶容納的整數可參看下表:

hilo 優化器把桶的序號放在了數據庫輔助表中,pooled-lo 優化器把下一個桶的第一個整數放在數據庫輔助表中,而 pooled優化器則把下下桶的第一個整數放在數據庫輔助表中。舉個例子,如果 increment_size=50, 當前某實體分到的主鍵編號為60,可以推測出各個優化器及對應的數據庫輔助表中的值。如下表所示:

一般來說,pooled-lo 比 pooled 更符合人的習慣,沒有設置 hibernate.id.optimizer.pooled.prefer_lo 為 true時,數據庫輔助表的值會出乎人的意料。
程序員看到英文單詞“pooled”,會和連接池這樣的概念聯系在一起,這裡的池不過是一堆可用於主鍵分配的整數的“池”,其含義與連接池很相似。
新 TableGenerator 實例
關於空洞
不管是 hilo、還是 pooled、或者 pooled-lo,在使用過程中不可避免地會產生空洞。比如當前主鍵編號分到第 60,接下來重啟了應用程序,Hibernate 無法記住上一次分配的數值,於是 61-100 之間的整數可能永遠都不會用於主鍵的分配。很多人會對此不適應,覺得像是丟了什麼東西,應用程序也因此不夠完美。其實,仔細去分析,這種感覺只能算是人的心理不適,對程序來說,只是需要生成唯一而不重復的數值而已,數據庫記錄之間的主鍵編號是否連續根本不影響系統的使用。ORM 程序需要適應這些空洞的存在,計算機的世界裡不會因為這些空洞而不夠完美。
最後,演示一下 Hibernate 新 TableGenerator 的完整功能。新 TableGenerator 的一些功能不在 JPA 中,因此不能使用 JPA 的 @TableGenerator 注解,而是要使用 Hibernate 自身的 @GenericGenerator 注解。
@GenericGenerator 注解有個 strategy 參數,用來指定主鍵生成器的名稱或類名,類名是容易找到的,不過寫起來太不方便了。生成器的名稱卻不大好找,翻遍 Hibernate 的 manual,devguide,都無法找到這些生成器的名稱,最後還得去看源碼。可以在 DefaultIdentifierGeneratorFactory 類中找到新 TableGenerator 的名稱應該是“enhanced-table”。配置新 TableGenerator 的例子參看清單 4 的代碼:
清單 4. 配置新 TableGenerator 的代碼
@Entity @Table(name="emp4")
public class Employee4 {
@GenericGenerator( name="id_gen", strategy="enhanced-table",
parameters = {
@Parameter( name = "table_name", value = "enhanced_gen"),
@Parameter( name ="value_column_name", value = "next"),
@Parameter( name = "segment_column_name",value = "segment_name"),
@Parameter( name = "segment_value", value = "emp_seq"),
@Parameter( name = "increment_size", value = "10"),
@Parameter( name = "optimizer",value = "pooled-lo")
})
@Id @GeneratedValue(generator="id_gen")
private long id;
private String firstName; private String lastName;
......
}
結束語
Hibernate 發展到現在,文檔的更新有些落後於代碼的實現,像新 Tablenerator 這樣的特性,影響極大,很多程序員都在不清楚這些特性的情況下使用Hibernate,這會給將來的升級帶來隱患。Hibernate 官方的文檔有待進一步完善,本文希望能夠在這裡做些補缺的工作。