首先,我們回想一下上一章提到的根搜索算法,它可以解決我們應該回收哪些對象的問題,但是它顯然還不能承擔垃圾搜集的重任,因為我們在程序(程序也就是指我們運行在JVM上的JAVA程序)運行期間如果想進行垃圾回收,就必須讓GC線程與程序當中的線程互相配合,才能在不影響程序運行的前提下,順利的將垃圾進行回收。
為了達到這個目的,標記/清除算法就應運而生了。它的做法是當堆中的有效內存空間(available memory)被耗盡的時候,就會停止整個程序(也被成為stop the world),然後進行兩項工作,第一項則是標記,第二項則是清除。
下面LZ具體解釋一下標記和清除分別都會做些什麼。
標記:標記的過程其實就是,遍歷所有的GC Roots,然後將所有GC Roots可達的對象標記為存活的對象。
清除:清除的過程將遍歷堆中所有的對象,將沒有標記的對象全部清除掉。
其實這兩個步驟並不是特別復雜,也很容易理解。LZ用通俗的話解釋一下標記/清除算法,就是當程序運行期間,若可以使用的內存被耗盡的時候,GC線程就會被觸發並將程序暫停,隨後將依舊存活的對象標記一遍,最終再將堆中所有沒被標記的對象全部清除掉,接下來便讓程序恢復運行。
下面LZ給各位制作了一組描述上面過程的圖片,結合著圖片,我們來直觀的看下這一過程,首先是第一張圖。
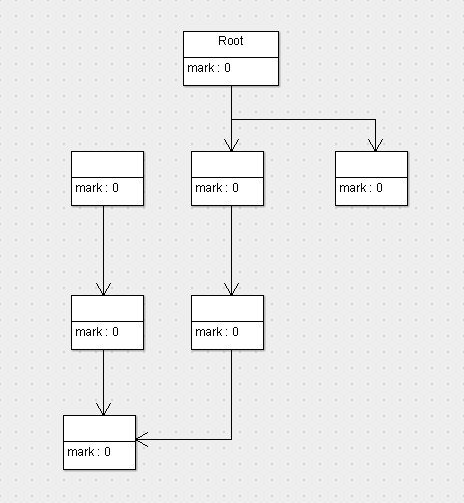
URL:http://www.bianceng.cn/Programming/Java/201410/45821.htm
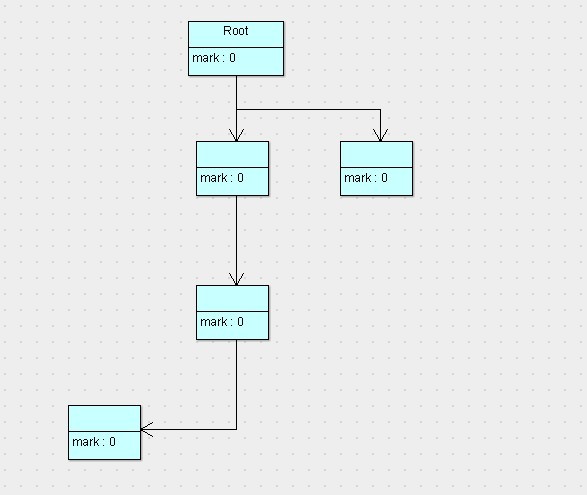
這張圖代表的是程序運行期間所有對象的狀態,它們的標志位全部是0(也就是未標記,以下默認0就是未標記,1為已標記),假設這會兒有效內存空間耗盡了,JVM將會停止應用程序的運行並開啟GC線程,然後開始進行標記工作,按照根搜索算法,標記完以後,對象的狀態如下圖。
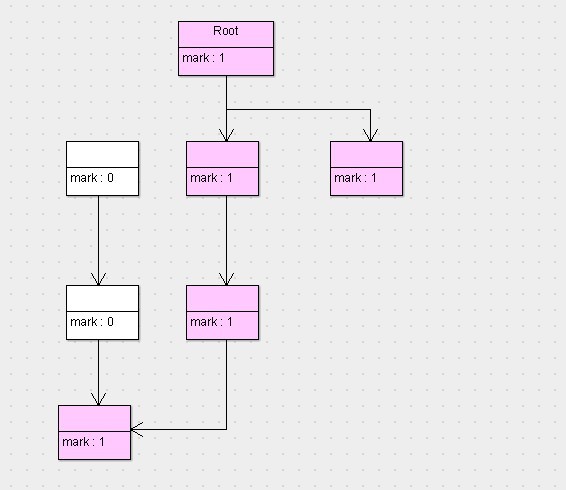
可以看到,按照根搜索算法,所有從root對象可達的對象就被標記為了存活的對象,此時已經完成了第一階段標記。接下來,就要執行第二階段清除了,那麼清除完以後,剩下的對象以及對象的狀態如下圖所示。
可以看到,沒有被標記的對象將會回收清除掉,而被標記的對象將會留下,並且會將標記位重新歸0。接下來就不用說了,喚醒停止的程序線程,讓程序繼續運行即可。
其實這一過程並不復雜,甚至可以說非常簡單,各位說對嗎。不過其中有一點值得LZ一提,就是為什麼非要停止程序的運行呢?
這個其實也不難理解,LZ舉個最簡單的例子,假設我們的程序與GC線程是一起運行的,各位試想這樣一種場景。
假設我們剛標記完圖中最右邊的那個對象,暫且記為A,結果此時在程序當中又new了一個新對象B,且A對象可以到達B對象。但是由於此時A對象已經標記結束,B對象此時的標記位依然是0,因為它錯過了標記階段。因此當接下來輪到清除階段的時候,新對象B將會被苦逼的清除掉。如此一來,不難想象結果,GC線程將會導致程序無法正常工作。
上面的結果當然令人無法接受,我們剛new了一個對象,結果經過一次GC,忽然變成null了,這還怎麼玩?
到此為止,標記/清除算法LZ已經介紹完了,下面我們來看下它的缺點,其實了解完它的算法原理,它的缺點就很好理解了。
1、首先,它的缺點就是效率比較低(遞歸與全堆對象遍歷),而且在進行GC的時候,需要停止應用程序,這會導致用戶體驗非常差勁,尤其對於交互式的應用程序來說簡直是無法接受。試想一下,如果你玩一個網站,這個網站一個小時就掛五分鐘,你還玩嗎?
2、第二點主要的缺點,則是這種方式清理出來的空閒內存是不連續的,這點不難理解,我們的死亡對象都是隨即的出現在內存的各個角落的,現在把它們清除之後,內存的布局自然會亂七八糟。而為了應付這一點,JVM就不得不維持一個內存的空閒列表,這又是一種開銷。而且在分配數組對象的時候,尋找連續的內存空間會不太好找。
看完它的缺點估計有的猿友要忍不住吐糟了,“這麼說這個算法根本沒法用嘛,那LZ還介紹這麼個玩意干什麼。”
猿友們莫要著急,一個算法有缺點,高人們自然會想盡辦法去完善它的。而接下來我們要介紹的兩種算法,皆是在標記/清除算法的基礎上優化而產生的。具體的內容,下一次LZ再和各位分享。
本次的分享就到此結束了,希望各位看完都能有所收獲,0.0。
作者:zuoxiaolong(左潇龍)
出處:博客園左潇龍的技術博客--http://www.cnblogs.com/zuoxiaolong