原因在上一章其實已經有所觸及,就是因為在平時的工作和研究當中,不可避免的會遇到內存溢出與內存洩露的問題。如果對GC策略與原理不了解的情況下碰到了前面所說的問題,很多時候會讓人不知所措。
當我們了解了相關知識以後,雖然有時候依然不能很快的解決問題,但可以肯定的是,至少不會出現無計可施的情況。
既然是要進行自動GC,那必然會有相應的策略,而這些策略解決了哪些問題呢,粗略的來說,主要有以下幾點。
1、哪些對象可以被回收。
2、何時回收這些對象。
3、采用什麼樣的方式回收。
有關上面所提到的三個問題,其實最主要的一個問題就是第一個,也就是哪些對象才是可以回收的。
URL:http://www.bianceng.cn/Programming/Java/201410/45820.htm
有一種比較簡單直觀的辦法,它的效率較高,被稱作引用計數算法。但是這個算法有一個致命的缺陷,那就是對於循環引用的對象無法進行回收。想象一下,假設JVM采用這種GC策略,那麼程序猿在編寫的程序的時候,下面這樣的代碼就不要指望再出現了。
public class Object {
Object field = null;
public static void main(String[] args) {
Thread thread = new Thread(new Runnable() {
public void run() {
Object objectA = new Object();
Object objectB = new Object();//1
objectA.field = objectB;
objectB.field = objectA;//2
//to do something
objectA = null;
objectB = null;//3
}
});
thread.start();
while (true);
}
}
這段代碼看起來有點刻意為之,但其實在實際編程過程當中,是經常出現的,比如兩個一對一關系的數據庫對象,各自保持著對方的引用。最後一個無限循環只是為了保持JVM不退出,沒什麼實際意義。
對於我們現在使用的GC來說,當thread線程運行結束後,會將objectA和objectB全部作為待回收的對象。而如果我們的GC采用上面所說的引用計數算法,則這兩個對象永遠不會被回收,即便我們在使用後顯示的將對象歸為空值也毫無作用。
這裡LZ大致解釋一下,在代碼中LZ標注了1、2、3三個數字,當第1個地方的語句執行完以後,兩個對象的引用計數全部為1。當第2個地方的語句執行完以後,兩個對象的引用計數就全部變成了2。當第3個地方的語句執行完以後,也就是將二者全部歸為空值以後,二者的引用計數仍然為1。根據引用計數算法的回收規則,引用計數沒有歸0的時候是不會被回收的。
由於引用計數算法的缺陷,所以JVM一般會采用一種新的算法,叫做根搜索算法。它的處理方式就是,設立若干種根對象,當任何一個根對象到某一個對象均不可達時,則認為這個對象是可以被回收的。
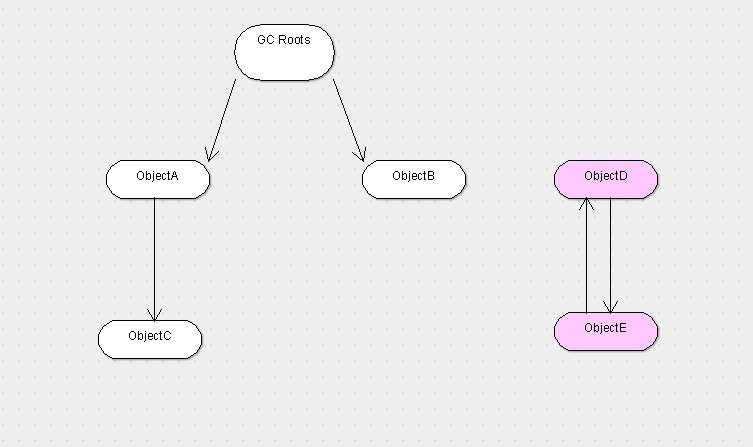
就拿上圖來說,ObjectD和ObjectE是互相關聯的,但是由於GC roots到這兩個對象不可達,所以最終D和E還是會被當做GC的對象,上圖若是采用引用計數法,則A-E五個對象都不會被回收。
說到GC roots(GC根),在JAVA語言中,可以當做GC roots的對象有以下幾種:
1、虛擬機棧中的引用的對象。
2、方法區中的類靜態屬性引用的對象。
3、方法區中的常量引用的對象。
4、本地方法棧中JNI的引用的對象。
第一和第四種都是指的方法的本地變量表,第二種表達的意思比較清晰,第三種主要指的是聲明為final的常量值。
根搜索算法解決的是垃圾搜集的基本問題,也就是上面提到的第一個問題,也是最關鍵的問題,就是哪些對象可以被回收。
不過垃圾收集顯然還需要解決後兩個問題,什麼時候回收以及如何回收。在根搜索算法的基礎上,現代虛擬機的實現當中,垃圾搜集的算法主要有三種,分別是標記-清除算法、復制算法、標記-整理算法。這三種算法都擴充了根搜索算法,不過它們理解起來還是非常好理解的。
結束語
限於文章篇幅不要太長,本次就不具體介紹三種垃圾搜集算法了,在下一章再與各位探討。
作者:zuoxiaolong(左潇龍)
出處:博客園左潇龍的技術博客--http://www.cnblogs.com/zuoxiaolong