Java 8帶來了很多可以使編碼更簡潔的特性。例如,像下面的代碼:
Collections.sort(transactions, new Comparator<Transaction>(){
public int compare(Transaction t1, Transaction t2){
return t1.getValue().compareTo(t2.getValue());
}
});
可以用替換為如下更為緊湊的代碼,功能相同,但是讀上去與問題語句本身更接近了:
transactions.sort(comparing(Transaction::getValue));
Java 8引入的主要特性是Lambda表達式、方法引用和新的Streams API。它被認為是自20年前Java誕生以來語言方面變化最大的版本。要想通過詳細且實際的例子來了解如何從這些特性中獲益,可以參考本文作者和Alan Mycroft共同編寫的《Java 8 in Action: Lambdas, Streams and Functional-style programming》一書。
這些特性支持程序員編寫更簡潔的代碼,還使他們能夠受益於多核架構。實際上,編寫可以優雅地並行執行的程序還是Java專家們的特權。然而,借助新的Streams API,Java 8改變了這種狀況,讓每個人都能夠更容易地編寫利用多核架構的代碼。
在這篇文章中,我們將使用以下三種風格,以不同方法計算一個大數據集的方差,並加以對比。
命令式風格
Fork/Join框架
Streams API
方差是統計學中的概念,用於度量一組數的偏離程度。方差可以通過對每個數據與平均值之差的平方和求平均值來計算。例如,給定一組表示人口年齡的數:40、30、50和80,我們可以這樣計算方差:
計算平均值:(40 + 30 + 50 + 80) / 4 = 50
計算每個數據與平均值之差的平方和:(40-50)2 + (30-50)2 + (50-50)2 + (80-50)2 = 1400
最後平均:1400/4 = 350
下面是計算方差的一種典型的命令式風格實現:
public static double varianceImperative(double[] population){
double average = 0.0;
for(double p: population){
average += p;
}
average /= population.length;
double variance = 0.0;
for(double p: population){
variance += (p - average) * (p - average);
}
return variance/population.length;
}
為什麼說這是命令式的呢?我們的實現用修改狀態的語句序列描述了計算過程。這裡,我們顯式地對人口年齡數組中的每個元素進行迭代,而且每次迭代時更新average和variance這兩個局部變量。這種代碼很適合只有一個CPU的硬件架構。確實,它可以非常直接地映射到CPU的指令集。
查看本欄目
那麼,如何編寫適合在多核架構上執行的實現代碼呢?應該使用線程嗎?這些線程是不是要在某個點上同步?Java 7引入的Fork/Join框架緩解了一些困難,所以讓我們使用該框架來開發方差算法的一個並行版本吧。
public class ForkJoinCalculator extends RecursiveTask<Double> {
public static final long THRESHOLD = 1_000_000;
private final SequentialCalculator sequentialCalculator;
private final double[] numbers;
private final int start;
private final int end;
public ForkJoinCalculator(double[] numbers, SequentialCalculator sequentialCalculator) {
this(numbers, 0, numbers.length, sequentialCalculator);
}
private ForkJoinCalculator(double[] numbers, int start, int end, SequentialCalculator
sequentialCalculator) {
this.numbers = numbers;
this.start = start;
this.end = end;
this.sequentialCalculator = sequentialCalculator;
}
@Override
protected Double compute() {
int length = end - start;
if (length <= THRESHOLD) {
return sequentialCalculator.computeSequentially(numbers, start, end);
}
ForkJoinCalculator leftTask = new ForkJoinCalculator(numbers, start, start + length/2,
sequentialCalculator);
leftTask.fork();
ForkJoinCalculator rightTask = new ForkJoinCalculator(numbers, start + length/2, end,
sequentialCalculator);
Double rightResult = rightTask.compute();
Double leftResult = leftTask.join();
return leftResult + rightResult;
}
}
這裡我們編寫了一個RecursiveTask類的子類,它對一個double數組進行切分,當子數組的長度小於等於給定阈值(THRESHOLD)時停止切分。切分完成後,對子數組進行順序處理,並將下列接口定義的操作應用於子數組。
public interface SequentialCalculator {
double computeSequentially(double[] numbers, int start, int end);
}
利用該基礎設施,可以按如下方式並行計算方差。
public static double varianceForkJoin(double[] population){
final ForkJoinPool forkJoinPool = new ForkJoinPool();
double total = forkJoinPool.invoke(new ForkJoinCalculator
(population, new SequentialCalculator() {
@Override
public double computeSequentially(double[] numbers, int start, int end) {
double total = 0;
for (int i = start; i < end; i++) {
total += numbers[i];
}
return total;
}
}));
final double average = total / population.length;
double variance = forkJoinPool.invoke(new ForkJoinCalculator
(population, new SequentialCalculator() {
@Override
public double computeSequentially(double[] numbers, int start, int end) {
double variance = 0;
for (int i = start; i < end; i++) {
variance += (numbers[i] - average) * (numbers[i] - average);
}
return variance;
}
}));
return variance / population.length;
}
本質上,即便使用Fork/Join框架,相對於順序版本,並行版本的編寫和最後的調試仍然困難許多。
查看本欄目
Java 8讓我們可以以不同的方式解決這個問題。不同於編寫代碼指出計算如何實現,我們可以使用Streams API粗線條地描述讓它做什麼。作為結果,庫能夠知道如何為我們實現計算,並施以各種各樣的優化。這種風格被稱為聲明式編程。Java 8有一個為利用多核架構而專門設計的並行Stream。我們來看一下如何使用它們來更快地計算方差。
假定讀者對本節探討的Stream有些了解。作為復習,Stream<T>是T類型元素的一個序列,支持聚合操作。我們可以使用這些操作來創建表示計算的一個管道(pipeline)。這裡的管道和UNIX的命令管道一樣。並行Stream就是一個可以並行執行管道的Stream,可以通過在普通的Stream上調用parallel()方法獲得。要復習Stream,可以參考Javadoc文檔。
好消息是,Java 8 API內建了一些算術操作,如max、min和average。我們可以使用Stream的幾種基本類型特化形式來訪問前面幾個方法:IntStream(int類型元素)、LongStream(long類型元素)和DoubleStream(double類型元素)。例如,可以使用IntStream.rangeClosed()創建一系列數,然後使用max()和min()方法計算Stream中的最大元素和最小元素。
回到最初的問題,我們想使用這些操作來計算一個規模較大的人口年齡數據的方差。第一步是從人口年齡數組創建一個Stream,可以通過Arrays.stream()靜態方法實現:
DoubleStream populationStream = Arrays.stream(population).parallel();
我們可以使用DoubleStream所支持的average()方法:
double average = populationStream.average().orElse(0.0);
下一步是使用average計算方差。人口年齡中的每個元素首先需要減去平均值,然後計算差的平方。可以將其視作一個Map操作:使用一個Lambda表達式(double p) -> (p - average) * (p - average)把每個元素轉換為另一個數,這裡是轉換為該元素與平均值差的平方。一旦轉換完成,我們就可以調用sum()方法來計算所有結果元素的和了。.
不過別那麼著急。Stream只能消耗一次。如果復用populationStream,我們會碰到下面這個令人驚訝的錯誤:
java.lang.IllegalStateException: stream has already been operated upon or closed
所以我們需要使用第二個流來計算方差,如下所示:
public static double varianceStreams(double[] population){
double average = Arrays.stream(population).parallel().average().orElse(0.0);
double variance = Arrays.stream(population).parallel()
.map(p -> (p - average) * (p - average))
.sum() / population.length;
return variance;
}
通過使用Streams API內建的操作,我們以聲明式、而且非常簡潔的方式重寫了最初的命令式風格代碼,而且聲明式風格讀上去幾乎就是方差的數學定義。我們再來研究一下三種實現版本的性能。
我們以非常不同的風格編寫了三個版本的方差算法。Stream版本是最簡潔的,而且是以聲明式風格編寫的,它讓類庫去確定具體的實現,並利用多核基礎設施。不過你可能想知道它們的執行效果如何。為找出答案,讓我們創建一個基准測試,對比一下三個版本的表現。我們先隨機生成1到140之間的3000萬個人口年齡數據,然後計算其方差。我們使用jmh來研究每個版本的性能。Jmh是OpenJDK支持的一個Java套件。讀者可以從GitHub克隆該項目,自己運行基准測試。
基准測試運行的機器是Macbook Pro,配備2.3 GHz的4核Intel Core i7處理器,16GB 1600MHz DDR3內存。此外,我們使用的JDK 8版本如下:
java version "1.8.0-ea" Java(TM) SE Runtime Environment (build 1.8.0-ea-b121) Java HotSpot(TM) 64-Bit Server VM (build 25.0-b63, mixed mode)
結果用下面的柱狀圖說明。命令式版本用了60毫秒,Fork/Join版本用了22毫秒,而流版本用了46毫秒。
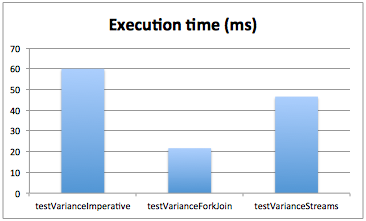
這些數據應該謹慎對待。比如,如果在32位JVM上運行測試,結果很可能有較大的差別。然而有趣的是,使用Java 8中的Streams API這種不同的編程風格,為在場景背後執行一些優化打開了一扇門,而這在嚴格的命令式風格中是不可能的;相對於使用Fork/Join框架,這種風格也更為直接。
查看本欄目