集成 Java 音譯模塊和 InfoSphere Streams 的自定義 Java 運算符
在成長型市場區域中,任何解決方案提供商面臨的首要挑戰是可用數據的方言和語言學的不一致性。由於成長型市場區域中擁有包括英語在內的多種官方語言,所以地區的語言符號逐漸嵌入到了英語符號中。因此,您首先需要執行音譯來實現數據中的一致性,然後再繼續執行處理/文本分析。
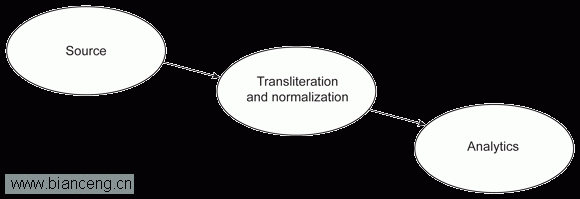
如果使用預定的語言,那麼數據音譯會為您提供更統一、更一致的結果。本文將介紹使用 InfoSphere Streams 的自定義 Java 運算符和 ICU4J 庫執行實時音譯時所涉及的步驟。IBM InfoSphere Streams 提供了執行實時分析流程的功能,提供了各種工具包和適配器,允許您實時連接到各種資源並從中交換數據,在數據上執行操作。實時音譯的高級實現架構如圖 1 所示。
業務先決條件:應當具有利用 InfoSphere Streams 設計和運行 Streams Processing Language (SPL) 應用程序作業的基本技能,並能利用 Java 編程的中級技能。源語言必須使用 UTF-8、UTF-16 格式進行編碼。
軟件先決條件:InfoSphere Streams(2.0 或更高版本),以及 ICU4J 庫。
執行以下步驟,創建音譯自定義 Java 運算符。
按照 Streams 信息中心 中的描述搭建用於 Java 運算符開發的 Streams Studio 環境。
搭建好環境之後,使用 Java 運算符中的 ICU4J 庫編寫音譯邏輯。ICU4J 庫的 jar 文件應導入到項目工作區中。SPL 中的原始 Java 運算符的結構如清單 1 所示。
public synchronized void initialize(OperatorContext context);
public void process(StreamingInput<Tuple> inputStream, Tuple tuple);
public void processPunctuation(StreamingInput<Tuple> inputStream,
StreamingData.Punctuation marker);
public void allPortsReady();
public void shutdown();
運算符的邏輯應位於流程函數內。清單 2 顯示了一個樣例代碼。
清單 2. 使用 Java 運算符執行音譯的樣例代碼
public String toBaseCharacters(final String sText) {
if (sText == null || sText.length() == 0)
return sText;
final char[] chars = sText.toCharArray();
final int iSize = chars.length;
final StringBuilder sb = new StringBuilder(iSize);
for (int i = 0; i < iSize; i++) {
String sLetter = new String(new char[] { chars[i] });
sLetter = Normalizer.normalize(sLetter, Normalizer.NFKD);
try {
byte[] bLetter = sLetter.getBytes("UTF-8");
sb.append((char) bLetter[0]);
} catch (UnsupportedEncodingException e) {
}
}
return sb.toString();
}
public final synchronized void process(final StreamingInput input,
final Tuple tuple) throws Exception {
try
{
OperatorContext ctxt =getOperatorContext();
Transliterator t=Transliterator.getInstance(
ctxt.getParameterValues("sourceLanguage").get(0)+"-"+
ctxt.getParameterValues("destLanguage")
.get(0));
StreamingOutput<OutputTuple> output = getOutput(0);
OutputTuple outputTuple = output.newTuple();
boolean reject = false;
//read the source tuple
String value = tuple.getString("inp");
if ((value == null)) {
throw(new Exception("Input is null"));
} else {
outputTuple.setString("TransliteratedText",
toBaseCharacters(t.transliterate(value.toString())));
}
output.submit(outputTuple);
}
catch(Exception e)
{
}
.....
讀取輸入文本,進行音譯,然後提交給輸出端口,請注意,應將輸入作為 ustring 來讀取,這是 Java 運算符中的字符串。
創建並編譯好運算符代碼後,配置運算符模型,使之可供 SPL 應用程序使用。
對於每一個新運算符而言,根據需要指定的整體配置需求創建相應的運算符模型。運算符模型的一個片段如圖 2 所示。
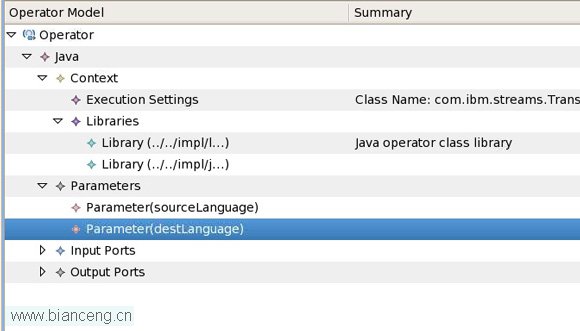
運算符中需要為各個代碼小節設置的值如表 1 所示。

考慮這樣一個場景,通過分析博客帖子和社交媒體社區帖子,您希望了解什麼樣的人群在討論您的產品,該場景是專門針對您的產品而創建。您的產品的客戶已經使用地方方言表達了他們的意見,但是分析工具很難理解這些客戶的態度,因為文本分析規則並不適用於所有方言。
為了解決這一挑戰,可在源語言上執行音譯,然後進行分析。清單 3 向您展示了如何在執行文本分析之前執行音譯。音譯運算符具有兩個參數:源語言和目標語言。如果源語言已知,則需要對其進行相應的設置。如果輸入語言未知,或者具有多種語言符號,那麼將其設置為 Any 會更安全一些。
查看本欄目
composite Main {
graph
stream <rstring LingualInput> SourceBlogs = InetSource ()
{
param
URIList:
["http://localblogs.com/fashionwear"];
initDelay: 5u;
incrementalFetch: true;
fetchIntervalSeconds: 60u;
}
stream <ustring TransliteratedText> TransliteratedOutput=
Transliterate(LingualInput)
{
param
sourceLanguage:"Any";
destLanguage:"Latin";
}
stream <rstring text,rstring product,rstring sentiment,rstring sentiment_text>
as sentiment = TextExtractor(TransliteratedOutput)
{
param
AQLFile: "getsentiment.aql";
}
() as RssResults = FileSink(sentiment)
{
param
file: "output.txt";
format: csv;
hasDelayField: false;
}
}
考慮從 URL 中讀取輸入。在這裡,客戶對 xyz 公司的產品表達了負面的情緒。此時的挑戰就是輸入,這是一個多語言的文本。
xyz suit
進行音譯之後,輸入就轉換為英語格式。
mujhe xyz suit pasanda nahin aya
音譯輸出為您提供了一個運行文本分析的通用平台。在文本中,pasand 和 nahin 都包含負面情緒。因此,這個輸入連同 AQL 文件中的規則一起傳遞給 Text Extractor 運算符,AQL 文件中的規則配置為處理音譯後的地區方言關鍵詞,比如 pasand、nahin 等。因此,Text Extractor 的輸出將如下所示。
mujhe xyz suit pasanda nahin aya, negative, nahin aaya
因此,您可以從一個多語言輸入中成功提取客戶的情緒。
ICU4J 提供一組支持區域化的類別。支持區域化功能的主要類別是 Transliterator 和 Normalizer。
Transliterator 類提供了一個 transliterate() 函數,該函數將字符串從一種語言轉換為另一種語言。音譯函數沒有狀態,也就是說函數中不保留以前的調用信息。使用 transliterate() 函數之前,需要為 Transliterator 實例提供所需的源語言和目標語言來將其初始化,並用破折號 (-) 分隔它們。例如:Transliterator.getInstance("Hindi-Latin");。
Normalizer 類提供將音譯函數的輸出標准化為組合格式或分解格式的函數。例如:拉丁字符 A-acute 等就可標准化為組合格式的單個 A,或者分解格式的兩個 A (AA)。
ICU4J 支持的一些語言轉換如下所示。
ASCII-Latin
Accents-Any
Amharic-Latin/BGN
Arabic-Latin
Bengali-Devanagari
Bengali-Latin
Kannada-Latin
Hindi-Latin
Telugu-Latin
Tamil-Latin
InfoSphere Streams 提供了一個調試程序,可以支持實時應用程序 Streams Debugger。Streams Debugger 提供的命令和選項可輕松用於跟蹤和驗證輸出。
本文提出了如何使用 ICU4J 庫執行音譯的問題,以及人們在構建原始 Java 運算符時必須執行的各種配置設置。音譯將充當解決多種語言挑戰的關鍵組件,並為運行文本分析提供了一個共同基礎。