這個故事源自一個很簡單的想法:創建一個對開發人員友好的、簡單輕量的線程間通訊框架,完全不 用鎖、同步器、信號量、等待和通知,在Java裡開發一個輕量、無鎖的線程內通訊框架;並且也沒有隊列 、消息、事件或任何其他並發專用的術語或工具。
只用普通的老式Java接口實現POJO的通訊。
它可能跟Akka的類型化actor類似,但作為一個必須超級輕量,並且要針對單台多核計算機進行優化的 新框架,那個可能有點過了。
當actor跨越不同JVM實例(在同一台機器上,或分布在網絡上的不同機器上)的進程邊界時,Akka框 架很善於處理進程間的通訊。
但對於那種只需要線程間通訊的小型項目而言,用Akka類型化actor可能有點兒像用牛刀殺雞,不過類 型化actor仍然是一種理想的實現方式。
我花了幾天時間,用動態代理,阻塞隊列和緩存線程池創建了一個解決方案。
圖一是這個框架的高層次架構:
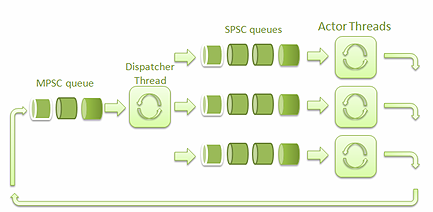
圖一: 框架的高層次架構
SPSC隊列是指單一生產者/單一消費者隊列。MPSC隊列是指多生產者/單一消費者隊列。
派發線程負責接收Actor線程發送的消息,並把它們派發到對應的SPSC隊列中去。
接收到消息的Actor線程用其中的數據調用相應的actor實例中的方法。借助其他actor的代理,actor 實例可以將消息發送到MPSC隊列中,然後消息會被發送給目標actor線程。
我創建了一個簡單的例子來測試,就是下面這個打乒乓球的程序:
public interface PlayerA (
void pong(long ball); //發完就忘的方法調用
}
public interface PlayerB {
void ping(PlayerA playerA, long ball); //發完就忘的方法調用
}
public class PlayerAImpl implements PlayerA {
@Override
public void pong(long ball) {
}
}
public class PlayerBImpl implements PlayerB {
@Override
public void ping(PlayerA playerA, long ball) {
playerA.pong(ball);
}
}
public class PingPongExample {
public void testPingPong() {
// 管理器隱藏了線程間通訊的復雜性
// 控制actor代理,actor實現和線程
ActorManager manager = new ActorManager();
// 在管理器內注冊actor實現
manager.registerImpl(PlayerAImpl.class);
manager.registerImpl(PlayerBImpl.class);
//創建actor代理。代理會將方法調用轉換成內部消息。
//會在線程間發給特定的actor實例。
PlayerA playerA = manager.createActor(PlayerA.class);
PlayerB playerB = manager.createActor(PlayerB.class);
for(int i = 0; i < 1000000; i++) {
playerB.ping(playerA, i);
}
}
經過測試,速度大約在每秒500,000 次乒/乓左右;還不錯吧。然而跟單線程的運行速度比起來,我突 然就感覺沒那麼好了。在 單線程 中運行的代碼每秒速度能達到20億 (2,681,850,373) !
居然差了5,000 多倍。太讓我失望了。在大多數情況下,單線程代碼的效果都比多線程代碼更高效。
我開始找原因,想看看我的乒乓球運動員們為什麼這麼慢。經過一番調研和測試,我發現是阻塞隊列 的問題,我用來在actor間傳遞消息的隊列影響了性能。

圖 2: 只有一個生產者和一個消費者的SPSC隊列
所以我發起了一場競賽,要將它換成Java裡最快的隊列。我發現了Nitsan Wakart的 博客 。他發了幾篇文章介紹單一生產者/單一消費者 (SPSC)無鎖隊列的實現。這些文章受到了Martin Thompson的演講 終極性能的無鎖算法的啟發 。
跟基於私有鎖的隊列相比,無鎖隊列的性能更優。在基於鎖的隊列中,當一個線程得到鎖時,其它線 程就要等著鎖被釋放。而在無鎖的算法中,某個生產者線程生產消息時不會阻塞其它生產者線程,消費者 也不會被其它讀取隊列的消費者阻塞。
在Martin Thompson的演講以及在Nitsan的博客中介紹的SPSC隊列的性能簡直令人難以置信 —— 超過了100M ops/sec。比JDK的並發隊列實現還要快10倍 (在4核的 Intel Core i7 上的性能大約在 8M ops/sec 左右)。
我懷著極大的期望,將所有actor上連接的鏈式阻塞隊列都換成了無鎖的SPSC隊列。可惜,在吞吐量上 的性能測試並沒有像我預期的那樣出現大幅提升。不過很快我就意識到,瓶頸並不在SPSC隊列上,而是在 多個生產者/單一消費者(MPSC)那裡。
用SPSC隊列做MPSC隊列的任務並不那麼簡單;在做put操作時,多個生產者可能會覆蓋掉彼此的值。 SPSC 隊列就沒有控制多個生產者put操作的代碼。所以即便換成最快的SPSC隊列,也解決不了我的問題。
為了處理多個生產者/單一消費者的情況,我決定啟用LMAX Disruptor ——一個基於環形緩沖區的高性能進 程間消息庫。
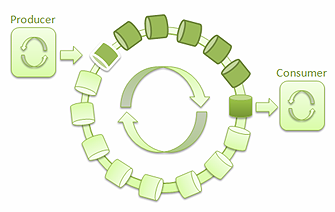
圖3: 單一生產者和單一消費者的LMAX Disruptor
借助Disruptor,很容易實現低延遲、高吞吐量的線程間消息通訊。它還為生產者和消費者的不同組合 提供了不同的用例。幾個線程可以互不阻塞地讀取環形緩沖中的消息:
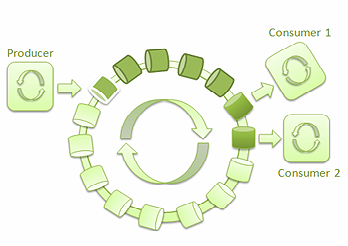
圖 4: 單一生產者和兩個消費者的LMAX Disruptor
下面是有多個生產者寫入環形緩沖區,多個消費者從中讀取消息的場景。
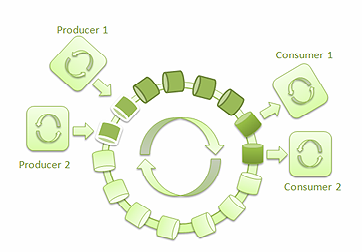
圖 5: 兩個生產者和兩個消費者的LMAX Disruptor
經過對性能測試的快速搜索,我找到了 三個發布者和一個消費者的吞吐量測試。 這個真是正合我意,它給出了下面這個結果:

在3 個生產者/1個 消費者場景下, Disruptor要比LinkedBlockingQueue快兩倍多。然而這跟我所期 望的性能上提升10倍仍有很大差距。
這讓我覺得很沮喪,並且我的大腦一直在搜尋解決方案。就像命中注定一樣,我最近不在跟人拼車上 下班,而是改乘地鐵了。突然靈光一閃,我的大腦開始將車站跟生產者消費者對應起來。在一個車站裡, 既有生產者(車和下車的人),也有消費者(同一輛車和上車的人)。
我創建了 Railway類,並用AtomicLong追蹤從一站到下一站的列車。我先從簡單的場景開始,只有一 輛車的鐵軌。
public class RailWay {
private final Train train = new Train();
// stationNo追蹤列車並定義哪個車站接收到了列車
private final AtomicInteger stationIndex = new AtomicInteger();
// 會有多個線程訪問這個方法,並等待特定車站上的列車
public Train waitTrainOnStation(final int stationNo) {
while (stationIndex.get() % stationCount != stationNo) {
Thread.yield(); // 為保證高吞吐量的消息傳遞,這個是必須的。
//但在等待列車時它會消耗CPU周期
}
// 只有站號等於stationIndex.get() % stationCount時,這個忙循環才會返回
return train;
}
// 這個方法通過增加列車的站點索引將這輛列車移到下一站
public void sendTrain() {
stationIndex.getAndIncrement();
}
}
為了測試,我用的條件跟在Disruptor性能測試中用的一樣,並且也是測的SPSC隊列——測 試在線程間傳遞long值。我創建了下面這個Train類,其中包含了一個long數組:
public class Train {
//
public static int CAPACITY = 2*1024;
private final long[] goodsArray; // 傳輸運輸貨物的數組
private int index;
public Train() {
goodsArray = new long[CAPACITY];
}
public int goodsCount() { //返回貨物數量
return index;
}
public void addGoods(long i) { // 向列車中添加條目
goodsArray[index++] = i;
}
public long getGoods(int i) { //從列車中移走條目
index--;
return goodsArray[i];
}
}
然後我寫了一個簡單的測試 :兩個線程通過列車互相傳遞long值。

圖 6: 使用單輛列車的單一生產者和單一消費者Railway
public void testRailWay() {
final Railway railway = new Railway();
final long n = 20000000000l;
//啟動一個消費者進程
new Thread() {
long lastValue = 0;
@Override
public void run() {
while (lastValue < n) {
Train train = railway.waitTrainOnStation(1); //在#1站等列車
int count = train.goodsCount();
for (int i = 0; i < count; i++) {
lastValue = train.getGoods(i); // 卸貨
}
railway.sendTrain(); //將當前列車送到第一站
}
}
}.start();
final long start = System.nanoTime();
long i = 0;
while (i < n) {
Train train = railway.waitTrainOnStation(0); // 在#0站等列車
int capacity = train.getCapacity();
for (int j = 0; j < capacity; j++) {
train.addGoods((int)i++); // 將貨物裝到列車上
}
railway.sendTrain();
if (i % 100000000 == 0) { //每隔100M個條目測量一次性能
final long duration = System.nanoTime() - start;
final long ops = (i * 1000L * 1000L * 1000L) / duration;
System.out.format("ops/sec = %,d\n", ops);
System.out.format("trains/sec = %,d\n", ops / Train.CAPACITY);
System.out.format("latency nanos = %.3f%n\n",
duration / (float)(i) * (float)Train.CAPACITY);
}
}
}
在不同的列車容量下運行這個測試,結果驚著我了:

在列車容量達到32,768時,兩個線程傳送消息的吞吐量達到了767,028,751 ops/sec。比Nitsan博客中 的SPSC隊列快了幾倍。
繼續按鐵路列車這個思路思考,我想知道如果有兩輛列車會怎麼樣?我覺得應該能提高吞吐量,同時 還能降低延遲。每個車站都會有它自己的列車。當一輛列車在第一個車站裝貨時 ,第二輛列車會在第二個車站卸貨,反之亦然。
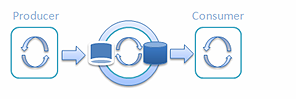
圖 7: 使用兩輛列車的單一生產者和單一消費者Railway
下面是吞吐量的結果:

結果是驚人的;比單輛列車的結果快了1.4倍多。列車容量為一時,延遲從192.6納秒降低到133.5納秒 ;這顯然是一個令人鼓舞的跡象。
因此我的實驗還沒結束。列車容量為2048的兩個線程傳遞消息的延遲為2,178.4 納秒,這太高了。我 在想如何降低它,創建一個有很多輛列車 的例子:
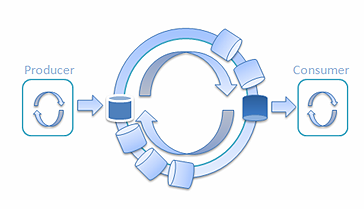
圖 8: 使用多輛列車的單一生產者和單一消費者Railway
查看本欄目
我還把列車容量降到了1個long值,開始玩起了列車數量。下面是測試結果:

用32,768 列車在線程間發送一個long值的延遲降低到了13.9 納秒。通過調整列車數量和列車容量, 當延時不那麼高,吞吐量不那麼低時,吞吐量和延時就達到了最佳平衡。
對於單一生產者和單一消費者(SPSC)而言,這些數值很棒;但我們怎麼讓它在有多個生產者和消費者 時也能生效呢?答案很簡單,添加更多的車站!
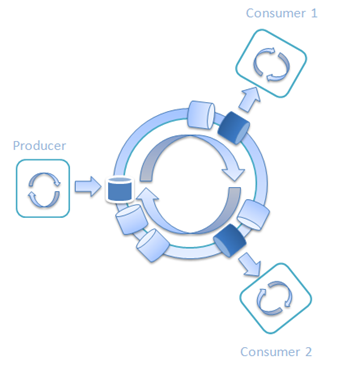
圖 9:一個生產者和兩個消費者的Railway
每個線程都等著下一趟列車,裝貨/卸貨,然後把列車送到下一站。在生產者往列車上裝貨時,消費者 在從列車上卸貨。列車周而復始地從一個車站轉到另一個車站。
為了測試單一生產者/多消費者(SPMC) 的情況,我創建了一個有8個車站的Railway測試。 一個車站屬於一個生產者,而另 外7個車站屬於消費者。結果是:
列車數量 = 256 ,列車容量 = 32:
ops/sec = 116,604,397 延遲(納秒) = 274.4
列車數量= 32,列車容量= 256:
ops/sec = 432,055,469 延遲(納秒) = 592.5
如你所見,即便有8個工作線程,測試給出的結果也相當好-- 32輛容量為256個long的列車吞吐量為 432,055,469 ops/sec。在測試期間,所有CPU內核的負載都是100%。
圖 10:在測試有8個車站的Railway 期間的CPU 使用情況
在玩這個Railway算法時,我幾乎忘了我最初的目標:提升多生產者/單消費者情況下的性能。
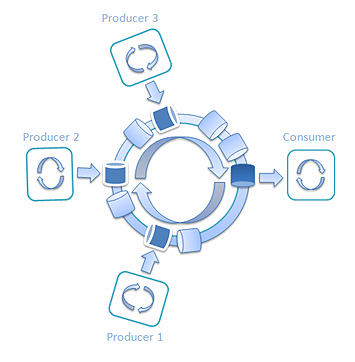
圖 11:三個生產者和一個消費者的 Railway
我創建了3個生產者和1個消費者的新測試。 每輛列車一站一站地轉圈,而每個生產者只給每輛車裝1/3容量的貨。消費者取出每輛車上三個生產者給 出的全部三項貨物。性能測試給出的平均結果如下所示:
ops/sec = 162,597,109 列車/秒 = 54,199,036 延遲(納秒) = 18.5
結果相當棒。生產者和消費者工作的速度超過了160M ops/sec。
為了填補差異,下面給出相同情況下的Disruptor結果- 3個生產者和1個消費者:
Run 0, Disruptor=11,467,889 ops/sec Run 1, Disruptor=11,280,315 ops/sec Run 2, Disruptor=11,286,681 ops/sec Run 3, Disruptor=11,254,924 ops/sec
下面是另一個批量消息的Disruptor 3P:1C 測試 (10 條消息每批):
Run 0, Disruptor=116,009,280 ops/sec Run 1, Disruptor=128,205,128 ops/sec Run 2, Disruptor=101,317,122 ops/sec Run 3, Disruptor=98,716,683 ops/sec;
最後是用帶LinkedBlockingQueue 實現的Disruptor 在3P:1C場景下的測試結果:
Run 0, BlockingQueue=4,546,281 ops/sec Run 1, BlockingQueue=4,508,769 ops/sec Run 2, BlockingQueue=4,101,386 ops/sec Run 3, BlockingQueue=4,124,561 ops/sec
如你所見,Railway方式的平均吞吐量是162,597,109 ops/sec,而Disruptor在同樣的情況下的最好結 果只有128,205,128 ops/sec。至於 LinkedBlockingQueue,最好的結果只有4,546,281 ops/sec。
Railway算法為事件批處理提供了一種可以顯著增加吞吐量的簡易辦法。通過調整列車容量或列車數量 ,很容易達成想要的吞吐量/延遲。
另外, 當同一個線程可以用來消費消息,處理它們並向環中返回結果時,通過混合生產者和消費者, Railway也能用來處理復雜的情況:
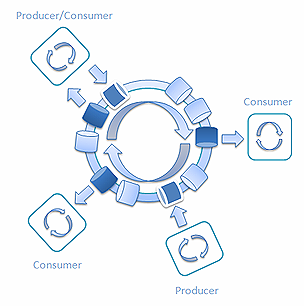
圖 12: 混合生產者和消費者的Railway
最後,我會提供一個經過優化的超高吞吐量 單生產者/單消費者測試:
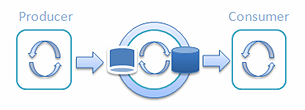
圖 13:單個生產者和單個消費者的Railway
它的平均結果為:吞吐量超過每秒15億 (1,569,884,271)次操作,延遲為1.3 微秒。如你所見,本文 開頭描述的那個規模相同的單線程測試的結果是每秒2,681,850,373。
你自己想想結論是什麼吧。
我希望將來再寫一篇文章,闡明如何用Queue和 BlockingQueue接口支持Railway算法,用來處理不同 的生產者和消費者組合。