需求背景 :TVT 測試中語言文字解碼
在 TVT(Translation Verification Testing 翻譯驗證)測 試時,我們需要不斷地將翻譯成各種語言的 PII(Programmed Integrated Information 程序集成信息)文件 更新到我們的資源文件中,用於我們測試。對於資源文件的管理,我們大部分時候都會用到 RTC。但就 RTC 本身,或者說 eclipse 平台本身並不提供一種途徑顯示這些翻譯後的文字本來的樣子(就是以本國文字的形 式來顯示),大量的信息是以 Unicode 的方式顯示的,這很不利於我們讀取和驗證。所以我們必須借助於一 種靈活方便的工具通過解碼來實現各種語言文字的顯示。我們設計的這個基於 Eclipse 平台上 plug-in,就 能夠輕松實現這個需要。
技術背景 : 基於 Java 的 Eclipse plugin 開發概述
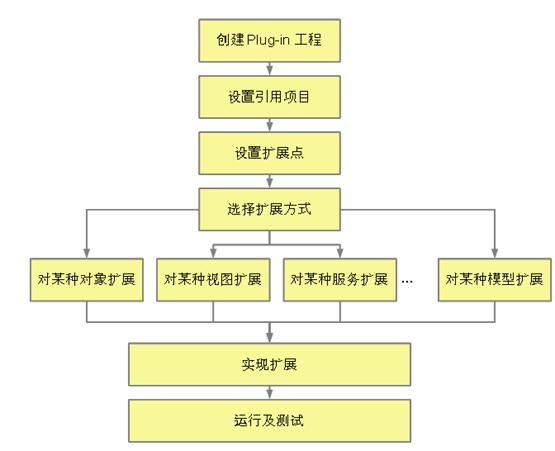
Eclipse 最有 魅力的地方就是它的插件體系結構。在這個體系中最基本的概念是擴展點(extension points),即為插件提 供的接口。每一個插件都是在現有的擴展點上進行開發,並可能還留有自己的擴展點,以便在這個插件上做繼 續的開發。由於有了插件,Eclipse 系統的核心部分在啟動的時候要完成的工作比較簡單,僅需要啟動平台的 基礎部分和查找系統的插件。在 Eclipse 中實現的絕大部分功能都是由相應的插件完成的。Eclipse 把很多 基本功能都做成了插件的形式。整個 Eclipse 體系結構就象一個大拼圖,可以不斷地向上加插件,同時,現 有插件上還可以再加些插件。這裡對通用的開發模式做了一個流程化的介紹,如下圖:
圖 1. 流程化 的開發模式
設計思路及代碼實現:plug-in 的解碼設計及代碼片段
plug -in 工程結構設計思路及代碼實現:
1. 對 Eclipse 的 TextEditor 中的 PopuMenu 進行擴展,添加菜單選項。
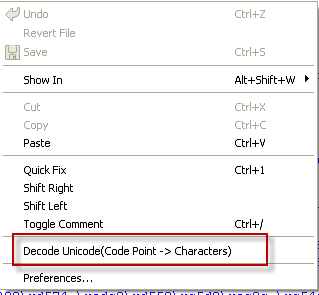
此工程中菜單選 項為“Decode Unicode(Code Point -> Characters)” 。該菜單選項添加為編輯器 TextEditor 的擴展, 對其他的編輯器(如 XMLEditor,JavaEditor 等)是不可見的。
在工程中打開一個文本文件,右鍵就 可以看到添加的菜單。
圖 2. 添加的菜單選項
2. 文件打開方式的選 擇。
從 Eclipse 打開的文件來源有工程外與工程中之分:
一是從工程中打開有兩種方式,一種是工程中直接找到 repository files 雙擊打開,另一種從工程中本 地的 workspace 中的文件。
二是從工程外打開文件的方式即工程外本地文件的打開方式(File->Open)。
圖 3. 打開 project 下的 repository 資源文件
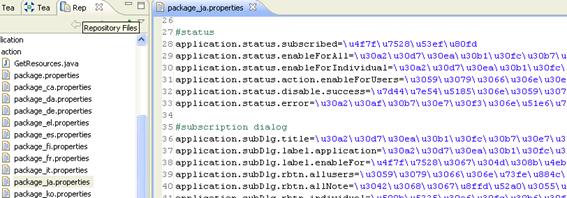
圖 4. 打開 Workspace 中文件
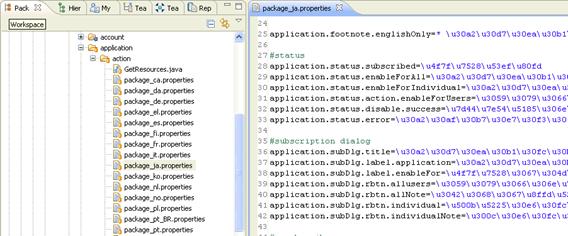
圖 5. 打開工程外本地文件
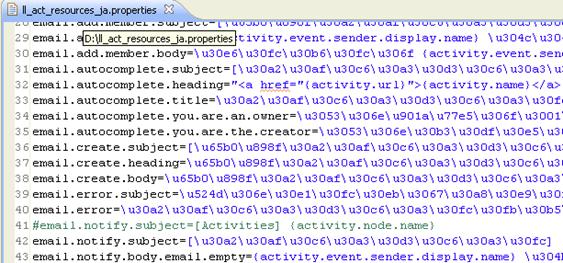
第一種方式,Eclipse 會使用 RemoteFileEditorInput 適配器來打開文件。我們可以通過 RemoteFileEditorInput 適配器得到遠程文件的讀入流。但是我們不能得到遠程文件的編碼方式,這裡同第三 種方式打開文件一樣,首先嘗試以工作區默認的編碼方式讀入,然後以本地系統默認的編碼方式讀入,最後嘗 試使用“UTF-8”來打開。如果仍然不能打開,提示用戶是不支持的編碼方式並要求用戶更改源文件的編碼方 式。
清單 1. 用 FileEditorInput 適配器來打開文件
// InputStream sourceFileIS; The input stream of source file
// String encodingType; The encoding type of
source file
if(targetEditor.getEditorInput() instanceof RemoteFileEditorInput){
RemoteFileEditorInput rf = (RemoteFileEditorInput)targetEditor.getEditorInput();
IInputStreamProvider isp =rf.getInputStreamProvider();
try {
sourceFileIS= isp.getInputStream(null);
encodingType = df.getEncoding();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
第二種方式,Eclipse 會使用 FileEditorInput 適配器來打開文件。我們可以通過 FileEditorInput 得到 IFile 對象從而獲得文件的編碼方式。再通過 IFile 對象的 getContents() 方法獲 得輸入流從而把源文件中的數據讀到數據緩存中。
清單 2. 用 FileEditorInput 適配器來打開文件
// InputStream sourceFileIS; The input stream of source file
// String encodingType; The encoding type of source file
else if (targetEditor.getEditorInput() instanceof FileEditorInput) {
FileEditorInput fei = (FileEditorInput) targetEditor.getEditorInput();
fileInWSpace = fei.getFile();
try {
sourceFileIS = fileInWSpace.getContents();
encodingType = fileInWSpace.getCharset();
} catch (CoreException e) {
// TODO Auto-generated catch block
e.printStackTrace();
第三種方式,Eclipse 會使用 FileStoreEditorInput 適配器來打 開文件。但是這個適配器不提供得到 IFile 對象的方法。只有從當前的 TextEditor 中得到本地文件的絕對 位置,然後以 JavaSE 中文件讀入流(java.io.FileInputStream)的方式的讀入文件。這種情況,我們無法 在讀入之前得到文件的編碼方式。那麼我們設定首先以 Eclipse 默認的編碼方式讀入這個流。如果出現不支 持的編碼方式異常(java.io.UnsupportedEncodingException), 就以當前系統默認的編碼方式讀入這個流 ,如果仍出現不支持的編碼方式異常就以“UTF-8”的編碼方式讀入這個流。最後如果仍然出現不支持的編碼 方式異常,則彈出對話框要求用戶更改源文件的編碼方式為 utf-8 後重試。
清單 3. 用 FileStoreEditorInput 適配器來打開文件
// InputStream sourceFileIS; The input
stream of source file
// String encodingType; The encoding type of source file
// DefaultEncodingSupport df = new DefaultEncodingSupport();
else if(targetEditor.getEditorInput()instanceofFileStoreEditorInput) {
try{
sourceFileIS =newFileInputStream(fileOutFromWSpace);
encodingType = df.getEncoding();
}catch(FileNotFoundException e) {
//TODOAuto-generated catch block
e.printStackTrace();
}
}
解碼設計思路及代碼實現
1. 讀取源文件:以文件流的方式讀取源文件,獲得源 文件中的數據到數據緩存中。
清單 4. 獲取源文件中數據
// InputStream sourceFileIS; The input stream of source file // String encodingType; The encoding type of source file InputStreamReader reader = new InputStreamReader(soureFileIS, encodingType);
2. 獲取數據:從緩存中按行讀取數據,然後以“\u”作為標簽把整行數據分割成一個字符串數 組。如下顯示:
email.create.subject=\uc0c8 \ud65c\ub3d9 {0}\uc744(\ub97c)
\uc791\uc131\ud588\uc2b5\ub2c8\ub2e4.
========> s[0] =" email.create.subject=", s[1] ="c0c8", s[2] ="d65c", s[3]="ub3d9 {0}",
s[4]="c744(", s[5] = "b97c)", s[6]="c791", s[7] ="c131", s[8] ="d588", s[9]="c2b5",
s[10]="b2c8", s[11]="b2e4."
清單 5. 從緩存中按行讀取數據
BufferedReader in = new BufferedReader(reader);
while ((line = in.readLine()) != null) {
sbf.append(decodeLine(line));
//sbf A string buffer to store the data source temporary
sbf.append("\r\n");
}
3. 解碼:對字符串數組的每個元素(第一個元素,也就是下標為 0 的元素除外。該元素不包含 需要處理的碼)中的前四個字符(一個十六進制的碼)進行解碼處理,該數組元素的其他的字符不變。
例如 s[4]="c744(" 是由“c744(” 這 5 個字符組成。 前四個為一個 16 進制的碼。所以暫時保存第 5 個字符,然後將前四個解碼成一個字符“?”。
清單 6. 對前四個字符解碼處理
/**
* decode the data source from Unicode to string
* @param sourceCharArray Unicode as char array
* @param encodingType the data source encode type
* @return the string after decode
*/
public staticString Decode2String(char[] sourceCharArray,
String encodingType) {
CharsetProvider provider =newCharsetProviderICU();
Charset charset;
CharsetDecoder decoder;
char[] c = sourceCharArray;
ByteBuffer bbf = ByteBuffer.allocate(4 * c.length);
CharBuffer cbf = CharBuffer.allocate(c.length / 2);
StringBuffer sb =newStringBuffer("");
for(inti = 0; i < c.length; i++) {
bbf.put(i, (byte) c[i]);
}
charset = provider.charsetForName(encodingType);
decoder = charset.newDecoder();
decoder.decode(bbf, cbf,true);
char[] cc = cbf.array();
for(inti = 0; i < cc.length; i++) {
sb.append(cc[i]);
}
returnsb.toString();
}
4. 組合替換:等到每個數組元素中的前四個字符解碼完成後與剩余的進行組合 ,形成新的字符串替換 原數組元素。
s[4] 中重新組合解碼後的字符“?”與 s[4] 中的第五個字符“ (”形成新的 s[4] =“?(”。其他數組元素的處理方式類似。
處理所有的字符串元素然後重新組合成 新的一行數據放入緩存。以同樣的方法處理其他行的數據後,組合成新的數據源顯示到界面上。
清單 7. 最後處理
// s[i] is the element of the string array witch create from spilt the data
source by "\u"
// String[] sStr = new String[s[i].length() - 3];
// sStr is used for store the result temporary
for (int j = 4; j < s[i].length(); j++) {
sStr[j - 3] = s[i].substring(j, j + 1);
}
for (int k = 0; k < sStr.length; k++) {
sb.append(sStr[k]); }
s[i] = sb.toString();
配置及使用方法:在 Eclipse 中的配置步驟及 RTC 中的使用舉例
代碼下載
參考本文最後的下載。
Plug-in 在 Eclipse 中的使用配置
找到您把安裝的 RTC 的 Eclipse 平台的路徑,如“D:\software\RTC-Client-Win-3.0.1\jazz\client\eclipse”把上述代碼 jar 文 件放入 plugins 文件夾中。啟動 RTC,如果您已經打開 RTC,請重啟 RTC。
不同數據的來源在 RTC 中使用舉例
第一種方式:用 repository workspace 中 文件顯示解碼
第一步:找到所需解碼的文件
同圖 2:OpenRepositoryFile.png
第二步 :打開文件,右擊文件空白處,在菜單中選擇“Decode Unicode(Code Point -> Characters)”
圖 6. 右擊文件空白的菜單
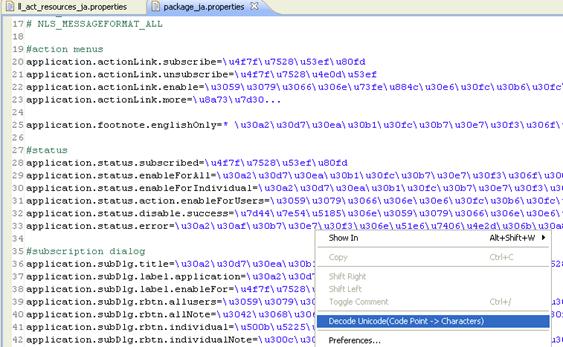
DecodeFileMenu.png
第 三步:查看解碼後的文件
圖 7. 查看解碼後的文件
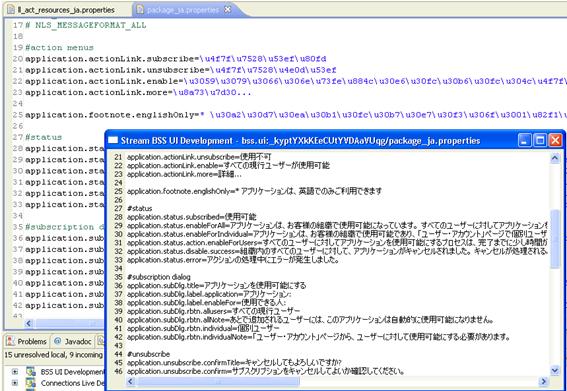
DecodeFileShow.png
第 二種方式及第三種方式:直接在 RTC 中打開本地文件。步驟與第一種方式非常相似,這裡就不再贅述。
結束語
在這篇文章中,我們了解到如何通過開發基於 Java 的 Eclipse plug-in 來實現 TVT 測試過程中的實際問題 – 在 RTC 中自動實現解碼來顯示翻譯的文字。這不僅提高了翻譯驗證測試的工作效 率,也是一次對現有測試工具的開發和擴展的努力和嘗試。我們期望能有更多的開發和測試人員加入其中,一 同開發更多更高效的插件,通過不斷增強和擴展現有的測試框架,使我們能借助這些工具高效而輕松地完成測 試任務。
下載
com.ibm.gvt.deco_1.0.0.jar