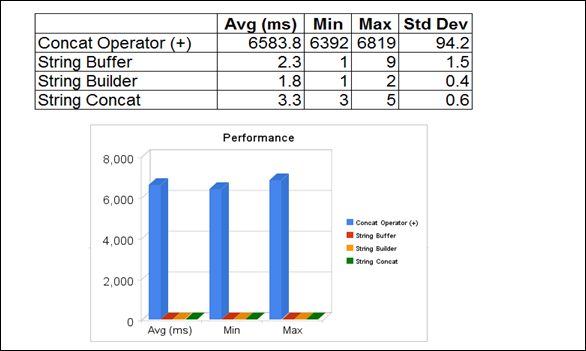
ivy中引入了一些自己的概念,了解並理會這些概念對ivy的學習使用是有幫助的。這裡翻譯一下官網的介紹ivy主要概念的文章,原文 在此:http://ant.apache.org/ivy/history/2.1.0-rc1/concept.html
因內容太長而拆分,下面是第二部分:
六. 沖突管理器
沖突管理器可以在沖突的模塊修訂本列表中選擇需要保留的修訂本。
如果修訂本對應相同的模塊,舉例說相同的組織/模塊名對,那麼稱為沖突的修訂本列表。
可用的沖突管理器列表在可以沖突管理器頁面可以得到。
想得到更多如果配置沖突管理器的細節,請看ivy文件參考的沖突章節。
七. Pattern matcher 模式匹配
從1.3之後在很多地方ivy使用模式來匹配一系列對象。例如,當通過使用匹配所有想排除的模塊的模式來聲明一個依賴時,你可以立即 排除這多個模塊。
ivy使用可插入式的模式匹配器來匹配哪些對象名。默認定義好的有3個:
* exact
This matcher matches only string when they are equal to the pattern one
這個匹配器僅匹配字符串,要求和模式相同。
* regexp
這個匹配器容許你使用java1.4或者更高版本的Pattern類支持的正則表達式
* glob
這個匹配器容許你使用unix風格的glob匹配器,僅有的能使用的字符是匹配任何字符串的*和精確匹配單個字符的?。注意僅僅當 jakarta oro2.0.8在classpath中時這個匹配器才可以使用。
同樣請注意,在任何匹配器中,字符'*'有匹配任意東西的特殊含義。對於不依賴匹配器的默認值尤其有用。
八. 附加屬性
從1.4版本之後在ivy的xml文件中有幾個標簽是可以通過被稱為附加屬性的東西來進行擴展。想法很簡單:如果你需要更多信息來定義 你的模塊,你可以添加你需要的屬性,然後能夠像訪問其他屬性一樣訪問它,比如在你的模式中。
從2.0版本之後,可以並且推薦為你的附加屬性使用xml命名空間。使用ivy附加命名空間是最簡單的添加你自己的附件屬性的方法。
例如:
這裡是一個ivy文件,屬性'color'設置為blue:
<ivy-module version="2.0" xmlns:e="http://ant.apache.org/ivy/extra">
<info organisation="apache"
module="foo"
e:color="blue"
status="integration"
revision="1.59"
/>
</ivy-module>
這樣當你定義一個基於foo的依賴時你就必須使用附加屬性。那些附加屬性 被作為標識符實際使用,類似org,name和revision。
<dependency org="apache" name="foo" e:color="blue" rev="1.5+" />
你還可以這樣定義你的倉庫模式:
${repository.dir}/[organisation]/[module]/[color]/[revision]/[artifact].[ext]
注意在模式中科你必須使用非限定屬性名(不帶命名空間前綴)
如果你不想使用xml命名空間,這是可以做到的,但是你需要使ivy文件驗證失效,因為你的文件不再符合任何正式的ivy xsd。查看設 置文檔來得知如何使驗證失效。
九. 校驗和
從1.4版本後,ivy容許使用校驗和,被稱為digester,來驗證下載文件的正確性。
目前ivy支持MD5和sha1算法。
使用MD5還是sha1的配置可以是全局的,或者是由依賴解析器設置。全局是使用變量ivy.checksums來列舉要進行的檢測(僅支持md5和 sha1),在每個解析器上你可以使用屬性
checksums來覆蓋全局設置。
設置是逗號分隔的使用的校驗和算法。
在檢測過程中(下載的時候),找到的第一個校驗和將被檢測,然後就結束。這意外著如果你設置為"sha1, md5",那麼如果ivy發現了一 個sha1文件,它將使用這個sha1來比較下載文件的sha1,並且如果比較是通過的,ivy將認為這個文件是正確的。如果沒有發現sha1文件, ivy將查找md5文件。如果沒有發現任何一個,將不進行檢測。
在發布過程中,任何例舉出來的校驗和算法都將被計算和上傳。
默認的校驗和算法是"sha1, md5"。
如果你想修改這個默認值,你可以設置變量ivy.checksums。因此想使校驗和驗證失效,你僅僅需要設置ivy.checksums為""。
十. 事件和觸發器
從1.4版本之後,當ivy完成依賴的解析和一些其他任務,ivy將在最重要的步驟前後發出事件。你可以使用ivy的api來監聽這些事件, 或者你甚至可以注冊一個觸發器在特定事件發生時來執行特定的動作。
這是尤其強大而靈活的特性,例如它容許在依賴解析前執行依賴的構建,或者在依賴解析過程中精確地追蹤發生的事情。
更多關於時間和觸發器的細節,請看本文檔的配置章節中的觸發器文檔頁面。
十一. 循環依賴
從1.4版本之後,循環依賴可以是直接或者間接。例如,如果A依賴A,這是循環依賴,如果A依賴B而B依賴A,這也是循環依賴。
在ivy1.4之前循環依賴會導致viy產生錯誤。到ivy1.4止,當ivy發現循環依賴時的行為可以通過循環依賴策略來配置。
3個內建的策略可用:
* ignore/忽略
循環依賴僅僅用詳細的信息警告進行標志。
* warn / 警告
和忽略相同,除非它們被標識為警告(默認)
* error / 錯誤
發現循環依賴時終止依賴解析
查看配置頁面來看如果配置你想使用的循環依賴策略。
十二. 緩存和變更管理
ivy非常依賴本地緩存來避免過於頻繁的訪問遠程倉庫,從而節約網絡帶寬和時間。
1) 緩存類型
ivy緩存由兩個不同部分組成:
* 倉庫緩存
倉庫緩存是ivy保存從模塊倉庫下載的數據的地方,和一些關系到這些制品的元信息在一起,和他們的原始位置一樣。
* 解析緩存
這個部分的緩存用來保存被ivy用來重用解析過程的結果的解析數據。
這個部分的緩存每次完成一次新的解析時都被覆蓋,並且決不能被多進程同時使用。
通常只有一個解析緩存,但是你可以定義多個倉庫緩存,每個解析器可以使用單獨的緩存。
2) 變更管理
為了加快依賴解析和緩存使用的方法,ivy默認認為修訂本從不修改。因此一旦ivy在它的緩存中有這個模塊(元數據或者制品),ivy信 任緩存,甚至不再查詢倉庫。大多數情況下這個優化時非常有用的,並且只要你遵循這個規范就不會引起問題: 修訂本從不變更。除性能 之外,還有幾個好的原因來遵循這個原則。
無論如何,取決於你當前的構建系統和你的依賴管理策略,你可能更願意更新你的模塊。有兩種變更需要考慮:
2.1) 模塊元數據變更
模塊提供者不考慮經常優化模塊元數據,他們更多的關注他們的api或者行為(如果他們甚至提供模塊元數據)。我們不喜歡的事情經常 發生:我們不得不更新模塊元數據,一個依賴被遺忘了,或者另一個丟失了......
在這種情況下,在你的依賴解析器上設置checkModified為"true"將是一個解決方案。這個標記告訴ivy需要檢查模塊的元數據相比較緩 存是否被修改. ivy首先檢查倉庫中元數據的最後修改時間以決定只在必要時下載它,同樣只在需要時更新它。
2.2) 制品變更
一些用戶,尤其是從maven2過來的用戶,喜歡使用一個特別的修訂版本來處理經常變更的模塊。在maven2中這個通常被稱為SNAPSHOT( 快照) 版本,並且有一種主張認為這樣可以幫助節約空間,因為只需要為開發時可能創建的大量的中間產物保留一個修訂版本。
ivy使用"changing revision"的概念來支持這種方法。changing revision就是這樣:一個ivy認為隨著時間推移始終可能變更的修訂版 本.為了處理這個,可以通過使用以來標簽明確指定一個依賴為可以變更,或者在解析器上使用changingPattern 和changingMatcher 屬性 來知名那個修訂版本或者修訂版本組可以被認為是變更的。
一旦ivy知道一個修訂版本是變更的,它將遵循這樣的原則來避免過於頻繁的檢查倉庫:如果模塊的元數據沒有修改,它將認為整個模 塊(包括制品)沒有修改。即使如果模塊描述符文件已經修改,它將檢查模塊的發行數據來看這個是不是同一個修訂版本的一個新的發行。 然後如果發行數據被修改了,它將檢查制品的最後修改時間戳,並相應的下載它們。
因此如果你想使用變更修訂版本,使用發布任務來發布你的模塊,請小心更新發布數據,然後一切都會工作的很好。並且記住也要將你 的解析器設置checkModified=true"。
十三. 路徑處理
作為一個依賴管理器,ivy有一系列的文件相關操作,大部分使用路徑或者路徑模式來在文件系統上定位文件。
這些路徑可以明確是的相對路徑或者絕對路徑。我們推薦經常使用絕對路徑,這樣你不必擔心你的相對路徑的基准路徑是什麼。ivy提 供一些變量,可以被用來作為你的絕對路徑的基准路徑。例如,ivy有基准路徑的概念,這個基本和ant一致。你可以使用變量ivy.basedir 來訪問這個基准目錄。因此如果你有類似這樣的路徑:
${ivy.basedir}/ivy.xml
你就得到了一個絕對路徑。在設置文件中,你同樣有一個名為ivy.settings.dir的變量指向你的設置文件所在的目錄,這使得定義和這 個目錄相關的路徑變得非常容易。
如果你真的想使用相對路徑,被用於實際定位文件的基准路徑取決於相對路徑在哪裡被定義:
* 在ivy文件中,路徑是相對於ivy文件自身(在ivy文件中唯一可能的路徑是用於配置包含申明)。
* 在設置文件中,用於文件包含的路徑(也就是屬性文件裝載和設置文件包含)是相對於設置文件所在的目錄。所有其他路徑除非明確記 錄否則必須是絕對路徑。
* 在ivy的ant任務和ivy參數或選項中,路徑是相對於ivy基准路徑的,當在ant中調用時這個路徑就是ant的basedir路徑一致。