垃圾回收的瓶頸
傳統分代垃圾回收方式,已經在一定程度上把垃圾回收給應用帶來的負擔降到了最小,把應用的吞吐量推到了一個極限。但是他無法解 決的一個問題,就是Full GC所帶來的應用暫停。在一些對實時性要求很高的應用場景下,GC暫停所帶來的請求堆積和請求失敗是無法接受 的。這類應用可能要求請求的返回時間在幾百甚至幾十毫秒以內,如果分代垃圾回收方式要達到這個指標,只能把最大堆的設置限制在一個 相對較小范圍內,但是這樣有限制了應用本身的處理能力,同樣也是不可接收的。
分代垃圾回收方式確實也考慮了實時性要求而提供了並發回收器,支持最大暫停時間的設置,但是受限於分代垃圾回收的內存劃分模型 ,其效果也不是很理想。
為了達到實時性的要求(其實Java語言最初的設計也是在嵌入式系統上的),一種新垃圾回收方式呼之欲出,它既支持短的暫停時間, 又支持大的內存空間分配。可以很好的解決傳統分代方式帶來的問題。
增量收集的演進
增量收集的方式在理論上可以解決傳統分代方式帶來的問題。增量收集把對堆空間劃分成一系列內存塊,使用時,先使用其中一部分( 不會全部用完),垃圾收集時把之前用掉的部分中的存活對象再放到後面沒有用的空間中,這樣可以實現一直邊使用邊收集的效果,避免了 傳統分代方式整個使用完了再暫停的回收的情況。
當然,傳統分代收集方式也提供了並發收集,但是他有一個很致命的地方,就是把整個堆做為一個內存塊,這樣一方面會造成碎片(無 法壓縮),另一方面他的每次收集都是對整個堆的收集,無法進行選擇,在暫停時間的控制上還是很弱。而增量方式,通過內存空間的分塊 ,恰恰可以解決上面問題。
Garbage Firest(G1)
這部分的內容主要參考這裡,這篇文章算是對G1算法論文的解讀。我也沒加什麼東西了。
目標
從設計目標看G1完全是為了大型應用而准備的。
支持很大的堆
高吞吐量
--支持多CPU和垃圾回收線程
--在主線程暫停的情況下,使用並行收集
--在主線程運行的情況下,使用並發收集
實時目標:可配置在N毫秒內最多只占用M毫秒的時間進行垃圾回收
當然G1要達到實時性的要求,相對傳統的分代回收算法,在性能上會有一些損失。
算法詳解
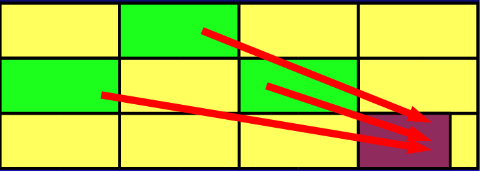
G1可謂博采眾家之長,力求到達一種完美。他吸取了增量收集優點,把整個堆劃分為一個一個等大小的區域(region)。內存的回收和 劃分都以 region為單位;同時,他也吸取了CMS的特點,把這個垃圾回收過程分為幾個階段,分散一個垃圾回收過程;而且,G1也認同分代 垃圾回收的思想,認為不同對象的生命周期不同,可以采取不同收集方式,因此,它也支持分代的垃圾回收。為了達到對回收時間的可預計 性,G1在掃描了region以後,對其中的活躍對象的大小進行排序,首先會收集那些活躍對象小的region,以便快速回收空間(要復制的活躍 對象少了),因為活躍對象小,裡面可以認為多數都是垃圾,所以這種方式被稱為Garbage First(G1)的垃圾回收算法,即:垃圾優先的 回收。
回收步驟:
初始標記(Initial Marking)
G1對於每個region都保存了兩個標識用的bitmap,一個為previous marking bitmap,一個為next marking bitmap,bitmap中包含了一 個bit的地址信息來指向對象的起始點。
開始Initial Marking之前,首先並發的清空next marking bitmap,然後停止所有應用線程,並掃描標識出每個region中root可直接訪 問到的對象,將region中top的值放入next top at mark start(TAMS)中,之後恢復所有應用線程。
觸發這個步驟執行的條件為:
G1定義了一個JVM Heap大小的百分比的閥值,稱為h,另外還有一個H,H的值為(1-h)*Heap Size,目前這個h的值是固定的,後續G1也許 會將其改為動態的,根據jvm的運行情況來動態的調整,在分代方式下,G1還定義了一個u以及soft limit,soft limit的值為H-u*Heap Size,當Heap中使用的內存超過了soft limit值時,就會在一次clean up執行完畢後在應用允許的GC暫停時間范圍內盡快的執行此步驟;
在pure方式下,G1將marking與clean up組成一個環,以便clean up能充分的使用marking的信息,當clean up開始回收時,首先回收能 夠帶來最多內存空間的regions,當經過多次的clean up,回收到沒多少空間的regions時,G1重新初始化一個新的marking與clean up構成 的環。
並發標記(Concurrent Marking)
按照之前Initial Marking掃描到的對象進行遍歷,以識別這些對象的下層對象的活躍狀態,對於在此期間應用線程並發修改的對象的以 來關系則記錄到remembered set logs中,新創建的對象則放入比top值更高的地址區間中,這些新創建的對象默認狀態即為活躍的,同時修 改top值。
最終標記暫停(Final Marking Pause)
當應用線程的remembered set logs未滿時,是不會放入filled RS buffers中的,在這樣的情況下,這些remebered set logs中記錄的 card的修改就會被更新了,因此需要這一步,這一步要做的就是把應用線程中存在的remembered set logs的內容進行處理,並相應的修改 remembered sets,這一步需要暫停應用,並行的運行。
存活對象計算及清除(Live Data Counting and Cleanup)
值得注意的是,在G1中,並不是說Final Marking Pause執行完了,就肯定執行Cleanup這步的,由於這步需要暫停應用,G1為了能夠達 到准實時的要求,需要根據用戶指定的最大的GC造成的暫停時間來合理的規劃什麼時候執行Cleanup,另外還有幾種情況也是會觸發這個步 驟的執行的:
G1采用的是復制方法來進行收集,必須保證每次的”to space”的空間都是夠的,因此G1采取的策略是當已經使用的內存空間達到了H時 ,就執行Cleanup這個步驟;
對於full-young和partially-young的分代模式的G1而言,則還有情況會觸發Cleanup的執行,full-young模式下,G1根據應用可接受的 暫停時間、回收young regions需要消耗的時間來估算出一個yound regions的數量值,當JVM中分配對象的young regions的數量達到此值時 ,Cleanup就會執行;partially-young模式下,則會盡量頻繁的在應用可接受的暫停時間范圍內執行Cleanup,並最大限度的去執行non- young regions的Cleanup。
展望
以後JVM的調優或許跟多需要針對G1算法進行調優了。