Java 的普及和廣泛應用,以及其基於虛擬機運行的機制,使得性能問題越來越重要。本文從 Java 虛擬機的角度,特別是垃圾回收機制來剖析了 Java 應用程序設計需要注意的方面,並總結出了幾條非常容易被忽視的設計、編寫代碼的原則和習慣。最後通過實例來介紹幾種主要的 Java Profiler 工具對我們進行開發和分析的幫助。本文要求讀者具有一定的 Java 虛擬機的基礎知識,一定的 Java 設計模式和開發經驗。通過閱讀本文,讀者能從 Java 運行的本質上對性能方面有一個很好的把握,在設計和編碼的過程中,遵循文中總結的原則和習慣,對於提高性能、可維護性、可擴展性很有幫助。同時讓讀者了解利用 profiler 工具來分析 Java 程序的性能。
開始之前
Java 平台已無處不在,Java EE、Java SE、Java ME 和 Java Card,Java 的發展為無數程序員提供了工作機會,都是“Java”,然而除了基本的 Java 語法大都一致外,程序員必須基於不同的平台有不同的考慮,學習不同平台的特點:
不同平台的環境
Java EE 所運行的硬件服務器、操作系統,Java SE 所在 PC 機的體系結構(X86/X64、MAC、SPARC 等),Java ME 所運行的手機或移動設備,Java Card 所在的智能卡芯片類型等;
不同平台虛擬機的特點
如是否支持多線程(這似乎是毋庸置疑,但是在 Java Card 平台上,由於計算資源相當有限,多線程目前還不被支持),Java EE 和 Java SE 的虛擬機特性幾乎相同,而 Java ME 虛擬機(KVM)根據移動設備的特點進行裁剪和優化,以適應於有限的物理內存和存儲空間,而根據設備處理能力的強弱還分為 CDC(Connected Device Configuration,聯網設備配置)和 CLDC(Connected Limited Device Configuration,聯網受限設備配置),更小設備和智能卡的虛擬機 JCVM(Java Card VM)更是裁剪了許多特性,如多線程、許多復雜數據類型的支持、主動的垃圾收集機制等,這甚至導致了對 Java 語法集的裁剪;
不同平台的 API 和可用的第三方庫
Java EE 和 Java SE 是超集與子集的關系,因為她們所處的計算機平台和操作系統目前很好的兼容,而 Java ME 和 Java Card 與 EE 和 SE 是 Totally different,除了 java.lang.*,部分 java.io.* 等核心類庫保留外,其他的 API 和類庫完全不同。java.microedition.* 和 javax.microedition.* 表明這是 ME 平台,javacard.* 表明這是 Java Card 平台。同時,由於 EE 和 SE 平台的普及程度和開發者人數,使得之上的第三方庫十分海量。深入了解和掌握平台的 API 和庫是不同平台程序員進階的必由之路。
從這個角度上說,Java 在不同的平台之間,並不是“一次編寫、處處運行”,考慮應用程序的設計和優化的時候,首先要看是在什麼平台上,因為源於以上不同的特點,編程模型、設計模式,甚至語言集都不盡相同。在這裡我們著重考慮 Java EE 和 SE 的視角,但有很多設計、編程原則和習慣對於所有平台的程序員來說,都適用。
Java 虛擬機
Java 虛擬機是支持 Java 語言運行的基礎,避開過多的 JVM 和實現的技術細節,我們對基礎架構進行了解,是進行應用程序優化必不可少的。如下圖所示:
圖 1. Java 虛擬機體系結構
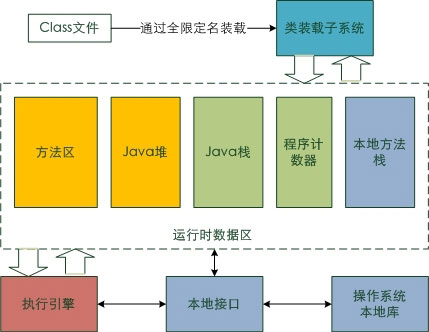
類裝載子系統:通過類的全限定名(包名和類名,網絡裝載還包括 URL)將 Class 裝載進運行時數據區;
方法區:Class 對於所有方法和 static 靜態數據的定義存儲在這裡,它就像一張表或數組,讓程序執行時在這裡找到相應方法的 Java 字節碼和靜態數據;
Java 堆:Java 對象的持久化存儲區,從類實例化而來的對象存儲在此,垃圾收集也在此進行,若是空間不夠容納當前所有對象,Out Of Memory 的異常將會拋出,對 Java 堆和垃圾收集的認識對應用性能調優很關鍵;
Java 棧:Java 方法的字節碼執行的地方,方法中局部變量的生命周期都在棧中,棧的大小是我們要考慮的一個關鍵點,它直接決定了方法調用的層數,這對遞歸程序來說尤為重要。我們所用的 JVM 都是基於 Java 棧的運行機制,而有一個例外的實現,Google 移動設備操作系統 Android 的虛擬機 Dalvik 則是基於寄存器的機制(Dalvik 雖然支持 Java 語言開發,但從虛擬機的角度看,並不符合 Java 標准),關於虛擬機實現時,棧和寄存器機制的比較,請參考論文“Virtual Machine Showdown: Stack Versus Registers”;
程序計數器:對於基於棧實現的 JVM,這幾乎是唯一寄存器了,它用來指示當前 Java 執行引擎執行到哪條 Java 字節碼,指針指向方法區的字節碼;
本地方法棧:這是 Java 調用操作系統本地庫的地方,用來實現 JNI(Java Native Interface,Java 本地接口);
執行引擎:JVM 的心髒,控制裝入 Java 字節碼並解析;
本地接口:連接了本地方法棧和操作系統庫。
Java 字節碼是 JVM 的指令,所有 Java 平台虛擬機有各自的指令集,而大部分指令相同,共 200 條左右,Java Card 虛擬機由於支持的數據類型少,相應的指令較少。部分虛擬機實現商為了優化性能,增加了一些自己特有的指令,當對於 Java 程序員來說,是透明的。下面是一段 Java 方法的字節碼示例:
清單 1. Java 字節碼例
/* 0x000092c4:0x04a7: */ _SCONST_0,
/* 0x000092c5:0x04a8: */ _SCONST_0,
/* 0x000092c6:0x04a9: */ _INVOKESTATIC, HIGH(0x08e8), LOW(0x08e8),
/* 0x000092c9:0x04ac: */ _POP,
/* 0x000092ca:0x04ad: */ _INVOKESTATIC, HIGH(0x8046), LOW(0x8046),
/* 0x000092cd:0x04b0: */ _IFEQ, 84,
/* 0x000092cf:0x04b2: */ _INVOKESTATIC, HIGH(0x8044), LOW(0x8044),
/* 0x000092d2:0x04b5: */ _GOTO, 79,
/* 0x000092d4:0x04b7: */ _ASTORE, 7,
當程序計數器中值為 0x000092ca:0x04ad,表明下一條即將執行字節碼為 _INVOKESTATIC, HIGH(0x8046), LOW(0x8046),該字節碼表明將調用某個靜態方法。
Java 語言一大好處就是不用關心對於內存的分配和回收,一切由垃圾收集器搞定。然而這並不代表 Java 程序員可以高枕無憂,再高效的收集器也可能因為濫用而導致性能問題。我們已經知道,Java 程序所涉及的空間分配和回收包括:
Java 堆,創建的 Java 對象(包括數組,數組也是一種對象)分配在堆中,垃圾收集對象來釋放空間;
Java 棧,棧劃分為操作數棧、棧幀數據和局部變量區,方法中分配的局部變量在棧中,同時每一次方法的調用都會在棧中分配棧幀,因此程序員在設計和開發應用時需考慮調用層數。
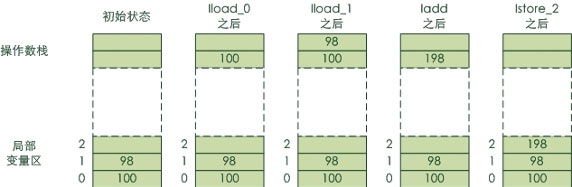
來看一段字節碼在 Java 棧中的執行示例,100 與 98 相加:
清單 2. 整數加法運算的 Java 字節碼
iload_0 // 載入局部變量 0,整型,壓入棧中
iload_1 // 載入局部變量 1,整型,壓入棧中
iadd // 彈出兩個整型數,相加,將結果壓入棧
istore_2 // 彈出整型數,存入局部變量 2
圖 2. 整數加法運算 Java 棧行為
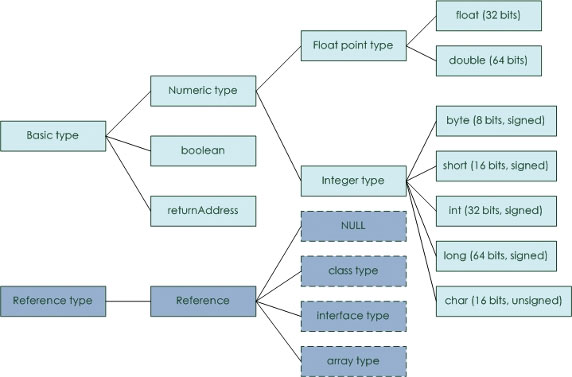
此外,對於 JVM,還需了解支持的數據類型和它們占用的空間:
圖 3. Java 數據類型
按代垃圾收集機制
雖然各家 JVM 的實現(Sun Hotspot、IBM J9、Oracle JRockit 等)不同,但均采用了按代的垃圾收集機制。垃圾收集就是標識出虛擬機中不被用到的垃圾對象,刪除以回收空間。按代垃圾收集算法主要分為三種:
復制算法,空間被分為等大的兩塊,從根開始訪問每一個關聯的活躍對象,將空間 A 的活躍對象全部復制到空間 B,然後一次性回收整個空間 A,優點:只訪問活躍對象,將所有活動對象復制走之後就清空整個空間,不用去訪問死對象,所以遍歷空間的成本較小,缺點:需要巨大的復制成本和較多的內存;
標記清除算法,從根開始訪問所有活躍對象,標記為活躍對象。然後再遍歷一次整個內存區域,把所有沒有標記活躍的對象進行回收處理,優點:不需要額外的空間,缺點:較長的 GC 暫停時間,較大的掃描時間開銷,產生較多的空間碎片;
標記清除整理算法,綜合上兩種算法的優點,先標記活躍對象,然後將其合並成較大的內存塊。
代的劃分:
年輕代:新創建的對象分配在此,研究表明,大部分程序所產生的對象都在此消亡,幾乎所有的收集器為年輕代使用復制算法,年輕代又被劃分為 1 個伊甸園區和 2 個存活區用來實施復制算法;
年老代:從年輕代存活下來的對象被復制到年老代,主要實施標記清除或標記清除整理算法;
持久代:裝載的類數據和信息存儲於此,無可消亡對象。
Java 虛擬機都提供了相應的選項來設置各個代所占用區的大小,無論是 Java EE 的服務器應用,還是 Java SE 桌面應用或產品,都需要經過對運行時對象創建和消亡狀態的分析,進行這些選項的合理設置,才能獲得較好的性能提升,畢竟垃圾收集是一項耗時的工作。讀者可以進一步深入研究相關的虛擬機選項,為自己的應用程序設置優化的數值。
垃圾收集按頻率可分為:
次收集(Minor Collection):頻繁發生在年輕代,收集快速消亡的對象;
主收集(Major Collection):年輕代和年老代的全范圍收集,頻率很低。
垃圾收集運行時,同一個 CPU 上的所有其它線程都將會被阻塞,所以對於 Java 應用程序來說,整個世界似乎停滯了,當整個標記、清除、整理周期完成後,所有應用程序線程得以繼續,許多 JVM 實現的垃圾收集機制對多 CPU 的機器環境進行優化,通過同步來實現垃圾收集線程和應用程序線程的並發,使程序獲得很好的總體性能。
設置虛擬機參數
通過設置虛擬機參數來配置垃圾收集器的行為和堆中不同區的大小分配。不同虛擬機的實現,參數選項不盡相同。IBM J9 虛擬機在 IBM 的從移動設備到企業解決方案中廣泛的被使用,本文關於虛擬機選項參數的設定均基於 IBM 的 J9。
了解了垃圾收集以及它對性能的影響後,我們可以根據應用程序的特點來設置 GC 的策略進行有效的優化。相關參數是 -Xgcpolicy:[optthruput | optavgpause | gencon | subpool]
-Xgcpolicy:optthruput,針對吞吐量優化,這是虛擬機默認的 GC 策略,適用於兩種極端情況:應用需要盡可能快的在短時間內運行結束,或應用長時間運行,且運行過程中的吞吐量沒有比較固定的大小和分布;
-Xgcpolicy:optavgpause,針對 GC 導致的停頓優化,通過並發地執行一部分垃圾收集,在高吞吐量和短 GC 停頓之間進行折中。應用程序停頓的時間更短。適用於應用具有比較規則和突發的吞吐量周期分布;
-Xgcpolicy:gencon,分代並發進行 GC,以不同方式處理短期存活的對象和長期存活的對象。采用這種策略時,具有許多短期存活對象的應用程序會表現出更短的停頓時間,同時仍然產生很好的吞吐量;
-Xgcpolicy:subpool,子池優化,采用與默認策略相似的算法,但是采用一種比較適合多處理器計算機的分配策略。適用於在多核環境下運行的具有較高對象創建速率的多線程應用。
除了設置 GC 策略,最常設置的堆大小參數有:-Xms,設置堆的初始大小;-Xmx,設置堆空間的最大值;-Xmn,設置年輕代空間大小;-Xmo,設置年老代空間大小。程序員需要根據實際的機器環境和應用本身的特點來設置合理的值。
容易忽視的設計、編程原則和習慣
對虛擬機工作機制的了解能夠使我們有把握寫出更優雅、更高效的 Java 代碼。下面是幾條值得參考的設計、編程原則和習慣。
及時更新虛擬機。
除了由於某些產品兼容性的需要必須使用過去某個虛擬機版本外,建議將開發環境和最終產品部署的虛擬機運行時環境要求更新至最新版本。最新的版本意味著最新的 API,更好的實現優化。這一點對嵌入式 Java(Java ME 和 Java Card)並不適用,隨著移動或智能設備的發行,虛擬機就已經固化在其中,而新發布的虛擬機版本不能像在 EE 和 SE 安裝的服務器和 PC 機一樣,輕松進行安裝。部分移動設備可以通過更新固件和操作系統程序來實現 VM 的版本更新。
良好的面向對象設計和架構,應用設計模式。
這點對於 Java 應用的性能、重用和可維護性尤為重要,設計模式是由大師們總結出的解決典型問題的通用架構,用對象來描述問題域,用設計模式來組織對象之間的行為。在設計和解決局部問題時,首先要看看抽象出來的問題是否和某個設計模式的目標問題一致。此外,盡可能多的了解虛擬機所支持的 API,看所需的功能是否已有現成的實現可供調用,虛擬機平台實現的 API 大都具有良好的性能。
關心 Java 棧。
前面了解到,對於基於棧的 Java 虛擬機,方法的調用和執行伴隨著壓棧和出棧操作。每個線程有各自獨立的棧,由虛擬機來管理棧的大小,但我們應該對它的大小有個概念。棧的大小是把雙刃劍,如果太小,可能會導致棧溢出,特別是在該線程內有遞歸、大的循環時出現溢出的可能性更大,如果過大,就會影響到可創建棧的數量,如果是多線程的應用,就會導致內存溢出。通過 -Xss可以設置 Java 棧的最大值,默認值為 256K。不建議設置該選項為其他值,好的方案是,通過優化程序來減少遞歸層數、避免過大的循環、減少方法的調用層次,讓你的程序盡量“扁平”,用盡可能好的對象間的關系來取代少數對象間深層次的方法調用。
加強對象管理,不放任自流。
過分依賴垃圾收集有時候會出現嚴重的性能問題,特別對於在程序運行中伴隨著大量大對象創建的情況。好的習慣是顯式的釋放不用對象的引用,在下一垃圾收集周期中被回收,這一點常常被 Java 程序員忽視,遺留的引用會導致 GC 無法回收這些邏輯上消亡的對象,看下面代碼示例:
清單 3. Java 實現的棧
public class Stack {
private static final int MAXLEN = 10;
private Object stk[] = new Object[MAXLEN];
private int stkp = -1;
public void push(Object p) {
stk[++stkp] = p;
}
public Object pop1() {
return stk[stkp--];
}
public Object pop2() {
Object p = stk[stkp];
stk[stkp--] = null;
return p;
}
}
示例代碼是一個棧結構,棧中存儲對象引用,容量為 10,stkp 是棧頂指針,push 方法將對象壓入棧中,pop1 和 pop2 彈出棧頂對象。pop1 直接將對象彈出,該對象可能被其它對象使用之後立刻釋放,而棧中仍有指向該對象的引用,由於棧可能在程序中長久存在,所以導致彈出的對象不能被回收。 pop2 方法在彈出對象前,將棧原來持有的對象引用置空釋放,從而使彈出的對象徹底與棧脫離關系而不影響 GC。對於在程序運行中要大量創建和釋放的對象,加強管理是很好的習慣,使用對象池機制是很好的解決方案,根據需要在對象池中創建一批對象,將不用的對象放回池中,待下次取出使用,這也大大節省了對象的反復創建和銷毀時間。
清單 4. Java 對象池代碼
import java.util.HashMap;
import java.util.LinkedHashSet;
public class ObjectFactory {
/** A counter for counting the number of objects in use. */
private static int objInUse = 0;
/** A counter for counting the number of objects in pool. */
private static int objInPool = 0;
/** The object pool. */
private static HashMap objectPool = new HashMap();
/** The corresponding object pool for a specific class. */
private static LinkedHashSet subObjPool;
/** Generate object for use */
public synchronized static Object generate(String className) {
Object retObj = null;
subObjPool = (LinkedHashSet) objectPool.get(className);
if (subObjPool != null && subObjPool.size() < 0) {
retObj = subObjPool.iterator().next();
subObjPool.remove(retObj);
objInPool--;
} else {
try {
retObj = newObj(className);
} catch (InstantiationException ie) {
return null;
} catch (IllegalAccessException iae) {
return null;
} catch (ClassNotFoundException cnfe) {
return null;
}
}
objInUse++;
return retObj;
}
public synchronized static void drop(Object freeObject) {
if (freeObject != null) {
subObjPool = (LinkedHashSet) objectPool.get(className);
if (subObjPool == null) {
subObjPool = new LinkedHashSet();
objectPool.put(className, subObjPool);
}
if (!subObjPool.contains(freeObject)) {
subObjPool.add(freeObject);
objInPool++;
objInUse--;
}
}
}
/** Counts the number of objects which are in use now. */
public static int countObjectInUse() {
return objInUse;
}
/** Checks the current size of the object pool. */
public static int checkPoolSize() {
return objInPool;
}
/** New object for class name. */
private static Object newObj(String className)
throws InstantiationException, IllegalAccessException,
ClassNotFoundException {
Object obj = Class.forName(className).newInstance();
return obj;
}
}
Java Profiler 工具
Java Profiler 是采用 JMX(Java Management Extensions,Java 資源管理框架)或 JVMPI(Java Virtual Machine Profiler Interface,Java 虛擬機監視程序接口)實現的對 Java 虛擬機中的資源、應用程序對象等進行監試的一類工具。Profiler 工具主要可以監視對象分配和回收、堆空間、線程運行、線程死鎖、網絡狀態等。這為 Java 程序員進行性能分析提供了入手點,通過對程序運行時的狀態分析,可以快速的定位問題,從而著手優化。Java Profiler 工具是分析 Java 程序性能的好幫手,但歸根結底,性能的提高還依賴於程序員對 Java 虛擬機有一定了解,在此基礎上遵循良好的設計和開發原則。這也是 Java 程序員成為真正高手的必由之路。
關於如何使用 profiler 工具,讀者可參考相關資源進行深入研究,常用的 Java Profiler 工具有:
JConsole,虛擬機 SDK 自帶工具,安裝好 Java SDK 後,在 /bin 目錄下啟動;
Eclipse TPTP(Test and Performance Tools Platform)是由 Eclipse.org 頂級項目提供的一個測試與性能監測方面的工具插件;
Netbeans Profiler,Sun 內置於 Netbeans 中 profiler,方便用 Netbeans 開發時使用;
Visual VM,最初,Sun 隨 JDK 6 Update 7 發布的 profiler,Visual Vm 包含 JConsole,同時界面更加美觀且易於使用。
結束語
本文從 Java 虛擬機的視角出發,剖析了與 Java 應用程序性能相關的因素,通過總結的一些程序員容易忽視的設計、編程原則和習慣,希望對幫助廣大 Java 程序員提高性能優化意識和水平有所幫助。