使用分析模塊擴展 IBM Dump Analyzer for Java
編寫自己的分析程序
簡介:本系列的第一篇文章 介紹了 IBM Dump Analyzer for Java(或者Dump Analyzer)。您已經了 解了它的功能、如何獲取以及運行方式。在開始這篇文章之前,您應該溫習一下上一期的文章,確保您已 經完全理解了 Dump Analyzer 的工作原理。
Dump Analyzer 工具的一個關鍵方面是它具有可擴展 性。它是由一組分析模塊 組成,每個模塊負責對轉儲的一個特定方面進行分析,並幫助診斷特定類型的 問題。本文將逐步說明如何編寫新的分析模塊以及如何在 Dump Analyzer 內部運行它。
概述
Dump Analyzer 的構建基礎是 Diagnostic Tooling Framework for Java(DTFJ),後者是 IBM 的 Java 平台實現的一部分。如果您想要編寫一個 Dump Analyzer 分析模塊,您應當熟悉 DTFJ。
Dump Analyzer 工具的目標就是提供一種已經基本構建完成的環境,供特定的分析模塊在其中運 行。首先,JVM 必須已經生成了系統轉儲並且使用 jextract 工具進行了格式化。Dump Analyzer 首先選 擇一個合適的映像工廠(將讀取格式化後的轉儲),然後再讀取文件來創建描述內存內容的 DTFJ Image 對象。隨後為轉儲中的每個 Java 運行時構建獨立的分析上下文。最後,選擇一個特定分析模塊在這些上 下文中運行。
分析模塊在運行時會訪問全部的 Image,但它主要針對它所分析的特定 Java 運行 時進行訪問。此外,它將利用各種不同的工具來生成報告、報告進程和錯誤。也可以使用很多實用類來簡 化分析程序的編寫。隨著時間的推移,我們的團隊期望在編寫分析程序和分離有用基礎架構時能夠提供更 多的實用類。
您可能需要構建三種類型的分析模塊。第一種模塊將運行並得出關於所分析的運行 時內容的結論。結論類似於 “the JIT is active”、“there are deadlocks” 、“this dump was caused by an application error” 或 “this dump contains WebSphere® classes”。第二種類型生成一個報告描述有關 Image 內容的詳細信息。在嘗試診 斷應用程序故障時可以使用這些報告。當然,這些報告會包含有關潛在錯誤的警告消息並列出轉儲內容。 這兩種類型的模塊都應使用 Java 語言編寫,本文將使用術語分析程序(analyzer)指代任意類型的分析 模塊。
通常,第一種分析模塊得出的結論將由另一種分析模塊進一步進行檢查,嘗試診斷特定故障或提供推 薦操作。最後,您應該能夠生成類似如下內容的推薦操作:
如果轉儲是由保護故障引起……
……當前線程處於本地代碼中……
……當前的本地代碼位於包 com.acme 中……
……建議您聯系 ACME Industries 以做進一步分析。
這些類型的規則可以使用 Dump Analyzer 中附帶的腳本語言編寫。這種腳本代表了第三種類型的分析 模塊。Dump Analyzer 在設計時就考慮了簡單性並且沒有使用循環結構。在腳本內部,可以請求特定的分 析操作並輸出一些結論。這些腳本本身並沒有實際執行分析,而是將其他分析模塊在邏輯上鏈接起來。
設置
無需執行任何特殊設置編寫分析模塊;訪問需要的 JAR 文件即可。因此,本文假定您已經根據本系列 第一篇文章中的說明通過 ISA 下載並安裝了 Dump Analyzer。很多編程人員使用 IDE 進行開發。因此本 文也詳細說明了如何設置 Eclipse 環境,使用它開發分析模塊。當然,也可以使用其他的 IDE,但是本 文主要針對 Eclipse。
要在 Eclipse 中開發分析模塊,您需要執行以下操作:
下載並安裝 Eclipse。
創建一個新的 Java 項目。
將 dumpAnalyzer.jar 添加到項目類路徑。
將 DTFJ JAR 添加到項目類路徑。
可從 Eclipse 主頁中的下載鏈接找到 Eclipse 下載說明。安裝完成之後,切換到 Java Perspective (單擊 Window > Open Perspective > Java)。在這個透視圖中,按照以下步驟創建一個新的 Java 項目:
單擊 File > New > Project。
選擇 Java Project 並單擊 Next。
在出現的向 導中:
輸入 AnalysisModule 作為項目名。
確保選中 Create new project in workspace 。
確保選中 Project layout 區域的 Create separate folders for sources and class files 。
單擊 Finish。
需要將四個 JAR 文件放入 AnalysisModule 項目的類路徑:
dumpAnalyzer.jar(位於 installDir/plugins/com.ibm.java.diagnostics.dbda.isa_(version number)/WEB-INF/lib)
dtfj-interface.jar(位於 installDir/plugins/com.ibm.java.diagnostics.dbda.isa_(version number)/WEB-INF/lib/j9)
用於 Java 5.0 及以上版本的 dtfj.jar(位於 installDir/plugins/com.ibm.java.diagnostics.dbda.isa_(version number)/WEB-INF/lib/j9)
用於 Java 1.4.2 的 dtfj.jar(位於 installDir/plugins/com.ibm.java.diagnostics.dbda.isa_(version number)/WEB-INF/lib/sov)
在所有這些文件路徑中,installDir 表示 ISA 的安裝目錄。(例如,Microsoft® Windows® 中的 ISA v3.1 的默認路徑是 C:\Program Files\IBM\ISA and ESA\IBM Support Assistant)。要將這些 JAR 文件添加到 Eclipse 的類路徑中,執行以下操作:
右鍵單擊 AnalysisModule 項目。
單擊 (Java) Build Path > Configure Build Path。
在 Build Path 屬性的 Libraries 選項卡中選擇 Add External Jars。導航到上面所示的 4 個 JAR 文件, 將它們添加到構建路徑。
使用 Order and Export 選項卡以及 Up 和 Down 按鈕調整 JAR 的顯示順序,使其和上面的列表順序 一致。
單擊 OK 保存修改。
您應當在包內編寫分析模塊,要在 AnalysisModule 項目內創建包,執行以下操作:
右鍵單擊 AnalysisModule 項目。
單擊 New > Package。
在出現的向導中輸入 mypackage。
單擊 Finish。
現在,您已經為編寫分析模塊准備好了環境。
不同類型的分析程序
在開始編寫分析程序之前,您需要確定哪種類型的分析程序可以最好地滿足您的需求。正如 “概述” 一節介紹的一樣,這兩種不同類型的分析程序的功能分別是:
一種得出某些結論並報告該結論的分析程序;例如 “Is the JIT active?” 或 “Is this a WebSphere dump?”
一種報告在轉儲中查找到的信息的分析程序;例如,找到的地址空間數量、所有找到線程的堆棧信息 ,等等。
這兩種場景可以使用兩種不同接口表示:分別是 IAnalyze 和 IReport(有關這兩種接口的詳細信息 ,請參閱 “接口” 一節或查找 Dump Analyzer 附帶的 Javadoc 包)。
最後,您還需要了解一點,不論您需要編寫何種類型,分析程序還必須實現一個接口:IAnalyzerBase (同樣,參閱 “接口” 一節獲得更多信息)。該接口提供所有分析程序都具備的常用功能。Dump Analyzer 提供了一個抽象的 AnalyzerBase 類;它包含很多有用的方法,因此您應該擴展 AnalyzerBase 而不是直接實現 IAnalyzerBase。
以下小節將展示如何創建這兩種不同類型分析程序的示例。
實現 IAnalyze 的分析程序
在 Eclipse 中創建實現 IAnalyze 接口的分析模塊時,要使用 New Class 向導(右鍵單擊在 設置 一節 中創建的包並選擇 New > Class)。在出現的向導中,輸入以下信息:
Name:DWAnalyze
Superclass:使用 Browse 按鈕添加 com.ibm.dtfj.analyzer.base.AnalyzerBase
Interfaces:使用 Add 按鈕添加 com.ibm.dtfj.analyzer.ext.IAnalyze
單擊 Finish 即可使用 stub 方法創建 DWAnalyze 分析程序類。
要繼續該示例,輸入清單 1 所示的代碼。這個簡單的示例可以確定被分析的轉儲是否是在多處理器機 器上創建的。
清單 1. 實現 IAnalyze 的分析程序
package mypackage;
import com.ibm.dtfj.analyzer.base.AnalyzerBase;
import com.ibm.dtfj.analyzer.ext.IAnalyze;
import com.ibm.dtfj.image.DTFJException;
import com.ibm.dtfj.image.Image;
import com.ibm.util.SimpleVector;
/**
* This is the basic design required to implement an IAnalyze Interface
*/
public class DWAnalyze extends AnalyzerBase implements IAnalyze {
private static String description = "Check the number of processors";
/*
* This rule checks if the processor count is greater than 1
*/
private static String[] multiProcessorRules = {
"processorCount > 1 TRUE"
};
/**
* An analyzer to report if the dump was produced on a multiprocessor machine
*/
public DWAnalyze() {
defineRule("isMultiProcessor",multiProcessorRules);
}
/* (non-Javadoc)
* @see com.ibm.dtfj.analyzer.base.AnalyzerBase#getShortDescription()
*/
public String getShortDescription() {
return description;
}
/* (non-Javadoc)
* @see com.ibm.dtfj.analyzer.ext.IAnalyze#doAnalysis()
*/
public String[] doAnalysis() {
return checkProcessors(getContext().getCurrentImage());
}
/**
* This function uses the getProcessorCount() function from the Image class
* and then adds an entry into the ret[] array for parsing through the analysisRules[]
* array. The format for passing through the analysisRules needs to be of the type
* name=value
*/
private String[] checkProcessors(Image image) {
ret = null;
try {
int procNum = image.getProcessorCount();
ret = new String[1];
ret[0] = "processorCount=" + procNum;
} catch (DTFJException e) {
handleError("No processor information",e);
}
return ret;
}
}
從上面的示例可以看到,必須實現兩種方法: getShortDescription() 和 doAnalysis()。 doAnalysis() 方法的目的是從轉儲中提取信息並以名稱/值對的方式返回。這些信息將通過使用 AnalyzerBase(能夠處理一些簡單的分析規則)的默認行為進行進一步分析。針對名稱/值對集使用各個 規則並選擇一個特定的名稱對值進行檢驗。在清單 1 中,如果名稱為 processorCount 的一項的值大於 1,規則處理結果將為真(true)。
要查看分析模塊的運行,可跳至 “運行分析程序” 一節。
實現 IReport 的分析程序
在創建實現 IReport 接口的分析模塊時,可遵循上一節中介紹的新類創建步驟。但是,這一次應該在 New Class 向導中輸入以下信息:
Name:DWReport
Superclass:使用 Browse 按鈕添加 com.ibm.dtfj.analyzer.base.AnalyzerBase
Interfaces:使用 Add 按鈕添加 com.ibm.dtfj.analyzer.ext.IReport
清單 2 中的代碼演示了可以實現 IReport 接口的類。這個簡單的示例將輸出創建轉儲的機器的類型 。這個類沒有制定任何決策,它的惟一功能就是創建一個報告。將清單 2 中的內容輸入新創建的 DWReport 類中,以繼續本文的示例。
清單 2. 實現 IReport 的分析程序
package mypackage;
import com.ibm.dtfj.analyzer.base.AnalyzerBase;
import com.ibm.dtfj.analyzer.base.AnalyzerContext;
import com.ibm.dtfj.analyzer.ext.IAnalysisReport;
import com.ibm.dtfj.analyzer.ext.IAnalyzerContext;
import com.ibm.dtfj.analyzer.ext.IReport;
import com.ibm.dtfj.image.DTFJException;
import com.ibm.dtfj.image.Image;
/**
* This is the basic design required to implement an IReport Interface
*/
public class DWReport extends AnalyzerBase implements IReport {
private static String description = "DWReport example";
public DWReport() {}
/*
* (non-Javadoc)
* @see com.ibm.dtfj.analyzer.base.AnalyzerBase#getShortDescription()
*/
public String getShortDescription() {
return description;
}
/*
* (non-Javadoc)
* @see com.ibm.dtfj.analyzer.ext.IReport#produceReport()
*/
public IAnalysisReport produceReport() {
IAnalysisReport ret = allocateReport();
IAnalyzerContext ctx = getContext();
if (ctx instanceof AnalyzerContext) {
try {
Image p = ((AnalyzerContext)ctx).getCurrentImage();
ret.printLiteral("Image created on " + p.getSystemType());
} catch (DTFJException e) {
e.printStackTrace();
}
}
return ret;
}
}
從清單 2 中可以看出,必須實現兩個方法:getShortDescription() 和 produceReport()。 produceReport() 方法的目的是從轉儲中提取信息並以報告的方式返回,以便將其封裝到 IAnalysisReport 對象中供稍後使用。報告對象將被發送到一個格式化程序中進行格式化以供查看。在清 單 2 中,生成了一個簡單的報告,可確定創建轉儲的系統的類型。
現在已了解了如何構建一個分析程序,您需要知道如何使用它實際分析一個 Java 應用程序。
運行分析程序
有三種位置可以運行您的分析程序:在 IDE 內部、命令行和 IBM Support Assistant(ISA)。可以 單獨運行分析程序,也可以作為腳本的一部分運行(在 “SML:概述” 和 “使用 SML 將分析程序鏈接 起來” 兩節中會詳細介紹後一種方法)。
在 Eclipse 中運行分析程序
同樣,本文使用 Eclipse 演示分析模塊在 IDE 中的運行。在 Eclipse 內運行 Dump Analyzer 的最 簡便方法是運行 DumpAnalyzer.main() 方法並傳遞需要進行分析的轉儲的完全限定名。為此,執行以下 操作:
在包浏覽器中選擇 AnalysisModule 項目。
右鍵單擊並選擇 Run As > Open Run Dialog。
在左側面板中,突出顯示 Java Application 並單擊 New 按鈕。
對新創建的配置使用如下信息(右側面板):
Main 選項卡:Project:找到 AnalysisModule 項目。
Main 選項卡:Main 類:搜索並查找 com.ibm.dtfj.analyzer.base.DumpAnalyzer 類。
Classpath 選項卡:選擇 Bootstrap Entries 並單擊 Add External Jars。添加三個 DTFJ JAR: dtfj-interface.jar、用於 Java 5.0 及以上版本的 dtfj.jar 和用於 Java 1.4.2 的 dtfj.jar(參見 “設置” 一節查找文件位置)並使用 Up 和 Down 按鈕調整顯示次序,使它們以 JRE System Library 中的次序顯示。
Arguments 選項卡:將轉儲的完全限定轉儲名添加到 Program arguments。
單擊 Run。Dump Analyzer 開始運行,將輸出發送到控制台視圖。如果沒有自動顯示視圖,可以通過 Window > Show View > Console 打開。
從命令行運行分析程序
要從命令行運行分析程序,應首先將它們打包為一個 JAR 文件,名為 analyzers.jar。可使用兩種方 法完成,使用 jar 命令或在 Eclipse 中使用如下步驟:
右鍵單擊 Eclipse 中的 AnalysisModule 項目。
選擇 Export。
單擊 Java > Jar File 並從 AnalysisModule 項目中僅選擇源。
確保選中 Export generated class files and resources。
為 analyzers.jar 輸入完全限定路徑。
單擊 Finish。
要從命令行運行分析程序,需要將以下 JAR 文件添加到 boot 類路徑:
dtfj-interface.jar(位於 installDir/plugins/com.ibm.java.diagnostics.dbda.isa_(version number)/WEB-INF/lib/j9)
用於 Java 5.0 及以上版本的 dtfj.jar(位於 installDir/plugins/com.ibm.java.diagnostics.dbda.isa_(version number)/WEB-INF/lib/j9)
用於 Java 1.4.2 的 dtfj.jar(位於 installDir/plugins/com.ibm.java.diagnostics.dbda.isa_ (version number)/WEB-INF/lib/sov)
此外,需要將以下 JAR 文件添加到類路徑:
dumpAnalyzer.jar(位於 installDir/plugins/com.ibm.java.diagnostics.dbda.isa_(version number)/WEB-INF/lib)
在本文的示例中,將這四個 JAR 文件從上面列出的位置復制到包含 analyzers.jar 包的目錄中。運 行分析程序的命令格式為:
java -cp dumpAnalyzer.jar<path separator>analyzers.jar
-Xbootclasspath/p:(list of jar files)
com.ibm.dtfj.analyzer.base.DumpAnalyzer (name of dump) (analyzer to run)
以下是用於 Windows 命令行示例:
set BCP=9/dtfj.jar;j9/dtfj-interface.jar;sov/dtfj.jar
java -cp dumpAnalyzer.jar;analyzers.jar -Xbootclasspath/p:$BCP
com.ibm.dtfj.analyzer.base.DumpAnalyzer 20070307.dmp.zip mypackage.DWReport
這將產生如清單 3 所示的輸出,其中顯示 DWReport 分析程序判斷出轉儲是由 Windows XP 生成的。 Error Summary 顯示轉儲中未發現錯誤。
清單 3. 腳本輸出
DumpAnalyzer V:1.0.2.20070906163649 starting analysis of 20070307.dmp.zip
14-Sep-2007 09:35:57 com.ibm.dtfj.analyzer.base.ImageContext initializeImageFactory
WARNING: Image factory generation failed com.ibm.dtfj.image.sov.ImageFactory
================================ Error Summary =================================
No errors
=============================== Analysis results ===============================
DumpAnalyzer V:1.0.2.20070906163649 : Start analysis of F:\20070307.dmp.zip
Image created on Windows XP
在 ISA 中運行分析程序
要通過 ISA 運行自己的分析程序,需要將它們打包為一個 JAR 文件,稱為 analyzers.jar ,並使用 您的文件替換 installDir/plugins/com.ibm.java.diagnostics.dbda.isa_(version number)/WEB- INF/lib 中的同名文件。要創建 JAR 文件,執行上一節 “從命令行運行分析程序” 開始部分介紹的步 驟。
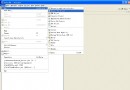
要運行分析程序,需要將完全限定名添加到 ISA Dump Analyzer 視圖的 Optional Parameters 文本 字段中。圖 1 顯示了所需的可選參數以及 清單 1 運行 DWAnalyze 示例的輸出:
圖 1. 通過 ISA 運行 DWAnalyze
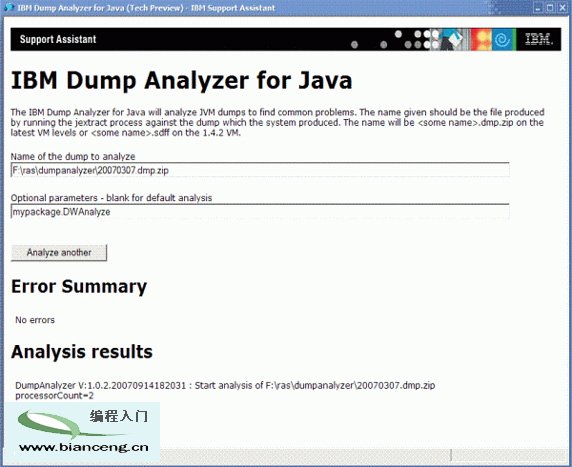
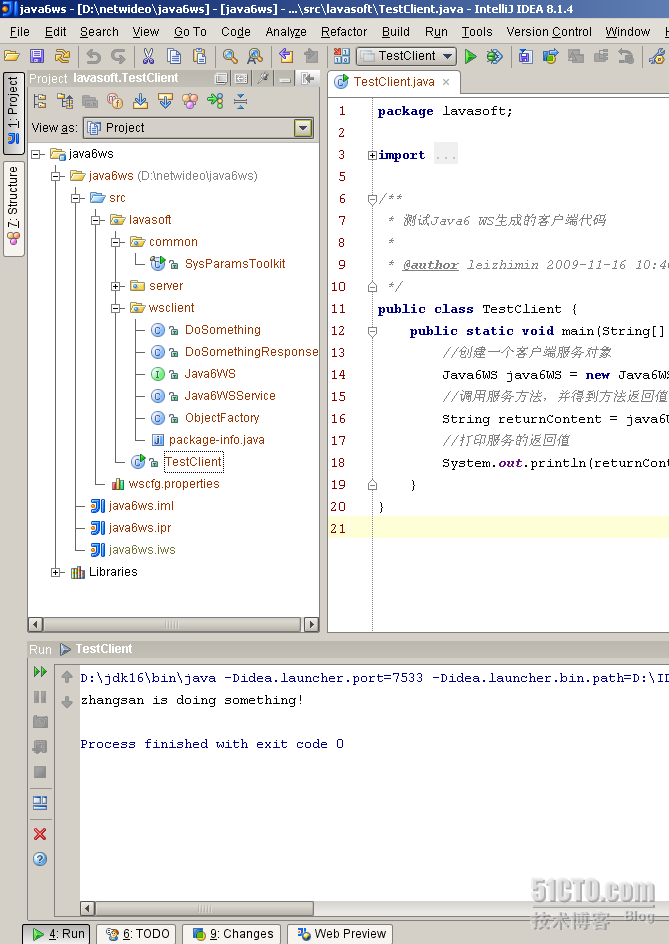
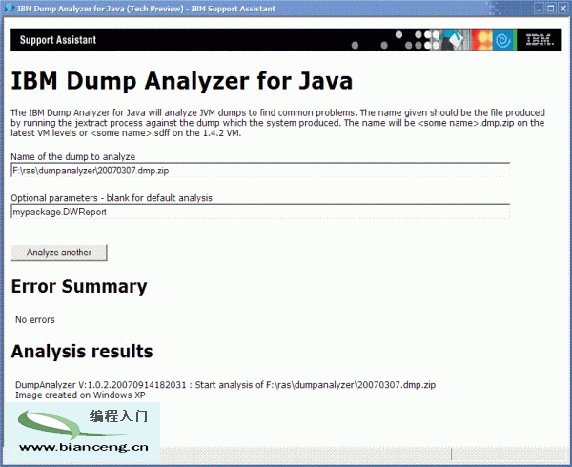
圖 2 顯示了所需的可選參數以及 清單 2 中運行 DWReport 示例的輸出:
圖 2. 通過 ISA 運行 DWReport
SML:概述
可以使用 Java 語言編寫所有四個分析模塊,並在這在很多情況下都是一種適當的方法。然而,有時 候您也許想避免 Java 語言的復雜性,而使用一些非常簡單的腳本功能調用現有的分析程序。針對這些情 況,我們的團隊提供了一種基於狀態機概念的語言,進入狀態機之後會在各個狀態之間移動,直到完成分 析。我們將這種語言稱為狀態機語言(SML)。我們沒有對 SML 使用任何循環結構並且進一步進行了限制 :一個狀態只能訪問一次。目的是確保可以快速構建腳本並且避免發生無休止的重復分析。
SML 由以下關鍵字組成:
import {name} 定義分析程序的完整包名,並使腳本可以使用其簡寫形式。state {name} 定義當前狀 態的名稱。{variable} = {analyzer}:{rule} 將一個變量設置為運行分析的結果。if ({boolean expr}) 條件語句。else 處理 if 語句為 false 時的情形。fi 結束 if 語句。newState {state name} 切換到 一個新狀態,由 state 關鍵字定義。report {analyzer} 在給定的分析程序上調用 produceReport() 方 法。print {message} 為用戶輸出消息。error {message} 在結果摘要中輸出錯誤消息。terminate {result} 使用給定結果結束腳本。可能的結果包括 OK、ERROR、FATAL、TRUE 和 FALSE。
必須將 SML 腳本保存到以 .sml 為擴展名的文件中。下一節將展示如何使用腳本將兩個分析程序鏈接 為一個簡單的分析流。
使用 SML 將分析程序鏈接起來
如上節所述,您可以使用 SML 將分析程序鏈接起來,SML 附帶在 Dump Analyzer 中。清單 4 展示了 這種腳本。它將您在本文前面創建的分析程序鏈接起來。
要繼續本示例,需要在 Eclipse AnalysisModule 項目中創建一個名為 script.sml 的文件並將清單 4 的內容復制到新創建的文件中。
清單 4. 將兩個分析程序鏈接在一起的腳本
// need to import the Analyzers to run
import mypackage.DWAnalyze
import mypackage.DWReport
// The state value is used to control the flow through the sml file
// It needs to be set to start initially
state start
// multi is set to the value returned from running the DWAnalyze class.
// It is the value that is returned from the analysisRules logic
// in this class
multi = DWAnalyze:isMultiProcessor
if (multi = true)
// depending on the value of multi, print some output
print DWAnalyze detected a multiprocessor dump
else
print DWAnalyze did not detect find a multiprocessor dump
fi
// Next run the DWReport class
report DWReport // run the report
// Finally exit
terminate ok
從清單 4 的注釋可以看出,示例腳本運行 DWAnalyze 類包含的 isMultiProcessor 規則並根據結果 輸出相應的消息。隨後又運行 DWReport 分析程序。
要使用該腳本運行您的分析程序,只需將腳本名作為運行時參數傳遞。和 “運行分析程序” 一節一 樣,您將依次了解運行新腳本的每個可能的運行時環境。
在 Eclipse 中運行腳本
要在 Eclipse 中運行腳本,首先執行 “在 Eclipse 中運行分析程序” 中描述的所有 步驟。當為分 析程序創建好運行時配置後,執行以下操作:
打開運行時配置(單擊 Run > Open Run Dialog)。
選擇 Java Application 下的項目條目。
單擊 Arguments 選項卡。
將 script.sml 的完全限定路徑添加到 Program Arguments 部分,排在要進行分析的經過 jextract 的轉儲的完全限定名之後。
單擊 Run。
像以前一樣,結果輸出被發送到 Eclipse Console 視圖。清單 5 顯示了一個示例:
清單 5. Eclipse 中的腳本輸出
DumpAnalyzer V:1.0.2.20070914161154 starting analysis of V:\mydumps\my.dmp.zip
================================ Error Summary =================================
No errors
=============================== Analysis results ===============================
DumpAnalyzer V:1.0.2.20070914161154 : Start analysis of V:\mydumps\my.dmp.zip
DWAnalyze detected a multiprocessor dump
Image created on AIX
在命令行中運行腳本
要在命令行中運行腳本,需要將以下內容添加到在 “從命令行運行分析程序” 小節運行的命令中:
-scriptDir:fully_qualified_path_to_directory_containing_script script.sml
該命令將在您指定的目錄中查找名為 script.sml 的腳本。輸出類似於 清單 5。
在 ISA 中運行腳本
要在 ISA 中運行腳本,執行 “在 ISA 中運行分析程序” 中的步驟,確保您的分析程序位於正確目 錄下名為 analyzers.jar 的 JAR 文件中。之後,啟動 ISA 並查找希望進行分析的轉儲文件。最後,將 如下內容添加到 Optional Parameters 文本框:
-scriptDir:fully_qualified_path_to_directory_containing_script script.sml
像之前一樣,單擊 Estimate Time 和 Analyze。ISA 窗口顯示腳本運行結果。同樣,輸出內容類似於 清單 5。
接口
編寫分析模塊只涉及幾個接口。本節將介紹這部分內容。
com.ibm.dtfj.analyzer.ext.IAnalyzerBase
所有分析程序必須實現 com.ibm.dtfj.analyzer.ext.IAnalyzerBase。這個接口定義了一些所有分析 程序都應具備的常見屬性和屬性訪問方法:
getName() 返回分析程序的惟一名稱。
getVersion() 返回分析程序的版本信息。
getShortDescription() 返回一行對分析程序的描述,在顯示分析程序列表時使用。
getLongDescription() 返回對分析程序的更長的描述,用於幫助信息。
setContext(IAnalyzerContext) 為分析程序設置上下文。分析程序必須實現該接口並保存應返回給 getContext() 的上下文。
getContext() 返回與分析程序相關的上下文(參見下面的 IAnalyzerContext)。
如果為主分析程序(primary analyzer),isPrimaryAnalyzer() 返回 true;就是說,與被嵌入到其 他分析程序中不同,主分析程序指從工具的最頂層調用的分析程序。
com.ibm.dtfj.analyzer.ext.IAnalyze
如果分析程序的目的是對轉儲執行分析並根據分析得出結論,它應該實現 com.ibm.dtfj.analyzer.ext.IAnalyze。這種分析程序是由一組用戶定義的規則(一個或多個)和一些分 析組成,分析以名稱/值對的形式生成輸出。然後將輸出與規則進行比較,得出結論。這種分析被劃分為 多個階段,因此控制環境(例如腳本或分析程序)可以在進行分析時作出決策:
doAnalysis() 是第一個階段。它以名稱/值對的形式生成結果。
analyzeResponse() 接受 doAnalysis() 生成的輸出並對其應用規則以得出結論。結論以 true 或 false 表示。
produceReport() 接受由 doAnalysis() 生成的輸出,應用特定的規則,並以報告的形式描述結論。
listRules() 生成一個規則列表,分析程序可以進行計算。
com.ibm.dtfj.analyzer.ext.IReport
分析程序可以實現 com.ibm.dtfj.analyzer.ext.IReport 接口,使用它將生成的關鍵信息創建為人類 可讀的報告。這個報告可能包含有關轉儲的信息或發現的問題。報告被設計為可以簡單地生成多個格式的 最終輸出,例如 HTML、XML、原始文本等等。
produceReport() 生成一個報告(使用 allocateReport())並添加相關信息。
com.ibm.dtfj.analyzer.base.AnalyzerBase
要簡化分析程序的實現,抽象基類 com.ibm.dtfj.analyzer.base.AnalyzerBase 提供了 IAnalyzerBase 的大多數方法的默認實現。您需要提供 getShortDescription() 的實現並且可能需要重 寫 getVersion() 和 isPrimaryAnalyzer()。該類還提供了一些實用方法,目的是簡化 IAnalyze 接口的 實現。
com.ibm.dtfj.analyzer.ext.IAnalyzerContext
com.ibm.dtfj.analyzer.ext.IAnalyzerContext 接口定義由工具的基礎架構提供的常見函數,所有分 析程序都可以使用這些函數。其中包括可以在分析過程中獲得 Java 運行時的功能。每個分析程序需要通 過 IAnalyzerBase 的 getContext() 方法返回的上下文對象訪問這些函數:
getCurrentJavaRuntime() 返回對 DTFJ JavaRuntime 對象的引用,後者表示當前進行分析的 JVM 運 行時。
loadAnalyzer() 返回對另一個分析程序的引用,根據其類名指定。
outputMessage() 向用戶輸出一條消息。
addError() 添加一條錯誤,將在完成分析後輸出到摘要中。
allocateReport() 分配一個新的報告,方便分析程序添加內容。
notifyAnalysisProgress() 為用戶提供有關分析過程的反饋。如果分析需要占用大量時間,您可能需 要使用這種方法。
com.ibm.dtfj.analyzer.ext.IAnalysisReport
com.ibm.dtfj.analyzer.ext.IAnalysisReport 接口定義報告創建功能,允許將分析程序生成的輸出 輕松轉換為多種不同格式。接口提供了大量方法,但是其中一些示例就能夠說明這種功能:
startSection() 啟用一個新的格式化區域,可能包含標題和不同的格式化規則。
printField() 通常用於輸出字段的名稱和內容。字段布局由格式化確定。
printLiteral() 用於輸出報告中的文字文本。
printReport() 包含當前報告中的嵌入報告。
endSection() 終止當前的格式化區域。
轉儲結構:概述
使用 ImageFactory 讀取 jextract 化的轉儲後將產生 DTFJ Image,本節將介紹其中的一些主要類。 當然,最主要的類是 Image 本身,它表示整個轉儲。它提供了很多屬性,例如對轉儲進行描述的 hostname;它還包含了一組 ImageAddressSpace 對象。通常,轉儲中只有一個地址空間,但有些環境允 許多個地址空間。在地址空間內,您可以找到一個或多個 ImageProcess 對象,其中一個可能就是當前的 對象。
通常,名稱以 Image 開頭的類表示該類不是特定於 Java 平台的;因此,在 ImageProcess 內,可以 迭代一組 ImageModule,表示進程中加載的庫,還可以迭代一組 ImageThread ,表示進程中活動的本地 線程。ImageThread 返回對 ImageRegister 集合的迭代器,它提供對注冊器當前值的訪問。最後, ImagePointer 表示地址空間中一個特定的內存位置,通常用於惟一地識別某些對象。再回到 ImageProcess,您可以迭代很多獨立的 ManagedRuntime 對象,這些對象定義了運行時的最常見形式。對 於要分析的大多數轉儲,您需要找到一個運行時,這個運行時將是 JavaRuntime;這是 ManagedRuntime 的具體化形式。
找到 JavaRuntime 對象後,可以在轉儲的時候檢查 JVM 的關鍵狀態。因此,可以迭代 JavaClassLoader、JavaThread、JavaMonitor 和 JavaHeap(可能有多個 JavaHeap)。還可以對經過 JIT 編譯的方法進行迭代。從 JavaClassLoader 中,可以迭代一組經過定義和緩存的類,從而進一步迭 代方法和字段。在 JavaHeap 中,可以迭代堆內的所有對象,然後反映到對象字段值中。通過這些操作, 您可以編寫分析代碼,詳細地檢查轉儲中表示的狀態,然後得出結論確定狀態是否有效。
實用類
在 DTFJ 映像中操作對象時,可以通過利用 Dump Analyzer 中附帶的實用類簡化某些常見操作。隨時 間推移,這些類的數量將逐漸增多,但是目前,一些類的目的就是簡化 Iterator 和 Vector 的使用。
DTFJIterator
DTFJIterator 類接受由 DTFJ 返回的 Iterator 並在內部處理所有 CorruptData 對象,因此分析程 序就不需要再進行處理。對象能夠被容易地記錄、而且對象數量會被統計和限制,這樣一來,當轉儲被嚴 重破壞,就不會強制分析程序處理長期運行的被破壞的對象。方法與 Iterator 中的一樣,不過 getCorruptObjectCount() 將返回經過迭代器處理的被破壞對象的數量。
DTFJSortedIterator
DTFJSortedIterator 類對 DTFJIterator 的功能進行擴展,將根據由對象類型確定的次序對返回的對 象進行排序。例如,線程將按照名稱順序排序,而對象則按照地址順序排序。該接口與 DTFJIterator 使 用的接口完全相同。
SimpleVector
SimpleVector 通過提供與 Vector 類相似的功能簡化了對對象數組的處理:
addObject() 在第一個空槽中添加給定對象。
addObjectOrExtend() 在第一個空槽中添加給定對象或擴展向量。
deleteObject() 從向量的任何槽中刪除對象。
deleteObjectAndCompress() 從向量的任何槽中刪除對象並將空槽 壓縮到初始狀態。
toString() 將以 [item1,item2] 的形式輸出向量。
實用分析程序
除了加載和執行分析程序的基本架構外,Dump Analyzer 還提供了一個實用工具庫,可以簡化較復雜 分析程序的實現。這些實用程序是由經過預定義的特定分析程序提供。
這個實用工具庫在不斷增長,因為我們的團隊一直在挑選新的通用函數,它們可以實現很多分析程序 。本節描述了一些目前極為常用的實用工具。
ObjectFinder
ObjectFinder 對 JVM 運行時進行全面掃描,找出特定類型對象的所有實例,然後再由其他分析程序 進行檢查。ObjectFinder 將構建一個緩存,因此,即使多個不同的分析程序連續請求不同類型對象的實 例,JVM 也只需執行一次掃描。下面展示了一些關鍵的函數:
findObjects() 返回一個向量,列出了在所分析的 JVM 運行時中找到的給定類的所有實例。
getObjectCount() 返回在所分析的 JVM 運行時中找到的給定類的實例數量。
produceReport() 生成一個報告,其中列出了在 JVM 運行時中找到的每個類的實例數量。
ClassFinder
ClassFinder 分析程序對 JVM 進行全面掃描,找到當前加載的所有 Java 類,然後再由其他分析程序 進行檢查。ClassFinder 構建緩存,因此即使多個不同的分析程序連續請求不同的類,JVM 運行時也只需 進行一次掃描。下面列出了關鍵的函數:
findClasses() 返回一個向量,列出了在所分析的 JVM 運行時中找到的具有給定類名的所有類定義。 注意,如果運行時中具有多個類加載器,那麼一個類名可能具有多個類定義。
produceReport() 生成一個報告,列出了 JVM 運行時中當前定義的所有類。
ObjectNavigatorCollection
ObjectNavigatorCollection 分析程序表示 JVM 運行時中給定類的一組實例,從 ObjectFinder 獲得 。其中的關鍵函數包括:
getObjectNavigator() 返回一個 ObjectNavigator 分析程序,從 ObjectNavigatorCollection 提供 的實例列表中封裝對象的一個特定實例。
getObjectsCount() 返回由 ObjectNavigatorCollection 封裝的對象實例的數量。
ObjectNavigator
ObjectNavigator 分析程序表示 JVM 運行時中給定類的某種特定實例,並提供訪問和輸出對象實例字 段的功能。其中的關鍵函數包括:
getFieldValueAtPath() 返回 ObjectNavigator 表示的對象實例的給定字段值,或者返回其他一些對 象的字段值,這些對象的字段引用了第一個對象的字段,使用類似 field1/field2/field3/... 的路徑表 示
printFieldValueAtPath() 輸出 ObjectNavigator 表示的對象實例的給定字段值,或者其他一些對象 的字段值,這些對象的字段引用了第一個對象的字段。
包裝器類
您還訪問了一組包裝器類分析程序,每個分析程序包含了一些必要的函數,可以解釋和提取所分析的 JVM 運行時中給定類型對象的內容。它們包括:
VectorWrapper:提取 JVM 運行時中找到的 java.util.Vector 實例的內容。
HashMapWrapper:提取 JVM 運行時中找到的 java.util.HashMap 實例的內容。
PropertiesWrapper:提取 JVM 運行時中找到的 java.util.Properties 實例的內容。
ThreadLocalWrapper:提取 JVM 運行時中找到的 java.lang.ThreadLocal 實例的內容。
結束語
現在,您已經了解了所有必需的知識,可以使用它們編寫自己的分析模塊並對轉儲文件診斷問題。如 果出現任何問題,請與本文任一位作者聯系,尋求幫助。我們希望您能夠成功地編寫出自己的分析程序並 盡可解決遇到的問題。
本文是系列文章的最後一篇。這四篇文章向您展示了如何使用 IBM Dump Analyzer for Java 對經過 jextract 的系統轉儲診斷問題、如何使用 Extensible Verbose Toolkit 顯示詳細的垃圾收集日志,以 及如何使用 IBM Lock Analyzer for Java 分析性能問題。我們希望您能夠使用這些工具解決 Java 應用 程序中的問題並提升性能。