說起BOM,這個問題還比較麻煩,因為BOM不可見,但用程序做不同編碼文本處理時候卻常常需要考慮 到BOM的問題。在此之前,先對BOM做個簡單認識。
先看看帶BOM的文件:
源文件:
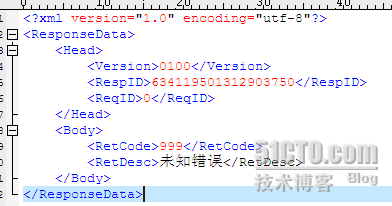
16進制打開:
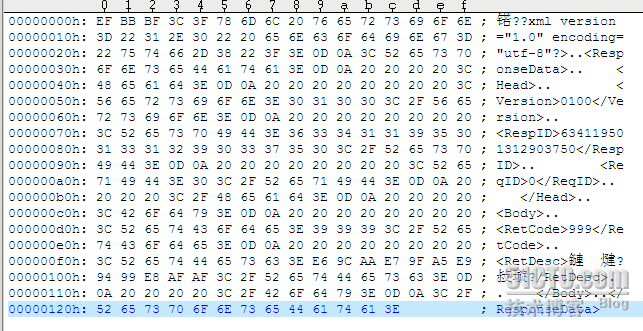
下面舉個例子,針對UTF-8的文件BOM做個處理:
String xmla = StringFileToolkit.file2String(new File ("D:\\projects\\mailpost\\src\\a.xml"),"UTF-8");
byte[] b = xmla.getBytes("UTF- 8");
String xml = new String(b,3,b.length-3,"UTF-8");
Document doc1 = DocumentHelper.parseText(xml);
Element e1 = (Element)doc1.selectSingleNode ("/ResponseData/Body/RetDesc");
Element e2 = (Element)doc1.selectSingleNode ("/ResponseData/Head/RespID");
Element e3 = (Element)doc1.selectSingleNode ("/ResponseData/Body/RetCode");
Element e4 = (Element)doc1.selectSingleNode ("/ResponseData/Body/RetDesc");
思路是:先按照UTF-8編碼讀取文件後,跳過前三個字符,重新構建一個新的字符串,然後用Dom4j解 析處理,這樣就不會報錯了。
其他編碼的方式處理思路類似,其實可以寫一個通用的自動識別的BOM的工具,去掉BOM信息,返回字 符串。
不過這個處理過程已經有牛人解決過了:http://koti.mbnet.fi/akini/java/unicodereader/
什麼是BOM
BOM(byte-order mark),即字節順序標記,它是插入到以UTF-8、UTF16或UTF-32編碼Unicode文件開 頭的特殊標記,用來識別Unicode文件的編碼類型。對於UTF-8來說,BOM並不是必須的,因為BOM用來標記 多字節編碼文件的編碼類型和字節順序(big-endian或little-endian)。
在絕大多數編輯器中都看不到BOM字符,因為它們能理解Unicode,去掉了讀取器看不到的題頭信息。 若要查看某個Unicode文件是否以BOM開頭,可以使用十六進制編輯器。下表列出了不同編碼所對應的BOM 。
BOM Encoding EF BB BF UTF-8 FE FF UTF-16 (big-endian) FF FE UTF-16 (little-endian) 00 00 FE FF UTF-32 (big-endian) FF FE 00 00 UTF-32 (little-endian)
BOM的來歷
為了識別 Unicode 文件,Microsoft 建議所有的 Unicode 文件應該以 ZERO WIDTH NOBREAK SPACE( U+FEFF)字符開頭。這作為一個“特征符”或“字節順序標記(byte-order mark,BOM)”來識別文件中 使用的編碼和字節順序。
不同的系統對BOM的支持
因為一些系統或程序不支持BOM,因此帶有BOM的Unicode文件有時會帶來一些問題。
1.JDK1.5以及之前的Reader都不能處理帶有BOM的UTF-8編碼的文件,解析這種格式的xml文件時,會拋 出異常:Content is not allowed in prolog.
2.Linux/UNIX 並沒有使用 BOM,因為它會破壞現有的 ASCII 文件的語法約定。
不同的編輯工具對BOM的處理也各不相同。使用Windows自帶的記事本將文件保存為UTF-8編碼的時候, 記事本會自動在文件開頭插入BOM(雖然BOM對UTF-8來說並不是必須的),但是editplus就不會這樣做。
BOM與XML
XML解析讀取XML文檔時,W3C定義了3條規則:
1.如果文檔中有BOM,就定義了文件編碼;
2.如果文檔中沒有BOM,就查看XML聲明中的編碼屬性;
3.如果上述兩者都沒有,就假定XML文檔采用UTF-8編碼。
出處http://lavasoft.blog.51cto.com/62575/331095