用AspectJ和JMX深入觀察Glassbox Inspector
簡介:隨著 Ron Bodkin 介紹如何把 AspectJ 和 JMX 組合成靈活而且模塊 化 的性能監視方式,就可以對散亂而糾纏不清的代碼說再見了。在這篇文章(共分 兩部分)的第一部分中,Ron 用來自開放源碼項目 Glassbox Inspector 的代碼 和想法幫助您構建一個監視系統,它提供的相關信息可以識別出特定問題,但是 在生產環境中使用的開銷卻足夠低。
現代的 Java™ 應用程序通常是采用許多第三方組件的復雜的、多線程 的、分布式的系統。在這樣的系統上,很難檢測(或者分離出)性能問題或可靠 性問題的根本原因,尤其是生產中的問題。對於問題容易重現的情況來說, profiler 這類傳統工具可能有用,但是這類工具帶來的開銷造成在生產環境、 甚 至負載測試環境中使用它們是不現實的。
監視和檢查應用程序和故障常 見 的一個備選策略是,為性能的關鍵代碼提供有關調用,記錄使用情況、計時以及 錯誤情況。但是,這種方式要求在許多地方分散重復的代碼,而且要測量哪些代 碼也需要經過許多試驗和錯誤才能確定。當系統變化時,這種方式既難維護,也 很難深入進去。這造成日後要求對性能需求有更好理解的時候,添加或修改應用 程序的代碼變得很困難。簡單地說,系統監視是經典的橫切關注點,因此任何非 模塊化的實現都會讓它混亂。
學習這篇分兩部分的文章就會知道,面向 方 面編程(AOP)很自然地適合解決系統監視問題。AOP 允許定義切入點,與要監 視 性能的許多連接點進行匹配。然後可以編寫建議,更新性能統計,而在進入或退 出任何一個連接點時,都會自動調用建議。
在本文的這半部分,我將介 紹 如何用 AspectJ 和 JMX 創建靈活的、面向方面的監視基礎設施。我要使用的監 視基礎設施是開放源碼的 Glassbox Inspector 監視框架(請參閱 參考資料) 的 核心。它提供了相關的信息,可以幫助識別特定的問題,但是在生產環境中使用 的開銷卻足夠小。它允許捕捉請求的總數、總時間以及最差情況性能之類的統計 值,還允許深入請求中數據庫調用的信息。而它做的所有這些,僅僅是在一個中 等規模的代碼基礎內完成的!
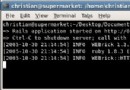
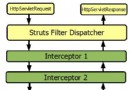
在這篇文章和下一篇文章中,我將從構建 一 個簡單的 Glassbox Inspector 實現開始,並逐漸添加功能。圖 1 提供了這個 遞 增開發過程的最終系統的概貌。請注意這個系統的設計是為了同時監視多個 Web 應用程序,並提供合並的統計結果。
圖 1. 帶有 JConsole JMX 客戶端 的 Glassbox Inspector
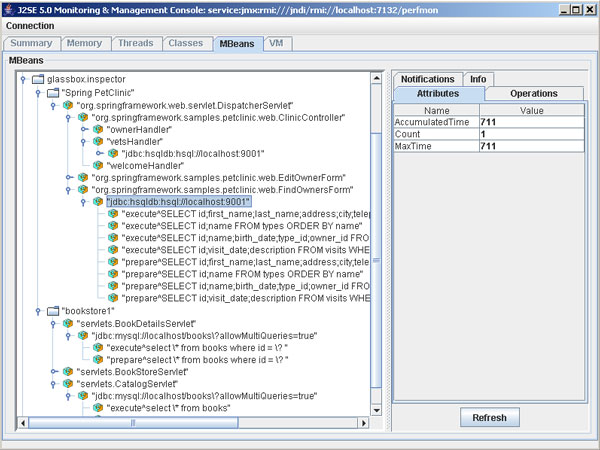
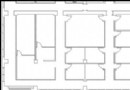
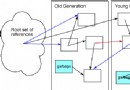
圖 2 是監視系統架構的概貌。方面與容器內的一個或多個應用程序交 互,捕捉性能數據,然後用 JMX Remote 標准把數據提出來。從架構的角度來看 ,Glassbox Inspector 與許多性能監視系統類似,區別在於它擁有定義良好的 實 現了關鍵監視功能的模塊。
圖 2. Glassbox Inspector 架構
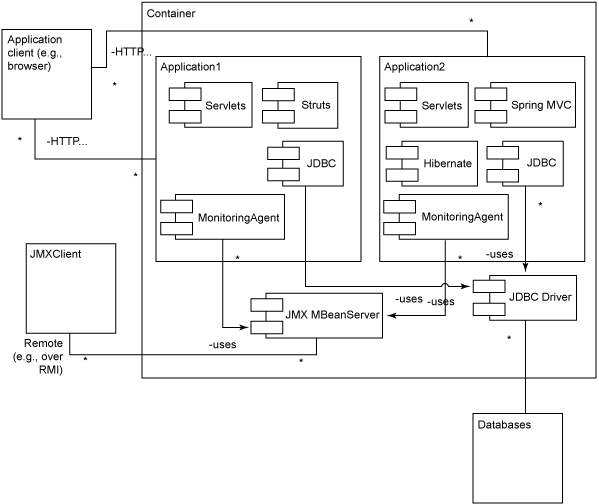
Java 管理擴展(JMX)是通過查看受管理對象的屬性來管理 Java 應 用 程序的標准 API。JMX Remote 標准擴展了 JMX,允許外部客戶進程管理應用程 序 。JMX 管理是 Java 企業容器中的標准特性。現有多個成熟的第三方 JMX 庫和 工 具,而且 JMX 支持在 Java 5 中也已經集成進核心 Java 運行時。Sun 公司的 Java 5 虛擬機包含 JConsole JMX 客戶端。
在繼續本文之前,應當下載 AspectJ、JMX 和 JMX Remote 的當前版本以及本文的源代碼包(請參閱 參考資 料 獲得技術內容,參閱下載 獲得代碼)。如果正在使用 Java 5 虛擬機,那麼 內置了 JMX。請注意源代碼包包含開放源碼的 Glassbox Inspector 性能監視基 礎設施 1.0 alpha 發行版的完整最終代碼。
基本的系統
我將從 一 個基本的面向方面的性能監視系統開始。這個系統可以捕捉處理 Web 請求的不 同 servlet 的時間和計數。清單 1 顯示了一個捕捉這個性能信息的簡單方面:
清單 1. 捕捉 servlet 時間和計數的方面
/**
* Monitors performance timing and execution counts for
* <code>HttpServlet</code> operations
*/
public aspect HttpServletMonitor {
/** Execution of any Servlet request methods. */
public pointcut monitoredOperation(Object operation) :
execution(void HttpServlet.do*(..)) && this (operation);
/** Advice that records statistics for each monitored operation. */
void around(Object operation) : monitoredOperation(operation) {
long start = getTime();
proceed(operation);
PerfStats stats = lookupStats (operation);
stats.recordExecution(getTime(), start);
}
/**
* Find the appropriate statistics collector object for this
* operation.
*
* @param operation
* the instance of the operation being monitored
*/
protected PerfStats lookupStats(Object operation) {
Class keyClass = operation.getClass();
synchronized(operations) {
stats = (PerfStats) operations.get(keyClass);
if (stats == null) {
stats = perfStatsFactory.
createTopLevelOperationStats(HttpServlet.class,
keyClass);
operations.put(keyClass, stats);
}
}
return stats;
}
/**
* Helper method to collect time in milliseconds. Could plug in
* nanotimer.
*/
public long getTime() {
return System.currentTimeMillis();
}
public void setPerfStatsFactory(PerfStatsFactory
perfStatsFactory) {
this.perfStatsFactory = perfStatsFactory;
}
public PerfStatsFactory getPerfStatsFactory() {
return perfStatsFactory;
}
/** Track top-level operations. */
private Map/*<Class,PerfStats>*/ operations =
new WeakIdentityHashMap();
private PerfStatsFactory perfStatsFactory;
}
/**
* Holds summary performance statistics for a
* given topic of interest
* (e.g., a subclass of Servlet).
*/
public interface PerfStats {
/**
* Record that a single execution occurred.
*
* @param start time in milliseconds
* @param end time in milliseconds
*/
void recordExecution(long start, long end);
/**
* Reset these statistics back to zero. Useful to track statistics
* during an interval.
*/
void reset();
/**
* @return total accumulated time in milliseconds from all
* executions (since last reset).
*/
int getAccumulatedTime();
/**
* @return the largest time for any single execution, in
* milliseconds (since last reset).
*/
int getMaxTime ();
/**
* @return the number of executions recorded (since last reset).
*/
int getCount();
}
/**
* Implementation of the
*
* @link PerfStats interface.
*/
public class PerfStatsImpl implements PerfStats {
private int accumulatedTime=0L;
private int maxTime=0L;
private int count=0;
public void recordExecution(long start, long end) {
int time = (int) (getTime()-start);
accumulatedTime += time;
maxTime = Math.max(time, maxTime);
count++;
}
public void reset() {
accumulatedTime=0L;
maxTime=0L;
count=0;
}
int getAccumulatedTime () { return accumulatedTime; }
int getMaxTime() { return maxTime; }
int getCount() { return count; }
}
public interface PerfStatsFactory {
PerfStats
createTopLevelOperationStats(Object type, Object key);
}
可以看到,第一個版本相當基礎。HttpServletMonitor 定義了一個切入點, 叫作 monitoredOperation,它匹配 HttpServlet 接口上任何名稱以 do 開始的 方法的執行。這些方法通常是 doGet() 和 doPost(),但是通過匹配 doHead() 、 doDelete()、doOptions()、doPut() 和 doTrace(),它也可以捕捉不常用的 HTTP 請求選項。
每當其中一個操作執行的時候,系統都會執行 around 通知去監視性能。建 議 啟動一個秒表,然後讓原始請求繼續進行。之後,通知停止秒表並查詢與指定操 作對應的性能統計對象。然後它再調用 PerfStats 接口的 recordExecution() , 記錄操作經歷的時間。這僅僅更新指定操作的總時間、最大時間(如果適用)以 及執行次數。自然也可以把這種方式擴展成計算額外的統計值,並在問題可能發 生的地方保存單獨的數據點。
我在方面中使用了一個哈希圖為每種操作處理程序保存累計統計值。在這個 版 本中,操作處理程序是 HttpServlet 的子類,所以 servlet 的類被用作鍵。我 還用術語 操作 表示 Web 請求,以便把它與應用程序可能產生的其他請求(例 如 ,數據庫請求)區分開。在這篇文章的第二部分,我將擴展這種方式,來解決更 常見的在控制器中使用的基於類或方法的跟蹤操作情況,例如 Apache Struts 的 動作類或 Spring 的多動作控制器方法。
公開性能數據
一旦捕捉到了性能數據,讓它可以使用的方式就很多了。最簡單的方式就是 把 信息定期地寫入日志文件。也可以把信息裝入數據庫進行分析。由於不增加延遲 、復雜性以及合計、日志及處理信息的開銷,提供到即時系統數據的直接訪問通 常會更好。在下一節中我將介紹如何做到這一點。
我想使用一個現有管理工作能夠顯示和跟蹤的標准協議,所以我將用 JMX API 來共享性能統計值。使用 JMX 意味著每個性能統計實例都會公開成一個管理 bean,從而提供詳細的性能數據。標准的 JMX 客戶端(像 Sun 公司的 JConsole )也能夠顯示這些信息。請參閱 參考資料 學習有關 JMX 的更多內容。
圖 3 是一幅 JConsole 的截屏,顯示了 Glassbox Inspector 監視 Duke 書 店示例應用程序性能的情況。(請參閱 參考資料)。清單 2 顯示了實現這個特 性的代碼。
圖 3. 用 Glassbox Inspector 查看操作統計值
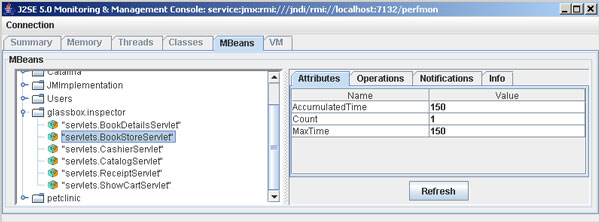
傳統上,支持 JMX 包括用樣本代碼實現模式。在這種情況下,我將把 JMX 與 AspectJ 結合,這個結合可以讓我獨立地編寫管理邏輯。
清單 2. 實現 JMX 管理特性
/** Reusable aspect that automatically registers
* beans for management
*/
public aspect JmxManagement {
/** Defines classes to be managed and
* defines basic management operation
*/
public interface ManagedBean {
/** Define a JMX operation name for this bean.
* Not to be confused with a Web request operation.
*/
String getOperationName();
/** Returns the underlying JMX MBean that
* provides management
* information for this bean (POJO).
*/
Object getMBean();
}
/** After constructing an instance of
* <code>ManagedBean</code>, register it
*/
after() returning (ManagedBean bean):
call(ManagedBean+.new(..)) {
String keyName = bean.getOperationName();
ObjectName objectName =
new
ObjectName("glassbox.inspector:" + keyName);
Object mBean = bean.getMBean();
if (mBean != null) {
server.registerMBean(mBean, objectName);
}
}
/**
* Utility method to encode a JMX key name,
* escaping illegal characters.
* @param jmxName unescaped string buffer of form
* JMX keyname=key
* @param attrPos position of key in String
*/
public static StringBuffer
jmxEncode(StringBuffer jmxName, int attrPos) {
for (int i=attrPos; i<jmxName.length(); i++) {
if (jmxName.charAt(i)==',' ) {
jmxName.setCharAt(i, ';');
} else if (jmxName.charAt(i)=='?'
|| jmxName.charAt(i)=='*' ||
jmxName.charAt(i)=='\\' ) {
jmxName.insert(i, '\\');
i++;
} else if (jmxName.charAt(i)=='\n') {
jmxName.insert(i, '\\');
i++;
jmxName.setCharAt(i, 'n');
}
}
return jmxName;
}
/** Defines the MBeanServer with which beans
* are auto-registered.
*/
private MBeanServer server;
public void setMBeanServer(MBeanServer server) {
this.server = server;
}
public MBeanServer getMBeanServer() {
return server;
}
}
可以看出這個第一個方面是可以重用的。利用它,我能夠用 after 建議自動 為任何實現 ManagedBean 接口的類登記對象實例。這與 AspectJ 標記器接口的 理念類似(請參閱 參考資料):定義了實例應當通過 JMX 公開的類。但是,與 真正的標記器接口不同的是,它還定義了兩個方法 。
這個方面提供了一個設置器,定義應當用哪個 MBean 服務器管理對象。這是 一個使用反轉控制(IOC)模式進行配置的示例,因此很自然地適合方面。在最 終 代碼的完整清單中,將會看到我用了一個簡單的輔助方面對系統進行配置。在更 大的系統中,我將用 Spring 框架這樣的 IOC 容器來配置類和方面。請參閱 參 考資料 獲得關於 IOC 和 Spring 框架的更多信息,並獲得關於使用 Spring 配 置方面的介紹。
清單 3. 公開負責 JMX 管理的 bean
/** Applies JMX management to performance statistics beans. */
public aspect StatsJmxManagement {
/** Management interface for performance statistics.
* A subset of @link PerfStats
*/
public interface PerfStatsMBean extends ManagedBean {
int getAccumulatedTime();
int getMaxTime();
int getCount();
void reset();
}
/**
* Make the @link PerfStats interface
* implement @link PerfStatsMBean,
* so all instances can be managed
*/
declare parents: PerfStats implements PerfStatsMBean;
/** Creates a JMX MBean to represent this PerfStats instance. */
public DynamicMBean PerfStats.getMBean() {
try {
RequiredModelMBean mBean = new RequiredModelMBean();
mBean.setModelMBeanInfo
(assembler.getMBeanInfo(this, getOperationName()));
mBean.setManagedResource(this,
"ObjectReference");
return mBean;
} catch (Exception e) {
/* This is safe because @link ErrorHandling
* will resolve it. This is described later!
*/
throw new
AspectConfigurationException("can't
register bean ", e);
}
}
/** Determine JMX operation name for this
* performance statistics bean.
*/
public String PerfStats.getOperationName() {
StringBuffer keyStr =
new StringBuffer("operation=\"");
int pos = keyStr.length();
if (key instanceof Class) {
keyStr.append(((Class)key).getName());
} else {
keyStr.append(key.toString());
}
JmxManagement.jmxEncode(keyStr, pos);
keyStr.append("\"");
return keyStr.toString();
}
private static Class[] managedInterfaces =
{ PerfStatsMBean.class };
/**
* Spring JMX utility MBean Info Assembler.
* Allows @link PerfStatsMBean to serve
* as the management interface of all performance
* statistics implementors.
*/
static InterfaceBasedMBeanInfoAssembler assembler;
static {
assembler = new InterfaceBasedMBeanInfoAssembler();
assembler.setManagedInterfaces(managedInterfaces);
}
}
清單 3 包含 StatsJmxManagement 方面,它具體地定義了哪個對象應當公開 管理 bean。它描述了一個接口 PerfStatsMBean,這個接口定義了用於任何性能 統計實現的管理接口。其中包括計數、總時間、最大時間的統計值,還有重設操 作,這個接口是 PerfStats 接口的子集。
PerfStatsMBean 本身擴展了 ManagedBean,所以它的任何實現都會自動被 JmxManagement 方面登記成進行管理。我采用 AspectJ 的 declare parents 格 式讓 PerfStats 接口擴展了一個特殊的管理接口 PerfStatsMBean。結果是 JMX Dynamic MBean 技術會管理這些對象,與使用 JMX 的標准 MBean 相比,我更喜 歡這種方式。
使用標准 MBean 會要求定義一個管理接口,接口名稱基於每個性能統計的實 現類,例如 PerfStatsImplMBean。後來,當我向 Glassbox Inspector 添加 PerfStats 的子類時,情況變糟了,因為我被要求創建對應的接口(例如 OperationPerfStatsImpl)。標准 MBean 的約定使得接口依賴於實現,而且代 表 這個系統的繼承層次出現不必要的重復。
這個方面剩下的部分負責用 JMX 創建正確的 MBean 和對象名稱。我重用了 來 自 Spring 框架的 JMX 工具 InterfaceBasedMBeanInfoAssembler,用它可以更 容易地創建 JMX DynamicMBean(用 PerfStatsMBean 接口管理 PerfStats 實例 )。在這個階段,我只公開了 PerfStats 實現。這個方面還用受管理 bean 類 上 的類型間聲明定義了輔助方法。如果這些類中的任何一個的子類需要覆蓋默認行 為,那麼可以通過覆蓋這個方法實現。
您可能想知道為什麼我用方面進行管理而不是直接把支持添加到 PerfStatsImpl 的實現類中。雖然把管理添加到這個類中不會把代碼分散,但是 它會把性能監視系統的實現與 JMX 混雜在一起。所以,如果我想把這個系統用 在 一個 沒有 JMX 的系統中,就要被迫包含 JMX 的庫,還要禁止有關服務。而且 , 當擴展系統的管理功能時,我還要公開更多的類用 JMX 進行管理。使用方面可 以 讓系統的管理策略保持模塊化。
數據庫請求監視
分布式調用是應用程序性能低和出錯誤的一個常見源頭。多數基於 Web 的應 用程序要做相當數量的數據庫工作,所以對查詢和其他數據庫請求進行監視就成 為性能監視中特別重要的領域。常見的問題包括編寫得有毛病的查詢、遺漏了索 引以及每個操作中過量的數據庫請求。在這一節,我將對監視系統進行擴展,跟 蹤數據庫中與操作相關的活動。
開始時,我將監視數據庫的連接次數和數據庫語句的執行。為了有效地支持 這 個要求,我需要歸納性能監視信息,並允許跟蹤嵌套在一個操作中的性能。我想 把性能的公共元素提取到一個抽象基類。每個基類負責跟蹤某項操作前後的性能 ,還需要更新系統范圍內這條信息的性能統計值。這樣我就能跟蹤嵌套的 servlet 請求,對於在 Web 應用程序中支持對控制器的跟蹤,這也會很重要( 在 第二部分討論)。
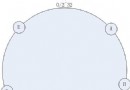
因為我想根據請求更新數據庫的性能,所以我將采用 composite pattern 跟 蹤由其他統計值持有的統計值。這樣,操作(例如 servelt)的統計值就持有每 個數據庫的性能統計。數據庫的統計值持有有關連接次數的信息,並聚合每個單 獨語句的額外統計值。圖 4 顯示整體設計是如何結合在一起的。清單 4 擁有新 的基監視方面,它支持對不同的請求進行監視。
圖 4. 一般化後的監視設計
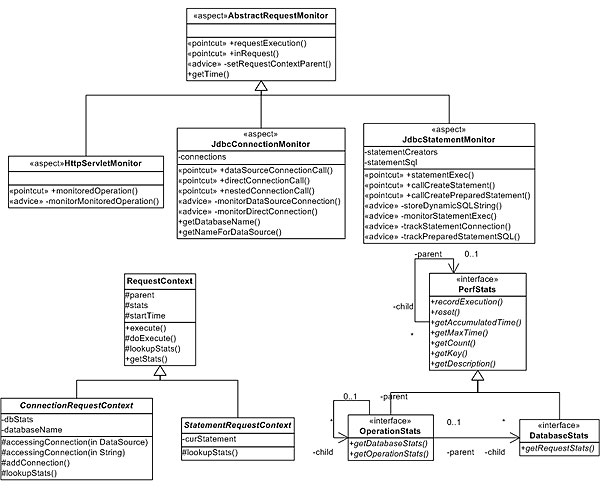
清單 4. 基監視方面
/** Base aspect for monitoring functionality.
* Uses the worker object pattern.
*/
public abstract aspect AbstractRequestMonitor {
/** Matches execution of the worker object
* for a monitored request.
*/
public pointcut
requestExecution(RequestContext requestContext) :
execution(* RequestContext.execute(..))
&& this(requestContext);
/** In the control flow of a monitored request,
* i.e., of the execution of a worker object.
*/
public pointcut inRequest(RequestContext requestContext) :
cflow(requestExecution(requestContext));
/** establish parent relationships
* for request context objects.
*/
// use of call is cleaner since constructors are called
// once but executed many times
after (RequestContext parentContext)
returning (RequestContext childContext) :
call(RequestContext+.new(..)) &&
inRequest(parentContext) {
childContext.setParent (parentContext);
}
public long getTime() {
return System.currentTimeMillis();
}
/** Worker object that holds context information
* for a monitored request.
*/
public abstract class RequestContext {
/** Containing request context, if any.
* Maintained by @link AbstractRequestMonitor
*/
protected RequestContext parent = null;
/** Associated performance statistics.
* Used to cache results of @link #lookupStats ()
*/
protected PerfStats stats;
/** Start time for monitored request. */
protected long startTime;
/**
* Record execution and elapsed time
* for each monitored request.
* Relies on @link #doExecute() to proceed
* with original request.
*/
public final Object execute() {
startTime = getTime();
Object result = doExecute ();
PerfStats stats = getStats();
if (stats != null) {
stats.recordExecution(startTime, getTime());
}
return result;
}
/** template method: proceed with original request */
public abstract Object doExecute();
/** template method: determines appropriate performance
* statistics for this request
*/
protected abstract PerfStats lookupStats();
/** returns performance statistics for this method */
public PerfStats getStats() {
if (stats == null) {
stats = lookupStats(); // get from cache if available
}
return stats;
}
public RequestContext getParent() {
return parent;
}
public void setParent(RequestContext parent) {
this.parent = parent;
}
}
}
不出所料,對於如何存儲共享的性能統計值和基方面的每請求狀態,有許多 選 擇。例如,我可以用帶有更底層機制的單體(例如 ThreadLocal)持有一堆統計 值和上下文。但是,我選用了工人對象(Worker Object)模式(請參閱 參考資 料),因為它支持更加模塊化、更簡潔的表達。雖然這會帶來一些額外的開銷, 但是分配單一對象並執行建議所需要的額外時間,比起為 Web 和數據庫請求提 供 服務來說,通常是微不足道的。換句話說,我可以在不增加開銷的情況下,在監 視代碼中做一些處理工作,因為它運行的頻繁相對很低,而且比起在通過網絡發 送信息和等候磁盤 I/O 上花費的時間來說,通常就微不足道了。對於 profiler 來說,這可能是個糟糕的設計,因為在 profiler 中可能想要跟蹤每個請求中的 許多操作(和方法)的數據。但是,我是在做請求的統計匯總,所以這個選擇是 合理的。
在上面的基方面中,我把當前被監視請求的中間狀態保存在匿名內部類中。 這 個工人對象用來包裝被監視請求的執行。工人對象 RequestContext 是在基類中 定義的,提供的 final execute 方法定義了對請求進行監視的流程。execute 方 法委托抽象的模板方法 doExecute() 負責繼續處理原始的連接點。在 doExecute() 方法中也適合在根據上下文信息(例如正在連接的數據源)繼續處 理被監視的連接點之前設置統計值,並在連接點返回之後關聯返回的值(例如數 據庫連接)。
每個監視方面還負責提供抽象方法 lookupStats() 的實現,用來確定為指定 請求更新哪個統計對象。lookupStats() 需要根據被監視的連接點訪問信息。一 般來說,捕捉的上下文對於每個監視方面都應當各不相同。例如,在 HttpServletMonitor 中,需要的上下文就是目前執行操作對象的類。對於 JDBC 連接,需要的上下文就是得到的數據源。因為要求根據上下文而不同,所以設置 工人對象的建議最好是包含在每個子方面中,而不是在抽象的基方面中。這種安 排更清楚,它支持類型檢測,而且也比在基類中編寫一個建議,再把 JoinPoint 傳遞給所有孩子執行得更好。


 回頁首
回頁首
servlet 請求跟蹤
AbstractRequestMonitor 確實包含一個具體的 after 建議,負責跟蹤請求 上 下文的雙親上下文。這就讓我可以把嵌套請求的操作統計值與它們雙親的統計值 關聯起來(例如,哪個 servlet 請求造成了這個數據庫訪問)。對於示例監視 系 統來說,我明確地 需要 嵌套的工人對象,而 不想 把自己限制在只能處理頂級 請求上。例如,所有的 Duke 書店 servlet 都把調用 BannerServlet 作為顯示 頁面的一部分。所以能把這些調用的次數分開是有用的,如清單 5 所示。在這 裡 ,我沒有顯示在操作統計值中查詢嵌套統計值的支持代碼(可以在本文的源代碼 中看到它)。在第二部分,我將重新回到這個主題,介紹如何更新 JMX 支持來 顯 示像這樣的嵌套統計值。
清單 5. 更新的 servlet 監視
清單 5 should now read
public aspect HttpServletMonitor extends AbstractRequestMonitor {
/** Monitor Servlet requests using the worker object pattern */
Object around(final Object operation) :
monitoredOperation(operation) {
RequestContext requestContext = new RequestContext() {
public Object doExecute() {
return proceed (operation);
}
public PerfStats lookupStats() {
if (getParent() != null) {
// nested operation
OperationStats parentStats =
(OperationStats)getParent().getStats();
return
parentStats.getOperationStats(operation.getClass ());
}
return lookupStats (operation.getClass());
}
};
return requestContext.execute();
}
...
清單 5 顯示了修訂後進行 serverlet 請求跟蹤的監視建議。余下的全部代 碼 與 清單 1 相同:或者推入基方面 AbstractRequestMonitor 方面,或者保持一 致。
JDBC 監視
設置好性能監視框架後,我現在准備跟蹤數據庫的連接次數以及數據庫語句 的 時間。而且,我還希望能夠把數據庫語句和實際連接的數據庫關聯起來(在 lookupStats() 方法中)。為了做到這一點,我創建了兩個跟蹤 JDBC 語句和連 接信息的方面: JdbcConnectionMonitor 和 JdbcStatementMonitor。
這些方面的一個關鍵職責是跟蹤對象引用的鏈。我想根據我用來連接數據庫 的 URI 跟蹤請求,或者至少根據數據庫名稱來跟蹤。這就要求跟蹤用來獲得連接的 數據源。我還想進一步根據 SQL 字符串跟蹤預備語句(在執行之前就已經准備 就 緒)。最後,我需要跟蹤與正在執行的語句關聯的 JDBC 連接。您會注意到: JDBC 語句 確實 為它們的連接提供了存取器;但是,應用程序服務器和 Web 應 用程序框架頻繁地使用修飾器模式包裝 JDBC 連接。我想確保自己能夠把語句與 我擁有句柄的連接關聯起來,而不是與包裝的連接關聯起來。
JdbcConnectionMonitor 負責測量數據庫連接的性能統計值,它也把連接與 它 們來自數據源或連接 URL 的元數據(例如 JDBC URL 或數據庫名稱)關聯在一 起 。JdbcStatementMonitor 負責測量執行語句的性能統計值,跟蹤用來取得語句 的 連接,跟蹤與預備(和可調用)語句關聯的 SQL 字符串。清單 6 顯示了 JdbcConnectionMonitor 方面。
清單 6. JdbcConnectionMonitor 方面
/**
* Monitor performance for JDBC connections,
* and track database connection information associated with them.
*/
public aspect JdbcConnectionMonitor extends AbstractRequestMonitor {
/** A call to establish a connection using a
* <code>DataSource</code>
*/
public pointcut dataSourceConnectionCall(DataSource dataSource) :
call(Connection+ DataSource.getConnection (..))
&& target(dataSource);
/** A call to establish a connection using a URL string */
public pointcut directConnectionCall(String url) :
(call(Connection+ Driver.connect(..)) || call(Connection+
DriverManager.getConnection(..))) &&
args(url, ..);
/** A database connection call nested beneath another one
* (common with proxies).
*/
public pointcut nestedConnectionCall() :
cflowbelow (dataSourceConnectionCall(*) ||
directConnectionCall (*));
/** Monitor data source connections using
* the worker object pattern
*/
Connection around(final DataSource dataSource) :
dataSourceConnectionCall(dataSource)
&& !nestedConnectionCall() {
RequestContext requestContext =
new ConnectionRequestContext() {
public Object doExecute() {
accessingConnection(dataSource);
// set up stats early in case needed
Connection connection = proceed(dataSource);
return addConnection(connection);
}
};
return (Connection)requestContext.execute();
}
/** Monitor url connections using the worker object pattern */
Connection around(final String url) : directConnectionCall(url)
&& !nestedConnectionCall() {
RequestContext requestContext =
new ConnectionRequestContext() {
public Object doExecute() {
accessingConnection(url);
Connection connection = proceed(url);
return addConnection (connection);
}
};
return (Connection)requestContext.execute();
}
/** Get stored name associated with this data source. */
public String getDatabaseName(Connection connection) {
synchronized (connections) {
return (String)connections.get (connection);
}
}
/** Use common accessors to return meaningful name
* for the resource accessed by this data source.
*/
public String getNameForDataSource (DataSource ds) {
// methods used to get names are listed in descending
// preference order
String possibleNames[] =
{ "getDatabaseName",
"getDatabasename",
"getUrl", "getURL",
"getDataSourceName",
"getDescription" };
String name = null;
for (int i=0; name == null &&
i<possibleNames.length; i++) {
try {
Method method =
ds.getClass().getMethod(possibleNames[i], null);
name = (String)method.invoke(ds, null);
} catch (Exception e) {
// keep trying
}
}
return (name != null) ? name : "unknown";
}
/** Holds JDBC connection-specific context information:
* a database name and statistics
*/
protected abstract class ConnectionRequestContext
extends RequestContext {
private ResourceStats dbStats;
/** set up context statistics for accessing
* this data source
*/
protected void
accessingConnection (final DataSource dataSource) {
addConnection (getNameForDataSource(dataSource),
connection);
}
/** set up context statistics for accessing this database */
protected void accessingConnection(String databaseName) {
this.databaseName = databaseName;
// might be null if there is database access
// caused from a request I'm not tracking...
if (getParent() != null) {
OperationStats opStats =
(OperationStats)getParent().getStats();
dbStats = opStats.getDatabaseStats(databaseName);
}
}
/** record the database name for this database connection */
protected Connection
addConnection(final Connection connection) {
synchronized(connections) {
connections.put (connection, databaseName);
}
return connection;
}
protected PerfStats lookupStats() {
return dbStats;
}
};
/** Associates connections with their database names */
private Map/*<Connection,String>*/ connections =
new WeakIdentityHashMap();
}
清單 6 顯示了利用 AspectJ 和 JDBC API 跟蹤數據庫連接的方面。它用一 個 圖來關聯數據庫名稱和每個 JDBC 連接。
在 jdbcConnectionMonitor 內部
在清單 6 顯示的 JdbcConnectionMonitor 內部,我定義了切入點,捕捉連 接 數據庫的兩種不同方式:通過數據源或直接通過 JDBC URL。連接監視器包含針 對 每種情況的監視建議,兩種情況都設置一個工人對象。doExecute() 方法啟動時 處理原始連接,然後把返回的連接傳遞給兩個輔助方法中名為 addConnection 的 一個。在兩種情況下,被建議的切入點會排除來自另一個連接的連接調用(例如 ,如果要連接到數據源,會造成建立 JDBC 連接)。
數據源的 addConnection() 委托輔助方法 getNameForDataSource() 從數據 源確定數據庫的名稱。DataSource 接口不提供任何這類機制,但是幾乎每個實 現 都提供了 getDatabaseName() 方法。getNameForDataSource() 用反射來嘗試完 成這項工作和其他少數常見(和不太常見)的方法,為數據庫源提供一個有用的 標識。addConnection() 方法然後委托給 addConnection() 方法,這個方法用 字 符串參數作為名稱。
被委托的 addConnection() 方法從父請求的上下文中檢索可以操作的統計值 ,並根據與指定連接關聯的數據庫名稱(或其他描述字符串)查詢數據庫的統計 值。然後它把這條信息保存在請求上下文對象的 dbStats 字段中,更新關於獲 得 連接的性能信息。這樣就可以跟蹤連接數據庫需要的時間(通常這實際是從池中 得到連接所需要的時間)。addConnection() 方法也更新到數據庫名稱的連接的 連接圖。隨後在執行 JDBC 語句更新對應請求的統計值時,會使用這個圖。 JdbcConnectionMonitor 還提供了一個輔助方法 getDatabaseName(),它從連接 圖中查詢字符串名稱找到連接。
弱標識圖和方面
JDBC 監視方面使用 弱標識 哈希圖。這些圖持有 弱 引用,允許連接這樣的 被跟蹤對象在只有方面引用它們的時候,被垃圾收集掉。這一點很重要,因為單 體的方面通常 不會 被垃圾收集。如果引用不弱,那麼應用程序會有內存洩漏。 方面用 標識 圖來避免調用連接或語句的hashCode 或 equals 方法。這很重要 , 因為我想跟蹤連接和語句,而不理會它們的狀態:我不想遇到來自 hashCode 方 法的異常,也不想在對象的內部狀態已經改變時(例如關閉時),指望對象的哈 希碼保持不變。我在處理動態的基於代理的 JDBC 對象(就像來自 iBatis 的那 些對象)時遇到了這個問題:在連接已經關閉之後調用對象上的方法就會拋出異 常。在完成操作之後還想記錄統計值時會造成錯誤。
從這裡可以學到的教訓是:把對第三方代碼的假設最小化。使用標識圖是避 免 對接受建議的代碼的實現邏輯進行猜測的好方法。在這種情況下,我使用了來自 DCL Java 工具的 WeakIdentityHashMap 開放源碼實現(請參閱 參考資料)。 跟 蹤連接或語句的元數據信息讓我可以跨越請求,針對連接或語句把統計值分組。 這意味著可以只根據對象實例進行跟蹤,而不需要使用對象等價性來跟蹤這些 JDBC 對象。另一個要記住的教訓是:不同的對象經常用不同的修飾器包裝(越 來 越多地采用動態代理) JDBC 對象。所以假設要處理的是這類接口的簡單而原始 的實現,可不是一個好主意!
jdbcStatementMonitor 內部
清單 7 顯示了 JdbcStatementMonitor 方面。這個方面有兩個主要職責:跟 蹤與創建和准備語句有關的信息,然後監視 JDBC 語句執行的性能統計值。
清單 7. JdbcStatementMonitor 方面
/**
* Monitor performance for executing JDBC statements,
* and track the connections used to create them,
* and the SQL used to prepare them (if appropriate).
*/
public aspect JdbcStatementMonitor extends AbstractRequestMonitor {
/** Matches any execution of a JDBC statement */
public pointcut statementExec(Statement statement) :
call(* java.sql..*.execute*(..)) &&
target (statement);
/**
* Store the sanitized SQL for dynamic statements.
*/
before(Statement statement, String sql,
RequestContext parentContext):
statementExec(statement) && args(sql, ..)
&& inRequest(parentContext) {
sql = stripAfterWhere(sql);
setUpStatement(statement, sql, parentContext);
}
/** Monitor performance for executing a JDBC statement. */
Object around(final Statement statement) :
statementExec (statement) {
RequestContext requestContext =
new StatementRequestContext() {
public Object doExecute () {
return proceed(statement);
}
};
return requestContext.execute();
}
/**
* Call to create a Statement.
* @param connection the connection called to
* create the statement, which is bound to
* track the statement's origin
*/
public pointcut callCreateStatement(Connection connection):
call(Statement+ Connection.*(..))
&& target (connection);
/**
* Track origin of statements, to properly
* associate statistics even in
* the presence of wrapped connections
*/
after(Connection connection) returning (Statement statement):
callCreateStatement (connection) {
synchronized (JdbcStatementMonitor.this) {
statementCreators.put(statement, connection);
}
}
/**
* A call to prepare a statement.
* @param sql The SQL string prepared by the statement.
*/
public pointcut callCreatePreparedStatement(String sql):
call(PreparedStatement+ Connection.*(String, ..))
&& args(sql, ..);
/** Track SQL used to prepare a prepared statement */
after(String sql) returning (PreparedStatement statement):
callCreatePreparedStatement (sql) {
setUpStatement(statement, sql);
}
protected abstract class StatementRequestContext
extends RequestContext {
/**
* Find statistics for this statement, looking for its
* SQL string in the parent request's statistics context
*/
protected PerfStats lookupStats() {
if (getParent() != null) {
Connection connection = null;
String sql = null;
synchronized (JdbcStatementMonitor.this) {
connection =
(Connection) statementCreators.get(statement);
sql = (String) statementSql.get(statement);
}
if (connection != null) {
String databaseName =
JdbcConnectionMonitor.aspectOf ().
getDatabaseName(connection);
if (databaseName != null && sql != null) {
OperationStats opStats =
(OperationStats) getParent().getStats();
if (opStats != null) {
ResourceStats dbStats =
opStats.getDatabaseStats (databaseName);
return dbStats.getRequestStats(sql);
}
}
}
}
return null;
}
}
/**
* To group sensibly and to avoid recording sensitive data,
* I don't record the where clause (only used for dynamic
* SQL since parameters aren't included
* in prepared statements)
* @return subset of passed SQL up to the where clause
*/
public static String stripAfterWhere(String sql) {
for (int i=0; i<sql.length()-4; i++) {
if (sql.charAt(i)=='w' || sql.charAt(i)==
'W') {
if (sql.substring(i+1, i+5).equalsIgnoreCase(
"here"))
{
sql = sql.substring(0, i);
}
}
}
return sql;
}
private synchronized void
setUpStatement(Statement statement, String sql) {
statementSql.put(statement, sql);
}
/** associate statements with the connections
* called to create them
*/
private Map/*<Statement,Connection>*/ statementCreators =
new WeakIdentityHashMap();
/** associate statements with the
* underlying string they execute
*/
private Map/*<Statement,String>*/ statementSql =
new WeakIdentityHashMap();
}
JdbcStatementMonitor 維護兩個弱標識圖:statementCreators 和 statementSql。第一個圖跟蹤用來創建語句的連接。正如前面提示過的,我不想 依賴這條語句的 getConnection 方法,因為它會引用一個包裝過的連接,而我 沒 有這個連接的元數據。請注意 callCreateStatement 切入點,我建議它去監視 JDBC 語句的執行。這個建議匹配的方法調用是在 JDBC 連接上定義的,而且會 返 回 Statement 或任何子類。這個建議可以匹配 JDBC 中 12 種不同的可以創建 或 准備語句的方式,而且是為了適應 JDBC API 未來的擴展而設計的。
statementSql 圖跟蹤指定語句執行的 SQL 字符串。這個圖用兩種不同的方 式 更新。在創建預備語句(包括可調用語句)時,在創建時捕捉到 SQL 字符串參 數 。對於動態 SQL 語句,SQL 字符串參數在監視建議使用它之前,從語句執行調 用 中被捕捉。(建議的先後次序在這裡沒影響;雖然是在執行完成之後才用建議查 詢統計值,但字符串是在執行發生之前捕捉的。)
語句的性能監視由一個 around 建議處理,它在執行 JDBC 語句的時候設置 工 人對象。執行 JDBC 語句的 statementExec 切入點會捕捉 JDBC Statement(包 括子類)實例上名稱以 execute 開始的任何方法的調用,方法是在 JDBC API 中 定義的(也就是說,在任何名稱以 java.sql 開始的包中)。
工人對象上的 lookupStats() 方法使用雙親(servlet)的統計上下文來查 詢 指定連接的數據庫統計值,然後查詢指定 SQL 字符串的 JDBC 語句統計值。直 接 的語句執行方法包括:SQL 語句中在 where 子句之後剝離數據的附加邏輯。這 就 避免了暴露敏感數據的風險,而且也允許把常見語句分組。更復雜的方式就是剝 離查詢參數而已。但是,多數應用程序使用預備語句而不是動態 SQL 語句,所 以 我不想深入這一部分。
跟蹤 JDBC 信息
在結束之前,關於監視方面如何解決跟蹤 JDBC 信息的挑戰,請靜想一分鐘 。 JdbcConnectionMonitor 讓我把數據庫的文本描述(例如 JDBC URL)與用來訪 問 數據庫的連接關聯起來。同樣,JdbcStatementMonitor 中的 statementSql 映 射 跟蹤 SQL 字符串(甚至是用於預備語句的字符串),從而確保可以用有意義的 名 稱,把執行的查詢分成有意義的組。最後,JdbcStatementMonitor 中的 statementCreators 映射讓我把語句與我擁有句柄(而不是包裝過)的連接關聯 。這種方式整合了多個建議,在把方面應用到現實問題時,更新內部狀態非常有 用。在許多情況下,需要跟蹤來自 一系列 切入點的上下文信息,在單一公開上 下文的 AspectJ 切入點中無法捕捉到這個信息。在出現這種情況時,一個切入 點 的跟蹤狀態可以在後一個切入點中使用這項技術就會非常有幫助。
這個信息可用之後,JdbcStatementMonitor 就能夠很自然地監視性能了。在 語句執行切入點上的實際建議只是遵循標准方法 ,創建工人對象繼續處理原始 的 計算。lookupStats() 方法使用這三個不同的映射來查詢與這條語句關聯的連接 和 SQL。然後它用它的雙親請求,根據連接的描述找到正確的數據庫統計值,並 根據 SQL 鍵字符串找到語句統計值。lookupStats() 是防御性的,也就是說它 在 應用程序的使用違背預期的時候,會檢查 null 值。在這篇文章的第二部分,我 將介紹如何用 AOP 系統地保證監視代碼不會在被監視的應用程序中造成問題。
第 1 部分結束語
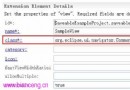
迄今為止,我構建了一個核心的監視基礎設施,可以系統地跟蹤應用程序的 性 能、測量 servlet 操作中的數據庫活動。監視代碼可以自然地插入 JMX 接口來 公開結果,如圖 5 所示。代碼已經能夠監視重要的應用程序邏輯,您也已經看 到 了擴展和更新監視方式有多容易。
圖 5. 監視數據庫結果
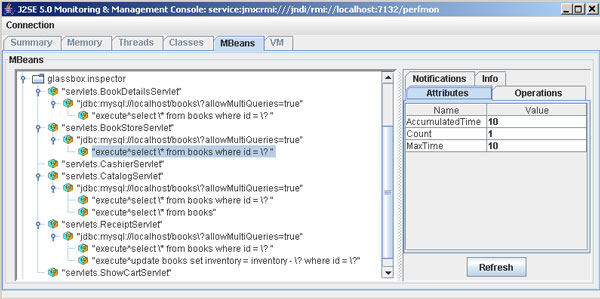
雖然這裡提供的代碼相當簡單,但卻是對傳統方式的巨大修改。AspectJ 模 塊 化的方式讓我可以精確且一致地處理監視功能。比起在整個示例應用程序中用分 散的調用更新統計值和跟蹤上下文,這是一個重大的改進。即使使用對象來封裝 統計跟蹤,傳統的方式對於每個用戶操作和每個資源訪問,也都需要多個調用。 實現這樣的一致性會很繁瑣,也很難一次實現,更不用說維護了。
在這篇文章的第二部分中,我將把重點放在開發和部署基於 AOP 的性能監視 系統的編程問題上。我將介紹如何用 AspectJ 5 的裝入時編織來監視運行在 Apache Tomcat 中的多個應用程序,包括在第三方庫中進行監視。我將介紹如何 測量監視的開銷,如何選擇性地在運行時啟用監視,如何測量裝入時編織的性能 和內存影響。我還會介紹如何用方面防止監視代碼中的錯誤造成應用程序錯誤。 最後,我將擴展 Glassbox Inspector,讓它支持 Web 服務和常見的 Web 應用 程 序框架(例如 Struts 和 Spring )並跟蹤應用程序錯誤。歡迎繼續閱讀!