簡介:在 Web 2.0 時代,NoSQL 數據存儲(比如 Bigtable 和 CouchDB)從 邊緣進入主流,因為它們能夠解決伸縮性問題,而且能夠大規模解決該問題。 Google 和 Facebook 只是已經開始使用 NoSQL 數據存儲的兩家知名公司,我們 仍然處於使用 NoSQL 數據存儲的早期階段。無模式數據存儲與傳統的關系數據庫 存在根本區別,但是利用它們比您想象的要簡單得多,尤其是當您從一個域模型 而不是一個關系模型開始時。
關系數據庫已經統治數據存儲 30 多年了,但是無模式(或 NoSQL)數據庫的 逐漸流行表明變化正在發生。盡管 RDBMS 為在傳統的客戶端 - 服務器架構中存 儲數據提供了一個堅實的基礎,但它不能輕松地(或便宜地)擴展到多個節點。 在高度可伸縮的 Web 應用程序(比如 Facebook 和 Twitter)的時代,這是一個 非常不幸的弱點。
盡管關系數據庫的早期替代方案(還記得面向對象的數據庫嗎?)不能解決真 正緊急的問題,NoSQL 數據庫(比如 Google 的 Bigtable 和 Amazon 的 SimpleDB)卻作為對 Web 的高可伸縮性需求的直接響應而崛起。本質上,NoSQL 可能是一個殺手問題的殺手應用程序 —隨著 Web 2.0 的演變,Web 應用程序開 發人員可能會遇到更多,而不是更少這樣的應用程序。
在這期 Java 開發 2.0 中,我將向您介紹無模式數據建模,這是經過關系思 維模式訓練的許多開發人員使用 NoSQL 的主要障礙。您將了解到,從一個域模型 (而不是關系模型)入手是簡化您的改變的關鍵。如果您使用 Bigtable(如我的 示例所示),您可以借助 Gaelyk:Google App Engine 的一個輕量級框架擴展。
NoSQL:一種新的思維方式?
當開發人員談論非關系或 NoSQL 數據庫時,經常提到的第一件事是他們需要 改變思維方式。我認為,那實際上取決於您的初始數據建模方法。如果您習慣通 過首先建模數據庫結構(即首先確定表及其關聯關系)來設計應用程序,那麼使 用一個無模式數據存儲(比如 Bigtable)來進行數據建模則需要您重新思考您的 做事方式。但是,如果您從域模型開始設計您的應用程序,那麼 Bigtable 的無 模式結構將看起來更自然。
為實現伸縮性而構建
伴隨高度可伸縮的 Web 應用程序面臨的新問題而來的是一些新的解決方案。 Facebook 並不依賴於一個關系數據庫來解決其存儲需求;相反,它使用一個 “ 鍵 / 值” 存儲 —主要是一個高性能 HashMap。稱為 Cassandra 的內部解決方 案也被 Twitter 和 Digg 使用,並在最近捐獻給了 Apache Software Foundation。Google 是另一個 Web 實體,它的爆炸式增長要求它尋求一個非關 系數據存儲 —Bigtable 就是尋求的結果。
非關系數據存儲沒有聯接表或主鍵,甚至沒有外鍵這個概念(盡管這兩種類型 的鍵以一種更松散的形式出現)。因此,如果您嘗試將關系建模作為一個 NoSQL 數據庫中的數據建模的基礎,那麼您可能最後以失敗告終。從域模型開始將使事 情變得簡單;實際上,我已經發現,域模型下的無模式結構的靈活性正在重新煥 發生機。
從關系數據模型遷移到無模式數據模型的相對復雜程度取決於您的方法:即您 從基於關系的設計開始還是從基於域的設計開始。當您遷移到 CouchDB 或 Bigtable 這樣的數據庫時,您 的確會喪失 Hibernate(至少現在)這樣的成熟 的持久存儲平台的順暢感覺。另一方面,您卻擁有能夠親自構建它的 “綠地效果 ”。在此過程中,您將深入了解無模式數據存儲。
實體和關系
無模式數據存儲賦予您首先使用對象來設計域模型的靈活性(Grails 這樣的 較新的框架自動支持這種靈活性)。您的下一步工作是將您的域映射到底層數據 存儲,這在使用 Google App Engine 時再簡單不過了。
在文章 “Java 開發 2.0:針對 Google App Engine 的 Gaelyk” 中,我介 紹了 Gaelyk —— 一個基於 Groovy 的框架,該框架有利於使用 Google 的底層 數據存儲。那篇文章的主要部分關注如何利用 Google 的 Entity對象。下面的示 例(來自那篇文章)將展示對象實體如何在 Gaelyk 中工作。
清單 1. 使用 Entity 的對象持久存儲
def ticket = new Entity("ticket")
ticket.officer = params.officer
ticket.license = params.plate
ticket.issuseDate = offensedate
ticket.location = params.location
ticket.notes = params.notes
ticket.offense = params.offense
通過對象設計
傾向於對象模型而不是數據庫的設計的模式在 Grails 和 Ruby on Rails 這 樣的現代 Web 應用程序框架中展現出來,這些現代 Web 應用程序框架強調對象 模型的設計,並為您處理底層數據庫架構創建。
這種對象持久存儲方法很有效,但容易看出,如果您頻繁使用票據實體 —例 如,如果您正在各種 servlet 中創建(或查找)它們,那麼這種方法將變得令人 厭煩。使用一個公共 servlet(或 Groovlet)來為您處理這些任務將消除其中一 些負擔。一種更自然的選擇 —我將稍後展示 —將是建模一個 Ticket對象。
返回比賽
我不會重復 Gaelyk 簡介中的那個票據示例,相反,為保持新鮮感,我將在本 文中使用一個賽跑主題,並構建一個應用程序來展示即將討論的技術。
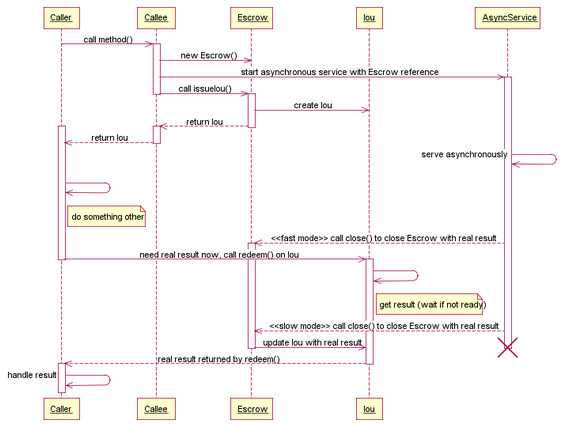
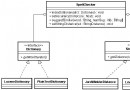
如圖 1 中的 “多對多” 圖表所示,一個 Race擁有多個 Runner,一個 Runner可以屬於多個 Race。
圖 1. 比賽和參賽者

如果我要使用一個關系表結構來設計這個關系,至少需要 3 個表:第 3 表將 是鏈接一個 “多對多” 關系的聯接表。所幸我不必局限於關系數據模型。相反 ,我將使用 Gaelyk(和 Groovy 代碼)將這個 “多對多” 關系映射到 Google 針對 Google App Engine 的 Bigtable 抽象。事實上,Gaelyk 允許將 Entity當 作 Map,這使得映射過程相當簡單。
通過 Shards 伸縮
Sharding是一種分區形式,它將一個表結構復制到多個節點,但邏輯上在各節 點之間劃分數據。例如,一個節點可以擁有駐留在美國的帳戶的所有相關數據, 而另一個節點則針對駐留在歐洲的所有帳戶。但如果節點擁有關系 —即跨 Shard 聯接,Shards 就會出現問題。這是一個棘手的問題,在很多情況下都無法解決。
無模式數據存儲的好處之一是無須事先知道所有事情,也就是說,與使用關系 數據庫架構相比,可以更輕松地適應變化。(注意,我並非暗示不能更改架構; 我只是說,可以更輕松地適應變化。)我不打算定義我的域對象上的屬性 —我將 其推遲到 Groovy 的動態特性(實際上,這個特性允許創建針對 Google 的 Entity對象的域對象代理)。相反,我將把我的時間花費在確定如何查找對象並 處理關系上。這是 NoSQL 和各種利用無模式數據存儲的框架還沒有內置的功能。
Model 基類
我將首先創建一個基類,用於容納 Entity對象的一個實例。然後,我將允許 一些子類擁有一些動態屬性,這些動態屬性將通過 Groovy 的方便的 setProperty方法添加到對應的 Entity實例。setProperty針對對象中實際上不存 在的任何屬性設置程序調用。(如果這聽起來聳人聽聞,不用擔心,您看到它的 實際運行後就會明白。)
清單 2 展示了位於我的示例應用程序的一個 Model實例的第一個 stab:
清單 2. 一個簡單的 Model 基類
package com.b50.nosql
import com.google.appengine.api.datastore.DatastoreServiceFactory
import com.google.appengine.api.datastore.Entity
abstract class Model {
def entity
static def datastore = DatastoreServiceFactory.datastoreService
public Model(){
super()
}
public Model(params){
this.@entity = new Entity(this.getClass().simpleName)
params.each{ key, val ->
this.setProperty key, val
}
}
def getProperty(String name) {
if(name.equals("id")){
return entity.key.id
}else{
return entity."${name}"
}
}
void setProperty(String name, value) {
entity."${name}" = value
}
def save(){
this.entity.save()
}
}
注意抽象類如何定義一個構造函數,該函數接收屬性的一個 Map —我總是可 以稍後添加更多構造函數,稍後我就會這麼做。這個設置對於 Web 框架十分方便 ,這些框架通常采用從表單提交的參數。Gaelyk 和 Grails 將這樣的參數巧妙地 封裝到一個稱為 params的對象中。這個構造函數迭代這個 Map並針對每個 “鍵 / 值” 對調用 setProperty方法。
檢查一下 setProperty方法就會發現 “鍵” 設置為底層 entity的屬性名稱 ,而對應的 “值” 是該 entity的值。
Groovy 技巧
如前所述,Groovy 的動態特性允許我通過 get和 setProperty方法捕獲對不 存在的屬性的方法調用。這樣,清單 2 中的 Model的子類不必定義它們自己的屬 性 —它們只是將對一個屬性的所有調用委托給這個底層 entity對象。
清單 2 中的代碼執行了一些特定於 Groovy 的操作,值得一提。首先,可以 通過在一個屬性前面附加一個 @來繞過該屬性的訪問器方法。我必須對構造函數 中的 entity對象引用執行上述操作,否則我將調用 setProperty方法。很明顯, 在這個關頭調用 setProperty將打破這種模式,因為 setProperty方法中的 entity變量將是 null。
其次,構造函數中的調用 this.getClass().simpleName將設置 entity的 “ 種類” — simpleName屬性將生成一個不帶包前綴的子類名稱(注意, simpleName的確是對 getSimpleName的調用,但 Groovy 允許我不通過對應的 JavaBeans 式的方法調用來嘗試訪問一個屬性)。
最後,如果對 id屬性(即,對象的鍵)進行一個調用,getProperty方法很智 能,能夠詢問底層 key以獲取它的 id。在 Google App Engine 中,entities的 key屬性將自動生成。
Race 子類
定義 Race子類很簡單,如清單 3 所示:
清單 3. 一個 Race 子類
package com.b50.nosql
class Race extends Model {
public Race(params){
super(params)
}
}
當一個子類使用一列參數(即一個包含多個 “鍵 / 值” 對的 Map)實例化 時,一個對應的 entity將在內存中創建。要持久存儲它,只需調用 save方法。
清單 4. 創建一個 Race 實例並將其保存到 GAE 的數據存儲
import com.b50.nosql.Runner
def iparams = [:]
def formatter = new SimpleDateFormat("MM/dd/yyyy")
def rdate = formatter.parse("04/17/2010")
iparams["name"] = "Charlottesville Marathon"
iparams["date"] = rdate
iparams["distance"] = 26.2 as double
def race = new Race(iparams)
race.save()
清單 4 是一個 Groovlet,其中,一個 Map(稱為 iparams)創建為帶有 3 個屬性 —一次比賽的名稱、日期和距離。(注意,在 Groovy 中,一個空白 Map 通過 [:]創建。)Race的一個新實例被創建,然後通過 save方法存儲到底層數據 存儲。
可以通過 Google App Engine 控制台來查看底層數據存儲,確保我的數據的 確在那裡,如圖 2 所示:
圖 2. 查看新創建的 Race
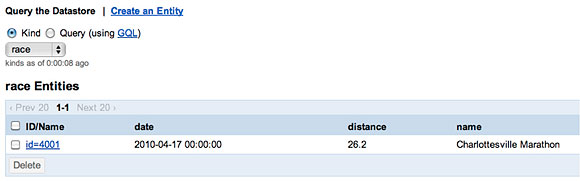
查找程序方法生成持久存儲的實體
現在我已經存儲了一個 Entity,擁有查找它的能力將有所幫助。接下來,我 可以添加一個 “查找程序” 方法。在本例中,我將把這個 “查找程序” 方法 創建為一個類方法(static)並且允許通過名稱查找這些 Race(即基於 name屬 性搜索)。稍後,總是可以通過其他屬性添加其他查找程序。
我還打算對我的查找程序采用一個慣例,即指定:任何名稱中不帶單詞 all的 查找程序都企圖找到 一個實例。名稱中包含單詞 all的查找程序(如 findAllByName)能夠返回一個實例 Collection或 List。清單 5 展示了 findByName查找程序:
清單 5. 一個基於 Entity 名稱搜索的簡單查找程序
static def findByName(name){
def query = new Query(Race.class.simpleName)
query.addFilter("name", Query.FilterOperator.EQUAL, name)
def preparedQuery = this.datastore.prepare(query)
if(preparedQuery.countEntities() > 1){
return new Race(preparedQuery.asList(withLimit(1))[0])
}else{
return new Race(preparedQuery.asSingleEntity())
}
}
這個簡單的查找程序使用 Google App Engine 的 Query和 PreparedQuery類 型來查找一個類型為 “Race” 的實體,其名稱(完全)等同於傳入的名稱。如 果有超過一個 Race符合這個標准,查找程序將返回一個列表的第一項,這是分頁 限制 1(withLimit(1))所指定的。
對應的 findAllByName與上述方法類似,但添加了一個參數,指定 您想要的 實體個數,如清單 6 所示:
清單 6. 通過名稱找到全部實體
static def findAllByName(name, pagination=10){
def query = new Query(Race.class.getSimpleName())
query.addFilter("name", Query.FilterOperator.EQUAL, name)
def preparedQuery = this.datastore.prepare(query)
def entities = preparedQuery.asList(withLimit(pagination as int))
return entities.collect { new Race(it as Entity) }
}
與前面定義的查找程序類似,findAllByName通過名稱找到 Race實例,但是它 返回 所有 Race。順便說一下,Groovy 的 collect方法非常靈活:它允許刪除創 建 Race實例的對應的循環。注意,Groovy 還支持方法參數的默認值;這樣,如 果我沒有傳入第 2 個值,pagination將擁有值 10。
清單 7. 查找程序的實際運行
def nrace = Race.findByName("Charlottesville Marathon")
assert nrace.distance == 26.2
def races = Race.findAllByName("Charlottesville Marathon")
assert races.class == ArrayList.class
清單 7中的查找程序按照既定的方式運行:findByName返回一個實例,而 findAllByName返回一個 Collection(假定有多個 “Charlottesville Marathon ”)。
“參賽者” 對象沒有太多不同
現在我已能夠創建並找到 Race的實例,現在可以創建一個快速的 Runner對象 了。這個過程與創建初始的 Race實例一樣簡單,只需如清單 8 所示擴展 Model :
清單 8. 創建一個參賽者很簡單
package com.b50.nosql
class Runner extends Model{
public Runner(params){
super(params)
}
}
看看 清單 8,我感覺自己幾乎完成工作了。但是,我還需創建參賽者和比賽 之間的鏈接。當然,我將把它建模為一個 “多對多” 關系,因為我希望我的參 賽者可以參加多項比賽。
沒有架構的域建模
Google App Engine 在 Bigtable 上面的抽象不是一個面向對象的抽象;即, 我不能原樣存儲關系,但可以共享鍵。因此,為建模多個 Race和多個 Runner之 間的關系,我將在每個 Race實例中存儲一列 Runner鍵,並在每個 Runner實例中 存儲一列 Race鍵。
我必須對我的鍵共享機制添加一點邏輯,但是,因為我希望生成的 API 比較 自然 —我不想詢問一個 Race以獲取一列 Runner鍵,因此我想要一列 Runner。 幸運的是,這並不難實現。
在清單 9 中,我已經添加了兩個方法到 Race實例。但一個 Runner實例被傳 遞到 addRunner方法時,它的對應 id被添加到底層 entity的 runners屬性中駐 留的 id的 Collection。如果有一個現成的 runners的 collection,則新的 Runner實例鍵將添加到它;否則,將創建一個新的 Collection,且這個 Runner 的鍵(實體上的 id屬性)將添加到它。
清單 9. 添加並檢索參賽者
def addRunner(runner){
if(this.@entity.runners){
this.@entity.runners << runner.id
}else{
this.@entity.runners = [runner.id]
}
}
def getRunners(){
return this.@entity.runners.collect {
new Runner( this.getEntity(Runner.class.simpleName, it) )
}
}
當清單 9 中的 getRunners方法調用時,一個 Runner實例集合將從底層的 id 集合創建。這樣,一個新方法(getEntity)將在 Model類中創建,如清單 10 所 示:
清單 10. 從一個 id 創建一個實體
def getEntity(entityType, id){
def key = KeyFactory.createKey(entityType, id)
return this.@datastore.get(key)
}
getEntity方法使用 Google 的 KeyFactory類來創建底層鍵,它可以用於查找 數據存儲中的一個單獨實體。
最後,定義一個新的構造函數來接受一個實體類型,如清單 11 所示:
清單 11. 一個新添加的構造函數
public Model(Entity entity){
this.@entity = entity
}
如清單 9、10和 11、以及 圖 1的對象模型所示,我可以將一個 Runner添加 到任一 Race,也可以從任一 Race獲取一列 Runner實例。在清單 12 中,我在這 個等式的 Runner方上創建了一個類似的聯系。清單 12 展示了 Runner類的新方 法。
清單 12. 參賽者及其比賽
def addRace(race){
if(this.@entity.races){
this.@entity.races << race.id
}else{
this.@entity.races = [race.id]
}
}
def getRaces(){
return this.@entity.races.collect {
new Race( this.getEntity(Race.class.simpleName, it) )
}
}
這樣,我就使用一個無模式數據存儲創建了兩個域對象。
通過一些參賽者完成這個比賽
此前我所做的是創建一個 Runner實例並將其添加到一個 Race。如果我希望這 個關系是雙向的,如 圖 1中我的對象模型所示,那麼我也可以添加一些 Race實 例到一些 Runner,如清單 13 所示:
清單 13. 參加多個比賽的多個參賽者
def runner = new Runner([fname:"Chris", lname:"Smith", date:34])
runner.save()
race.addRunner(runner)
race.save()
runner.addRace(race)
runner.save()
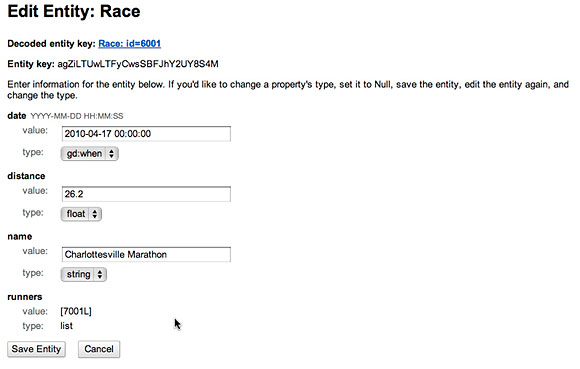
將一個新的 Runner添加到 race並添加對 Race的 save的調用後,這個數據存 儲已使用一列 ID 更新,如圖 3 中的屏幕快照所示:
圖 3. 查看一項比賽中的多個參賽者的新屬性
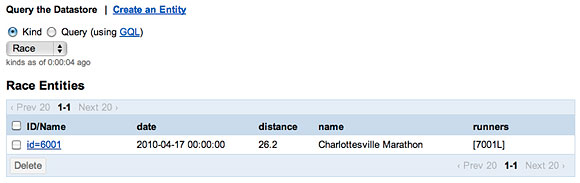
通過仔細檢查 Google App Engine 中的數據,可以看到,一個 Race實體現在 擁有了一個 Runners 的 list,如圖 4 所示。
圖 4. 查看新的參賽者列表
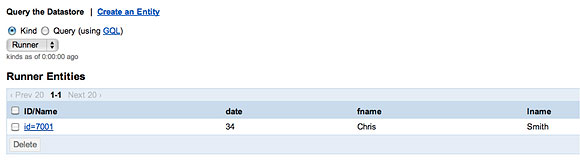
同樣,在將一個 Race添加到一個新創建的 Runner實例之前,這個屬性並不存 在,如圖 5 所示。
圖 5. 一個沒有比賽的參賽者
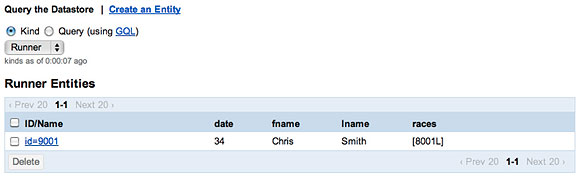
但是,將一個 Race關聯到一個 Runner後,數據存儲將添加新的 races ids 的 list。
圖 6. 一個參加比賽的參賽者
無模式數據存儲的靈活性正在刷新 —屬性按照需要自動添加到底層存儲。作 為開發人員,我無須更新或更改架構,更談不上部署架構了!
NoSQL 的利弊
當然,無模式數據建模也有利有弊。回顧上面的比賽應用程序,它的一個優勢 是非常靈活。如果我決定將一個新屬性(比如 SSN)添加到一個 Runner,我不必 進行大幅更改 —事實上,如果我將該屬性包含在構造函數的參數中,那麼它就會 自動添加。對那些沒有使用一個 SSN 創建的舊實例而言,發生了什麼事情?什麼 也沒發生!它們擁有一個值為 null的字段。
快速閱讀器
在 “NoSQL 與關系模型孰優孰劣” 的爭論中,速度是一個重要因素。對於一 個為潛在的數百萬用戶傳輸數據的現代 Web 站點(想想 Facebook 的 4 億用戶 和計數)來說,關系模型的速度太慢了,更不用說其高昂的成本。相比之下, NoSQL 的數據存儲的讀取速度非常快。
另一方面,我已經明確表明要犧牲一致性和完整性來換取效率。這個應用程序 的當前數據架構沒有向我施加任何限制 —理論上我可以為同一個對象創建無限個 實例。在 Google App Engine 引擎的鍵處理機制下,它們都有惟一的鍵,但其他 屬性都是一致的。更糟糕的是,級聯刪除不存在,因此如果我使用相同的技術來 建模一個 “一對多” 關系並刪除父節點,那麼我得到一些無效的子節點。當然 ,我可以實現自己的完整性檢查 —但關鍵是,我必須親自動手(就像完成其他任 務一樣)。
使用無模式數據存儲需要嚴明的紀律。如果我創建各種類型的 Races —有些 有名稱,有些沒有,有些有 date屬性,而另一些有 race_date屬性 —那麼我只 是在搬起石頭砸自己(或使用我的代碼的人)的腳。
當然,也有可能聯合使用 JDO、JPA 和 Google App Engine。在多個項目上使 用過關系模型和無模式模型後,我可以說 Gaelyk 的低級 API 最靈活,使用最方 便。使用 Gaelyk 的另一個好處是能夠深入了解 Bigtable 和一般的無模式數據 存儲。
結束語
流行時尚來了又去,有時無需理會它們(明智的建議來自一個衣櫥裡滿是休閒 服的家伙)。但 NoSQL 看起來不太像一種時尚,更像是高度可伸縮的 Web 應用 程序開發的一個新興基礎。NoSQL 數據庫不會替代 RDBMS,但是,它們將補充它 。無數成功的工具和框架基於關系數據庫,RDBMSs 本身似乎沒有面臨過時的危險 。
總之,NoSQL 數據庫的作用是向對象 - 關系數據模型提供一個及時的替代方 案。它們向我們展示,有些事情是可行的,並且 —對於一些特定的、高度強制的 用例 —甚至更好。無模式數據庫最適用於需要高速數據檢索和可伸縮性的多節點 Web 應用程序。它們還有一個極好的副作用,即允許開發人員從一個面向域的視 角、而不是關系視角進行數據建模。