Hibernate獲取數據的方式有不同的幾種,其與緩存結合使用的效果也不盡相同,而Hibernate中具體 怎麼使用緩存其實是我們很關心的一個問題,直接涉及到性能方面。
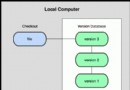
緩存在Hibernate中主要有三個方面:一級緩存、二級緩存和查詢緩存;一級緩存在Hibernate中對應 的即為session范圍的緩存,也就是當session關閉時緩存即被清除,一級緩存在Hibernate中是不可配置 的部分;二級緩存在Hibernate中對應的即為SessionFactory范圍的緩存,通常來講SessionFactory的生 命周期和應用的生命周期相同,所以可以看成是進程緩存或集群緩存,二級緩存在Hibernate中是可以配 置的,可以通過class-cache配置類粒度級別的緩存(class-cache在class中數據發生任何變化的情況下自 動更新),同時也可通過collection-cache配置集合粒度級別的緩存(collection-cache僅在collection中 增加了元素或者刪除了元素的情況下才自動更新,也就是當collection中元素發生值的變化的情況下它是 不會自動更新的),緩存自然會帶來並發的訪問問題,這個時候相應的就要根據應用來設置緩存所采用的 事務隔離級別,和數據庫的事務隔離級別概念基本一樣,沒什麼多介紹的,^_^;查詢緩存在Hibernate同 樣是可配置的,默認是關閉的,可以通過設置cache.use_query_cache為true來打開查詢緩存。根據緩存 的通常實現策略,我們可以來理解Hibernate的這三種緩存,緩存的實現通過是通過key/value的Map方式 來實現,在Hibernate的一級、二級和查詢緩存也同樣如此,一級、二級緩存使用的key均為po的主鍵ID, value即為po實例對象,查詢緩存使用的則為查詢的條件、查詢的參數、查詢的頁數,value有兩種情況, 如果采用的是select po.property這樣的方式那麼value為整個結果集,如采用的是from這樣的方式那麼 value為獲取的結果集中各po對象的主鍵ID,這樣的作用很明顯,節省內存,^_^
簡單介紹完Hibernate的緩存後,再結合Hibernate的獲取數據方式來說明緩存的具體使用方式,在 Hibernate中獲取數據常用的方式主要有四種:Session.load、Session.get、Query.list、 Query.iterator。
1、Session.load
在執行session.load時,Hibernate首先從當前session的一級緩存中獲取id對應的值,在獲取不到的 情況下,將根據該對象是否配置了二級緩存來做相應的處理,如配置了二級緩存,則從二級緩存中獲取id 對應的值,如仍然獲取不到則還需要根據是否配置了延遲加載來決定如何執行,如未配置延遲加載則從數 據庫中直接獲取,在從數據庫獲取到數據的情況下,Hibernate會相應的填充一級緩存和二級緩存,如配 置了延遲加載則直接返回一個代理類,只有在觸發代理類的調用時才進行數據庫查詢的操作。
在這樣的情況下我們就可以看到,在session一直打開的情況下,要注意在適當的時候對一級緩存進行 刷新操作,通常是在該對象具有單向關聯維護的時候,在Hibernate中可以使用象session.clear、 session.evict的方式來強制刷新一級緩存。
二級緩存則在數據發生任何變化(新增、更新、刪除)的情況下都會自動的被更新。
2、Session.get
在執行Session.get時,和Session.load不同的就是在當從緩存中獲取不到時,直接從數據庫中獲取id 對應的值。
3、Query.list
在執行Query.list時,Hibernate的做法是首先檢查是否配置了查詢緩存,如配置了則從查詢緩存中查 找key為查詢語句+查詢參數+分頁條件的值,如獲取不到則從數據庫中進行獲取,從數據庫獲取到後 Hibernate將會相應的填充一級、二級和查詢緩存,如獲取到的為直接的結果集,則直接返回,如獲取到 的為一堆id的值,則再根據id獲取相應的值(Session.load),最後形成結果集返回,可以看到,在這樣的 情況下,list也是有可能造成N次的查詢的。
查詢緩存在數據發生任何變化的情況下都會被自動的清空。
4、Query.iterator
在執行Query.iterator時,和Query.list的不同的在於從數據庫獲取的處理上,Query.iterator向數 據庫發起的是select id from這樣的語句,也就是它是先獲取符合查詢條件的id,之後在進行 iterator.next調用時才再次發起session.load的調用獲取實際的數據。
可見,在擁有二級緩存並且查詢參數多變的情況下,Query.iterator會比Query.list更為高效。
這四種獲取數據的方式都各有適用的場合,要根據實際情況做相應的決定,^_^,最好的方式無疑就是 打開show_sql選項看看執行的情況來做分析,系統結構上只用保證這種調整是容易實現的就好了,在 cache這個方面的調整自然是非常的容易,只需要調整配置文件裡的設置,而查詢的方式則可對外部進行 屏蔽,這樣要根據實際情況調整也非常容易。