簡介
多線程應用程序可以滿足當前不斷增長的業務需求,同時還可以減少所需系統 的數量。但是多線程應用程序的可伸縮性卻受不到了不可並發執行的代碼的限制 ;這些串行組件對可伸縮性造成了限制,請參見 阿達姆定律 和 I/O 問題。我們 的上一篇文章 Horizontal Scaling on a Vertical System Using Solaris Zones 介紹了如何使用分區(Zone)擴展 Xitami/NexSRS,即在每個分區中都運 行一個副本。在每個分區中都運行一個副本可將性能提升一倍,但是這仍然不是 Xitami 可伸縮問題的解決方案。一些解決方案要麼將 Long Running Web Process (LRWP) 協議遷移到 Sun Web Server,要麼讓 NexSRS 使用 Netscape Server API (NSAPI)。我們決定采用完全不同的方式:在 Java 中實現 LRWP 協 議並在 Web 容器中運行。GlassFish 是現行可用的開放源碼項目,因此我們選擇 使用 GlassFish 來實現我們的想法。我們期望這種方式在小型系統上的性能能夠 接近 Xitami/NexSRS 性能,並且可以很好地擴展到較大的系統中。
實現要快於 Xitami/NexSRS —— Xitami 是使用 C 語言編寫的一款非常小的 Web 服務器,而且名列十佳 Web 服務器之一。我們的實現可以更好地擴展到較大 的 CMT 系統中,但是使用 Java 實現 LRWP 在單核系統中具有 23% 的性能優勢 ,而在 4 核系統中具有 78% 的性能優勢,這顯示了其從單核系統到多核系統的 可伸縮性,而 Xitami 實現擴展到 4 核系統上只能達到約 15K CPM。如圖 1 所 示。
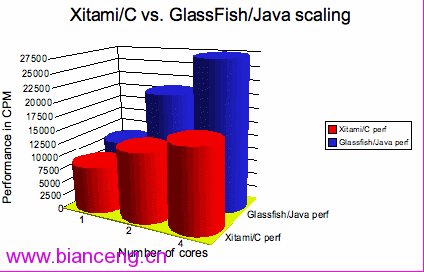
圖 1:Xitami/C 與 GlassFish/Java 的可伸縮性比較
Long Running Web Process (LRWP)
Xitami Web 服務器使用 LRWP 協議與其對等體(peer)進行通信。對等體是 與 Web 客戶機通信的進程。Web 客戶機可以是浏覽器或其他類型的使用 HTTP 通 信的客戶機。LRWP 類似於這樣一種 CGI:Web 客戶機請求調用 cgi-bin/context ,cgi-bin/context 允許 Web 容器調用 cgi-bin 可執行程序,並將來自 Web 客 戶機的輸入傳遞給可執行程序,再將輸出返回給 Web 客戶機。在 LRWP 中,LRWP 對等體與 LRWP 代理之間將建立一個 TCP 連接。LRWP 代理可以是 Web 容器或運 行在 Web 容器中的進程,LRWP 對等體可以是運行於網絡中的任何進程。連接時 ,LRWP 對等體將注冊感興趣的 Web 上下文。Web 上下文可以是任何上下文,比 如說 /osp 、/tep 或 /cgi-bin 本身。當針對該上下文發起請求時,代理會將輸 入傳遞給 LRWP 對等體,並將對等體返回的輸出發送給 Web 客戶機。LRWP 代理 還可以同時支持多個對等體。對等體可以是一個進程中的多個不同線程,也可以 多個進程。各個對等體將建立連接並注冊感的上下文。
使用 Java 實現 LRWP
要使用 Java 實現此協議,我們需要一個 Web 容器來處理 HTTP。由於 ISV 比較喜歡開放源碼的 Web 容器,因此我們選擇使用 GlassFish。GlassFish 是一 款 Java Platform Enterprise Edition (Java EE) 應用服務器,它構建於 Apache Tomcat Web 容器之上。它使用 servlets 監聽 HTTP 請求,並將請求傳 遞給在容器中運行的 LRWP 代理。然後,LRWP 代理將請求傳遞給正確的 LRWP對 等體,並將應答返回給 servlet。LRWP 代理服務器將注冊對等體感興趣的上下文 並等待對這些上下文的請求。如果有請求匹配某個上下文,則 servlet 線程將進 入上下文鎖定休眠狀態,然後代理會將該請求傳遞給 LRWP 對等體,並等待對等 體的應答,然後喚醒 servlet 線程並將應答傳遞給它。最後,servlet 線程將應 答返回給 Web 客戶機。
使用 Java 實現 LRWP
我們已經實現了 LRWP 代理,即通過一個 Web 應用程序監聽 "/*" 上下文, 這樣所有請求都將傳入這個應用程序。如果請求的對象是 LRWP 對等體注冊的某 個上下文,則將請求傳遞給 LRWP 對等體進行下一步處理;如果請求的對象是未 通過 LRWP 代理注冊的上下文,則將該請求發送給默認 servlet 使用 ServletContext RequestDispatcher 對象進行下一步處理。希望提供 LRWP 服務 的 Service Provider(LRWP 對等體應用程序)必須通過 LRWP 代理使用 LRWP 協議注冊自己。經過初始信息交換之後(依照 LRWP 協議),LRWP 代理和對等體 之間將通過 LRWP RequestHandler 建立起連接。每個對等體應用程序將創建一個 LRWP RequestHandler 實例。對等體應用程序將注冊一個相關的 URL 上下文,對 該上下文的請求都將轉發給對等體應用程序。LRWP 對等體可以與 LRWP 代理建立 多個連接,從而通過注冊相同的上下文實現負載均衡。LRWP 對等體應用程序還可 以注冊多個 URL 上下文。
與 LRWP 對等體和 NexSRS 的集成
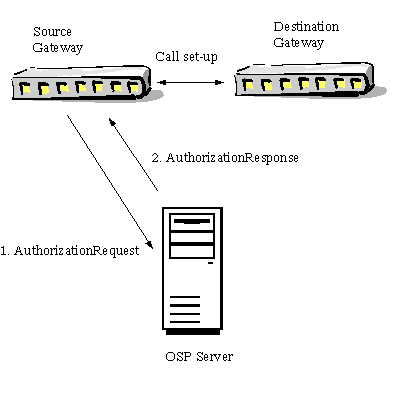
Open Settlements Protocol (OSP) 是 VoIP 載體(carrier)的一個國際標 准,它為 IP 通信提供了安全機制。OSP 服務器用於授權在對等 VoIP 網關之間 建立呼叫,如 圖 1 所示。源網關(發起呼叫建立的網關)發送一個授權請求消 息給 OSP 服務器,以獲取目標網關的 IP 地址從而完成該號碼的呼叫。OSP 服務 器向源網關發回一個授權應答消息。授權應答消息包含可完成呼叫的目標網關的 IP 地址,以及源網關在呼叫建立過程中需要使用的數字簽名令牌(digitally signed token)。源網關使用該數字簽名令牌連接目標網關;然後,目標網關驗 證該令牌是否來自受信任源。
呼叫結束時,源網關和目標網關都會向 OSP 服務器發送一個 UsageIndication 消息。然後,OSP 服務器向源網關和目標網關發送一個 UsageConfirmation 消息表示對 UsageIndication 消息的確認,如圖 2 所示。
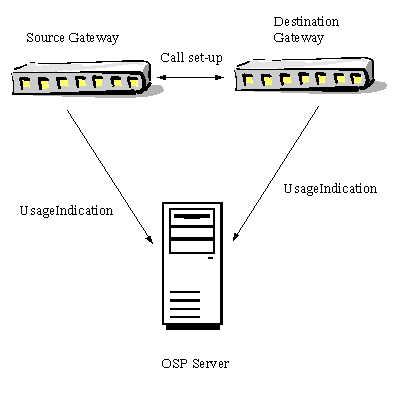
圖 2: UsageConfirmation 消息
NexSRS 是一個多線程的 OSP 服務器並且也是一個 LRWP 對等體。客戶機使用 HTTP 與 NexSRS 通信。NexSRS 使用一個外部 Web 服務器處理 HTTP 請求。外部 Web 服務器使用 LRWP 協議將客戶機請求發送給 NexSRS 進行處理。NexSRS 通過 HOSTNAME:1081 連接到 LRWP 代理,然後注冊多個上下文(如 /osp、/tep、/cgi-bin 等)並等待來自 Web 客戶機的請求。每個上下文都在單 獨的線程中進行處理。LRWP 代理注冊上下文,並且當 Web 客戶機請求類似於 http://hostname:1080/osp 這樣的 URL 時,LRWP 代理會將 /osp 與 LRWP 對等 體匹配並將請求傳遞給該對等體進行處理。
改進 LRWP 性能
優化 LRWP 代理 Java 代碼
最初的設計方案是使用多線程服務器充當 ServletContainer 中的 LRWP 代理 。每個 LRWP 對等體都注冊在服務器中,服務器啟動線程來處理連接。servlet 會將請求傳遞給代理,代理喚醒線程發送來自 Web 客戶請求並將 servlet 線程 置於休眠狀態。通過喚醒 servlet 線程並將代理對等體線程置於休眠狀態,可以 將來自對等體的應答返回給 Web 客戶機。經過修改後,采用了容器線程模型,使 用 servlet 線程本身將請求傳遞給對等體,等待應答,然後將應答返回給 Web 客戶機。此設計方案使用 LRWP 代理線程,該線程將接受來自對等體的連接並創 建一個 RequestHandler 實例注冊該連接。代理使用 Vector 對象作為一列 LRWP RequestHandlers 來維護處理程序。將請求轉發給 LRWP 對等體以及處理來自 LRWP 對等體的應答時,此設計還添加或刪除了一些處理程序。結果發現這樣的設 計成了一個瓶頸,因為 Vector 為同步結構,並且對方法關鍵部分的訪問也通過 wait/notify 機制實現了同步。初次設計時,查找RequestHandlers 的方法是迭 代列表並找到上下文匹配的 RequestHandler。經過修改,我們引入了一個 ContextAssistantManager 對象來管理 RequestHandlers 列表。這種方法不用再 添加或刪除請求處理程序,ContextAssistantManager 將跟蹤使用中的處理程序 並且對相同上下文的請求會將 servlet 線程置於休眠狀態。
ContextAssistantManager 代碼段:
class ContextAssistantManager {
public synchronized HttpProxyService getPeerService() {
ProxyServiceWrapper wrpSvc = null;
if(vectSize == 0) {
return null;
}
do {
if(lastExec < 0 || lastExec > vectSize)
lastExec = 0;
wrpSvc = (ProxyServiceWrapper)vect.get(lastExec);
lastExec++;
} while (!(wrpSvc.isFree()));
return wrpSvc;
}
}
代碼示例 1:ContextAssistantManager 代碼段
可改進性能的其他修改:
避免多個副本
編寫代碼時使用函數調用返回值作為檢查條件,比如說:
if (getValue() == null) {
error;
} else {
String value = getValue();
}
開銷較大,因為 getValue 生成兩個 String 對象或者返回對象類型。這段代 碼需要改為:
String value = getValue();
if (value == null) {
error;
}
避免分配字節數組
發送給套接字的(或從套接字接收的)網絡代碼需要使用字節的格式。因此如 果數據為 String 格式則需要將其轉換為字節格式,從而分配字節數組發送或接 收數據。除了使用 String 和字節數組存儲數據之外,還可以使用直接映向緩沖 區(如 ByteBuffer)的方式,這樣可以允許創建並銷毀這些對象。比如說,如果 要向對等體發送一個請求,可以在 StringBuffer 中創建報頭,然後將其轉換為 String 以訪問字節。還可以使用 ByteBuffer 來存儲數據,並且可以使用 CharBuffer 來創建視圖,而不是使用 StringBuffer 或 String。這同樣適用於 返回應答消息。
優化 GlassFish
優化 HTTPConnector Grizzly
GlassFish 的 HTTPConnector、Grizzly 默認將使用 NIO 處理客戶機請求的 連接。New Input/Output (NIO) 是 JDK 1.4 引入的 IO 機制,它提供了可伸縮 的網絡的文件 IOI,以及本地緩沖管理功能。NIO 引入了通道(channel)的概念 ,允許流(stream)成為通道。SocketChannel 是可選擇的通道,並且允許選擇 讀取或寫入多個流。有了它,將不再需要為每個連接使用一個單獨線程。因此服 務器現在可以只使用少許線程處理多個客戶機連接,從而提高性能並減少了線程 開銷。SocketChannel 可以是閉塞的也可以是非閉塞的。Grizzly 同時提供了閉 塞和非閉塞實現,並且默認情況為非閉塞實現,它使用 2 個線程和最多 5 個線 程處理來自客戶機的請求。這種方式是可優化的,將線程數量增加到 10 個可以 達到最佳性能。增加池容量也可以改進性能。池容量的增加如下所示:
<request-processing header-buffer-length-in-bytes="4096" initial-thread-count="2" request-timeout-in-seconds="30" thread- count="10" thread-increment="1"/>
<keep-alive max-connections="10000000" thread-count="1" timeout-in- seconds="30"/>
<connection-pool max-pending-count="14096" queue-size-in- bytes="14096" receive-buffer-size-in-bytes="14096" send-buffer-size-in -bytes="18192"/>
keepalive 也得到的增加,方法是將 max-connections 修改為 10000000。 keepalive 似乎存在一個問題,因為增加其計數實際上並不會阻止服務器建立新 連接。為解決此問題,我們將 TCP_TIME_WAIT_INTERVAL 修改為 1000,並增加了 文件描述符限制。
優化垃圾收集(Garbage Collection)
<jvm-options>-Xms3400m</jvm-options>
<jvm-options>-Xmx3400m</jvm-options>
<jvm-options>-XX:UseParallelGC</jvm-options>
<jvm-options>-Xmn256m</jvm-options>
使用並行收集程序可以將 GlassFish 性能提升為 27K,如 圖 1 所示。在 4 核系統上使用並行收集程序之後,原來默認收集程序出現的暫停情況消失了。將 堆大小從 1400m 增加到 3400m 也可以改進性能。將其進一步增加到 7m 可以實 現更大的性能提升。(GlassFish 可能與 64 位 JVM 之間存在一些問題,我們並 沒有嘗試這一組合。)
優化 Solaris
Solaris 10 可以通過優化達到開箱即用的性能。我們將 TCP_TIME_WAIT_INTERVAL 修改為1000(刪除此狀態連接的時間間隔,默認為 4 分鐘),增加文件描述符限制,將 TCP_CONN_REQ_MAX_Q [7] 修改為 10000 並將 TCP_CONN_REQ_MAX_Q0 修改為 1000。此外,我們還在 /etc/system 中添加了 IP:IPCL_CONN_HASH_SIZES 和 TCP_IP_ABORT_INTERVAL 並分別設置為 1000 和 500。
$ndd -set /dev/tcp tcp_time_wait_interval 1000
$ndd -set /dev/tcp tcp_conn_req_max_q 10000
$ndd -set /dev/tcp tcp_conn_req_max_q0 10000
將以下內容添加到 /etc/system
set ip:ipcl_conn_hash_sizes=10000
set tcp_ip_abort_interval=500
設置 ndd -set /dev/tcp tcp_time_wait_interval 1000 並增加文件描述符 限制將性能從 4500 CPM 提升到當前數值。這與上文說到的 Keepalive 問題有關 。
在基於 x86 的系統上運行
負載生成
使用 Sun Fire V280(2 個 CPU)和 ApacheBench 工具會生成負載。使用腳 本啟動三個 ApacheBench 實例,每個實例都向類似於 http://eagle:1080-/osp 的 URL 發送一個消息。
%./ab.sol8 -p auth.xml -n 1000000 -c 10 -k http://eagle:1080/osp &
%./ab.sol8 -p src.xml -n 1000000 -c 10 -k http://eagle:1080/osp &
%./ab.sol8 -p dest.xml -n 3000000 -c 30 -k http://eagle:1080/osp &
在服務器端,使用一個 GlassFish 實例在 1080 端口上監聽對 LRWP 代理 Web 應用程序的請求,從而監聽 "/*" 上下文。
測量 CPS
通過修改 nexus.log 文件測量 Calls per second (CPS) —— 日志文件將顯 示 calls per minute (CPM) 數據,我們需求將其轉換為 CPS。ApacheBench 還 可以在測試結束時輸出 CPS,並且該數據將與日志文件進行比較以確保測試運行 成功。
系統性能
測試環境為 x4100(雙核,兩個插槽,8GB,2.6Ghz)和 Solaris 10 操作系 統。使用 Solaris 的動態處理器配置工具 psradm 啟用/禁用核。
表 1. Xitami/NexSRS 的 CPU 使用率
核 呼叫/分(Calls per Minute) CPU 使用率 (%) nexus_server Xitami 1 8575 53 45 2 12880 44 34 4 15470 31 21
表 2. GlassFish(使用 Java 實現的 LRWP 代理)/NexSRS 的 CPU 使用率
核 呼叫/分(Calls per Minute) CPU 使用率 (%) nexus_server GlassFish 1 10569 68 28 2 20578 66 26 4 27246 43 21性能提升
GlassFish(使用 Java 實現的 LRWP)/NexSRS 在性能上完全優於 Xitami/NexSRS(從單核到四核)。GlassFish/NexSRS 在單核系統上有 23% 的速 度優勢,在四核系統上有 76% 的速度優勢。GlassFish/NexSRS 組合在單核系統 上的 CPU 使用率為 68%,而在四核系統上的 CPU 使用率為 43%。Xitami/NexSRS 組合在單核系統上的 CPU 使用率為 53%, 而在四核系統上的 CPU 使用率為 31% 。GlassFish 從單核到四核的平均 CPU 使用率 25%,而 Xitami 在單核系統上的 CPU 使用率為 45% 並且在四核系統上的 CPU 使用率為大約 21%。與 Xitami 相 比,支持 NIO 的 GlassFish 使用的 CPU 時間更少,從而使 NexSRS 具有更好的 可伸縮性。
結束語
從單核到四核,“使用 Java 實現的 LRWP 代理結合 GlassFish”在性能上全 面超越了“使用 C 實現的 LRWP 代理結合 Xitami”1。支持 NIO 的 GlassFish 可以很好地從單核系統擴展到四核系統,並且通過增加堆大小還可以在 64 位 JVM 上實現更大的性能提升。