實時系統和垃圾收集
實時(RT)應用程序開發與通用應用程序開發的差異在於前者對部分運行時行為強加了時間限制。此類限制通常是對應用程序的某些部分實施的,比如中斷處理程序,其響應中斷的代碼必須在給定的時間范圍內完成工作。對於硬 RT 系統,比如心髒監測器或國防系統,如果這類系統的運行超出時限,可以看作是整個系統的災難性失敗。而對於軟 RT 系統,超出時限可能會有些不利影響 —— 比如 GUI 不能顯示其監控流的所有結果 —— 但是不會導致系統失敗。
在 Java 應用程序中,Java 虛擬機(JVM)負責優化運行時行為、管理對象堆以及接合操作系統和硬件。雖然語言和平台之間的這個管理層簡化了軟件開發,但同時也給程序帶來了一定數量的開銷。GC 就是一個這樣的例子,它通常會導致應用程序中的不確定性暫停。暫停的頻率和時長都不可預測,使得 Java 語言在傳統上並不適合開發 RT 應用程序。一些基於 Java 實時規范(RTSJ)的現有解決方案使開發人員能夠避開 Java 技術的不確定性方面,但是需要對現有的編程模型做些更改。
Metronome 是一種確定性的垃圾收集器,為標准的 Java 應用程序提供有限制的低暫停時間和指定的應用程序利用率。有限制的暫停時間的減少源於收集方法的增加和細致的工程決斷,包括對 VM 的基本更改。利用率是指應用程序所能夠運行的特定時間窗中的時間百分比,剩余時間則用於 GC。Metronome 讓用戶能夠指定應用程序的利用率級別。通過與 RTSJ 結合使用,Metronome 使開發人員能夠在時間窗很小的情況下構建具有確定的低暫停時間和無暫停的軟件。本文解釋了 RT 應用程序的傳統 GC 的限制,詳述了 Metronome 的方法,並且為使用 Metronome 開發硬 RT 應用程序提供了一些工具和指導。
傳統 GC
傳統 GC 實現使用 stop-the-world (STW) 方法來恢復堆內存。應用程序一直運行,直至耗盡堆的可用內存,此時 GC 停止所有的應用程序代碼、執行垃圾收集,然後讓應用程序繼續運行。
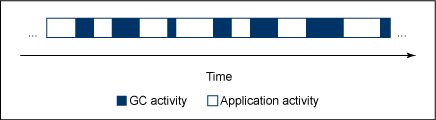
圖 1 演示了用於 GC 活動的傳統的 STW 暫停,這些暫停在頻率和持續時間方面通常都不可預測。傳統的 GC 是不確定的,因為恢復內存所需執行工作的數量取決於應用程序所使用對象的總的數量和大小、這些對象之間的相互連接,以及為釋放足夠的堆內存以滿足未來分配所需完成的工作的多少。
圖 1. 傳統 GC 暫停
傳統 GC 非確定性的原因
考察一下 GC 的基本組件,就不難理解 GC 時間沒有限制並且不可預測的原因了。GC 暫停通常包括兩個獨立階段:標記 階段和清理 階段。雖然很多實現和方法可以結合或修改這兩個階段的含義,或通過其他手段(如壓縮或減少堆中的碎片)來增強 GC,或使某些階段的操作與應用程序的運行並發執行,這兩個概念是傳統 GC 的技術基線。
標記階段負責跟蹤應用程序可見的所有對象並將它們標記 為活的,以免回收它們的存儲。這個跟蹤以根集 開始,它由一些內部結構組成,比如線程棧和對象的全局引用。跟蹤然後遍歷引用鏈直至標記完根集中所有(直接或間接)可獲得的對象。標記階段最後也沒有標記的對象是應用程序不可獲得的對象(死對象),因為不存在從根集經過任何引用序列找到這些對象的路徑。標記階段的長度不可預測,原因是應用程序中活對象的數目在任何特定時間都不可預測,並且遍歷所有引用以便找到系統中所有活對象的耗費也不可預測。一個運行穩定的系統中的 oracle 可以根據以前的計時特征來預測時間需求,但是這些預測的精確性又是不確定性的另一個來源。
清理階段負責在標記完成後考察堆並回收死對象的存儲,將其放回堆的自由存儲中,使那些存儲可用於分配。與標志階段類似,將死對象清理回自由內存池的耗費也不能完全預測。雖然系統中活對象的數目和大小可從標記階段獲得,但是對它們在堆中的位置及其對於自由內存池的適宜性進行分析所需的工作卻不可預測。
傳統 GC 對於 RT 應用程序的適宜性
RT 應用程序必須能夠響應具有確定時間間隔的實際刺激。傳統 GC 無法滿足這個需求,因為應用程序必須暫停以便 GC 可以回收所有未使用的內存。回收所花費的時間沒有限制並受波動的影響。此外,GC 中斷應用程序的時機在傳統上不可預測。應用程序暫停的持續時間被稱作暫停時間,因為這段時間暫停了應用程序進程使 GC 可以回收自由空間。RT 應用程序要求低暫停時間,因為那通常表示應用程序響應具有較高的計時限制。
Metronome GC
Metronome 的方法用於將執行 GC 循環的時間劃分為一系列的增量,稱作量子。為此,每個階段通過一系列不連續的步驟來完成其全部工作,允許收集器執行以下操作:
搶占應用程序一小段確定的時間。
執行收集操作。
讓應用程序恢復運行。
這個順序與傳統模型形成了很好的對比,在傳統模型中,應用程序在某個不可預測的時間暫停,GC 運行一段沒有限制的時間後完成,然後 GC 停止,讓應用程序恢復運行。
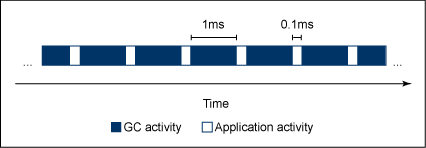
雖然將 STW GC 循環分解為短暫的有限制的暫停有助於減少 GC 的影響,但這對 RT 應用程序來說還不夠。為了使 RT 應用程序滿足其時限要求,任何特定時間段中都必須有足夠的部分可供應用程序使用;否則,就會發生需求沖突,應用程序也會失敗。例如,可假定一個 GC 暫停被限制為 1 毫秒的場景:在每 1 毫秒的 GC 暫停之間,應用程序只能運行 0.1 毫秒,則程序執行幾乎沒有進展,甚至不太復雜的 RT 系統也可能失敗,因為它們缺少時間執行處理。實際上,足夠接近的短暫停時間與完整的 STW GC 並無二致。
圖 2 演示了 GC 運行多數時間但仍然保留 1 毫秒的暫停時間:
圖 2. 暫停時間短但是應用程序時間更短
利用率
除了有限制的暫停時間外,還需要另外一種測量方法來確定分配給應用程序和 GC 的時間百分比。我們將應用程序利用率定義為:分配給特定時間窗內的應用程序的時間百分比,在這段時間內應用程序連續地執行完整個運行過程。Metronome 保證應用程序可以獲得一定百分比的處理時間。剩余時間的使用由 GC 決定:可以分配給應用程序也可以由 GC 使用。短暫停時間可以保證比傳統收集器分解得更細的利用率。因為用於測量利用率的時間間隔趨近於零,所以應用程序的預期利用率是 0% 或 100%,原因是這個時間間隔低於 GC 量的大小。對滑動窗口大小的度量必須嚴格保證利用率。Metronome 在 10 毫秒的時間窗內使用 500 微秒的時間量,默認的利用率目標為 70%。
圖 3 演示一個劃分為多個 500 微秒時間片的 GC 循環,該循環在 10 毫秒的時間窗內具有 70% 的利用率:
圖 3. 滑動窗口利用率
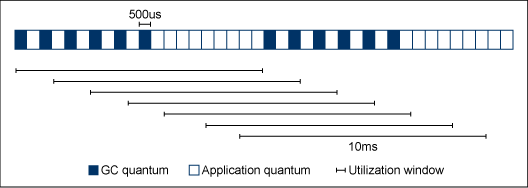
在圖 3 中,每個時間片表示運行 GC 或應用程序的一個時間量。時間片下面的各欄表示滑動窗口。每個滑動窗口具有最多 6 個 GC 時間量和至少 14 個應用程序時間量。每個 GC 時間量後接至少 1 個應用程序時間量,即使通過連續的 GC 時間量來保持目標利用率也是如此。這就保證了將應用程序暫停時間限制為 1 個時間量長度。但是,如果指定的目標利用率低於 50%,則會產生一些連續的 GC 時間量使 GC 能夠滿足分配。
圖 4 和圖 5 演示了一個典型的應用程序利用率場景。在圖 4 中,利用率降為 70% 的區域表示正在進行 GC 循環的區域。注意,如果 GC 是不活動的,則應用程序的利用率為 100%。
圖 4. 總利用率
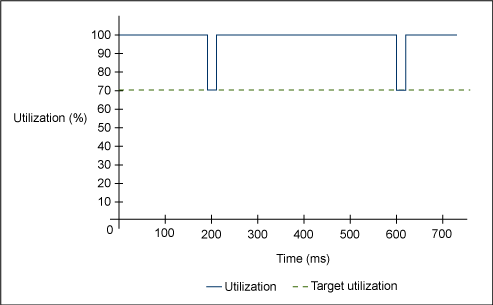
圖 5 演示了圖 4 的一個 GC 循環片段:
圖 5. GC 循環利用率
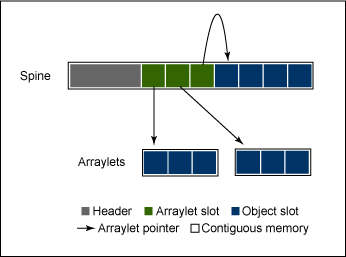
圖 5 的 A 段是一個梯型圖,其中下降的部分對應於 GC 時間量,而平緩的部分對應於應用程序時間量。梯型表示 GC 通過與應用程序交錯實現低暫停時間,從而產生目標利用率的梯狀下降。組成 B 段的應用程序活動只保持所有滑動窗口的利用率目標。利用率模式只在模式開始時顯示 GC 活動,這一點很常見。原因在於只要得到允許,GC 就會運行(保持暫停時間和利用率),而這通常意味著它會在模式開始時耗盡分得的時間並允許應用程序在時間窗的剩余部分恢復執行。C 段表示利用率接近目標利用率時的 GC 活動。上升的部分表示應用程序時間量,而下降的部分表示 GC 時間量。造成此段呈鋸齒狀的原因同樣是因為 GC 和應用程序交錯執行以便保持低暫停時間。D 段表示 GC 循環完成前的部分。此段呈上升趨勢表示 GC 不再運行而應用程序將重新獲得 100% 的利用率。
在 Metronome 中,用戶可以指定目標利用率;本文的 調整 Metronome 一節提供了與此相關的更多信息。
使用 Metronome 運行應用程序
Metronome 的設計目的是為現有的應用程序提供 RT 行為。不需要修改用戶代碼。期望的堆大小和目標利用率必須針對應用程序進行調整,使目標利用率保持期望的應用程序吞吐量,同時使 GC 能夠滿足分配。用戶應該按照希望維持的最大負載運行應用程序,以便保證 RT 特征和充足的應用程序吞吐量。本文的 調整 Metronome 一節說明了吞吐量或利用率不足時可以執行哪些操作。在某些情形下,Metronome 的短暫停時間保證不能滿足應用程序的 RT 特征。此時,您可以使用 RTSJ 來避免 GC 導致的暫停時間。
Java 實時規范
RTSJ 是 “一種使 Java 程序能夠用於實時應用程序的 Java 平台規范”。Metronome 必須意識到 RTSJ 的某些方面 —— 尤其是 RealtimeThread(RT 線程)、NoHeapRealtimeThread(NHRT)和永久內存。除了別的特征外,RT 線程是以高於普通 Java 線程的優先級運行的 Java 線程。NHRT 是不能包含堆對象引用的 RT 線程。換言之,NHRT 能夠訪問的對象不能引用服從 GC 的對象。作為對這種妥協的交換,GC 不會阻止 NHRT 的調度,即使在 GC 循環期間也是如此。這意味著 NHRT 不會導致任何暫停時間。永久內存提供了一個不服從 GC 的內存空間;即,NHRT 可以引用永久對象。這些只是 RTSJ 的一些方面,有關完整規范的鏈接,請參閱 參考資料。
確定性 GC 相關的技術問題
Metronome 使用 J9 虛擬機中的幾個關鍵方法來實現確定的暫停時間,同時保證 GC 的安全性。這些方法包括 arraylet、基於時間的垃圾收集器調度、用於跟蹤活對象的根結構處理、協調 J9 虛擬機和 GC 以保證能夠找到所有的活對象,以及用於暫停 J9 虛擬機來提供 GC 時間量的機制。
Arraylet
雖然 Metronome 通過將收集過程分解為步進的工作單元實現了確定的暫停時間,但是在某些情形下分配可能導致 GC 中出現 hiccup。大對象的分配就是一個這樣的例子。對大多數收集器實現而言,分配子系統持有一個自由堆內存池,應用程序通過分配對象使用該池,然後由收集器通過清理來補充該池。第一次收集後,自由堆內存主要是一些曾經的活對象(現在已死)的結果。因為沒有關於這些對象如何死去或何時死去的可預測模式,所以得到的堆上的自由內存是大小不一的碎片集合,即使會出現相鄰死對象合並的情況。此外,每個收集循環會返回一個不同的自由塊模式。結果,如果沒有足夠大的自由內存塊能夠滿足請求的需要,則分配一個很大的對象就會失敗。這些大對象通常是數組;標准對象一般不會多於幾十個字段,在大多數 JVM 中常常占用不到 2K 的空間。
為了緩解碎片問題,一些收集器針對其收集循環實現一個壓縮或碎片整理階段。清理完成後,如果分配請求無法滿足,則系統將嘗試移動堆中現有的活對象以便將兩個或更多的自由塊合並成一個更大的塊。這個階段有時作為一個隨需應變的特性來實現,被嵌入到收集器的結構(例如半空間收集器)中,或以一種增量的形式來實現。每個這樣的系統都有自己的平衡方法,但一般說來壓縮階段在時間和工作上都耗費頗多。
WebSphere Real Time 中當前版本的 Metronome 沒有實現壓縮系統。為使碎片不成為一個問題,Metronome 使用 arraylet 將標准的線性表示分解為若干個不連續的小塊,可以對這些小塊進行彼此獨立的分配。
圖 6 演示了數組對象作為 spine(它是可由堆上的其他對象引用的中心對象和惟一實體)和一系列的 arraylet 葉子(包含有實際的數組內容)出現:
圖 6. Arraylet
arraylet 葉子不由其他的堆對象引用,並且可能在堆中的任何位置以任意順序分布。這些葉子具有固定的大小,允許對元素的位置進行簡單的計算,這是一個附加的迂回。如圖 6 所示,spine 中由於內部碎片導致的內存使用開銷已經通過將葉子的所有 trailing 數據包含到 spine 中而得到優化。
注意,這種格式意味著數組 spine 可能成長到無限制的大小,但是在現有的系統中還沒有發現這是一個問題。
調度 GC 時間量
為了給 GC 調度確定性暫停,Metronome 使用了以下兩個不同的線程來完成一致性調度和短暫連續的暫停時間:
alarm 線程。為了確定地調度 GC 時間量,Metronome 使用 alarm 線程來用作心跳機制。alarm 線程具有很高的優先級(比系統中所有其他的 JVM 線程的優先級都要高),它的喚醒速度與 GC 量子時間段相同(Metronome 中為 500 微秒),並負責決定是否應該調度某個 GC 時間量。如果應該調度,則 alarm 線程必須暫停運行 JVM 並喚醒 GC 線程。alarm 線程只在一個很短的時間段內處於活動狀態(通常低於 10 微秒)並隨應用程序靜默的執行。
GC 線程。GC 線程在一個 GC 時間量期間執行實際工作。GC 線程必須首先完成對 alarm 線程啟動的 JVM 的暫停。然後才能在剩余的時間內執行 GC 工作,在時間量臨近結束時將自身調回休眠狀態並恢復 JVM 的運行。如果 GC 線程無法在時間量結束前完成預定的任務項目,那麼也可以搶占性地進入休眠。對於 RTSJ 而言,GC 線程的優先級比除 NHRT 之外的所有 RT 線程的優先級都要高。
協作暫停機制
雖然 Metronome 使用一系列小的、步進式的暫停來完成一個 GC 循環,但是它仍然必須以 STW 方式為每個時間量暫停 JVM。對於每個這樣的 STW 暫停,Metronome 在 J9 虛擬機中使用協作暫停機制。這個機制不依賴任何特殊的本地線程功能來暫停線程。作為替代,它使用了一個異步形式的消息傳遞系統來通知 Java 線程:必須釋放對內部 JVM 結構(包括堆)的訪問並進入休眠,直至被告知恢復處理。J9 虛擬機中的 Java 線程周期性地檢查是否發出了暫停請求,如果已經發出,則它們將執行以下步驟:
釋放所有使用的內部 JVM 結構。
將所有使用的對象引用存儲在良好描述的位置。
告知中央 JVM 暫停機制已經到達安全點。
休眠並等待相應的恢復。
一旦恢復,線程將重新讀取對象指針並重新獲取其先前占用的 JVM 相關結構。釋放 JVM 結構的操作讓 GC 線程以一種安全的形式處理這些結構;對部分更新的結構進行讀和寫操作可能導致不可預測的行為和沖突。通過存儲和重新加載對象指針,線程給 GC 在 GC 時間量期間提供了更新對象指針的機會,如果對象作為任何類似壓縮的操作的一部分移動時有此更新必要。
因為暫停機制與 Java 線程協作,所以每個線程中的周期性檢查應該用盡可能小的時間間隔分開,這一點非常重要。這一任務由 JVM 和即時(JIT)編譯器負責完成。雖然檢查暫停請求會帶來系統開銷,但是可以根據 GC 的需要很好地定義一些結構(比如棧),讓它精確地確定棧中的值是否為對象的指針。
這種暫停機制僅用於當前參與 JVM 相關活動的線程;非 Java 線程或 Java 本地接口(JNI)代碼外並且不使用 JNI API 的 Java 線程不服從暫停。如果這些線程參與了任何 JVM 活動(比如連接到 JVM 或調用 JNI API),則它們將協作性的進行暫停,直至完成 GC 時間量。這一點很重要,原因在於它使 Java 處理相關的線程繼續得到調度。雖然線程的優先級會得到考慮,但是在這些其他的線程中對系統進行任何可見形式的干擾都會影響 GC 的確定性。
寫入屏障
全面的 STW 收集器具有以下優點:可以跟蹤對象引用和 JVM 內部結構,應用程序不會干擾對象圖中的鏈接。通過將 GC 循環分解為一系列小的 STW 階段並與應用程序交錯執行,Metronome 確實帶來了跟蹤系統中活對象的潛在問題。因為應用程序在處理對象後可能修改對象的引用,使收集器無法察覺未處理對象。圖 7 演示了隱藏對象的問題:
圖 7. 隱藏對象問題
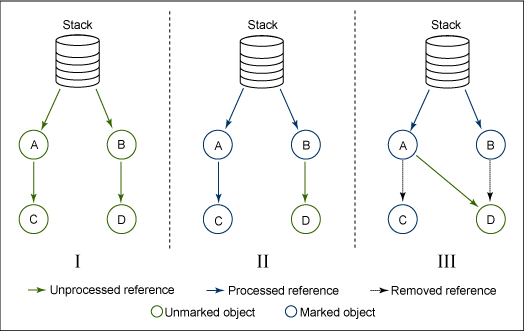
假定圖 7 第 I 段所描述的堆中存在一個對象圖。Metronome 收集器處於活動狀態並在此時間量中被分配執行跟蹤工作。在其分配的時間段中,它的作用是在時間用完之前跟蹤根對象及其引用的對象,並且需要將 JVM 調回 II 段。在應用程序的運行期間,對象之間的引用會發生變化,因此對象 A 現在指向一個未處理對象,該對象不再被 III 段中的任何其他位置引用。然後 GC 被調回並在其他的時間量中繼續處理,漏掉這個隱藏 對象指針。結果是,在把未標記對象返回到自由列表的 GC 的清理階段,將會回收一個活對象,產生一個懸空 指針,導致不正確的行為或者甚至是 JVM 或 GC 中的破壞。
為了防止出現此類錯誤,JVM 和 Metronome 必須協作跟蹤堆和 JVM 的更改,使 GC 將所有的相關對象保持為活的。這項任務通過寫入屏障 來完成,它將跟蹤所有的對象寫操作並記錄對象間引用的創建和銷毀,使收集器可以跟蹤潛在隱藏的活對象。Metronome 所使用的屏障類型稱為初始快照(snapshot at the beginning,SATB)屏障。它在收集循環開始時在概念上記錄堆的狀態並保留當時的和當前循環中分配的所有活對象。具體的解決方案涉及一個 Yuasa 類型的屏障(請參閱 參考資料),其中將會記錄任何字段存儲中的重寫值並將其視為具有相關的根引用。在重寫啟用活對象設置保護和處理之前保留槽的原始值。
內部 JVM 結構也需要此類屏障處理,包括 JNI 全局引用列表結構。因為應用程序可以向此列表中添加對象和從中刪除對象,所以可以使用屏障來跟蹤刪除的對象(避免類似於字段重寫的隱藏對象問題)和添加的對象(消除重新掃描結構的需求)。
根掃描和根處理
為了開始跟蹤活對象,垃圾收集器從一組根 中獲得的初始對象開始。根是 JVM 中的結構,表示了應用程序顯式(如 JNI 全局引用)創建或隱式(如棧)創建的對象的硬引用。根結構被作為收集器中標記階段初始功能的一部分進行掃描。
大多數根在執行期間可以根據其對象引用進行延展。出於這個原因,必須跟蹤對它們的引用設置的更改,如 寫入屏障 一節所述。但是,某些結構(如棧)不能提供對未造成嚴重性能影響的 push 和 pop 的跟蹤。因此,對掃描棧作出了某些限制和更改,使 Metronome 能夠適合 Yuasa 形式的屏障:
棧的原子掃描。單獨線程棧必須自動進行掃描,或在單個時間量內掃描。這樣做的原因在於,執行期間線程可以從其棧中彈出任意數量的引用 —— 執行過程中可能存儲在其他位置的引用。棧掃描過程中的暫停可能導致丟失對存儲的跟蹤或在兩部分掃描之間錯過,在堆中產生一個懸空指針。應用程序開發人員應該意識到棧應自動進行掃描並且應避免在 RT 應用程序中使用很深的棧。
模糊屏障。雖然棧必須自動進行掃描,但是如果在單個時間量期間所有棧都被掃描,則可能難以保持確定性。GC 和 JVM 可以在掃描 Java 棧的同時交錯執行。這可能導致通過一系列加載和存儲將對象從一個線程移動到另一個線程。為了避免丟失對象的引用,GC 期間未被掃描過的線程讓屏障跟蹤重寫值和存儲的值。跟蹤存儲的對象,應將其存儲在已經處理過的對象中並從棧中彈出,通過寫入屏障保持可獲取性。
調整 Metronome
了解堆大小和應用程序利用率方面的關系非常重要。雖然高目標的利用率對於實現最佳應用程序吞吐量很有幫助,但是 GC 必須能夠跟上應用程序的分配率。如果目標利用率和分配率都很高,則應用程序可能耗盡內存,強迫 GC 連續地運行並且在多數情況下使利用率降低到 0%。這種降低帶來了大量的暫停時間,通常對 RT 應用程序來說不可接收。如果遇到這種情形,必須作出選擇來降低目標利用率,以便提供更多的 GC 時間,增加堆大小以支持更多的應用程序,或將此二者結合使用。某些情形可能需要使用內存以維持確定的目標利用率,因此在性能開銷上降低目標利用率是惟一選擇。
圖 8 演示了一種典型的堆大小和應用程序利用率之間的平衡。更高的利用率百分比需要更大的堆,因為有些堆在低利用率的應用程序中允許運行,而在 GC 中則不允許運行。
圖 8. 堆大小和利用率的對比
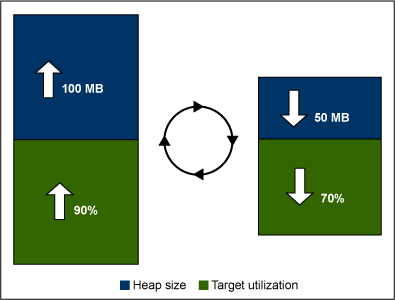
利用率和堆大小之間的關系跟應用程序有很大關系,達到一個大致平衡需要使用應用程序和 VM 參數反復實驗。
冗余 GC
冗余 GC 是一種記錄 GC 活動並將其輸出到一個文件或屏幕中的工具。您可以使用它來確定參數(堆大小、目標利用率、窗口大小和時間量)是否支持應用程序運行。清單 1 演示了一個冗余輸出的例子:
清單 1. 冗余 GC 示例
<?xml version="1.0" ?>
<verbosegc version="200702_15-Metronome">
<gc type="synchgc" id="1" timestamp="Tue Mar 13 15:17:18 2007" intervalms="0.000">
<details reason="system garbage collect" />
<duration timems="30.023" />
<heap freebytesbefore="535265280" />
<heap freebytesafter="535838720" />
<immortal freebytesbefore="15591288" />
<immortal freebytesafter="15591288" />
<synchronousgcpriority value="11" />
</gc>
<gc type="trigger start" id="1" timestamp="Tue Mar 13 15:17:45 2007" intervalms="0.000" />
<gc type="heartbeat" id="1" timestamp="Tue Mar 13 15:17:46 2007" intervalms="1003.413">
<summary quantumcount="477">
<quantum minms="0.078" meanms="0.503" maxms="1.909" />
<heap minfree="262144000" meanfree="265312260" maxfree="268386304" />
<immortal minfree="14570208" meanfree="14570208" maxfree="14570208" />
<gcthreadpriority max="11" min="11" />
</summary>
</gc>
<gc type="heartbeat" id="2" timestamp="Tue Mar 13 15:17:47 2007" intervalms="677.316">
<summary quantumcount="363">
<quantum minms="0.024" meanms="0.474" maxms="1.473" />
<heap minfree="261767168" meanfree="325154155" maxfree="433242112" />
<immortal minfree="14570208" meanfree="14530069" maxfree="14570208" />
<gcthreadpriority max="11" min="11" />
</summary>
</gc>
<gc type="trigger end" id="1" timestamp="Tue Mar 13 15:17:47 2007" intervalms="1682.816"/>
</verbosegc>
每個 Verbose GC 事件都包含在 <gc></gc> 標記中。有多種可用的事件類型,但是清單 1 中給出了最常見的幾種。synchgc 類型表示同步 GC,它是從頭到尾連續運行的 GC 循環;即,不與應用程序交錯運行。發生這種情況有以下兩個原因:
System.gc() 由應用程序調用。
堆被注滿,應用程序分配內存失敗。
同步 GC 的原因包含在 <details> 標記中,其中 system garbage collect 用於第一種情形而 out of memory 用於第二種情形。第一種情形在應用程序的可維持性方面沒有使用特定的參數。但是,在很多情況下從用戶應用程序調用 System.gc() 會導致應用程序利用率降至 0% 並導致較長的暫停時間;因此應該避免這種情況。但是如果因為第二種情況發生同步 GC —— 內存不足錯誤 —— 則意味著 GC 不能跟上應用程序分配。因此您應該考慮增加堆或降低應用程序利用率目標以避免出現同步 GC。
trigger GC 事件類型對應 GC 循環的開始點和結束點。它們可用於對 heartbeat GC 事件進行分批。heartbeat GC 事件類型將多個 GC 時間量的信息整合到一個總括的冗余事件中。注意,這與 alarm 線程心跳無關。quantumcount 屬性對應 heartbeat GC 中整合的 GC 時間量。<quantum> 標記表示關於 heartbeat GC 中整合的 GC 時間量的計時信息。<heap> 和 <immortal> 標記包含關於 heartbeat GC 中整合的時間量結尾的自由內存的信息。<gcthreadpriority> 標記包含關於時間量開始時 GC 線程優先級的信息。
時間量值指的是應用程序所見的暫停時間。普通的時間量接近 500 微秒,而且必須對最大的時間量進行監控以保證它們能夠為 RT 應用程序提供可接受的暫停時間。長暫停時間可能源於 GC 被系統中的其他進程搶占,使其不能完成其時間量而且不能讓應用程序恢復運行,或者是因為濫用了系統中的某些根結構並成長到了不可管理的大小(見 使用 Metronome 時的注意事項 一節)。
永久內存是 RTSJ 所需要的並且不服從 GC 的資源。出於這個原因,常常會發現冗余 GC 記錄中的永久自由內存下降並且不會恢復。它用於諸如字符串常量和類之類的對象。需要注意程序的行為並適當地調整永久內存的大小。
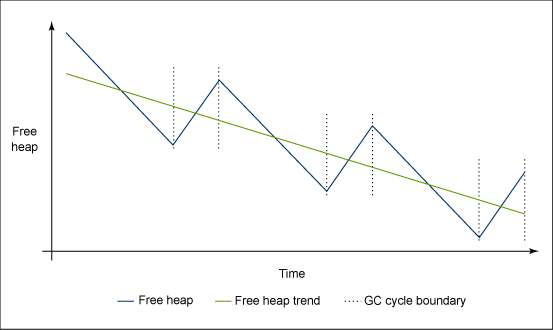
應該監控堆的使用以保證總趨勢保持穩定。堆自由空間呈下降趨勢表明可能存在應用程序導致的洩漏。導致洩漏的原因很多,包括越來越多的散列表、不確定保存的大型資源對象和未清理的全局 JNI 引用。
圖 9 和圖 10 演示了自由堆空間中的穩定和遞減的趨勢。注意,容易實現本地的最小和最大空間,因為自由空間僅在 GC 循環期間增加並且在應用程序處於活動時和進行分配時相應減少。
圖 9. 穩定自由堆
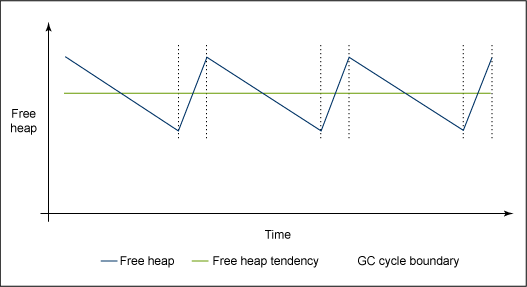
圖 10. 遞減自由堆
<gc> 標記的 interval 屬性指的是從上次輸出相同類型的冗余 GC 事件起所經過的時間。對於 heartbeat 事件類型,它用來表示從 trigger start 事件起所經過的時間(如果它是當前 GC 循環的第一次心跳)。
Tuning Fork
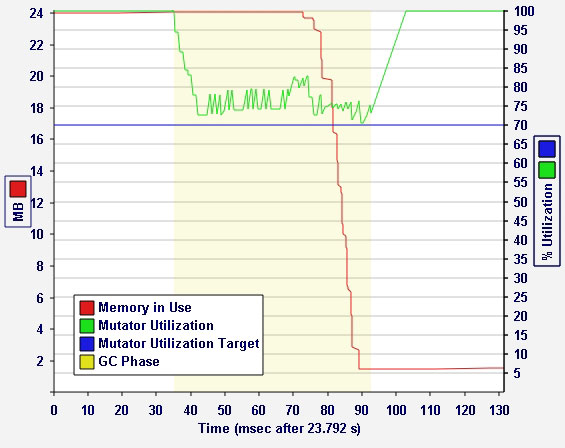
Tuning Fork 是一種獨立的工具,用於調優 Metronome 以便更好地適合用戶應用程序。Tuning Fork 讓用戶檢查 GC 活動的很多細節,方法是在執行活動後通過跟蹤日志檢查或在運行時通過套接字檢查。Metronome 構建時考慮了 Tuning Fork 並記錄了很多可在 Tuning Fork 應用程序中檢查的事件。例如,它顯示了時間上的應用程序利用率並檢查了用於各個 GC 階段的時間。
圖 11 演示了 Tuning Fork 所生成的 GC 性能概要圖,包括目標利用率、堆內存使用和應用程序利用率:
圖 11. Tuning Fork 性能概要
使用 Metronome 時的注意事項
Metronome 竭力為 GC 提供短暫確定的暫停,在應用程序代碼中和底層平台中出現了一些可能影響這些結果的情形,有時會導致暫停時間異常。使用標准 JDK 收集器帶來的 GC 行為更改在此也會出現。
RTSJ 規定 GC 不能處理永久內存。因為類位於永久內存中,所以它們不服從 GC 並且因此不能被卸載。希望使用大量類的應用程序需要適當地調整永久空間,要卸載類的應用程序需要在 WebSphere Real Time 中調整其編程模型。
Metronome 中的 GC 工作是基於時間的,而對硬件時鐘的任何更改都可能導致難於診斷的問題。使系統時間與 Network Time Protocol (NTP) 服務器同步然後讓硬件時鐘和系統時間同步就是一個這樣的例子。這將表現為時間上突然跳躍到 GC 並可能導致維持利用率目標的失敗或者可能導致內存不足的錯誤。
在單個機器上運行多個 JVM 可能造成 JVM 之間相互干擾,使利用率圖發生傾斜。alarm 線程是一個高優先級 RT 線程,它會搶占任何其他具有較低優先級的線程,而 GC 線程仍然以 RT 優先級運行。如果在任何時間都有足夠的 GC 和 alarm 線程是活動的,則沒有活動的 GC 循環的 JVM 可能使其應用程序線程被其他 JVM 的 GC 和 alarm 線程搶占,而時間實際上分配給了應用程序,原因是該 VM 的 GC 是不活動的。