雖然新的 Java I/O 框架( java.nio )能解決 I/O 支持所具有的多數性能 問題,但是它並沒有滿足使用字節數組和管道的應用程序內部通信的所有性能需 求。本文是分兩部分的系列文章的最後一篇,Java 密碼專家和作家 Merlin Hughes 開發了一組新的流,以補充標准的 Java I/O 字節數組流類和管道流類 ,在設計中強調以高性能為目標。請到關於本文的 討論論壇,與作者和其他讀 者分享您對本文的看法。(您也可以單擊文章頂部或底部的 討論。)
在 本系列的第一篇文章中,您學習了解決從只能寫出數據的源讀取數據的問 題的一些不同方法。在可能的解決方案中,我們研究了怎樣使用字節數組流、管 道流以及直接處理該問題的定制框架。定制方法顯然是最有效率的解決方案;但 是,分析其它幾種方法有助於看清標准 Java 流的一些問題。具體地說,字節數 組輸出流並不提供可提供對它的內容進行只讀訪問的高效機制,管道流的性能通 常很差。
為了處理這些問題,我們將在本文中實現功能同樣齊全的替換類,但在實現 時更強調性能。讓我們先來簡要地討論一下同步問題,因為它與 I/O 流有關。
同步問題
一般來說,我推薦在不是特別需要同步的情況下避免不必要地使用同步。顯 然,如果多個線程需並發地訪問一個類,那麼這個類需確保線程安全。但是,在 許多情況下並不需要並發的訪問,同步成了不必要的開銷。例如,對流的並發訪 問自然是不確定的 ― 您無法預測哪些數據被先寫入,也無法預測哪個線程讀了 哪些數據 ― 也就是說,在多數情況下,對流的並發訪問是沒用的。所以,對所 有的流強制同步是不提供實際好處的花費。如果某個應用程序要求線程安全,那 麼通過應用程序自己的同步原語可以強制線程安全。
事實上,Collection 類的 API 作出了同樣的選擇:在缺省的情況下,set、 list 等等都不是線程安全的。如果應用程序想使用線程安全的 Collection,那 麼它可以使用 Collections 類來創建一個線程安全的包裝器來包裝非線程安全 的 Collection。如果這種作法是有用的,那麼應用程序可以使用完全相同的機 制來包裝流,以使它線程安全;例如, OutputStream out = Streams.synchronizedOutputStream (byteStream) 。請參閱附帶的 源代碼中 的 Streams 類,這是一個實現的示例。
所以,對於我所認為的多個並發線程無法使用的類,我沒用同步來為這些類 提供線程安全。在您廣泛采用這種方式前,我推薦您研究一下 Java 語言規范( Java Language Specification)的 Threads and Locks那一章(請參閱 參考資 料),以理解潛在的缺陷;具體地說,在未使用同步的情況下無法確保讀寫的順 序,所以,對不同步的只讀方法的並發訪問可能導致意外的行為,盡管這種訪問 看起來是無害的。
更好的字節數組輸出流
當您需要把未知容量的數據轉儲到內存緩沖區時, ByteArrayOutputStream 類是使用效果很好的流。當我為以後再次讀取而存儲一些數據時,我經常使用這 個類。但是,使用 toByteArray() 方法來取得對結果數據的讀訪問是很低效的 ,因為它實際返回的是內部字節數組的副本。對於小容量的數據,使用這種方式 不會有太大問題;然而,隨著容量增大,這種方式的效率被不必要地降低了。這 個類必須復制數據,因為它不能強制對結果字節數組進行只讀訪問。如果它返回 它的內部緩沖區,那麼在一般的情況下,接收方無法保證該緩沖區未被同一數組 的另一個接收方並發地修改。
StringBuffer 類已解決了類似的問題;它提供可寫的字符緩沖區,它還支持 高效地返回能從內部字符數組直接讀取的只讀 String 。因為 StringBuffer 類 控制著對它的內部數組的寫訪問,所以它僅在必要時才復制它的數組;也就是說 ,當它導出了 String 且後來調用程序修改了 StringBuffer 的時候。如果沒有 發生這樣的修改,那麼任何不必要的復制都不會被執行。通過支持能夠強制適當 的訪問控制的字節數組的包裝器,新的 I/O 框架以類似的方式解決了這個問題 。
我們可以使用相同的通用機制為需要使用標准流 API 的應用程序提供高效的 數據緩沖和再次讀取。我們的示例給出了可替代 ByteArrayOutputStream 類的 類,它能高效地導出對內部緩沖區的只讀訪問,方法是返回直接讀取內部字節數 組的只讀 InputStream 。
我們來看一下代碼。清單 1 中的構造函數分配了初始緩沖區,以存儲寫到這 個流的數據。為了存儲更多的數據,該緩沖區將按需自動地擴展。
清單 1. 不同步的字節數組輸出流
package org.merlin.io;
import java.io.*;
/**
* An unsynchronized ByteArrayOutputStream alternative that efficiently
* provides read-only access to the internal byte array with no
* unnecessary copying.
*
* @author Copyright (c) 2002 Merlin Hughes <merlin@merlin.org>
*/
public class BytesOutputStream extends OutputStream {
private static final int DEFAULT_INITIAL_BUFFER_SIZE = 8192;
// internal buffer
private byte[] buffer;
private int index, capacity;
// is the stream closed?
private boolean closed;
// is the buffer shared?
private boolean shared;
public BytesOutputStream () {
this (DEFAULT_INITIAL_BUFFER_SIZE);
}
public BytesOutputStream (int initialBufferSize) {
capacity = initialBufferSize;
buffer = new byte[capacity];
}
清單 2 顯示的是寫方法。這些方法按需擴展內部緩沖區,然後把新數據復制 進來。在擴展內部緩沖區時,我們使緩沖區的大小增加了一倍再加上存儲新數據 所需的容量;這樣,為了存儲任何所需的數據,緩沖區的容量成指數地增長。為 了提高效率,如果您知道您將寫入的數據的預期容量,那麼您應該指定相應的初 始緩沖區的大小。 close() 方法只是設置了一個合適的標志。
清單 2. 寫方法
public void write (int datum) throws IOException {
if (closed) {
throw new IOException ("Stream closed");
} else {
if (index >= capacity) {
// expand the internal buffer
capacity = capacity * 2 + 1;
byte[] tmp = new byte[capacity];
System.arraycopy (buffer, 0, tmp, 0, index);
buffer = tmp;
// the new buffer is not shared
shared = false;
}
// store the byte
buffer[index ++] = (byte) datum;
}
}
public void write (byte[] data, int offset, int length)
throws IOException {
if (data == null) {
throw new NullPointerException ();
} else if ((offset < 0) || (offset + length > data.length)
|| (length < 0)) {
throw new IndexOutOfBoundsException ();
} else if (closed) {
throw new IOException ("Stream closed");
} else {
if (index + length > capacity) {
// expand the internal buffer
capacity = capacity * 2 + length;
byte[] tmp = new byte[capacity];
System.arraycopy (buffer, 0, tmp, 0, index);
buffer = tmp;
// the new buffer is not shared
shared = false;
}
// copy in the subarray
System.arraycopy (data, offset, buffer, index, length);
index += length;
}
}
public void close () {
closed = true;
}
清單 3 中的字節數組抽取方法返回內部字節數組的副本。因為我們無法防止 調用程序把數據寫到結果數組,所以我們無法安全地返回對內部緩沖區的直接引 用。
清單 3. 轉換成字節數組
public byte[] toByteArray () {
// return a copy of the internal buffer
byte[] result = new byte[index];
System.arraycopy (buffer, 0, result, 0, index);
return result;
}
當方法提供對存儲的數據的只讀訪問的時候,它們可以安全地高效地直接使 用內部字節數組。清單 4 顯示了兩個這樣的方法。 writeTo() 方法把這個流的 內容寫到輸出流;它直接從內部緩沖區進行寫操作。 toInputStream() 方法返 回了可被高效地讀取數據的輸入流。它所返回的 BytesInputStream (這是 ByteArrayInputStream 的非同步替代品。)能直接從我們的內部字節數組讀取 數據。在這個方法中,我們還設置了標志,以表示內部緩沖區正被輸入流共享。 這一點很重要,因為這樣做可以防止在內部緩沖區正被共享時這個流被修改。
清單 4. 只讀訪問方法
public void writeTo (OutputStream out) throws IOException {
// write the internal buffer directly
out.write (buffer, 0, index);
}
public InputStream toInputStream () {
// return a stream reading from the shared internal buffer
shared = true;
return new BytesInputStream (buffer, 0, index);
}
可能會覆蓋共享數據的唯一的一個方法是顯示在清單 5 中的 reset() 方法 ,該方法清空了這個流。所以,如果 shared 等於 true 且 reset() 被調用, 那麼我們創建新的內部緩沖區,而不是重新設置寫索引。
清單 5. 重新設置流
public void reset () throws IOException {
if (closed) {
throw new IOException ("Stream closed");
} else {
if (shared) {
// create a new buffer if it is shared
buffer = new byte[capacity];
shared = false;
}
// reset index
index = 0;
}
}
}
更好的字節數組輸入流
用 ByteArrayInputStream 類來提供對內存中的二進制數據基於流的讀訪問 是很理想的。但是,有時候,它的兩個設計特點使我覺得需要一個替代它的類。 第一,這個類是同步的;我已講過,對於多數應用程序來說沒有這個必要。第二 ,如果在執行 mark() 前調用它所實現的 reset() 方法,那麼 reset() 將忽略 初始讀偏移。這兩點都不是缺陷;但是,它們不一定總是人們所期望的。
清單 6 中的 BytesInputStream 類是不同步的較為普通的字節數組輸入流類 。
清單 6. 不同步的字節數組輸入流
package org.merlin.io;
import java.io.*;
/**
* An unsynchronized ByteArrayInputStream alternative.
*
* @author Copyright (c) 2002 Merlin Hughes <merlin@merlin.org>
*/
public class BytesInputStream extends InputStream {
// buffer from which to read
private byte[] buffer;
private int index, limit, mark;
// is the stream closed?
private boolean closed;
public BytesInputStream (byte[] data) {
this (data, 0, data.length);
}
public BytesInputStream (byte[] data, int offset, int length) {
if (data == null) {
throw new NullPointerException ();
} else if ((offset < 0) || (offset + length > data.length)
|| (length < 0)) {
throw new IndexOutOfBoundsException ();
} else {
buffer = data;
index = offset;
limit = offset + length;
mark = offset;
}
}
public int read () throws IOException {
if (closed) {
throw new IOException ("Stream closed");
} else if (index >= limit) {
return -1; // EOF
} else {
return buffer[index ++] & 0xff;
}
}
public int read (byte data[], int offset, int length)
throws IOException {
if (data == null) {
throw new NullPointerException ();
} else if ((offset < 0) || (offset + length > data.length)
|| (length < 0)) {
throw new IndexOutOfBoundsException ();
} else if (closed) {
throw new IOException ("Stream closed");
} else if (index >= limit) {
return -1; // EOF
} else {
// restrict length to available data
if (length > limit - index)
length = limit - index;
// copy out the subarray
System.arraycopy (buffer, index, data, offset, length);
index += length;
return length;
}
}
public long skip (long amount) throws IOException {
if (closed) {
throw new IOException ("Stream closed");
} else if (amount <= 0) {
return 0;
} else {
// restrict amount to available data
if (amount > limit - index)
amount = limit - index;
index += (int) amount;
return amount;
}
}
public int available () throws IOException {
if (closed) {
throw new IOException ("Stream closed");
} else {
return limit - index;
}
}
public void close () {
closed = true;
}
public void mark (int readLimit) {
mark = index;
}
public void reset () throws IOException {
if (closed) {
throw new IOException ("Stream closed");
} else {
// reset index
index = mark;
}
}
public boolean markSupported () {
return true;
}
}
使用新的字節數組流
清單 7 中的代碼演示了怎樣使用新的字節數組流來解決第一篇文章中處理的 問題(讀一些壓縮形式的數據):
清單 7. 使用新的字節數組流
public static InputStream newBruteForceCompress (InputStream in)
throws IOException {
BytesOutputStream sink = new BytesOutputStream ();
OutputStream out = new GZIPOutputStream (sink);
Streams.io (in, out);
out.close ();
return sink.toInputStream ();
}
更好的管道流
雖然標准的管道流既安全又可靠,但在性能方面不能令人滿意。幾個因素導 致了它的性能問題:
對於不同的使用情況,大小為 1024 字節的內部緩沖區並不都適用;對於大 容量的數據,該緩沖區太小了。
基於數組的操作只是反復調用低效的一個字節一個字節地復制操作。該操作 本身是同步的,從而導致非常嚴重的鎖爭用。
如果管道變空或變滿而在這種狀態改變時一個線程阻塞了,那麼,即使僅有 一個字節被讀或寫,該線程也被喚醒。在許多情況下,線程將使用這一個字節並 立即再次阻塞,這將導致只做了很少有用的工作。
最後一個因素是 API 提供的嚴格的約定的後果。對於最通用的可能的應用程 序中使用的流來說,這種嚴格的約定是必要的。但是,對於管道流實現,提供一 種更寬松的約定是可能的,這個約定犧牲嚴格性以換取性能的提高:
僅當緩沖區的可用數據(對阻塞的讀程序而言)或可用空間(對寫程序而言 )達到指定的某個 滯後阈值或發生異常事件(例如管道關閉)時,阻塞的讀程 序和寫程序才被喚醒。這將提高性能,因為僅當線程能完成適度的工作量時它們 才被喚醒。
只有一個線程可以從管道讀取數據,只有一個線程可以把數據寫到管道。否 則,管道無法可靠地確定讀程序線程或寫程序線程何時意外死亡。
這個約定可完全適合典型應用程序情形中獨立的讀程序線程和寫程序線程; 需要立即喚醒的應用程序可以使用零滯後級別。我們將在後面看到,這個約定的 實現的操作速度比標准 API 流的速度快兩個數量級(100 倍)。
我們可以使用幾個可能的 API 中的一個來開發這些管道流:我們可以模仿標 准類,顯式地連接兩個流;我們也可以開發一個 Pipe 類並從這個類抽取輸出流 和輸入流。我們不使用這兩種方式而是使用更簡單的方式:創建一個 PipeInputStream ,然後抽取關聯的輸出流。
這些流的一般操作如下:
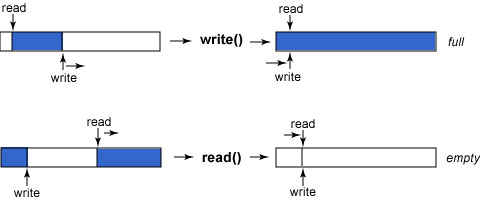
我們把內部數組用作環緩沖區(請看圖 1):這個數組中維護著一個讀索引 和一個寫索引;數據被寫到寫索引所指的位置,數據從讀索引所指的位置被讀取 ;當兩個索引到達緩沖區末尾時,它們回繞到緩沖區起始點。任一個索引不能超 越另一個索引。當寫索引到達讀索引時,管道是滿的,不能再寫任何數據。當讀 索引到達寫索引時,管道是空的,不能再讀任何數據。
同步被用來確保兩個協作線程看到管道狀態的最新值。Java 語言規范對內存 訪問的順序的規定是很寬容的,因此,無法使用無鎖緩沖技術。
圖 1. 環緩沖區
在下面的代碼清單中給出的是實現這些管道流的代碼。清單 8 顯示了這個類 所用的構造函數和變量。您可以從這個 InputStream 中抽取相應的 OutputStream (請看清單 17 中的代碼)。在構造函數中您可以指定內部緩沖 區的大小和滯後級別;這是緩沖區容量的一部分,在相應的讀程序線程或寫程序 線程被立即喚醒前必須被使用或可用。我們維護兩個變量, reader 和 writer ,它們與讀程序線程和寫程序線程相對應。我們用它們來發現什麼時候一個線程 已死亡而另一個線程仍在訪問流。
清單 8. 一個替代的管道流實現
package org.merlin.io;
import java.io.*;
/**
* An efficient connected stream pair for communicating between
* the threads of an application. This provides a less-strict contract
* than the standard piped streams, resulting in much-improved
* performance. Also supports non-blocking operation.
*
* @author Copyright (c) 2002 Merlin Hughes <merlin@merlin.org>
*/
public class PipeInputStream extends InputStream {
// default values
private static final int DEFAULT_BUFFER_SIZE = 8192;
private static final float DEFAULT_HYSTERESIS = 0.75f;
private static final int DEFAULT_TIMEOUT_MS = 1000;
// flag indicates whether method applies to reader or writer
private static final boolean READER = false, WRITER = true;
// internal pipe buffer
private byte[] buffer;
// read/write index
private int readx, writex;
// pipe capacity, hysteresis level
private int capacity, level;
// flags
private boolean eof, closed, sleeping, nonBlocking;
// reader/writer thread
private Thread reader, writer;
// pending exception
private IOException exception;
// deadlock-breaking timeout
private int timeout = DEFAULT_TIMEOUT_MS;
public PipeInputStream () {
this (DEFAULT_BUFFER_SIZE, DEFAULT_HYSTERESIS);
}
public PipeInputStream (int bufferSize) {
this (bufferSize, DEFAULT_HYSTERESIS);
}
// e.g., hysteresis .75 means sleeping reader/writer is not
// immediately woken until the buffer is 75% full/empty
public PipeInputStream (int bufferSize, float hysteresis) {
if ((hysteresis < 0.0) || (hysteresis > 1.0))
throw new IllegalArgumentException ("Hysteresis: " + hysteresis);
capacity = bufferSize;
buffer = new byte[capacity];
level = (int) (bufferSize * hysteresis);
}
清單 9 中的配置方法允許您配置流的超時值和非阻塞模式。超時值的單位是 毫秒,它表示阻塞的線程在過了這段時間後將被自動喚醒;這對於打破在一個線 程死亡的情況下可能發生的死鎖是必要的。在非阻塞模式中,如果線程阻塞,那 麼 InterruptedIOException 將被拋出。
清單 9. 管道配置
public void setTimeout (int ms) {
this.timeout = ms;
}
public void setNonBlocking (boolean nonBlocking) {
this.nonBlocking = nonBlocking;
}
清單 10 中的讀方法都遵循相當標准的模式:如果我們還沒有讀線程的引用 ,那麼我們先取得它,然後我們驗證輸入參數,核對流未被關閉或沒有異常待處 理,確定可以讀取多少數據,最後把數據從內部的環緩沖區復制到讀程序的緩沖 區。清單 12 中的 checkedAvailable() 方法在返回前自動地等待,直到出現一 些可用的數據或流被關閉。
清單 10. 讀數據
private byte[] one = new byte[1];
public int read () throws IOException {
// read 1 byte
int amount = read (one, 0, 1);
// return EOF / the byte
return (amount < 0) ? -1 : one[0] & 0xff;
}
public synchronized int read (byte data[], int offset, int length)
throws IOException {
// take a reference to the reader thread
if (reader == null)
reader = Thread.currentThread ();
// check parameters
if (data == null) {
throw new NullPointerException ();
} else if ((offset < 0) || (offset + length > data.length)
|| (length < 0)) { // check indices
throw new IndexOutOfBoundsException ();
} else {
// throw an exception if the stream is closed
closedCheck ();
// throw any pending exception
exceptionCheck ();
if (length <= 0) {
return 0;
} else {
// wait for some data to become available for reading
int available = checkedAvailable (READER);
// return -1 on EOF
if (available < 0)
return -1;
// calculate amount of contiguous data in pipe buffer
int contiguous = capacity - (readx % capacity);
// calculate how much we will read this time
int amount = (length > available) ? available : length;
if (amount > contiguous) {
// two array copies needed if data wrap around the buffer end
System.arraycopy (buffer, readx % capacity, data, offset,
contiguous);
System.arraycopy (buffer, 0, data, offset + contiguous,
amount - contiguous);
} else {
// otherwise, one array copy needed
System.arraycopy (buffer, readx % capacity, data, offset,
amount);
}
// update indices with amount of data read
processed (READER, amount);
// return amount read
return amount;
}
}
}
public synchronized long skip (long amount) throws IOException {
// take a reference to the reader thread
if (reader == null)
reader = Thread.currentThread ();
// throw an exception if the stream is closed
closedCheck ();
// throw any pending exception
exceptionCheck ();
if (amount <= 0) {
return 0;
} else {
// wait for some data to become available for skipping
int available = checkedAvailable (READER);
// return 0 on EOF
if (available < 0)
return 0;
// calculate how much we will skip this time
if (amount > available)
amount = available;
// update indices with amount of data skipped
processed (READER, (int) amount);
// return amount skipped
return amount;
}
}
當數據從這個管道被讀取或數據被寫到這個管道時,清單 11 中的方法被調 用。該方法更新有關的索引,如果管道達到它的滯後級別,該方法自動地喚醒阻 塞的線程。
清單 11. 更新索引
private void processed (boolean rw, int amount) {
if (rw == READER) {
// update read index with amount read
readx = (readx + amount) % (capacity * 2);
} else {
// update write index with amount written
writex = (writex + amount) % (capacity * 2);
}
// check whether a thread is sleeping and we have reached the
// hysteresis threshold
if (sleeping && (available (!rw) >= level)) {
// wake sleeping thread
notify ();
sleeping = false;
}
}
在管道有可用空間或可用數據(取決於 rw 參數)前,清單 12 中的 checkedAvailable() 方法一直等待,然後把空間的大小或數據的多少返回給調 用程序。在這個方法內還核對流未被關閉、管道未被破壞等。
清單 12. 檢查可用性
public synchronized int available () throws IOException {
// throw an exception if the stream is closed
closedCheck ();
// throw any pending exception
exceptionCheck ();
// determine how much can be read
int amount = available (READER);
// return 0 on EOF, otherwise the amount readable
return (amount < 0) ? 0 : amount;
}
private int checkedAvailable (boolean rw) throws IOException {
// always called from synchronized(this) method
try {
int available;
// loop while no data can be read/written
while ((available = available (rw)) == 0) {
if (rw == READER) { // reader
// throw any pending exception
exceptionCheck ();
} else { // writer
// throw an exception if the stream is closed
closedCheck ();
}
// throw an exception if the pipe is broken
brokenCheck (rw);
if (!nonBlocking) { // blocking mode
// wake any sleeping thread
if (sleeping)
notify ();
// sleep for timeout ms (in case of peer thread death)
sleeping = true;
wait (timeout);
// timeout means that hysteresis may not be obeyed
} else { // non-blocking mode
// throw an InterruptedIOException
throw new InterruptedIOException
("Pipe " + (rw ? "full" : "empty"));
}
}
return available;
} catch (InterruptedException ex) {
// rethrow InterruptedException as InterruptedIOException
throw new InterruptedIOException (ex.getMessage ());
}
}
private int available (boolean rw) {
// calculate amount of space used in pipe
int used = (writex + capacity * 2 - readx) % (capacity * 2);
if (rw == WRITER) { // writer
// return amount of space available for writing
return capacity - used;
} else { // reader
// return amount of data in pipe or -1 at EOF
return (eof && (used == 0)) ? -1 : used;
}
}
清單 13 中的方法關閉這個流;該方法還提供對讀程序或寫程序關閉流的支 持。阻塞的線程被自動喚醒,該方法還檢查各種其它情況是否正常。
清單 13. 關閉流
public void close () throws IOException {
// close the read end of this pipe
close (READER);
}
private synchronized void close (boolean rw) throws IOException {
if (rw == READER) { // reader
// set closed flag
closed = true;
} else if (!eof) { // writer
// set eof flag
eof = true;
// check if data remain unread
if (available (READER) > 0) {
// throw an exception if the reader has already closed the pipe
closedCheck ();
// throw an exception if the reader thread has died
brokenCheck (WRITER);
}
}
// wake any sleeping thread
if (sleeping) {
notify ();
sleeping = false;
}
}
清單 14 中的方法檢查這個流的狀態。如果有異常待處理,那麼流被關閉或 管道被破壞(也就是說,讀程序線程或寫程序線程已死亡),異常被拋出。
清單 14. 檢查流狀態
private void exceptionCheck () throws IOException {
// throw any pending exception
if (exception != null) {
IOException ex = exception;
exception = null;
throw ex; // could wrap ex in a local exception
}
}
private void closedCheck () throws IOException {
// throw an exception if the pipe is closed
if (closed)
throw new IOException ("Stream closed");
}
private void brokenCheck (boolean rw) throws IOException {
// get a reference to the peer thread
Thread thread = (rw == WRITER) ? reader : writer;
// throw an exception if the peer thread has died
if ((thread != null) && !thread.isAlive ())
throw new IOException ("Broken pipe");
}
當數據被寫入這個管道時,清單 15 中的方法被調用。總的來說,它類似於 讀方法:我們先取得寫程序線程的副本,然後檢查流是否被關閉,接著進入把數 據復制到管道的循環。和前面一樣,該方法使用 checkedAvailable() 方法, checkedAvailable() 自動阻塞,直到管道中有可用的容量。
清單 15. 寫數據
private synchronized void writeImpl (byte[] data, int offset, int length)
throws IOException {
// take a reference to the writer thread
if (writer == null)
writer = Thread.currentThread ();
// throw an exception if the stream is closed
if (eof || closed) {
throw new IOException ("Stream closed");
} else {
int written = 0;
try {
// loop to write all the data
do {
// wait for space to become available for writing
int available = checkedAvailable (WRITER);
// calculate amount of contiguous space in pipe buffer
int contiguous = capacity - (writex % capacity);
// calculate how much we will write this time
int amount = (length > available) ? available : length;
if (amount > contiguous) {
// two array copies needed if space wraps around the buffer end
System.arraycopy (data, offset, buffer, writex % capacity,
contiguous);
System.arraycopy (data, offset + contiguous, buffer, 0,
amount - contiguous);
} else {
// otherwise, one array copy needed
System.arraycopy (data, offset, buffer, writex % capacity,
amount);
}
// update indices with amount of data written
processed (WRITER, amount);
// update amount written by this method
written += amount;
} while (written < length);
// data successfully written
} catch (InterruptedIOException ex) {
// write operation was interrupted; set the bytesTransferred
// exception field to reflect the amount of data written
ex.bytesTransferred = written;
// rethrow exception
throw ex;
}
}
}
如清單 16 所示,這個管道流實現的特點之一是寫程序可設置一個被傳遞給 讀程序的異常。
清單 16. 設置異常
private synchronized void setException (IOException ex)
throws IOException {
// fail if an exception is already pending
if (exception != null)
throw new IOException ("Exception already set: " + exception);
// throw an exception if the pipe is broken
brokenCheck (WRITER);
// take a reference to the pending exception
this.exception = ex;
// wake any sleeping thread
if (sleeping) {
notify ();
sleeping = false;
}
}
清單 17 給出這個管道的有關輸出流的代碼。 getOutputStream() 方法返回 OutputStreamImpl ,OutputStreamImpl 是使用前面給出的方法來把數據寫到內 部管道的輸出流。OutputStreamImpl 類繼承了 OutputStreamEx , OutputStreamEx 是允許為讀線程設置異常的輸出流類的擴展。
清單 17. 輸出流
public OutputStreamEx getOutputStream () {
// return an OutputStreamImpl associated with this pipe
return new OutputStreamImpl ();
}
private class OutputStreamImpl extends OutputStreamEx {
private byte[] one = new byte[1];
public void write (int datum) throws IOException {
// write one byte using internal array
one[0] = (byte) datum;
write (one, 0, 1);
}
public void write (byte[] data, int offset, int length)
throws IOException {
// check parameters
if (data == null) {
throw new NullPointerException ();
} else if ((offset < 0) || (offset + length > data.length)
|| (length < 0)) {
throw new IndexOutOfBoundsException ();
} else if (length > 0) {
// call through to writeImpl()
PipeInputStream.this.writeImpl (data, offset, length);
}
}
public void close () throws IOException {
// close the write end of this pipe
PipeInputStream.this.close (WRITER);
}
public void setException (IOException ex) throws IOException {
// set a pending exception
PipeInputStream.this.setException (ex);
}
}
// static OutputStream extension with setException() method
public static abstract class OutputStreamEx extends OutputStream {
public abstract void setException (IOException ex) throws IOException;
}
}
使用新的管道流
清單 18 演示了怎樣使用新的管道流來解決上一篇文章中的問題。請注意, 寫程序線程中出現的任何異常均可在流中被傳遞。
清單 18. 使用新的管道流
public static InputStream newPipedCompress (final InputStream in)
throws IOException {
PipeInputStream source = new PipeInputStream ();
final PipeInputStream.OutputStreamEx sink = source.getOutputStream ();
new Thread () {
public void run () {
try {
GZIPOutputStream gzip = new GZIPOutputStream (sink);
Streams.io (in, gzip);
gzip.close ();
} catch (IOException ex) {
try {
sink.setException (ex);
} catch (IOException ignored) {
}
}
}
}.start ();
return source;
}
性能結果
在下面的表中顯示的是這些新的流和標准流的性能,測試環境是運行 Java 2 SDK,v1.4.0 的 800MHz Linux 機器。性能測試程序與我在上一篇文章中用的相 同:
管道流
15KB:21ms;15MB:20675ms
新的管道流
15KB:0.68ms;15MB:158ms
字節數組流
15KB:0.31ms;15MB:745ms
新的字節數組流
15KB:0.26ms;15MB:438ms
與上一篇文章中的性能差異只反映了我的機器中不斷變化的環境負載。您可 以從這些結果中看到,在大容量數據方面,新的管道流的性能遠好於蠻力解決方 案;但是,新的管道流的速度仍然只有我們分析的工程解決方案的速度的一半左 右。顯然,在現代的 Java 虛擬機中使用多個線程的開銷遠比以前小得多。
結束語
我們分析了兩組可替代標准 Java API 的流的流: BytesOutputStream 和 BytesInputStream 是字節數組流的非同步替代者。因為這些類的預期的用例涉 及單個線程的訪問,所以不采用同步是合理的選擇。實際上,執行時間的縮短( 最多可縮短 40%)很可能與同步的消滅沒有多大關系;性能得到提高的主要原因 是在提供只讀訪問時避免了不必要的復制。第二個示例 PipeInputStream 可替 代管道流;為了減少超過 99% 的執行時間,這個流使用寬松的約定、改進的緩 沖區大小和基於數組的操作。在這種情況下無法使用不同步的代碼;Java 語言 規范排除了可靠地執行這種代碼的可能性,否則,在理論上是可以實現最少鎖定 的管道。
字節數組流和管道流是基於流的應用程序內部通信的主要選擇。雖然新的 I/O API 提供了一些其它選擇,但是許多應用程序和 API 仍然依賴標准流,而 且對於這些特殊用途來說,新的 I/O API 並不一定有更高的效率。通過適當地 減少同步的使用、有效地采用基於數組的操作以及最大程度地減少不必要的復制 ,性能結果得到了很大的提高,從而提供了完全適應標准流框架的更高效的操作 。在應用程序開發的其它領域中采用相同的步驟往往能取得類似地性能提升。