應用背景簡介
在許多典型行業應用中,需要處理按照地域、時間或類別等維度產生並被管理 與維護的數據。被管理的數據分類方式基本維持恆定,而數據本身的內容(字段 )則需要根據業務需要不斷變化。一方面,被管理的數據必須支持按照權限進行 增刪改查操作;另一方面,還需要能夠進行所見即所得的圖表分析,如不同地域 之間數據的對比、時間維度數據變化規律的分析、不同類別數據的分類匯總、甚 至包括關聯數據之間的統計關系維持等。
例如在電力行業,電網公司按照地域進行劃分,其以電量、負荷為代表的核心 業務數據按照時間發生並被計量。這些被管理的數據具有一定的共性:數據所屬 地域、數據的時間劃分、數據的統計口徑等數據的維度基本維持不變,但數據的 類別卻隨著經濟形勢發展變化、不同地區產業結構、甚至是地方政策等經常發生 變化。以地區的月度用電量為例,雖然電力行業有用電分類標准用以統一各地區 的用電分類和類別名稱,但是經濟發展的不均衡和產業結構的差異,使得不同地 區實際需要關注的用電分類大同小異,這要求系統提供的數據管理分析功能能夠 對後台關系數據庫中數據表列的變化有較強的適應能力;另一方面,地區差異性 還導致了不同電網公司關注的數據集合本身就有差別,這又要求系統提供的數據 管理分析功能能夠適應增減數據庫表的個性化需求。
暫且把本文需要實現的目標功能稱為數據管理分析平台,它需要具備如下特點 :
這是一個用在產品中的功能,通用性和可維護性是第一位的。
這是一個 B/S 應用,用戶使用浏覽器訪問系統。
用戶在界面上可以對數據進行增刪改查。
不同數據之間的計算關系維持對用戶透明。
用戶可以對查詢到的數據進行作圖分析。
跨數據庫平台。
分析與方案選型
由於期望這個數據管理分析平台能夠在不同的產品中復用,因此本方案應針對 數據存儲在關系數據庫中的共同特征進行抽象,而不是針對特定產品的業務邏輯 進行抽象。換句話說,應該針對關系數據庫的表和字段進行抽象,而不是根據特 定產品的業務數據對象進行抽象。這允許最終實現能夠通過簡單配置來實現增加 和減少被管理數據類別(被管理表的擴展),以及對特定數據類別的增加和減少 被管理數據字段(被管理列的擴展)。
為何使用 JDBC
如果把被管理的數據,按照數據庫表映射為 POJO,再針對 POJO 實現後續的 展現和 Persistence 操作,即使 DIY 出一個像 Hibernate 一樣完整的 Persistence 工具來,需要增加被管理的數據類別時,仍然需要根據這個數據類 別對應的關系數據庫表,映射出一個 POJO 類。這個過程產生了新的Java 代碼, 意味著研發、測試、發布、實施等整個軟件工程過程被啟動了,把這個過程叫做 配置是明顯不合適的。
當然,B/S 架構應用中常用的通過表單提交方式實現 CRUD 的方案就更不可取 了,以流行的SSH(Struts、Spring、Hibernate)模式為例,增加新的被維護數 據,意味著至少需要增加一個 JSP 頁面用來生成用戶界面,一個 ActionFormBean 用來接收表單的數據,一個 Hibernate 的表映射 POJO 對象, 不僅同樣意味著啟動一個完整的軟件工程工程,而且工作量是隨著新增數據類別 的數目線性增長的。
說到這裡,可能您已經想到了數據庫客戶端,沒錯,數據庫客戶端就是一個典 型的所見即所得滿足用戶對數據進行增刪改查需求的實現。如果我們對一個數據 庫客戶端進行改造,讓它將查詢結果以用戶的業務視角進行展現,同時讓它在浏 覽器中運行,提供對所顯示數據進行作圖分析的功能,並且能夠維持關聯數據的 計算關系,那就圓滿了。
可惜的是,我們不能像數據庫客戶端那樣,讓最終用戶直接面臨存儲業務數據 的物理表,在一個數據庫表的直接查詢結果上進行增刪改查操作。因為在滿足數 據庫設計范式的前提下,數據表中有很多我們稱之為 ID 的字段。例如,一個按 地區存儲某種數據的表中,表示地區的字段中,一定是存儲了一個代表地區的ID 和另一個存儲地區信息的數據表做外鍵關聯,在查詢時,需要做多表連接才能獲 得地區 ID 對應的可以讓最終用戶讀懂的地區描述信息。
因此,我們的數據管理分析平台,至少應該有能力向用戶提供一個可以修改的 多表連接查詢結果集。如果你想到了視圖,那很好,因為確實很多關系數據庫都 支持視圖的更新,而且自打 JDK1.4 以後,JDBC 的RowSet 擴展也正式成為了 JDK 標准 API 的一部分,允許通過 JDBC 對查詢結果集進行數據更新操作。如果 我們的數據管理分析平台是綁定在特定數據庫平台之上的,那麼仔細研究一下對 應的數據庫平台對視圖更新的支持情況,仔細規約出一套可行性視圖設計方案也 許理論上是可能的。但是,我們的數據管理分析平台是希望能夠跨數據庫平台的 ,由於不同的數據庫在視圖更新上各有特點,采用這個方案,將會大大降低解決 方案的數據庫無關性。
既然如此,不妨抱住 JDBC 的大腿再好好想想。在 Java 世界裡,我們使用 JDBC 來完成對一行數據的增刪改查操作,有兩個必要條件:一是能獲得數據表的 名稱,二是唯一定位數據行的條件,通常是主鍵值。因此,對於一個連接查詢的 結果集,只要能夠確認被修改數據列對應的表,以及該列所在行對應的主鍵值, 使用標准 SQL,借助 JDBC 就能實現數據的更新操作。
以國家統計局的年度人口統計數據為例,用戶看到的展現形式如下:
表 1. 年度人口數據的用戶界面
地區 年份 總人口 男 女 城鎮 鄉村 全國 1999 125786 64692 61094 43748 82038 全國 2000 126743 65437 61306 45906 80837 全國 2001 127627 65672 61955 48064 79563 全國 2002 128453 66115 62338 50212 78241 全國 2003 129227 66556 62671 52376 76851 全國 2004 129988 66976 63012 54283 75705 全國 2005 130756 67375 63381 56212 74544 全國 2006 131448 67728 63720 57706 73742 全國 2007 132129 68048 64081 59379 72750
這裡的數據,應該來自關系數據庫中的兩個表,它們是:
表 2. 地區表(AREA)
Name Type Comments AREAID VARCHAR2(10) 地區 ID,主鍵 AREANAME VARCHAR2(20) 地區名稱
表 3. 人口表(POPULATION)
Name Type Comments AREAID VARCHAR2(10) 地區 ID,主鍵,外鍵 YEAR VARCHAR2(4) 年份,主鍵 TOTAL NUMBER 總人口 MEN NUMBER 男 WOMEN NUMBER 女 CITY NUMBER 城鎮 COUNTRY NUMBER 鄉村
表 1 所示的數據,應該來自表 2 和表 3 的連接查詢:
代碼 1. SQL 示例
Select
A.AREANAME,B.AREAID,B.YEAR,B.TOTAL,B.MEN,B.WOMEN,B.CITY,B.COUNTRY
from
AREA A, POPULATION B
where
A.AREAID = B.AREAID
如前所述,查詢結果集中包含了 AREA 表的AREANAME 列,滿足了用戶業務邏 輯視角的展示需要;包含了 POPULATION 表的AREAID 和 YEAR 兩列,滿足了在 POPULATION 表中定位數據行進行數據更新的需要。
采用 Applet + JSP
如果僅僅只需要滿足表 1 所示的圖形界面——一個展現數據的表格,那麼表 現層的選擇沒有任何約束,可以用在 Java EE 平台下的任何表現層技術都能滿足 。表格中的數據需要能夠修改;如地區這樣的列需支持下拉列表選擇填寫;表格 中的數據可以支持復制、粘貼;必須允許用戶根據表格中的數據制作圖表;圖表 可以放大縮小;圖表可以打印;圖表可以導出成圖片;……
隨著要求的進一步增多,可選范圍迅速減小,但是可以肯定的是,Java Swing + JFreeChart 差不多可以滿足所有要求。考慮到這個功能是用於 B/S 架構系統 中的,選擇嵌入 JSP 頁面的Applet
作為表現層策略,是合適的。
一旦表現層確定為 JSP + Applet 的方式,意味著客戶端獲取到了最大的可 交互性。在服務器端查詢的結果集,進行簡單封裝,采用對象序列化方式,將其 傳送到 Applet 端,Applet 端使用 Java Swing 構造顯示的圖形界面,並處理用 戶的操作。
使用模板 SQL 實現查詢
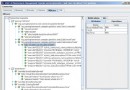
在用戶界面中,像時間和地區這樣的數據篩選條件,可能分別用下拉列表選擇 和樹形結構實現,以增強直觀度和易用性。換句話說,代碼 1 所示的SQL 語句中 ,需要根據用戶在界面上的選擇結果,生成適當的where 子句以響應篩選條件。 假設根據需求,構造了如下圖所示的UI:
圖 1. UI 示意圖
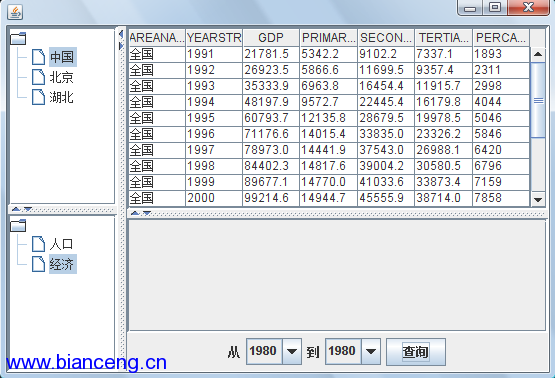
那麼,圖示的UI中,地區的選擇,在代碼 1 對應的SQL中,對應添加 B.AREAID=? 的where 子句選;兩個年份的選擇,對應添加 B.YEAR between ? and ? 的子句;而數據類別的選擇,則是用來確定被查詢的數據類別的。考慮使 用如代碼 2 所示的SQL 語句:
代碼 2. SQL 示例
Select
A.AREANAME,B.AREAID,B.YEAR,B.TOTAL,B.MEN,B.WOMEN,B.CITY,B.COUNTRY
from
AREA A, POPULATION B
where
A.AREAID = B.AREAID and B.@area and B.@year
上述代碼中,@area 和 @year 是需要根據用戶所選擇之條件進行替換的替換 標識。
不要小看這一點點小手段,統計局的大多數數據都是按照地區和時間進行分類 和統計的,因此上面的簡單方案已經可以處理大多數統計數據的查詢需求了。而 且 @area 這個替換標識,既可以用 AREAID=? 的子句替換,也可以用 AREAID in (?,?) 的子句替換。對應到操作中,就是可以實現不同地區數據的對比查詢,再 使用 JFreeChart 提供圖表支持,就可以實現一系列有價值的數據分析功能。
另外,代碼 2 的SQL 示例查詢的結果集中,POPULATION 表的AREAID 字段雖 然是查詢結果集的一部分,但是這個字段並不應該顯示在最終用戶界面中,查詢 出這個字段是為了滿足結果集可更新的必要條件。因此,可以提供一個額外的配 置信息,指明查詢結果集中的哪些字段在傳輸到客戶端 Applet 後需要被“隱藏 ”起來,客戶端 Applet 處理顯示時,不顯示這些字段,但需維持這些字段和數 據行之間的關聯關系不被破壞。
具體的實現細節,請參見本文附帶的參考實現代碼。
記錄用戶的增刪改操作
如何實現查詢操作,前面的小節已經表述了,本節的核心是解決用戶的數據修 改如何保存到數據庫中。
首先重復一下對關系數據庫中的一行記錄進行修改的兩個必要條件:一是能獲 得數據表的名稱,二是唯一定位數據行的條件,通常是主鍵值。通過上一節描述 的模板 SQL中查詢列的約定,可以確保目標數據表的主鍵列都被查詢到數據結果 集中,並被封裝後傳送到客戶端 Applet 以供顯示。因此,對數據增刪改支持的 實現,其實就是需要實現記錄用戶的增刪改操作,並由服務器端根據該記錄生成 系列 SQL 語句並執行。
修改操作,可以分為兩種情況,一種情況是修改非主鍵數據列,另一種情況是 修改主鍵數據列。前者是安全的,也是容易記錄的;後者則會帶來一些問題:一 是主鍵重復問題,不過這個無法由程序替用戶解決,二是主鍵被修改後,相當於 數據行的唯一定位條件丟失,如果不能找回原來的主鍵值,則無法完成相應的 Update 操作,還可能更新錯誤的數據行。
刪除操作,也有兩種情況,一種情況是刪除時,該行數據的主鍵列未被修改, 另一種情況時,刪除操作時,主鍵列已經被修改過了。結合修改情況考慮,也會 出現類似的情況,由於主鍵列已經被修改而造成刪除操作無效(主鍵對應的記錄 不存在)或者刪除了錯誤的記錄(主鍵修改後,與另一條已經存在的數據記錄一 致)。
對於增加,情況稍微復雜一點,一來是像表 1 所示的地區列,是屬於外鍵關 聯數據,要求用戶記住描述字段來填寫是不合理的,理應提供下拉列表供用戶選 擇;二來數據表中可能有標識性的ID 字段作為主鍵,例如自動增加的ID 主鍵, 可能由數據庫維護,也可能由程序維護,需要特別處理。考慮到需要適應不同數 據庫平台的限制,保險起見,可以約定都使用程序維護。
維持關聯數據的一致性
一旦涉及到數據修改,就有可能涉及到數據一致性問題,例如前面列舉的 POPULATION 表記錄了人口數據,本文附件的參考實現中,還有一個 ECONOMIC 表 記錄了經濟數據,其中的人均 GDP 數據是和 POPULATION 表中的總人口以及 ECONOMIC 表中的GDP 有邏輯計算關系的。如果用戶修改了總人口數據,那麼人均 GDP 理應一並被修改,如果用戶修改了 GDP 總值數據,那麼人均 GDP 同樣也應 重新計算。
數據庫觸發器理論上是一種選擇,但在本文的場景下,它至少有兩方面缺點。 首先,它是數據庫平台相關的,編寫的觸發器和存儲過程有移植代價;其次,數 據之間的計算關系,屬於業務邏輯,在當前分層而治的主流架構思想下,在數據 庫中處理部分業務邏輯,這屬於業務邏輯的不合理蔓延。
只要換種思路,事情就變得簡單了。維持關聯數據一致性的邏輯,在 Java 類 中實現;當對應的數據被修改後,只要能夠出發相應 Java 類的調用就行了。對 於圖 1 所示的一個被管理的數據類別,數據被修改後,可能出發的關聯數據計算 是既定的。在配置時,增加一個新的配置項,即數據修改後需要調用的統計實現 Java 類就可以了。配置項的內容可以直接使用 Java 的類名,約定提供默認無參 數構造函數,實現統一接口,便於進行 reflect 調用就行了。
架構設計
根據前面章節的分析,確定使用 Applet 作為表現端,服務器端則采用 Servlet 與 Applet 進行通信,接收來自 Applet 的用戶請求,並將處理後的結 果返回給客戶端。如下圖所示:
圖 2. 架構簡圖
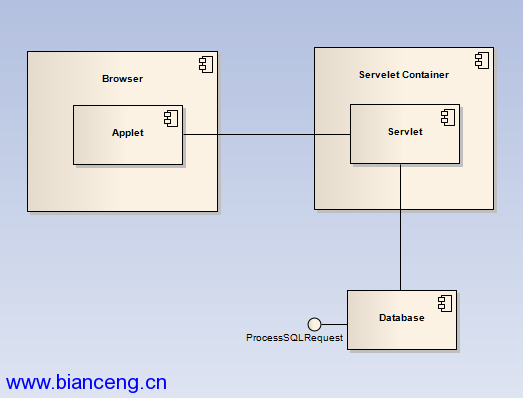
其中,Applet 和 Servlet 之間的通信使用 java.net.URLConnection 和對象 序列化實現,Servlet 和 Database 當然是通過 JDBC 執行 SQL 語句來完成交互 。
圖 3. 類圖
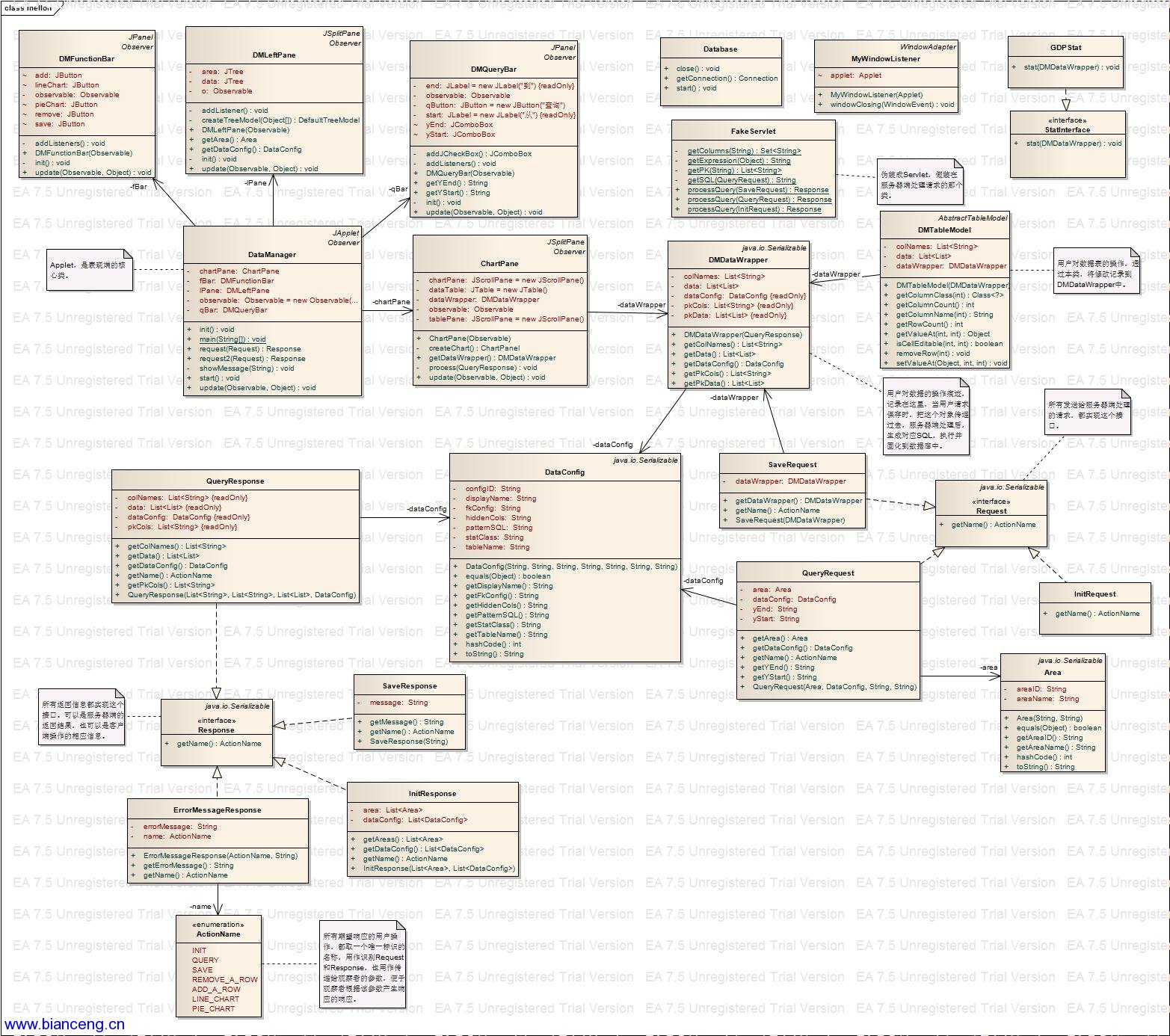
參考實現說明
有興致的讀者可以下載本文附帶的附件,MellonDataManager.jar,它包含一 個由 NetBeans6.5 打包的可執行 jar 文件:DataAnalyse.jar。還有一個 lib 目錄,裡面應該放置示例代碼的執行所需要的3 個 jar 文件,derby.jar(Java DB),可以在 JDK1.6中獲得,也可以到 http://developers.sun.com/javadb/downloads/index.jsp 下載;jcommon- 1.0.16.jar(JFreeChart 需要的支持包)和 jfreechart-1.0.13.jar,這兩個包 可以到 http://www.jfree.org/jfreechart/download.html 下載。以及一個 src 目錄,是所有的源文件。
cn.mellon.Database 類,負責初始化數據庫和提供數據庫連接。
cn.mellon.FakeServlet 類,因為本文所描述的應用應該是一個 Web Application,為了使程序能夠作為獨立 Application 執行,使用本類偽裝 Servlet 來接收 Applet 發送的請求,其實是 Applet 直接在同一個 JVM中調用 的,不過將其改為 Servlet,並讓整個應用運行在 Tomcat中,也是非常容易的事 情。
cn.mellon.DataManager 類,是核心的Applet 實現,同樣的,為了方便程序 作為獨立 Application 運行,這個 Applet 被添加了 main 方法,因此它兼具 Applet 和 Application 雙重身份。
當您下載到三個必須的jar 包,並將起放置在指定的lib 目錄後,您可以使用 命令行 java – jar DataAnalyse.jar 來運行這個示范實現,程序首先初始化數 據庫,創建幾個示例的表並未對應表插入一定數量的數據。
程序的運行效果,如下圖所示:
圖 4. 參考實現運行效果

對表格中數據的修改和刪除操作,都記錄在 cn.mellon.DMDataWrapper 類中 ,cn.mellon.FakeServlet 通過解析這個類,生成相應的SQL 語句後執行,從而 將數據修改更新到數據庫中。
圖 3 的界面中,左上方的地區選擇樹內容來自地區表,可以修改地區表對應 的數據後,重新啟動程序觀察效果。配置表是本功能實現的核心配置數據所在, 本參考實現也一並將其暴露以允許在界面中修改配置信息,觀察效果。同樣的, 修改保存後,需要重新啟動程序,方能看到效果。因為配置信息和地區信息一樣 ,都是在 Applet 加載時,從服務器端獲取並被緩存在 Applet 端的。
還有一些和本文主題關系不大的實現細節,讀者可以從代碼或注釋中閱讀到, 如果想進一步交流,可以發郵件給我。
優勢與局限性分析
本文所述的方案是應用於 Web Application 的,對於經常需要添加新的數據 類別的應用,可以免去針對每種新增數據重復開發對應的前端頁面和後台處理類 等服務器端程序。通過簡單配置即可對新增的數據表對應的數據類別完成增刪改 查系列操作,也同時獲得了相關的圖表分析功能,相關的分析功能越多,這個配 置產生的收益就越大。
本方案也有局限性,由於本方案是基於 JDBC 的,因此當本方案和基於 O/R Mapping 實現 Persistence 層的Web Application 共存時,與 O/R Mapping 的 緩存機制恐無法兼容,因為本方案相當於不經 O/R Mapping 層直接修改了數據庫 表。
另外,本方案的數據被查詢出來後,處在離線狀態,不同用戶在同一時間對相 同數據的修改動作,是相互覆蓋的,至少在服務器端實現同步處理之前是這樣的 。如果使用系統的用戶數量有限,且各自維護的數據沒有重疊,基本上是安全的 。如果使用系統的用戶數量很大,彼此數據重疊,則需要考慮控制同步問題,很 明顯本方案是不適合用在並發訪問數量非常大的匿名訪問系統中的。
本文配套源碼