在我們測試 Java 應用程序時,往往需要連接數據庫,並從數據庫中獲得准確 的測試數據用以測試應用程序是否正確。然而准備測試數據的工作較為復雜,一 旦數據庫中的數據發生變化,要想恢復到之前的版本也很費時。對於那些沒有條 件連接數據庫的測試者而言,測試工作是不能進行下去的。因此,如果可以為某 個待測應用准備一套完備的測試數據,讓程序開發、測試人員在不依賴於具體數 據庫的情況下對應用進行測試,這無疑是十分方便的。
簡介
JdbcProxy 是 SourceForge 上一個開源的 Java 項目,用 Java 語言編寫, 遵循 LGPL 和 MPL1.1 協議,由 Frans van Gool 開發,支持 JDBC2.0 規范。通 過繼承和重寫 JDBC2.0 的接口,將一個 Java 應用訪問數據庫的過程記錄在 XML 文件中,並通過這些文件在脫離數據庫的情況下重現這個調用過程。 JdbcProxy 可以用在 Java 應用程序的測試中,進行數據准備並模擬數據庫調用過程。讀者 可以從 JdbcProxy 主頁 獲得最新的程序源代碼以及說明文檔。目前最新的版本 是 1.1 。
使用 JdbcProxy 代替普通的數據庫調用可以滿足程序開發、測試人員的很多 需求,使准備測試數據的工作變得簡單。以文章查詢系統為例,有些測試用例需 要測試當數據庫中沒有數據時頁面的顯示情況——顯示沒有相應數據的頁面;有 些測試用例需要測試當數據庫中只有一條數據時頁面的顯示情況——顯示文章的 內容而不是文章的列表;還有些測試用例需要測試頁面的分頁效果,這時就需要 為程序准備不同的測試數據。如果采用直接連接測試用數據庫的方式進行測試, 不同的測試用例需要重新准備測試數據庫,操作起來比較復雜,也不能同時測試 不同的測試場景。如果使用 JdbcProxy,就可以為同一個 Java 程序准備不同的 測試用數據文件,測試者可以脫離後端數據庫的限制,只需要訪問到數據文件就 能完成測試。不同測試人員能夠彼此不受影響的同時測試這個應用,從而大大簡 化了准備測試環境的過程。
使用 JdbcProxy
JdbcProxy 提供了兩種記錄 JDBC 調用過程的方式,一種是方便開發人員和測 試人員閱讀的,另一種是用於回放 JDBC 調用過程的。
第一種方式主要是為了讓開發人員和測試人員能夠了解 Java 應用調用 JDBC 的詳細信息,當應用程序較為復雜——例如進行了多表查詢,采用這種記錄方式 可以讓開發人員和測試人員一目了然的看到應用程序訪問數據庫的過程。
第二種方式是為測試程序准備數據的關鍵步驟之一。為了回放 JDBC 調用過程 ,JdbcProxy 分別處理應用程序對數據庫的每個請求 (request) 與響應 (response),並在指定目錄下生成一系列 XML 文件,這些文件是回放 JDBC 調用 過程的基礎。這些 request/response 文件並不能直接被 JdbcProxy 調用, JdbcProxy 還提供了一個 StubTraceMerger 工具,用來將這些 request/response 文件整合在一個文件中,這個整合的文件就是我們測試 Java 應用所需要的數據文件。
JdbcProxy 提供了一種通過 HTTP 服務器發送請求並接收響應的機制,這些請 求和響應都按照應用程序的 JDBC 調用順序記錄在整合文件中,當 Java 應用試 圖通過 JDBC 連接數據庫時,JdbcProxy 會通過 HTTP 服務器從整合文件中讀取 相應的數據,模擬調用數據庫的過程,使用戶得以在脫離數據庫的情況下進行 Java 應用的測試。
因此要想利用 JdbcProxy 測試 Java 應用程序,首先需要生成用於回放 JDBC 調用過程的 request/response 文件,然後將這些 request/response 文件整合 在一個文件中,最後將這個整合的數據文件提供給 HTTP 服務器,這樣 JdbcProxy 就可以通過 HTTP 服務器訪問到數據文件,實現脫離數據庫進行測試 的目的。
下面將對 JdbcProxy 提供的每個功能做詳細的介紹。
記錄方便開發人員和測試人員閱讀的 JDBC 調用過程
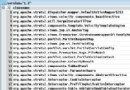
JdbcProxy 可以跟蹤 JDBC 調用過程,生成方便開發人員和測試人員閱讀的文 件格式。在普通的數據庫調用中,如果開發人員和測試人員想了解 JDBC 的調用 過程,或者需要完整的查看某個 SQL 語句,則需要手工將這些信息打印出來或者 記錄在日志中。 JdbcProxy 的這個功能就像為 JDBC 的調用過程自動記錄了一個 日志,開發人員和測試人員可以從日志中獲得被調用的每一個方法,以及調用方 法的參數和返回值。這樣便於開發人員和測試人員發現由於 SQL 語句拼寫錯誤而 導致的數據庫訪問失敗,或是由於數據庫中沒有數據而導致的空指針異常,使應 用程序的數據庫訪問過程更加直觀。可以根據清單 1中的示例代碼生成 JDBC 調 用過程。
清單 1
import java.sql.Statement;
public class JdbcProxyDemo {
public static void main(String args[]) throws Exception {
String driver = "nl.griffelservices.proxy.jdbc.oracle.StubTracerDriver";
String url = "jdbc:tracer::COM.ibm.db2.jdbc.app.DB2Driver:jdbc:db2:SAMPLE";
Class.forName(driver);
Connection connection = DriverManager.getConnection (url);
Statement stmt = connection.createStatement();
stmt.executeUpdate("DELETE FROM greetings WHERE greeting='Good Night'");//delete
stmt.executeUpdate("INSERT INTO greetings VALUES('Good Evening')"); //insert
stmt.executeUpdate("UPDATE greetings SET greeting = 'Good Night'
WHERE greeting = 'Good Evening'"); //update
ResultSet rs = stmt.executeQuery("SELECT * FROM greetings");//select
while (rs.next()) {
System.out.println(rs.getString("greeting"));
}
rs.close();
stmt.close();
connection.close();
}
}
與普通數據庫調用不同,清單 1中示例程序中所需的數據庫驅動是 JdbcProxy 提供的StubTracerDriver,URL 的結構如下:
jdbc:tracer:<filename>:<driver>:<url>
其中:
<filename> 是保存結果的文件名;如果為空,結果會被輸出到控制台 。
<driver> 是數據庫驅動名,該示例程序使用的是 db2 的驅動。
<url> 是數據源的 URL,該示例程序使用 jdbc:db2:SAMPLE,不需要用 戶名和密碼。
運行上述程序得到清單 2的記錄結果:
清單 2
//記錄調用 getConnection 方法java.sql.Driver.connect (jdbc:db2:SAMPLE, {}) returns
DB2Connection
{
connectionHandle = 1
SPConnected = false
source = SAMPLE
user =
conArgs =
closed = false
describeCached = false
describeParam = true
isReadOnly = false
autoClose = false
LONGDATA compat = false
}
//記錄建立的 Connection 對象
java.sql.Connection.<init>(
DB2Connection
{
connectionHandle = 1
SPConnected = false
source = SAMPLE
user =
conArgs =
closed = false
describeCached = false
describeParam = true
isReadOnly = false
autoClose = false
LONGDATA compat = false
}
)
//記錄調用 createStatement 方法
java.sql.Connection.createStatement() returns
DB2Statement
{
Connection -> DB2Connection
Connection -> {
Connection -> connectionHandle = 1
Connection -> SPConnected = false
Connection -> source = SAMPLE
Connection -> user =
Connection -> conArgs =
Connection -> closed = false
Connection -> describeCached = false
Connection -> describeParam = true
Connection -> isReadOnly = false
Connection -> autoClose = false
Connection -> LONGDATA compat = false
Connection -> }
ResultSet -> null
statementHandle = 1:1
SQL = null
maxRows = 0
maxFieldSize = 0
rowCount = 0
colCount = 0
closed = false
internalStmt = false
returnCode = 0
}
//記錄建立的 Statement 對象
java.sql.Statement.<init>(
DB2Statement
{
Connection -> DB2Connection
Connection -> {
Connection -> connectionHandle = 1
Connection -> SPConnected = false
Connection -> source = SAMPLE
Connection -> user =
Connection -> conArgs =
Connection -> closed = false
Connection -> describeCached = false
Connection -> describeParam = true
Connection -> isReadOnly = false
Connection -> autoClose = false
Connection -> LONGDATA compat = false
Connection -> }
ResultSet -> null
statementHandle = 1:1
SQL = null
maxRows = 0
maxFieldSize = 0
rowCount = 0
colCount = 0
closed = false
internalStmt = false
returnCode = 0
}
)
//執行刪除操作,操作成功,返回值是 1
java.sql.Statement.executeUpdate(DELETE FROM greetings WHERE greeting='Good Night')
returns 1
//執行添加操作,操作成功,返回值是 1
java.sql.Statement.executeUpdate(INSERT INTO greetings VALUES('Good Evening'))
returns 1
//執行修改操作,操作成功,返回值是 1
java.sql.Statement.executeUpdate(UPDATE greetings SET greeting = 'Good Night'
WHERE greeting = 'Good Evening')
returns 1
//執行查詢操作並返回結果集
java.sql.Statement.executeQuery(SELECT * FROM greetings) returns
DB2ResultSet
{
Statement -> DB2Statement
Statement -> {
Statement -> Connection -> DB2Connection
Statement -> Connection -> {
Statement -> Connection -> connectionHandle = 1
Statement -> Connection -> SPConnected = false
Statement -> Connection -> source = SAMPLE
Statement -> Connection -> user =
Statement -> Connection -> conArgs =
Statement -> Connection -> closed = false
Statement -> Connection -> describeCached = false
Statement -> Connection -> describeParam = true
Statement -> Connection -> isReadOnly = false
Statement -> Connection -> autoClose = false
Statement -> Connection -> LONGDATA compat = false
Statement -> Connection -> }
Statement -> statementHandle = 1:1
Statement -> SQL = SELECT * FROM greetings
Statement -> maxRows = 0
Statement -> maxFieldSize = 0
Statement -> rowCount = 0
Statement -> colCount = 0
Statement -> closed = false
Statement -> internalStmt = false
Statement -> returnCode = 0
Statement -> }
numCols = 1
mappedRS = false
nullTag = true
closed = false
maxFieldSize = 0
returnCode = 0
returnLen = 0
colTypes[0] = 0
colSizes[0] = 0
}
//記錄建立的 ResultSet 對象
java.sql.ResultSet.<init>(
DB2ResultSet
{
Statement -> DB2Statement
Statement -> {
Statement -> Connection -> DB2Connection
Statement -> Connection -> {
Statement -> Connection -> connectionHandle = 1
Statement -> Connection -> SPConnected = false
Statement -> Connection -> source = SAMPLE
Statement -> Connection -> user =
Statement -> Connection -> conArgs =
Statement -> Connection -> closed = false
Statement -> Connection -> describeCached = false
Statement -> Connection -> describeParam = true
Statement -> Connection -> isReadOnly = false
Statement -> Connection -> autoClose = false
Statement -> Connection -> LONGDATA compat = false
Statement -> Connection -> }
Statement -> statementHandle = 1:1
Statement -> SQL = SELECT * FROM greetings
Statement -> maxRows = 0
Statement -> maxFieldSize = 0
Statement -> rowCount = 0
Statement -> colCount = 0
Statement -> closed = false
Statement -> internalStmt = false
Statement -> returnCode = 0
Statement -> }
numCols = 1
mappedRS = false
nullTag = true
closed = false
maxFieldSize = 0
returnCode = 0
returnLen = 0
colTypes[0] = 0
colSizes[0] = 0
}
)
//執行 rs.next() 方法,返回值是 true
java.sql.ResultSet.next() returns true
//執行 rs.getString() 方法,返回對應列的值
java.sql.ResultSet.getString(greeting) returns Good Night
//執行 System.out.println Good Night
java.sql.ResultSet.next() returns true
java.sql.ResultSet.getString(greeting) returns Good Morning
Good Morning
java.sql.ResultSet.next() returns true
java.sql.ResultSet.getString(greeting) returns Good Afternoon
Good Afternoon
//執行 rs.next() 方法,返回值是 false
java.sql.ResultSet.next() returns false
//關閉 ResultSet
java.sql.ResultSet.close()
//關閉 Statement
java.sql.Statement.close()
//關閉 Connection
java.sql.Connection.close()
可以看到,JdbcProxy 記錄下了每一個 JDBC 調用的參數和返回值,可以很容 易的通過這些值判斷出程序在什麼地方出現問題。如果運行過程中出現異常, JdbcProxy 還可以將拋出的異常記錄下來。
記錄用於回放的 JDBC 調用過程
方便開發人員和測試人員閱讀的 JDBC 調用過程其記錄形式不便於進行解析, 因此並不能直接被用來回放的 JDBC 調用過程。為了簡化准備數據的過程, JdbcProxy 還可以生成一種用於回放 JDBC 調用過程的,特別是易於在 HTTP 服 務器上使用的記錄文件。在運行新的程序之前,我們首先需要新建一個空的文件 夾 output 用來存放 JdbcProxy 生成的一系列 request/response 文件,然後將 url 做以下修改,如 清單 3 所示。
清單 3
String url = "jdbc:stubtracer:output:COM.ibm.db2.jdbc.app.DB2Driver:jdbc:db2:SAMPLE" ;
URL 結構如下:
jdbc:stubtracer:<foldername>:<driver>:<url>< /CODE>
其中:
<foldername> 是輸出 request/response 文件的位置;如果為空則將 文件內容輸出到控制台。
<driver> 是數據庫驅動名,該示例程序使用的是 DB2 的驅動。
<url> 是數據源的 URL,該示例程序使用 jdbc:db2:SAMPLE,不需要用 戶名和密碼。
運行上述程序會在指定目錄下生成 32 個以 request/response 開頭的文本文 件,如圖 1所示。
圖 1. request/response 文件
這些文件包含了回放 JDBC 調用過程所需的所有請求和響應。以建立 Connection 的請求為例,該示例程序對數據庫的第一個請求就是建立 Connection,這個過程記錄在 request_0_0.txt 文件中,參見清單 4。其中文件 名中的 2 個“ 0 ”分別代表本次 JDBC 調用的 id 和 status,調用的方法是 connect 。
清單 4
<?xml version="1.0" encoding="UTF-8"?>
<request>
<class>java.sql.Driver</class>
<id>0</id>
<status>0</status>
<method>connect</method>
<parameter>
<class>java.lang.String</class>
<value>jdbc:db2:SAMPLE</value>
</parameter>
<parameter>
<class>java.util.Properties</class>
<value>{language=C}</value>
</parameter>
</request>
JdbcProxy 會根據 request 文件中 id 和 status 的值找到對應的 response 文件,在本例中為 response_0_0.txt,參見清單 5。在 response_0_0.txt 中, 我們看到已經新建了一個 java.sql.Connection 的對象,並且指定了下一個請求 的 id 和 status 。
清單 5
<?xml version="1.0" encoding="UTF-8"?>
<response>
<newstatus>1</newstatus>
<returnvalue>
<nl.griffelservices.proxy.stub.ProxyObject>
<class>java.sql.Connection</class>
<id>1</id>
<status>0</status>
</nl.griffelservices.proxy.stub.ProxyObject>
</returnvalue>
</response>
整合 request/response 文件
在上面生成的 request/response 文件還需要進行整合才能提供給 HTTP 服務 器用於回放 JDBC 調用過程。可以使用 StubTraceMerger 工具將一系列 request/response 文件整合成一個文件。整合文件需要運行的命令如清單 6所示 。
清單 6
StubTracerMerger output
該命令的結構如下:
StubTracerMerger <foldername>[<id>[<status>] ]
其中:
<foldername> 是 request/response 文件存放的位置,不可為空。
<id> 是需要整合的初始響應的 id,默認值為 0,即整合完整的 JDBC 調用過程。
<status> 是需要整合的初始響應的 status,默認值為 0 。
運行上述命令,StubTracerMerger 會將所有 request/response 文件的內容 按照調用的順序整合在一個 <response> 元素下,並在控制台上輸出一段 整合的 XML 文件。從 XML 文件中,我們能夠看到 StubTracerMerger 將新建的 Connection,Statement 以及 ResultSet 對象記錄在 ProxyObject 結點中,調 用的方法則被記錄在 requestresponse 結點。例如:java.sql.Connection 調用 了 createStatement() 以及 close() 兩個方法,所以 Connection 的 ProxyObject 結點中包含了兩個 requestresponse 子結點;生成的 java.sql.Statement 分別進行了刪除、添加、修改、查詢,以及關閉 Statement 操作,因此該結點包含 5 個 requestresponse 子結點。其中 id 代表對象的標 識,status 代表該對象狀態,初始值為 0 。按照這種方式,JdbcProxy 將 Java 應用程序調用 JDBC 訪問數據庫的過程記錄成了一個 XML 文件。清單 7中給出一 段執行刪除操作的示例,讀者可以在文章最後的 下載 區下載到完整的 XML 文件 。
清單 7
<?xml version="1.0" encoding="UTF-8"?>
<response>
<newstatus>1</newstatus>
<returnvalue>
<nl.griffelservices.proxy.stub.ProxyObject>
<!--初始化 Connection 對象-->
<class>java.sql.Connection</class>
<!--Connection 對象的 id 是 1-->
<id>1</id>
<!--Connection 對象的 status,初始值為 0-->
<status>0</status>
<requestresponse>
<request>
<!--第一次使用 Connection 對象,調用 createStatement 方法,因此 status 賦值 0-->
<status>0</status>
<!--調用 createStatement 方法-->
<method>createStatement</method>
</request>
<response>
<!--Connection 對象下一次被使用時 status 的值-->
<newstatus>1</newstatus>
<returnvalue>
<nl.griffelservices.proxy.stub.ProxyObject>
<!--初始化 Statement 對象-->
<class>java.sql.Statement</class>
<!--Statement 對象的 id 是 2-->
<id>2</id>
<!--Statement 對象的 status,初始值為 0-->
<status>0</status>
<!--執行刪除操作的代碼-->
<requestresponse>
<request>
<!--第一次使用 Statement 對象,調用 executeUpdate 方法,因此 status 賦值 0-->
<status>0</status>
<!--調用 executeUpdate 方法-->
<method>executeUpdate</method>
<!--executeUpdate 方法的參數-->
<parameter>
<class>java.lang.String</class>
<!--執行刪除的 SQL 語句-->
<value>DELETE FROM greetings
WHERE greeting='Good Night'</value>
</parameter>
</request>
<response>
<newstatus>1</newstatus>
<!--執行刪除操作成功,返回值為 1-->
<returnvalue>
<int>1</int>
</returnvalue>
</response>
</requestresponse>
<!--省去執行插入、更新、查詢操作的代碼-->
<requestresponse>
<request>
<status>4</status>
<!--關閉 Statement 對象-->
<method>close</method>
</request>
<response>
<newstatus>5</newstatus>
<returnvalue/>
</response>
</requestresponse>
</nl.griffelservices.proxy.stub.ProxyObject>
</returnvalue>
</response>
</requestresponse>
<requestresponse>
<request>
<status>1</status>
<!--關閉 Connection 對象-->
<method>close</method>
</request>
<response>
<newstatus>2</newstatus>
<returnvalue/>
</response>
</requestresponse>
</nl.griffelservices.proxy.stub.ProxyObject>
</returnvalue>
</response>
通過 HTTP 服務器回放 JDBC 調用過程
JdbcProxy 提供了通過 HTTP 服務器回放 JDBC 調用過程的方式,即用戶只需 要將准備好的數據文件提供給 HTTP 服務器就可以在脫離數據庫的情況下模擬對 數據庫的訪問,完成 Java 應用的測試。如果想通過 HTTP 服務器回放 JDBC 調 用過程,只需要修改示例程序中的 url,如清單 8所示。
清單 8
String url = "jdbc:stub:localhost:80:1000";
URL 結構如下:
jdbc:stub:<hostname>:<port>:<timeout>
其中:
<hostname> 是 HTTP 服務器的主機名,本地機器為 localhost 。
<port> 是 HTTP 服務器的端口號。
<timeout> 是超時時間,單位是毫秒。
在該示例程序中我們采用 Apache 的 HTTP server 2.2.4,使用默認端口 80 。用整合的數據文件替換 \htdocs 目錄下的默認歡迎頁面,這樣 HTTP 服務器就 可以從本地 80 端口接收請求並在數據文件中匹配到相應的 response,將 response 內容返回給 Java 應用程序。我們可以在控制台得到與直接連接數據庫 時相同的返回結果,JdbcProxy 可以通過預先准備好的數據文件,在不連接數據 庫的情況下通過 HTTP 服務器獲得准確的響應數據,測試 Java 應用程序是否能 夠正確執行。
開發人員和測試人員可以通過修改整合的數據來獲得不同的測試場景,例如按 照整合文件的數據格式添加新的數據、刪除多余的數據、或是修改數據的類型, 用來構建不同的測試用例,滿足不同測試的需要。
改進 JdbcProxy
在整合 request/response 文件時,JdbcProxy 只能將整合的數據文件輸出到 控制台,這種輸出方式非常不利於在回放過程中使用。如果可以直接將其輸入到 \htdocs 目錄下的默認文件中,則省去了每次移動文件的麻煩。另外,JdbcProxy 只提供通過 HTTP 服務器回放 JDBC 調用過程的方式,必須有 HTTP 服務器的支 持。因此,我們對 JdbcProxy 進行了一些改進,首先可以將整合的文件直接輸出 到指定目錄下,其次可以不依靠 HTTP 服務器直接從整合文件中獲取 JDBC 響應 。
下面將介紹如何直接生成整合文件以及通過整合文件回放 JDBC 調用過程。
直接生成整合文件
在生成整合文件時,我們可以省去一系列生成 request/response 文件的步驟 ,直接將每個 request 和 response 存儲於一個靜態的 TreeMap 中,再將 TreeMap 中的內容整合並按照指定路徑輸出到文件中。這樣做可以大大節省依次 讀取每個 request/response 文件所需要的時間,提高程序運行的效率。同時, 可以自行指定整合文件的輸出位置,不需要手動將整合的數據文件內容從控制台 復制到 \htdocs 目錄下的默認歡迎頁面,在一定程度上減少了工作量。此處的改 動包括:修改了 StubTracerHandler 類的 invoke 方法,在 nl.griffelservices.proxy.stub 包下增加了 FileStubTracerMerger 類,demo 包下增加了 GenerateMergerFile 類。
在運行程序之前,需要先將 StubTracerHandler 類的 invoke 方法做如下修 改:
tracer.trace(request, response);
改成
new FileStubTracerMerger(map,request,response);
以便直接從內存中讀取 response 生成整合文件。此外還需要運行下面程序, 如清單 9所示。
清單 9
import java.sql.Statement;
public class JdbcProxyDemo {
public static void main(String args[]) throws Exception {
String driver = "nl.griffelservices.proxy.jdbc.oracle.StubTracerDriver";
String url = "jdbc:stubtracer::COM.ibm.db2.jdbc.app.DB2Driver:jdbc:db2:SAMPLE";
Class.forName(driver);
Connection connection = DriverManager.getConnection (url);
Statement stmt = connection.createStatement();
stmt.executeUpdate("DELETE FROM greetings WHERE greeting='Good Night'");//delete
stmt.executeUpdate("INSERT INTO greetings VALUES('Good Evening')");//insert
stmt.executeUpdate("UPDATE greetings SET greeting = 'Good Night'
WHERE greeting = 'Good Evening'"); //update
ResultSet rs = stmt.executeQuery("SELECT * FROM greetings");//select
while (rs.next()) {
System.out.println(rs.getString("greeting"));
}
rs.close();
stmt.close();
connection.close();
//將整合數據文件輸出到 output/mergerfile.xml
GenerateMergerFile mergerfile = new GenerateMergerFile ("output/mergerfile.xml");
mergerfile.generateFile();
}
}
其中所需要的 driver 與前面記錄用於回放的 JDBC 調用過程中的 driver 相 同,url 則不需要提供 foldername 。另外還要在程序的最後加入兩行代碼, GenerateMergerFile 方法所需的參數即整合文件的相對路徑和文件名。運行上述 程序,在 output 目錄下會生成名為 mergerfile.xml 的整合文件, mergerfile.xml 即為測試 Java 應用程序所准備的數據文件。
通過整合文件回放調用過程
對於直接通過整合文件回放 JDBC 調用過程的問題,我們重寫了 JdbcProxy 中的一些方法。依然使用前面的示例程序,如果采用這種方式回放調用過程,我 們要修改 driver 和 url 兩個參數,如清單 10所示。
清單 10
String driver = "nl.griffelservices.proxy.jdbc.oracle.FileStubTracerDriver";
String url = "jdbc:stub:output/mergerfile.xml";
通過對這兩個參數的修改,JdbcProxy 將調用我們重寫的方法,不需要通過 HTTP 服務器而是直接從整合文件中獲取程序所需的響應結果。此處的改動包括: 在 nl.griffelservices.proxy.stub 包下增加了 FileClient、FileStub、 FileStubHandler、FileStubTracerMerger 四個類,在 nl.griffelservices.proxy.jdbc.oracle 包下增加了 FileStubTracerDriver 類 ,在 nl.griffelservices.proxy.jdbc.util 包下增加了 FileCombinedHandler 類。我們主要修改了 FileCombinedHandler 類中的 DriverUrl 方法用於解析新 的參數;修改了 FileClient 類中的 invoke 方法用於從整合文件中讀取相應的 response 。讀者可以從文章最後的下載區中下載修改後的代碼。
此時數據庫驅動是我們改寫的提供的FileStubTracerDriver,URL 的結構如下 :
jdbc:stub:<filepath>
其中:
<filepath> 是整合文件的相對路徑和文件名。
運行上述程序,我們可以在控制台得到與直接連接數據庫時相同的返回結果, 不必通過 HTTP 服務器 JdbcProxy 也可以進行 Java 應用的測試。
結語
JdbcProxy 可以讓程序開發人員和測試人員脫離數據庫的限制完成測試工作。 如果測試工作需要多人共同完成,那麼采用 HTTP 服務器的方式能夠保證數據的 一致性,更加便於小組成員協作;如果准備數據以及測試程序的工作由同一人完 成,那麼通過整合文件的方式則更加直接,能夠提高程序運行的效率。
本文以一個實例介紹了 JdbcProxy 的基本功能,以及如何使用 JdbcProxy 進 行數據的准備和測試。考慮到 JdbcProxy 只能通過 HTTP 服務器回放 JDBC 訪問 ,本文還對 JdbcProxy 進行了改進,提供了直接通過整合的數據文件進行回放的 方式。您可以根據實際情況選擇合適的回放方式,參照這個實例對 JdbcProxy 進 行修改,來測試您的 Java 應用程序,實現脫離數據庫的測試工作。
本文配套源碼