在本文的第一部分中,我們通過一個單一線程的基准,比較了同步的 StringBuffer和非同步的StringBuilder之間的性能。從最初的基准測試結果來看 ,偏向鎖提供了最佳的性能,比其他的優化方式更有效。測試的結果似乎表明獲 取鎖是一項昂貴的操作。但是在得出最終的結論之前,我決定先對結果進行檢驗 :我請我的同事們在他們的機器上運行了這個測試。盡管大多數結果都證實了我 的測試結果,但是有一些結果卻完全不同。在本文的第二部分中,我們將更深入 地看一看用於檢驗測試結果的技術。最後我們將回答現實中的問題:為什麼在不 同的處理器上的鎖開銷差異如此巨大?
基准測試中的陷阱
通過一個基准測試,尤其是一個“小規模基准測試”(microbenchmark),來 回答這個問題是非常困難的。多半情況下,基准測試會出現一些與你期望測量的 完全不同的情景。即使當你要測量影響這個問題的因素時,結果也會被其他的因 素所影響。有一點在這個實驗開始之初就已經很明確了,即這個基准測試需要由 其他人全面地進行審查,這樣我才能避免落入報告無效基准測試數據的陷阱中。 除了其他人的檢查以外,我還使用了一些工具和技術來校驗結果,這些我會在下 面的幾節中談到。
結果的統計處理
大多數計算機所執行的操作都會在某一固定的時間內完成。就我的經驗而言, 我發現即使是那些不確定性的操作,在大多數條件下基本上也能在固定的時間內 完成。正是根據計算的這種特性,我們可以使用一種工具,它通過測量讓我們了 解事情何時開始變得不正常了。這樣的工具是基於統計的,其測量結果會有些出 入。這就是說,即使看到了一些超過正常水平的報告值,我也不會做過多過的解 釋的。原因是這樣的,如果我提供了指令數固定的CPU,而它並沒有在相對固定的 時間內完成的話,就說明我的測量受到了一些外部因素的影響。如果測試結果出 現了很大的異常,則意味著我必須找到這個外部的影響進而解決它。
盡管這些異常效果會在小規模基准測試中被放大,但它不至於會影響大規模的 基准測試。對於大規模的基准測試來說,被測量的目標應用程序的各個方面會彼 此產生干擾,這會帶來一些異常。但是異常仍然能夠提供一些很有益的信息,可 以幫助我們對干擾級別作出判斷。在穩定的負荷下,我並不會對個別異常情況感 到意外;當然,異常情況不能過多。對於那些比通常結果大一些或小一些的結果 ,我會觀察測試的運行情況,並將它視為一種信號:我的基准測試尚未恰當地隔 離或者設置好。這樣對相同的測試進行不同的處理,恰恰說明了全面的基准測試 與小規模基准測試之間的不同。
最後一點,到此為止仍然不能說明你所測試的就是你所想的。這至多只能說明 ,對於最終的問題,這個測試是最有可能是正確的。
預熱方法的緩存
JIT會編譯你的代碼,這也是眾多影響基准測試的行為之一。Hotspot會頻繁地 檢查你的程序,尋找可以應用某些優化的機會。當找到機會後,它會要求 JIT編 譯器重新編譯問題中的某段代碼。此時它會應用一項技術,即當前棧替換(On Stack Replacement,OSR),從而切換到新代碼的執行上。執行OSR時會對測試產 生各種連鎖影響,包括要暫停線程的執行。當然,所有這樣的活動都會干擾到我 們的基准測試。這類干擾會使測試出現偏差。我們手頭上有兩款工具,可以幫助 我們標明代碼何時受到JIT的影響了。第一個當然是測試中出現的差異,第二個是 -XX:-PrintCompilation標記。幸運的是,如果不是所有的代碼在測試的早期就進 行JIT化處理,那麼我們可以將它視為另外一種啟動時的異常現象。我們需要做的 就是在開始測量前,先不斷地運行基准測試,直到所有代碼都已經完成了JIT化。 這個預熱的階段通常被稱為“預熱方法的緩存 ”。
大多數JVM會同時運行在解釋的與本機的模式中。這就是所謂的混合模式執行 。隨著時間的流逝,Hotspot和JIT會根據收集的信息將解釋型代碼轉化為本機代 碼。Hotspot為了決定應該使用哪種優化方案,它會抽樣一些調用和分支。一旦某 個方法達到了特定的阈值後,它會通知JIT生成本機代碼。這個阈值可以通過- XX:CompileThreshold標記來設定。例如,設定-XX:CompileThreshold=10000, Hotspot會在代碼被執行10,000次後將它編譯為本機代碼。堆管理
下一個需要考慮的是垃圾收集,或者更廣為人知的名字—堆管理。在任何應用 程序執行的過程中,都會定期地發生很多種內存管理活動。它們包括:重新劃分 棧空間大小、回收不再被使用的內存、將數據從一處移到另一處等等。所有這些 行為都導致JVM影響你的應用程序。我們面對的問題是:基准測試中是否需要將內 存維護或者垃圾回收的時間包括進來?問題的答案取決於你要解決的問題的種類 。在本例中,我只對獲取鎖的開銷感興趣,也就是說,我必須確保測試中不能包 含垃圾回收的時間。這一次,我們又能夠通過異常的現象來發現影響測試的因素 ,一旦出現這種問題,垃圾回收都是一個可能的懷疑對象。明確問題的最佳方式 是使用 -verbose:gc標志,開啟GC的日志功能。
在這個基准測試中,我做了大量的String、StringBuffer和StringBuilder操 作。在每次運行的過程中大概會創建4千萬個對象。對於這樣一種數量級的對象群 來說,垃圾回收毫無疑問會成為一個問題。我使用兩項技術來避免。第一,提高 堆空間的大小,防止在一個迭代中出現垃圾回收。為此,我利用了如下的命令行 :
>java -server -XX:+EliminateLocks -XX:+UseBiasedLocking - verbose:gc -XX:NewSize=1500m -XX:SurvivorRatio=200000 LockTest
然後,加入清單1的代碼,它為下一次迭代准備好堆空間。
System.gc();
Thread.sleep(1000);
清單1. 運行GC,然後進行短暫的休眠。
休眠的目的在於給垃圾回收器充分的時間,在釋放其他線程之後完成工作。有 一點需要注意:如果沒有CPU任何活動,某些處理器會降低時鐘頻率。因此,盡管 CPU時鐘會自旋等待,但引入睡眠的同時也會引入延遲。如果你的處理器支持這種 特性,你可能必須要深入到硬件並且關閉掉“節能”功能才行。
前面使用的標簽並不能阻止GC的運行。它只表示在每一次測試用例中只運行一 次GC。這一次的暫停非常小,它產生的開銷對最終結果的影響微乎其微。對於我 們這個測試來說,這已經足夠好了。
偏向鎖延遲
還有另外一種因素會對測試結果產生重要的影響。盡管大多數優化都會在測試 的早期發生,但是由於某些未知的原因,偏向鎖只發生在測試開始後的三到四秒 之後。我們又要重述一遍,異常行為再一次成為判斷是否存在問題的重要標准了 。-XX:+TraceBiasedLocking標志可以幫助我們追蹤這個問題。還可以延長預熱時 間來克服偏向鎖導致的延遲。
Hotspot提供的其他優化
Hotspot不會在完成一次優化後就停止對代碼的改動。相反,它會不斷地尋找 更多的機會,提供進一步的優化。對於鎖來說,由於很多優化行為違反了 Java存 儲模型中描述的規范,所以它們是被禁止的。然而,如果鎖已經被JIT化了,那麼 這些限制很快就會消失。在這個單線程化的基准測試中,Hotspot可以非常安全地 將鎖省略掉。這樣就會為其他的優化行為打開大門;比如方法內聯、提取循環不 變式以及死代碼的清除。
如果仔細思考下面的代碼,可以發現A和B都是不變的,我們應該把它抽取出來 放到循環外面,並引入第三個變量,這樣可以避免重復的計算,正如清單3中所示 的那樣。通常,這都是程序員的事情。但是Hotspot 可以識別出循環不變式並把 它們抽取到循環體外面。因此,我們可以把代碼寫得像清單2那樣,但是它執行時 其實更類似於清單3的樣子。 int A = 1;
int B = 2;
int sum = 0;
for (int i = 0; i < someThing; i++) sum += A + B;
清單2 循環中包含不變式
int A = 1;
int B = 2;
int sum = 0;
int invariant = A + B;
for (int i = 0; i < someThing; i++) sum += invariant;
清單3 不變式已抽取到循環之外
這些優化真的應該允許麼?還是我們應該做一些事情防止它的發生?這個有待 商榷。但至少,我們應該知道是否應用了這些優化。我們絕對要避免“死代碼消 除”這種優化的出現,否則它會徹底擾亂我們的測試!Hotspot能夠識別出我們沒 有使用concatBuffer和concatBuilder操作的結果。或者可以說,這些操作沒有邊 界效應。因此沒有任何理由執行這些代碼。一旦代碼被標識為已“死亡”,JIT就 會除去它。好在我的基准測試迷惑了Hotspot,因此它並沒有識別出這種優化,至 少目前還沒有。
如果由於鎖的存在而抑制了內聯,反之沒有鎖就可能出現內聯,那麼我們要確 保在測試結果中沒有包含額外的方法調用。現在可以用到的一種技術是引入一個 接口(清單4)來迷惑Hotspot。
public interfaceConcat {
String concatBuffer(String s1, String s2, String s3);
String concatBuilder(String s1, String s2, String s3);
public class LockTest implements Concat {
...}
清單4 使用接口防止方法內聯
防止內聯的另一種方法是使用命令行選項-XX:-Inline。我已經驗證,方法內 聯並沒有給基准測試的報告帶來任何不同。
執行棧輸出
最後,請看下面的輸出結果,它使用了下面的命令行標識。
>java -server -XX:+DoEscapeAnalysis -XX:+PrintCompilation -XX:+EliminateLocks -XX:+UseBiasedLocking -XX:+TraceBiasedLocking LockTest
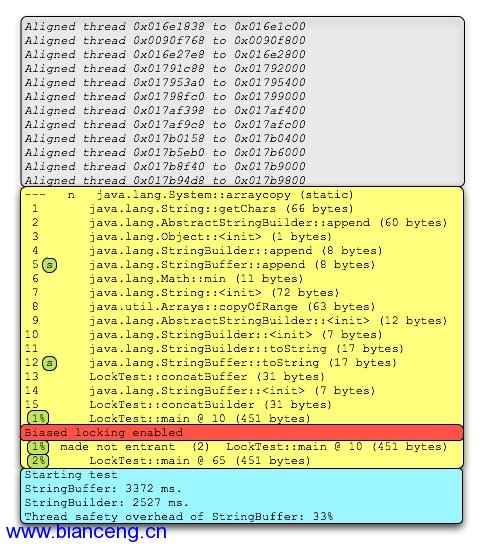
圖1 基准測試的執行棧輸出
JVM默認會啟動12個線程,包括:主線程、對象引用處理器、Finalize、 Attach監聽器等等。上圖中第一個灰色段顯示的是這些線程的對齊,它們可以使 用偏向鎖(注意所有地址都以00結尾)。你盡管忽略可以忽略它們。接下來的黃 色段包含了已編譯方法的信息。我們看一下第5行和12行,能夠發現它們都標記了 一個額外的“s”。表1的信息告訴我們這些方法都是同步的。包含了“%”的各行 已經使用了OSR。紅色的行是偏向鎖被激活的地方。最底下的藍綠色框是基准測試 開始計時的地方。從記錄基准測試開始時間的輸出中可以看到,所有編譯都已經 發生了。這說明前期的預熱階段足夠長了。如果你想了解日志輸出規范的更多細 節,可以參考這個頁面和這篇文章。

表1 編譯示例碼
單核系統下的結果
盡管我的多數同事都在使用Intel Core 2 Duo處理器,但還是有一小部分人使 用陳舊的單核機器。在這些陳舊的機器上,StringBuffer基准測試的結果和 StringBuilder實現的結果幾乎相同。由於產生這種不同可能是多種因素使然,因 此我需要另外一個測試,嘗試忽略盡可能多的可能性。最好的選擇是,在BIOS中 關閉Core 2 Duo中的一個核,然後重新運行基准測試。運行的結果如圖2所示。
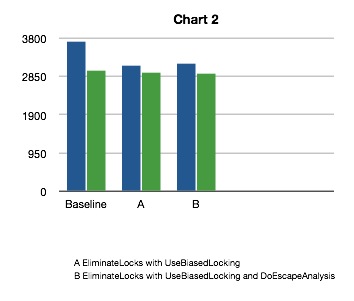
圖2 單核系統的性能
在多核環境下運行的時候,關閉了三種優化行為後獲得了一個基准值。這次, StringBuilder又保持了平穩的吞吐量。更有趣的是,盡管 StringBuffer比 StringBuilder要稍慢,但是在多核平台下,StringBuffer的性能更接近於 StringBuilder。從這個測試開始我們將一步步勾勒出基准測試的真實面目。
在多核的世界中,線程間共享數據的現實呈現出一種全新的面貌。所有現代的 CPU必須使用本地存儲的緩存,將獲取指令和數據的延遲降到最低。當我們使用鎖 的時候,會導致一次存儲關卡(Barrier)被插入到執行路徑中。存儲關卡像一個 信號,它通知CPU此時必須和其他所有的CPU進行協調,以此獲得最新的數值。為 了完成這個任務,CPU之間將要彼此通訊,從而導致每個處理器暫定當前正在運行 的應用程序線程。這個過程要花多少時間已經成了CPU存儲模型的指標之一。越是 保守的存儲模型,越是線程安全的,但是它們在協調各個處理器核的時候也要花 費更多的時間。在Core 2 Duo上,第二個核將固定的運行基准從3731ms提高到了 6574ms,或者說增加了176%。很明顯,Hotspot所提供的任何幫助都能明顯改進我 們的應用程序的總體性能。
逸出分析真的起作用了麼?
現在,還有一種優化很明顯會起作用,但是我們還沒有考慮,它就是鎖省略。 鎖省略是最近才實現的技術,而且它依賴於逸出分析,後者是一種Profiling 技 術,其自身也是剛剛才實現的。為了穩妥一些,各公司和組織都宣稱這些技術只 有在有限的幾種情況下才起作用。比如,在一個簡單的循環裡,對一個局部變量 執行遞增,且該操作被包含在一個同步塊內,由一個局部的鎖保護著。這種情況 下逸出分析是起作用的[http://blog.nirav.name/2007_02_01_archive.html]。 同時它在Mont Carlo的Scimark2基准測試中可以工作(參見 [http://math.nist.gov/scimark2/index.html])。
將逸出分析包含在測試中
那麼,為什麼逸出分析可以用於上述的情況中,卻不能用於我們的基准測試中 ?我曾經嘗試過將StringBuffer和 StringBuilder的部分方法進行內聯。我也修 改過代碼,希望可以強制逸出分析運行。我想看到鎖最終被忽略,而性能可以獲 得大幅提升。老實說,處理這個基准測試的過程既困惑,又讓人倍感挫折。我必 須無數次地在編輯器中使用ctrl-z,以便恢復到前面一個我認為逸出分析應該起 作用的版本,但是卻不知由於什麼原因,逸出分析卻突然不起作用了。有時,鎖 省略卻又會莫名其妙地出現。
最後,我認識到激活鎖省略似乎和被鎖對象的數據大小有關系。你運行清單2 的代碼就會看到這一點。正如你所看到的,無論運行多少次,結果都毫無區別, 這說明DoEscapeAnalysi沒有產生影響。
>java -server -XX:-DoEscapeAnalysis EATest
thread unsafe: 941 ms.
thread safe: 1960 ms.
Thread safety overhead: 208%
>java -server -XX:+DoEscapeAnalysis EATest
thread unsafe: 941 ms.
thread safe: 1966 ms.
Thread safety overhead: 208%
在下面的兩次運行中,我移除了ThreadSafeObject類中一個沒有被用過的域。 如你所見,當開啟了逸出分析,所有性能有了很大的提高。
>java -server -XX:-DoEscapeAnalysis EATest
thread unsafe: 934 ms.
thread safe: 1962 ms.
Thread safety overhead: 210%
>java -server -XX:+DoEscapeAnalysis EATest
thread unsafe: 933 ms.
thread safe: 1119 ms.
Thread safety overhead: 119%
逸出分析的數目在Windows和Linux上都能看到。然而在Mac OS X上,即使有額 外未被使用的變量也不會有任何影響,任何版本的基准測試的結果都是120%。這 讓我不由地相信在Mac OS X上有效性的范圍比其他系統更廣泛。我猜測這是由於 它的實現比較保守,根據不同條件(比如鎖對象數據大小和其他OS特定的特性) 及早地關掉了它。
結論
當我剛開始這個實驗,解釋應用各種鎖優化的Hotspot的有效性的時候,我估 計它將花費我幾個小時的時間,最終這會豐富我的blog的內容。但是就像其他的 基准測試一樣,對結果進行驗證和解釋的過程最終耗費了幾周的時間。同樣,我 也與很多專家進行合作,他們分別花費了大量時間檢查結果,並發表他們的見解 。即使在這些工作完成以後,仍然很難說哪些優化起作用了,而哪些沒有起作用 。盡管這篇文章引述了一組測試結果,但它們是特定我的硬件和系統的。大家可 以考慮是否能在自己的系統上看到相同類型的測試結果。另外,我最初認為這不 過是個小規模基准測試,但是後來它逐漸既要滿足我,也要滿足所有審核代碼的 人,而且去掉了Hotspot不必要的優化。總之,這個實驗的復雜度遠遠地超出了我 的預期。
如果你需要在多核機器上運行多線程的應用程序,並且關心性能,那麼很明顯 ,你需要不斷地更新所使用的JDK到最新版本。很多(但不是全部)前面的版本的 優化都可以在最新的版本中獲得兼容。你必須保證所有的線程優化都是激活的。 在JDK 6.0中,它們默認是激活的。但是在JDK 5.0中,你需要在命令行中顯式地 設置它們。如果你在多核機器上運行單線程的應用程序,就要禁用除第一個核以 外所有核的優化,這樣會使應用程序運行得更快。
在更低級的層面上,單核系統上鎖的開銷遠遠低於雙核處理器。不同核之間的 協調,比如存儲關卡語義,通過關掉一個核運行的測試結果看,很明顯會帶來系 統開銷。我們的確需要線程優化,以此降低這一開銷。幸運的是,鎖粗化和(尤 其是)偏向鎖對於基准測試的性能確實有明顯的影響。我也希望逸出分析與鎖省 略一起更能夠做到更好,產生更多的影響。這項技術會起作用,可只是在很少的 情況下。客觀地說,逸出分析仍然還處於它的初級階段,還需要大量的時間才能 變得成熟。
最後的結論是,最權威的基准測試是讓你的應用程序運行在自己的系統上。當 你的多線程應用的性能沒有符合你的期望的時候,這篇文章能夠為你提供了一些 思考問題的啟示。而這就是此文最大的價值所在。
關於Jeroen Borgers
Jeroen Borger是Xebia 的資深咨詢師。Xebia是一家國際IT咨詢與項目組織公 司,專注於企業級Java和敏捷開發。Jeroen幫助他的客戶攻克企業級Java系統的 性能問題,他同時還是Java性能調試課程的講師。他在從1996年開始就可以在不 同的Java項目中工作,擔任過開發者、架構師、團隊lead、質量負責人、顧問、 審核員、性能測試和調試員。他從2005年開始專注於性能問題。
鳴謝
沒有其他人的鼎力相助,是不會有這篇文章的。特別感謝下面的朋友:
Dr. Cliff Click,原Sun公司的Server VM主要架構師,現工作在Azul System ;他幫我分析,並提供了很多寶貴的資源。
Kirk Pepperdine,性能問題的權威,幫助我編輯文章。
David Dagastine,Sun JVM性能組的lead,他為我解釋了很多問題,並把我引 領到正確的方向。
我的很多Xebia的同事幫我進行了基准測試。
清單1.
public class LockTest {
private static final int MAX = 20000000; // 20 million
public static void main(String[] args) throws InterruptedException {
// warm up the method cache
for (int i = 0; i < MAX; i++) {
concatBuffer("Josh", "James", "Duke");
concatBuilder("Josh", "James", "Duke");
}
System.gc();
Thread.sleep(1000);
long start = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
concatBuffer("Josh", "James", "Duke");
}
long bufferCost = System.currentTimeMillis() - start;
System.out.println("StringBuffer: " + bufferCost + " ms.");
System.gc();
Thread.sleep(1000);
start = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
concatBuilder("Josh", "James", "Duke");
}
long builderCost = System.currentTimeMillis() - start;
System.out.println("StringBuilder: " + builderCost + " ms.");
System.out.println("Thread safety overhead of StringBuffer: "
+ ((bufferCost * 10000 / (builderCost * 100)) - 100) + "% \n");
}
public static String concatBuffer(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
public static String concatBuilder(String s1, String s2, String s3) {
StringBuilder sb = new StringBuilder();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
}
清單2.
public class EATest {
private static final int MAX = 200000000; // 200 million
public static final void main(String[] args) throws InterruptedException {
// warm up the method cache
sumThreadUnsafe();
sumThreadSafe();
sumThreadUnsafe();
sumThreadSafe();
System.out.println("Starting test");
long start;
start = System.currentTimeMillis();
sumThreadUnsafe();
long unsafeCost = System.currentTimeMillis() - start;
System.out.println(" thread unsafe: " + unsafeCost + " ms.");
start = System.currentTimeMillis();
sumThreadSafe();
long safeCost = System.currentTimeMillis() - start;
System.out.println(" thread safe: " + safeCost + " ms.");
System.out.println("Thread safety overhead: "
+ ((safeCost * 10000 / (unsafeCost * 100)) - 100) + "%\n");
}
public static int sumThreadSafe() {
String[] names = new String[] { "Josh", "James", "Duke", "B" };
ThreadSafeObject ts = new ThreadSafeObject();
int sum = 0;
for (int i = 0; i < MAX; i++) {
sum += ts.test(names[i % 4]);
}
return sum;
}
public static int sumThreadUnsafe() {
String[] names = new String[] { "Josh", "James", "Duke", "B" };
ThreadUnsafeObject tus = new ThreadUnsafeObject();
int sum = 0;
for (int i = 0; i < MAX; i++) {
sum += tus.test(names[i % 4]);
}
return sum;
}
}
final class ThreadUnsafeObject {
// private int index = 0;
private int count = 0;
private char[] value = new char[1];
public int test(String str) {
value[0] = str.charAt(0);
count = str.length();
return count;
}
}
final class ThreadSafeObject {
private int index = 0; // remove this line, or just the '= 0' and it will go faster!!!
private int count = 0;
private char[] value = new char[1];
public synchronized int test(String str) {
value[0] = str.charAt(0);
count = str.length();
return count;
}
}
查看英文原文:Do Java 6 threading optimizations actually work? - Part II。