介紹 — Java 6中的線程優化
Sun、IBM、BEA和其他公司在各自實現的Java 6虛擬機上都花費了大量的精力 優化鎖的管理和同步。諸如偏向鎖(biased locking)、鎖粗化(lock coarsening)、由逸出(escape)分析產生的鎖省略、自適應自旋鎖(adaptive spinning)這些特性,都是通過在應用程序線程之間更高效地共享數據,從而提 高並發效率。盡管這些特性都是成熟且有趣的,但是問題在於:它們的承諾真的 能實現麼?在這篇由兩部分組成的文章裡,我將逐一探究這些特性,並嘗試在單 一線程基准的協助下,回答關於性能的問題。
悲觀鎖模型
Java支持的鎖模型絕對是悲觀鎖(其實,大多數線程庫都是如此)。如果有兩 個或者更多線程使用數據時會彼此干擾,這種極小的風險也會強迫我們采用非常 嚴厲的手段防止這種情況的發生——使用鎖。然而研究表明,鎖很少被占用。也 就是說,一個訪問鎖的線程很少必須等待來獲取它。但是請求鎖的動作將會觸發 一系列的動作,這可能導致嚴重的系統開銷,這是不可避免的。
我們的確還有其他的選擇。舉例來說,考慮一下線程安全的StringBuffer的用 法。問問你自己:是否你曾經明知道它只能被一個線程安全地訪問,還是堅持使 用StringBuffer,為什麼不用StringBuilder代替呢?
知道大多數的鎖都不存在競爭,或者很少存在競爭的事實對我們作用並不大, 因為即使是兩個線程訪問相同數據的概率非常低,也會強迫我們使用鎖,通過同 步來保護被訪問的數據。“我們真的需要鎖麼?”這個問題只有在我們將鎖放在 運行時環境的上下文中觀察之後,才能最終給出答案。為了找到問題的答案,JVM 的開發者已經開始在HotSpot和JIT上進行了很多的實驗性的工作。現在,我們已 經從這些工作中獲得了自適應自旋鎖、偏向鎖和以及兩種方式的鎖消除(lock elimination)——鎖粗化和鎖省略(lock elision)。在我們開始進行基准測試 以前,先來花些時間回顧一下這些特性,這樣有助於理解它們是如何工作的。
逸出分析 — 簡析鎖省略(Escape analysis - lock elision explained)
逸出分析是對運行中的應用程序中的全部引用的范圍所做的分析。逸出分析是 HotSpot分析工作的一個組成部分。如果HotSpot(通過逸出分析)能夠判斷出指 向某個對象的多個引用被限制在局部空間內,並且所有這些引用都不能“逸出” 到這個空間以外的地方,那麼HotSpot會要求JIT進行一系列的運行時優化。其中 一種優化就是鎖省略(lock elision)。如果鎖的引用限制在局部空間中,說明 只有創建這個鎖的線程才會訪問該鎖。在這種條件下,同步塊中的值永遠不會存 在競爭。這意味這我們永遠不可能真的需要這把鎖,它可以被安全地忽略掉。考 慮下面的方法:
public String concatBuffer(String s1, String s2, String s3) {,
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
圖1. 使用局部的StringBuffer連接字符串
如果我們觀察變量sb,很快就會發現它僅僅被限制在concatBuffer方法內部了 。進一步說,到sb的所有引用永遠不會“逸出”到 concatBuffer方法之外,即聲 明它的那個方法。因此其他線程無法訪問當前線程的sb副本。根據我們剛介紹的 知識,我們知道用於保護sb的鎖可以忽略掉。
從表面上看,鎖省略似乎可以允許我們不必忍受同步帶來的負擔,就可以編寫 線程安全的代碼了,前提是在同步的確是多余的情況下。鎖省略是否真的能發揮 作用呢?這是我們在後面的基准測試中將要回答的問題。
簡析偏向鎖(Biased locking explained)
大多數鎖,在它們的生命周期中,從來不會被多於一個線程所訪問。即使在極 少數情況下,多個線程真的共享數據了,鎖也不會發生競爭。為了理解偏向鎖的 優勢,我們首先需要回顧一下如何獲取鎖(監視器)。
獲取鎖的過程分為兩部分。首先,你需要獲得一份契約.一旦你獲得了這份契 約,就可以自由地拿到鎖了。為了獲得這份契約,線程必須執行一個代價昂貴的 原子指令。釋放鎖同時就要釋放契約。根據我們的觀察,我們似乎需要對一些鎖 的訪問進行優化,比如線程執行的同步塊代碼在一個循環體中。優化的方法之一 就是將鎖粗化,以包含整個循環。這樣,線程只訪問一次鎖,而不必每次進入循 環時都進行訪問了。但是,這並非一個很好的解決方案,因為它可能會妨礙其他 線程合法的訪問。還有一個更合理的方案,即將鎖偏向給執行循環的線程。
將鎖偏向於一個線程,意味著該線程不需要釋放鎖的契約。因此,隨後獲取鎖 的時候可以不那麼昂貴。如果另一個線程在嘗試獲取鎖,那麼循環線程只需要釋 放契約就可以了。Java 6的HotSpot/JIT默認情況下實現了偏向鎖的優化。
簡析鎖粗化(Lock coarsening explained)
另一種線程優化方式是鎖粗化(或合並,merging)。當多個彼此靠近的同步 塊可以合並到一起,形成一個同步塊的時候,就會進行鎖粗化。該方法還有一種 變體,可以把多個同步方法合並為一個方法。如果所有方法都用一個鎖對象,就 可以嘗試這種方法。考慮圖2中的實例。
public static String concatToBuffer(StringBuffer sb, String s1, String s2, String s3) {
sb.append(s1);
sb.append(s2);
sb.append(s3);
return
}
圖2. 使用非局部的StringBuffer連接字符串
在這個例子中,StringBuffer的作用域是非局部的,可以被多個線程訪問。所 以逸出分析會判斷出StringBuffer的鎖不能安全地被忽略。如果鎖剛好只被一個 線程訪問,則可以使用偏向鎖。有趣的是,是否進行鎖粗化,與競爭鎖的線程數 量是無關的。在上面的例子中,鎖的實例會被請求四次:前三次是執行append方 法,最後一次是執行toString方法,緊接著前一個。首先要做的是將這種方法進 行內聯。然後我們只需執行一次獲取鎖的操作(為整個方法),而不必像以前一 樣獲取四次鎖了。
這種做法帶來的真正效果是我們獲得了一個更長的臨界區,它可能導致其他線 程受到拖延從而降低吞吐量。正因為這些原因,一個處於循環內部的鎖是不會被 粗化到包含整個循環體的。
線程掛起 vs. 自旋(Thread suspending versus spinning)
在一個線程等待另外一個線程釋放某個鎖的時候,它通常會被操作系統掛起。 操作在掛起一個線程的時候需要將它換出CPU,而通常此時線程的時間片還沒有使 用完。當擁有鎖的線程離開臨界區的時候,掛起的線程需要被重新喚醒,然後重 新被調用,並交換上下文,回到CPU調度中。所有這些動作都會給JVM、OS和硬件 帶來更大的壓力。
在這個例子中,如果注意到下面的事實會很有幫助:鎖通常只會被占有很短的 一段時間。這就是說,如果能夠等上一會兒,我們可以避免掛起線程的開銷。為 了讓線程等待,我們只需將線程執行一個忙循環(自旋)。這項技術就是所謂的 自旋鎖。
當鎖被占有的時間很短時,自旋鎖的效果非常好。另一方面,如果鎖被占有很 長時間,那麼自旋的線程只會消耗CPU而不做任何有用的工作,因此帶來浪費。自 從JDK 1.4.2中引入自旋鎖以來,自旋鎖被分為兩個階段,自旋十個循環(默認值 ),然後掛起線程。
自適應自旋鎖(Adaptive spinning)
JDK 1.6中引入了自適應自旋鎖。自適應意味著自旋的時間不再固定了,而是 取決於一個基於前一次在同一個鎖上的自旋時間以及鎖的擁有者的狀態。如果在 同一個鎖對象上,自旋剛剛成功過,並且持有鎖的線程正在運行中,那麼自旋很 有可能再次成功。進而它將被應用於相對更長的時間,比如100個循環。另一方面 ,如果自旋很少發生過,它將被遺棄,避免浪費任何CPU周期。
StringBuffer vs. StringBuilder的基准測試
但是要想設計出一種方法來判斷這些巧妙的優化方法到底多有效,這條路並不 平坦。首要的問題就是如何設計基准測試。為了找到問題的答案,我決定去看看 人們通常在代碼中運用了哪些常見的技巧。我首先想到的是一個非常古老的問題 :使用StringBuffer代替String可以減少多少開銷?
一個類似的建議是,如果你希望字符串是可變的,就應該使用StringBuffer。 這個建議的緣由是非常明確的。String是不可變的,但如果我們的工作需要字符 串有很多變化,StringBuffer將是一個開銷較低的選擇。有趣的是,在遇到JDK 1.5中的StringBuilder(它是StringBuffer的非同步版本)後,這條建議就不靈 了。由於StringBuilder與 StringBuffer之間唯一的不同在於同步性,這似乎說 明,測量兩者之間性能差異的基准測試必須關注在同步的開銷上。我們的探索從 第一個問題開始,非競爭鎖的開銷如何?
這個基准測試的關鍵(如清單1所示)在於將大量的字符串拼接在一起。底層 緩沖的初始容量足夠大,可以包含三個待連接的字符串。這樣我們可以將臨界區 內的工作最小化,進而重點測量同步的開銷。
基准測試的結果
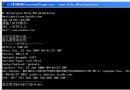
下圖是測試結果,包括EliminateLocks、UseBiasedLocking和 DoEscapeAnalysis的不同組合。
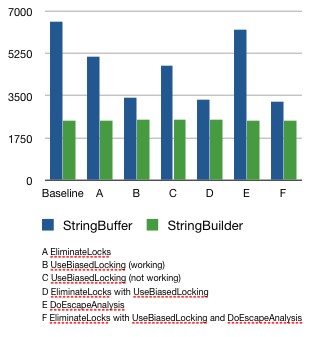
圖3. 基准測試的結果
關於結果的討論
之所以使用非同步的StringBuilder,是為了提供一個測量性能的基線。我也 想了解一下各種優化是否真的能夠影響StringBuilder的性能。正如我們所看到的 ,StringBuilder的性能可以保持在一個不變的吞吐量水平上。因為這些技術的目 標在於鎖的優化,因此這個結果符合預期。在性能測試的另一欄中我們也可以看 到,使用沒有任何優化的同步的StringBuffer,其運行效率比StringBuilder大概 要慢三倍。
仔細觀察圖3的結果,我們可以注意到從左到右性能有一定的提高,這 可以歸功於EliminateLocks。不過,這些性能的提升比起偏向鎖來說又顯得有些 蒼白。事實上,除了C列以外,每次運行時如果開啟偏向鎖最終都會提供大致相同 的性能提升。但是,C列是怎麼回事呢?
在處理最初的數據的過程中,我注意到有一項測試在六個測試中要花費 格外長的時間。由於結果的異常相當明顯,因此基准測試似乎在報告兩個完全不 同的優化行為。經過一番考慮,我決定同時展示出高值和低值(B列和C列)。由 於沒有更深入的研究,我只能猜測這裡應用了一種以上的優化(很可能是兩種) ,並且存在一些競爭條件,偏向鎖大多時候會取勝,但不非總能取勝。如果另一 種優化占優了,那麼偏向鎖的效果要麼被抑制,要麼就被延遲了。
這種奇怪的現象是逸出分析導致的。明確了這個基准測試的單線程化的本質後 ,我期待著逸出分析會消除鎖,從而將StringBuffer的性能提到了與 StringBuilder相同的水平。但是很明顯,這並沒有發生。還有另外一個問題;在 我的機器上,每一次運行的時間片分配都不盡相同。更為復雜的是,我的幾位同 事在他們的機器上運行這些測試,得到的結果更混亂了。在有些時候,這些優化 並沒有將程序提速那麼多。
前期的結論
盡管圖3列出的結果比我所期望的要少,但確實可以從中看出各種優化能夠除 去鎖產生的大部分開銷。但是,我的同事在運行這些測試時產生了不同的結果, 這似乎對測試結果的真實性提出了挑戰。這個基准測試真的測量鎖的開銷了麼? 我們的結論成熟麼?或者還有沒有其他的情況?在本文的第二部分裡,我們將會 深入研究這個基准測試,力爭回答這些問題。在這個過程中,我們會發現獲取結 果並不困難,困難的是判斷出這些結果是否可以回答前面提出的問題。
public class LockTest {
private static final int MAX = 20000000; // 20 million
public static void main(String[] args) throws InterruptedException {
// warm up the method cache
for (int i = 0; i < MAX; i++) {
concatBuffer("Josh", "James", "Duke");
concatBuilder("Josh", "James", "Duke");
}
System.gc();
Thread.sleep(1000);
System.out.println("Starting test");
long start = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
concatBuffer("Josh", "James", "Duke");
}
long bufferCost = System.currentTimeMillis() - start;
System.out.println("StringBuffer: " + bufferCost + " ms.");
System.gc();
Thread.sleep(1000);
start = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
concatBuilder("Josh", "James", "Duke");
}
long builderCost = System.currentTimeMillis() - start;
System.out.println("StringBuilder: " + builderCost + " ms.");
System.out.println("Thread safety overhead of StringBuffer: "
+ ((bufferCost * 10000 / (builderCost * 100)) - 100) + "%\n");
}
public static String concatBuffer(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
public static String concatBuilder(String s1, String s2, String s3) {
StringBuilder sb = new StringBuilder();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
}
運行基准測試
我運行這個測試的環境是:32位的Windows Vista筆記本電腦,配有Intel Core 2 Duo,使用Java 1.6.0_04。請注意,所有的優化都是在Server VM上實現 的。但這在我的平台上不是默認的VM,它甚至不能在JRE中使用,只能在JDK中使 用。為了確保我使用的是Server VM,我需要在命令行上打開-server選項。其他 的選項包括:
-XX:+DoEscapeAnalysis, off by default
-XX:+UseBiasedLocking, on by default
-XX:+EliminateLocks, on by default
編譯源代碼,運行下面的命令,可以啟動測試:
java-server -XX:+DoEscapeAnalysis LockTest關於Jeroen Borgers
Jeroen Borger是Xebia的資深咨詢師。Xebia是一家國際IT咨詢與項目組織公 司,專注於企業級Java和敏捷開發。Jeroen幫助他的客戶攻克企業級Java系統的 性能問題,他同時還是Java性能調試課程的講師。他在從1996年開始就可以在不 同的Java項目中工作,擔任過開發者、架構師、團隊lead、質量負責人、顧問、 審核員、性能測試和調試員。他從2005年開始專注於性能問題。
鳴謝
沒有其他人的鼎力相助,是不會有這篇文章的。特別感謝下面的朋友:
Dr. Cliff Click,原Sun公司的Server VM主要架構師,現工作在Azul System ;他幫我分析,並提供了很多寶貴的資源。
Kirk Pepperdine,性能問題的權威,幫助我編輯文章。
David Dagastine,Sun JVM性能組的lead,他為我解釋了很多問題,並把我引 領到正確的方向。
我的很多Xebia的同事幫我進行了基准測試;