這裡有2種完全不同的方法來設計JAVA企業程序,其中一種選擇是采用標准EJB2實現途徑(approach)。我更願意稱這種方法為重量級實現途徑,當你使用重量級實現途徑時你需要用會話beans(session bean)和消息驅動 beans(message-driven bean)去實現業務邏輯。你也可以使用DAOs(data access object)或者實體bean去訪問業務邏輯
另外一種選擇是使用POJOs 和輕量級構架,這種方式我稱為POJO實現途徑。當使用POJOs實現途徑時,你的業務邏輯完全由POJO來實現。你可以使用持久型構架又叫做對象/關系映射構架(a.k.a=also know as )例如Hibernate 或者 JDO來訪問數據庫,再用Spring AOP(面向層面編程)來提供企業服務,比如事務管理和安全。
EJB3由於融合了POJOs和其他一些輕量級概念,所以對兩者(指輕量級和重考鍛揪叮┑那�分不是很清楚。舉個例子,POJO中的實體bean既可以再EJB容器內運行,也可以再EJB容器外運行,然而POJOs中的會話bean和消息驅動bean仍然有重量級的行為,因為他們只能在EJB容器內部運行。所以,顯而易見的,EJB3既是重量級的又有POJO的特性。EJB3中的實體bean是輕量級實現途徑中的一部分。
在開發過程中,首要的是從各種各樣的設計中選擇到底采用重量級實現途徑還是采用POJO實現途徑。決策可以影響程序的幾個方面,包括業務邏輯結構和數據訪問機制。為了幫助從兩種實現途徑中擇其一,來看這張典型的企業應用程序結構圖,結構圖在圖示1中,而且在設計過程中就必須判斷到底使用那種策略。
Figure 1. A typical application architecture and the key business logic and database access design decisions.
程序由網絡基本表示層、業務層、持久層組成。網絡基本表示層負責HTTP請求和為一般的浏覽器客戶端、XML和其他的胖體客戶端生成HTML,比如為Ajax基本客戶端生成HTML.業務層被表示層調用,用來實現程序業務邏輯。持久層被業務邏輯層用來訪問外部數據源,比如數據庫和其他程序。
表示層的設計不在本篇文章討論之內,來看圖表的其他部分,我們需要決定業務層結構的接口,這個接口是提供給表示層以及其他客戶端的。而且還需要決定怎樣訪問能供多個程序訪問的數據庫。我們還必須決定如何處理短期事務處理事務和長期事務處理事務的並發問題。這些加起來一共有5種決策。每種決策都是要設計者來制定,為了能看懂演示圖(big picture)要求每個開發者也都了解這些策略。
這些決策直接決定程序業務和表示層設計的特點。當然,還要決定一些其他很重要的決策。比如業務處理(transactions)、安全問題、緩存問題以及如何整合程序,但是關於這些問題通常在其他文獻中討論在圖表1中顯示的五種決策,每種決策都有多種選擇。每種選擇根據它要解決的實際問題都有相應的優缺點。後續章節中,你會發現每種決策針對一個或多個領域時,在功能性、易開發性、可維護性和可用性方面有不同的平衡點。盡管我是POJO實現途徑的超級大FANS,但是仍然需要了解其優缺點,以便於為你的程序做最好的選擇下面我們來了解一下每種決策的大綱和其選項。
決策1:組織業務邏輯
現在,很多的注意力都集中在某項技術的優點和缺點,盡管這很重要,但是在本質上你需要了解如何建構你的業務邏輯。如果不考慮如何組織就去寫代碼是非常簡單的。例如,為一個會話BEAN添加代碼要比在域模式(domain model.: An object model of the domain that incorporates both behavior and data.)中判斷應該添加那種新特性要簡單的多。理論上你仍然需要刻意的為你的軟件設計最合適的業務邏輯。畢竟我相信你有過修改別人垃圾結構代碼的慘痛經驗
關鍵的決策是:到底應該用面向對象的實現途徑還是面向過程的實現途徑來實現你的程序。這個不是關於技術的決策,但是你技術上的決策可以潛在的約束你的業務邏輯的組織結構。采用EJB2技術,有利於面向過程設計,然而POJOs和輕量級構架可以讓你為特殊的程序選擇最好的實現途徑
采用過程式設計
雖然我是一個面向對象實現途徑(指前文的使用POJO和LIGHTFRAMEWORK)的倡導者,但是有些情況下面向對象實現途徑有些大材小用,比如你只想實現一個非常簡單的業務邏輯。而且,有時候,面向對象實現途徑不太可行-―比如,你沒有持久層構架來將你的對象映射到數據庫中,在這種情況下,更好的方法是編寫面向過程的代碼,而且采用Martin Fowler稱作事務腳本(Transaction Script)的設計模式,要比采用面向對象實現途徑設計要好,因為你只需要寫一個方法來調用事務處理腳本去處理表示層的請求。
采種這種實現途徑的一個很重要的特點是,用於實現某種行為的類和數據存儲區是分開的。在EJB2的應用程序中,這種方式的業務邏輯和圖表2中的設計是非常相似的。這種設計的核心全都集中在EJB或者POJO的行為上,因為他們實現了事務腳本,並且還操作那些 “啞”對象數據(因為他們只擁有很少的行為,大部分都是數據)。因為大部分的行為都集中在少量的大型類上,所以代碼會變的很難理解與維護。
Figure 2. The structure of a procedural design: large transaction script classes and many small data objects
這種設計具有高面向過程的特性,而且基本不依靠面向對象語言的特性。如果你曾經使用過C或者其他非面向對象語言的話,你應該用過這種設計模式。如果這種模式很適合你的設計的話,用這種模式設計也是一種不錯的選擇。
這種直觀的過程式開發途徑,非常的誘人,因為你只需要寫代碼就好了,不用考慮如何組織你的類文件。但問題是,如果你的業務邏輯非常的復雜,那麼你的代碼會變的噩夢般的難以維護。所以,除非你要寫的程序非常的簡單,否則你應該用面向對象設計你的程序,而不要受面向過程的代碼的誘惑。
采用面向對象設計
在面向對象設計中,業務邏輯是由對象模型構成的,對象模型是由許多小類組成的關系網。這些類直接體現的是問題域的解決方法,如圖3所示,在這種模式中,有些類只有數據,有些類只有行為,但是大多數的則兩者都有,這是優秀的類設計的一種特點。
Figure 3. The structure of a domain model: small classes that have state and behavior
面向對象設計有許多的好處,包括可以提高可維護性和可延展性。你可以用EJB2的實體bean來實現一個簡單的對象模型。但是如果像要獲得更多的好處的話,必須要使用POJOs技術和輕量級持久層構架――比如Hibernate和JDO技術。POJO可以讓你開發豐富的模型,這些模型可以擁有繼承和回調等特點。而輕量級持久層構架可以讓你很簡單的從對象模型映射到數據庫。
對象模型的另外一個名字是域模型,Fowler稱這種由面向對象途徑來開發的業務邏輯叫做域模型設計模式。(就是類的設計是直接用來解決問題的,則這種設計模式叫做域模型設計模式)
表模型設計模式
我曾經一直用域模型和事務處理腳本模型設計應用程序。但是有一次我聽說JAVA企業應用程序可以用第三種途徑來實現,這種途徑就是Fowler所說的表模型設計模式。這種模式比事務處理腳本模式更加的結構化,因為它為數據庫中的每個表都寫了一個類,而這個類中實現了所有對這個表的操作代碼,這個類就是表模型類。(我的解釋就是為每個表專門寫個類,對表的所有操作,全都由這個類中的方法實現,相當於用一個類模擬的數據庫中的表)。和事務處理腳本模式相比,它將數據和行為分別封裝到了不同的類中,因為表模型類的實例相當於真實數據庫中的數據,這當然要比單獨的一條記錄要好的多。最後,可維護性成了問題,然而表模型設計模式還是有一些好處的。
決策2:封裝業務邏輯
前面幾章,我沒有提及如何組織業務邏輯。你必須決定業務邏輯有什麼樣的接口。業務邏輯的接口由一些數據和方法組成,這些數據和方法由表示層來調用。在設計接口時重點需要考慮的是:應該封裝哪些業務邏輯的操作,而哪些操作不應該顯示給表示層。封裝接口可以提高程序的可維護性,因為通過隱藏業務邏輯的操作細節,可以實現修改業務邏輯而不影響表示層。缺點是,你必須為封裝業務邏輯而特意的寫很多的代碼。
你還需要考慮其他重要的問題,比如如何處理事務處理,安全,和遠程調用問題。通常這些也是業務邏輯接口要負責的問題。為了保證數據的連貫性,業務層的接口必須保證每個事務處理中的調用都能執行。同樣,也要驗證調用者是否有權限調用業務方法。業務層接口還要負責處理一些遠程客戶端的問題。
來考慮一下選項。
EJB session faç;ade
經典的J2EE解決方案是:用EJB來封裝業務邏輯-基本的session facade.EJB容器提供事務處理管理,安全,分布式事務處理和遠程訪問。Facade方式可以通過封裝業務邏輯來提高程序可維護性。粗糙型(Coarse-grained) API通過減少表示層對業務層的訪問次數,而提高性能(因為它將對各個業務流程的處理再封裝了一次,所以對底層的業務流程來說,它的API是比較粗糙的,這裡也許翻譯的不好。請大家見諒)。因為減少調用的次數,可以減少對數據庫事務處理的次數,還可以提高對象在緩沖區的機會。如果表示層通過遠程訪問業務層,則這種API還可以減少網絡負擔。圖表4給出了一個EJB-based session facade的例子。
Figure 4. Encapsulating the business logic with an EJB session faç;ade
在這種設計模式中,表示層也許是通過遠程來調用facade(相當於session的一個高級接口),EJB容器從facade中得到這個調用,並驗證調用者的權限,然後開始一個業務處理。這個時候facade調用底層的業務對象,而這些業務對象負責實現具體的業務邏輯。等Facade返回後,EJB容器提交業務處理或者讓該業務處理循環等待。
不幸的是,使用EJB session facade有一些嚴重的缺點。比如,EJB的會話bean只能在EJB容器中運行,這樣就托慢了開發和測試周期。另外,如果用EJB2,則用來向表示層傳輸數據的數據傳輸對象的開發和維護就會變的很枯燥而且曠日持久。
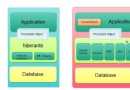
POJO facade
對於許多程序來說,更好的實現途徑是用POJO facade和AOP協作。比如負責管理事務處理、表示層的連接和安全問題的Spring 構架。POJO facade對業務層的封裝風格和EJB facade很相似,通常也可以用一樣的公共方法。而POJO和EJB關鍵區別是用POJO代替了EJB,用AOP提供的服務(例如業務處理管理和安全機制)替代了EJB容器。表5中,顯示了用POJO facade的例子。
Figure 5. Encapsulating the business logic with a POJO faç;ade
表示層調用POJO facade, POJO facade 調用業務對象。和EJB容器截獲EJB facade方式一樣,AOP通過“攔截機”來截獲POJO facade,並驗證調用者的權限,然後開始提交業務處理或讓該業務循環等待。
通過在應用程序服務器外部開發和調試業務邏輯,對POJO facade的開發可以變的很簡單,同時還可以獲得許多EJB中會話Bean的好處,比如聲明事務處理和安全。關鍵是,你可以少寫點代碼。你可以避免寫數據傳輸對象類,因為POJO facade可以將對象域直接反饋給表示層;你可以使用依賴注射的方式來將應用程序組裝起來,而不用在為JNDI寫查找代碼了。
然而,有些時候不能那用POJO facade,比如它不能參與到遠程客戶端建立的分布式事務處理。
暴露模型域模式
使用facade的一個缺點是你必須寫額外的代碼,而且負責將對象域返回給表示層的代碼很容易出錯。如果表示層設法調用某個對象,而業務層卻沒有提供該對象,也會增加runtime error出現的機會。如果你用JDO , Hibernate或者EJB3,則可以避免這種問題,方法是:將模型域(session區域)暴露給表示層,再將相應的對象域(存儲對象的區域)返回給表示層,根據表示層在對象域之間的操作關系,持久層來導入相應的對象。(也就是把session區域給表示層,然後分析它需要的對象,再讓持久層去加載這些對象)這就是所謂的lazy loading 技術。圖表6中顯示了表示層自由的訪問對象域的設計圖。
Figure 6. Using an exposed domain model
在圖表6的設計中,表示層不通過facade而直接調用域對象,Spring AOP仍然提供服務,例如事務處理管理和安全。
用這種實現途徑的一個重要的好處是,業務層不需要知道哪些對象需要調用,也不用知道那些需要返回給表示層。盡管這挺起來很簡單,但是你會發現一些缺點。這會增加表示層的復雜度,因為你必須處理對數據庫的連接。而且在基於Web的應用程序中,事務處理管理也要非常小心,因為在表示層將數據反饋給浏覽器之前,事務處理的數據必須保持正確。
決策3:訪問數據庫
無論你怎樣對業務邏輯怎樣的組織和封裝,最終你還是要從數據庫中取數據出來。在經典的J2EE應用程序中,你有2個選擇:JDBC――這個需要很多的底層代碼;或者實體Bean――這個用起來非常困難,而且缺少重要特征。相比來說,使用輕量級構架令人高興的事情之一就是:你有一些新的而且更有力的方法去訪問數據庫,而且這種方法可以顯著的減少訪問數據庫的代碼。讓咱們來進一步研究
直接用JDBC會有什麼問題
最近突然出現了對象/關系 映射構架(比如JDO和Hibernate) 和SQL映射構架(比如iBATIS)這些不是憑空出現的。相反,他們是在JAVA 聯盟在JDBC屢造挫折之後才出現的。為了了解新構架出現的原因,這裡咱們回顧一下直接使用JDBC會出現的問題。在許多程序中直接使用JDBC不是一個好的選擇,主要有以下三個原因:。開發和維護SQL非常的困難而且耗費時間――一些開發者發現要寫龐大而且復雜的SQL語句非常的困難。反映數據庫變化的SQL語句會變得非常耗時。你必須小心的考慮犧牲可維護性是否值得。。用SQL會使移植性變的很差――因為需要數據庫的特殊SQL語句。如果一個程序和多個數據庫有關系,那麼你就要寫多個版本的SQL語句,這使得可維護性變變成噩夢。。直接寫JDBC代碼要會非常耗時,而且容易出錯。你必須寫很多的樣板代碼去獲得連接,創建和初始化適當的聲明,還要用精確的聲明去清理連接。而且你還要寫代碼去將JAVA 對象映射到SQL聲明。由於要無奈的去寫,JDBC代碼很容易出錯。
如果你的程序必須直接運行SQL語句的話,那前面兩個問題是無法避免的。有時候為了獲得好的性能,必須要全力的寫SQL語句,包括供應商提供的那些特殊東西。由於許多業務上的原因,持久層可能會產生混亂的SQL語句,為了防止這種情況,DBA可能要求你的程序來完全控制SQL語句的執行。通常,團隊買進的關系型數據庫過於龐大,以至於應用程序工作時會出現一些和數據庫有關的瑣碎事務。根據“iBATIS in Action”的作者說這裡會有一種情況出現:“數據庫或者SQL語句本身存在的時間比程序代碼存在的時間還要長,或者同一段SQL語句或數據庫有多個程序的版本。有些情況下,程序已經用另外一種語言重寫了,但是SQL語句和數據庫卻沒有太大的改變。” 如果直接使用SQL弄的你筋疲力盡,那麼很幸運,這裡有一種直接執行SQL語句的構架,它可比用JDBC要容易多了。當然了,這就是iBATIS.
使用iBATIS
我開發過的所有企業JAVA應用程序,都是直接執行SQL語句的。早期的程序是執行特定的SQL語句的,後來是用持久層構架再用少量的SQL語句構成的。一開始我直接用JDBC來執行SQL語句,但是後來,我經常寫一些小的構架去完成JDBC中那些比較無聊的部分。我也用過一段Spring的JDBC類,這些類除去了JDBC中的許多樣板代碼。但是無論是我自己寫的構架還是使用Spring的類,在Java類映射到SQL語句的時候都會存在問題,這就是我為什麼那麼高興的加入iTATIS 那邊的原因了。
iBATIS 不僅將應用程序完全的與“數據庫連接”、具體的SQL語句隔絕開來,更實現了通過XML描述文檔來將JavaBean 映射到SQL語句。它用Java bean 內省機制來將“道具bean(bean properties)”映射為相應的數據庫語句占位符,而且它可以將ResultSet後的結果構造為bean.它還可以通過數據庫生成主鍵,自動加載相關的對象、實現緩存和lazy loading.這樣,iBATIS 就除去了許多執行SQL語句帶來的苦差。通過編輯XML描述文檔和調用少量的iBATIS的API,代替了寫大量的JDBC底層代碼。
使用持久層框架
當然,iBATIS不能實現高層開發和維護SQL語句,而且缺乏可移植性。為了避免這類問題,你需要用到持久層框架。持久層框架可以將對象域映射到數據庫中。它提供了創建,查找,刪除對象的API函數。當程序要控制對象時它可以自動的加載相應的對象,還可以在事務處理結束時自動更新數據庫。持久層框架通過對象/關系映射機制可以自動的生成SQL語句,對象/關系映射機制用XML文檔定義了怎樣將類映射為表,怎樣將數據映射為列(column)和關系是怎樣被映射為外鍵與連接表的。
在持久層構架上EJB也有它的短處:實體bean.EJB2的實體bean有很多的不足,而且開發和測試它會變得非常的枯燥。最後,很少用EJB2的實體bean了。在EJB3中會說明那些問題。
兩種最有流行的輕量級持久層構架是JDO和Hibernate,前者是Sun的標准框架,後者是開源工程。兩種框架都可以為POJO類提供持久層事務處理。你可以用POJO類來開發和測試你的業務邏輯,而不用擔心持久層的問題,這個時候它會將類映射到數據庫中的schema.另外,他們兩個都可以在服務器程序外部或者內部,這樣可以進一步降低開發難度。用Hibernate和JDO來進行開發比用老的EJB2的實體bean要舒服的多。
除了要決定怎樣訪問數據庫外,還要決定如何處理數據庫的並行處理問題。下面來看一下,為什麼並行處理問題那麼重要,同時看一下可實現的選項
決策4:處理數據庫事務處理的並行問題
差不多所有的企業應用程序都需要多用戶和多個後台進程並行的更新數據庫。2個數據庫 處理事務同時訪問同時訪問同一個數據是很正常的,但是這種情況很可能引起數據庫中的數據不一致或者引起應用程序的不正常。由於大部分的應用程序都需要處理多個處理事務並行訪問同一個數據,則它可以影響到業務和持久層的設計。
無論你是使用EJB還是輕量級構架,你的程序必須可以並行訪問共享數據。EJB2要求使用供應商提供的特殊擴充接口來實現並行,然而與此不同的是,JDO和Hibernate可以直接支持大部分並行機制。更重要的是,使用JDO和Hibernate不僅只配置簡單,而且只需要少量的代碼就可以實現了。
在這樣主要介紹幾種“並行更新數據庫處理事務”的選項的概要,這些事務處理和用戶的輸入無關。下一章,我主要介紹一下如何在應用程序級長時間的並行更新數據庫處理事務,這種處理事務會與用戶輸入有關,而且是由一系列的數據庫事務處理組成的。
獨立數據庫事務
有時候對共享數據的並行訪問可以簡單的依靠數據庫本身來實現,數據庫可以設置為執行孤立的數據――這只是對數據庫而言。如果你對這種概念不熟悉也不要擔心,你只要記住:如果應用程序使用完全的孤立事務方式,那麼同時執行2個事務的結果和一個接一個的執行是一樣的。(也就是說,如果你用孤立事務的方式來訪問數據庫的話,你同時執行2個事務,就會變成一個接一個的串行執行了。)
這種方法也許聽起來非常的簡單,但問題是這種處理方式有時候會降低性能,因為如何實現對事務的孤立是由數據庫來決定的。為了這個原因,許多應用程序都避免使用它,而采用optimistic或者pessimistic 所鎖,這會在下面講到。
開放式鎖定
並行更新數據的一種途徑是用開放式鎖定。開放式鎖定工作原理是通過應用程序來檢查數據是否被更新(被其他事務修改造成的)而實現的。一種更普通的實現開放式鎖定的方法是在每個表中添加一個“版本列”(version column),對每個表而言,程序每次改變其中一行的時候都會更新這個“版本列”。每個UPDATE語句中的WHERE語句會根據上次查詢的結果判斷這個版本號是不是被更改了。在事務訪問數據庫中的數據時,程序中可以用PreparedStatement.executeUpadte()這個函數的返回值來檢查行的個數,從而判斷是否要繼續執行UPDATE語句。如果數據中的行已經被其他的事務更新或者刪除了,那麼程序會讓該事務從新訪問數據庫。
用開放式鎖定機制來鎖定那些直接執行SQL語句的應用程序是非常簡單的。但是,用持久層構架(比如JDO和Hibernate)實現更容易,因為他們已經提供了開放式鎖定機制――在配置選項中。一旦在配置選項中,選中了這種方式,持久層構架會自動的生成SQL的UPDATE語句來完成版本檢查的任務。開放式鎖定的名字來源於一種假設的情況,在這種情況下:並發更新的機會非常少,而且程序只能檢測、覆蓋這些數據而不能防止這種事情的發生。另外一種可選的途徑是用保守式鎖定,使用他的假設條件是:並發更新肯定會發生,而且必須被禁止。
保守式鎖定
對於開放式鎖定來說,另外一種途徑是使用保守式鎖定。當一個事務讀取某些行的數據時,他會對這些數據加鎖,這樣就防止其他的事務訪問這些數據了。具體的實現是需要數據庫支持的,然而不幸的是,不是所有的數據庫都支持保守式鎖定。如果你的數據庫支持話,那麼你的應用程序直接執行SQL語句來實現保守式鎖定將非常容易。但是,可能你已經猜到了,在程序中用JDO或者Hibernate來實現保守式鎖定更容易,JDO以配置選項的方式提供了保守式鎖定,而Hibernage提供了簡單的API實現鎖定對象。
除了可以處理單個數據庫事務並行問題,常常你還需要處理多數據庫事務的並行問題。
決策5:在長事務下處理並發訪問
獨立事務、開放式鎖定、和保守式鎖定只能用在單個數據庫事務上的,然而,許多的程序需要 長時間的 在多個數據庫事務之間 讀取或者更新 共享數據。比如,有一種情況描述的是 怎樣實現 用戶編輯命令,這和很多的進程有關,這些進程可能會運行 很長的時間,而且它由 多個數據庫事務組成。因為數據可能會被 一個數據庫事務 讀取,而又被 另外一個數據庫事務 修改了,那麼程序必須對 共享數據的並發訪問 進行不同的處理。這樣就必須使用 開放式鎖定設計模式或 者保守是鎖定設計模式,關於這兩種模式會在Fowler的 Patterns of Enterprise Application Architecutre中詳細介紹。
開放式脫機鎖定
模式一種選擇是開放式鎖定機制的擴展,它會從第一次讀取數據開始,在編輯進程執行後檢查數據是否已經被修改了。例如,你可以在數據庫的共享數據的表中使用版本號來實現。在編輯進程開始的時候,程序將版本號存儲到會話狀態中,然後每次用戶要存儲數據時,應用程序都要進行檢查,保證數據庫中的版本號和會話狀態中的版本號一致。
因為開放式脫機鎖定模式只有在用戶進行保存修改過的數據時才可以檢測,所以它只有在不成為客戶的累贅的時候,才可以很好的運行。但如果情況是:客戶必須要撤銷幾個操作的話,那麼就會因為這種鎖定模式而非常苦惱,那麼更好的一種選擇是用保守式脫機鎖定。
保守式脫機鎖定
模式在編輯進程開始時,保守式脫機鎖定方式通過鎖定 共享數據,來解決 多個數據庫事務 同時更新共享數據的問題,這樣,這個編輯進程就可以防止 其他的用戶來修改數據了。這種方式和保守式鎖定機制一開始描述的很類似,但它是靠程序來實現的,而不是數據庫。因為同一時間內,只有有權利編輯共享數據的用戶,才有權利去保存這些修改。