簡介
數據庫的選型應該是會為您帶來商業優勢的戰略性決策。一旦做出決策,您 就必須充分利用該數據庫服務器來實現這一優勢。本文簡要地介紹了 Java™ 2 Enterprise Environment(J2EE)環境,並討論了 J2EE 開發中使用的面向對象方法(分析 、設計、實現),以及一些與對象持久性相關的問題,因為對象持久性與對象-關系數據庫管 理系統(ORDBMS)的使用相關聯。
Web 體系結構背景
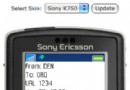
J2EE 包含幾十個縮寫詞 ,每個均代表不同的概念。要理解這一復雜性,回顧一下 Web 體系結構的發展過程是十分有 用的,如圖 1 所示。
圖 1. Web 體系結構
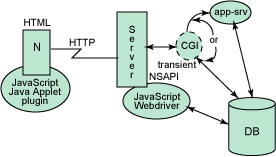
圖 1 中所展 示的體系結構代表了 1996 年的 Web 環境。那時,浏覽器和 Web 服務器主要是由 Netscape 提供的,而 Netscape 的產品在當時較之以前的產品來說是一個重大的進步。
在圖 1 的左側,我們看到的是浏覽器。它包含一些附加功能,以使用插件來提供像顯示 .pdf 文件 這樣的功能。它還增加了一些編程功能,以改善與用戶的交互。其中包括一種能夠添加到 HTML 語言中的腳本語言 JavaScript(獨立於 Java 創建的),以及可包含在 HTML 頁中進 行下載的 Java applet。
該浏覽器使用超文本傳輸協議(HTTP)與 Web 服務器進行 通信。HTTP 的重要特點就是它建立在請求-響應模型的基礎上。每個請求-響應都是相互獨立 的。Web 服務器不會等待當前客戶機的下一請求。因此,該協議是 無狀態的(stateless) 。
萬維網(WWW)是為了易於訪問文檔而創建的。因為每個請求都是單獨完成的,所 以無需追蹤復雜的交互。Web 服務器可以接收請求,並使用所提供的信息在由 Web 服務器控 制的目錄結構中檢索所請求的文檔。
在發展初期,Web 服務器的定義中添加了一個稱作公共網關接口(Common Gateway Interface,CGI)的接口。這是一種按照所定義的協議來調用以指定格式接收信息的程序, 使用該程序來實現請求,並將之返回給 Web 服務器的簡單方式。該方式還有能力調用一個可 以生成更多動態內容的程序。因為這是對於浏覽器請求的擴展,所以 CGI 程序是暫時性的: 通過請求創建,一旦返回結果就終止。
CGI 協議也有其局限性,並用於實現訪問關系數據庫的應用程序。這意味著每當向駐留在 關系數據庫中的信息發出請求時,都必須打開數據庫連接,插入、更新和檢索數據,以及關 閉連接。在大多數情況下,多數時間都消耗在數據庫的連接上。
人們想出了兩個辦法來解決該問題:
讓 CGI 程序與永久性程序進行對話。
以及通過包含 API 來擴展 Web 服務器的功能。
第一個辦法是讓 CGI 程序與永久性程序進行對話,這個方法可以有許多變種。CGI 程序 可以啟動一個要基於某個 ID 來進行訪問的應用程序,而這個 ID 是我們在響應中返回的( 如圖 1 中的 app-srv 所示)。如果此 ID 在某個間隔內還沒有被重新使用,程序將終止。 另一種方式是讓一個永久性程序來處理所有客戶機向該應用程序發送的請求。該場景極可能 需要一個多線程程序,用於驗證客戶機的有效性,以及向每個新的客戶機分配 ID。然後,它 必須記錄每個客戶機 ID 的超時時間。
第二個辦法是通過包含 API 來擴展 Web 服務器的功能,即利用 Web 服務器 API(圖 1 中的 NSAPI)來編寫應用程序,並將之駐留在 Web 服務器上。通過該方法,Web 服務器可以 保持數據庫連接,以及包含應用程序特定的處理信息。這種方法也需要記錄用戶和連接超時 。
進入應用程序服務器
將各種 Web 應用程序的實現方式合並成為一個更完整的架構是有道理的。那時,Java 倡 導的“一次編寫,到處運行”的概念已經十分流行。所以,J2EE 的成型並未花很長時間。
J2EE 是一個 Java 規范,且深受面向對象(OO)程序設計方法的影響(Java 是一種 OO 編程語言)。其目標是提供一個應用架構,其中包含實現企業應用程序所需的所有特性,這 包括可移植性、可伸縮性、事務控制,等等。J2EE 規范包括:
J2SE:Java 2 Standard Edition 包含了著名的 Java 環境,其中包括與平台無關的 Java 開發工具箱/Java 運行時環境(JDK/JRE)、多線程環境、Java 基礎類等。
EJB:Enterprise Java Beans 提供了在分布式環境中表示對象的標准方式。EJB 具有三 種類型:會話 bean、實體 bean 和消息 bean。
Servlets:Java Servlets 提供了請求-響應通信模式中的操作機制。
JSP:Java Server Pages 是特殊類型的 servlets,用於動態創建 HTML 頁並顯示給用戶 。
JDBC:Java 數據庫連接接口提供了與諸如關系數據庫的數據源進行通信的標准化方式。
JTA/JTS:Java 事務 API 與 Java 事務服務。
JMS:Java 消息服務。
JNDI:Java 命名和目錄接口。該接口對於 J2EE 環境至關重要,因為它提供了一種無需 知道其位置就可以追蹤資源的方式。您可以將之與 LDAP 目錄服務等同起來。
JavaMail
JAXP:用於 XML 處理的 Java API。它還包括用於 XML 注冊的 Java API(JAXR)和基於 XML 的 RPC 通信協議(JAX-RPC)。
Connector Architecture:該體系結構提供了與未集成在 J2EE 環境中的遺留系統進行通 信的方式。
JAAS:Java 認證和授權服務。
這些規范仍然在不斷演變著,而且還在添加更多組件。頗有意義的是,這些規范是基於標 准的,並且致力於提供應用程序提供者、應用程序服務器提供者以及硬件平台之間的可移植 性。正如您可以看到的,J2EE 環境正試圖提供企業應用程序中所需的所有可能服務。這包括 了多年以來以不同形式提供的許多服務。
圖 2 中提供了 J2EE 環境的高層表示。而真正的實現則可能包含許多其他組件,並且可 以將其對象分布在大型網絡中的多個機器上。
圖 2. J2EE 高層體系結構
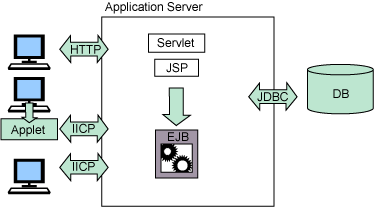
注意,該體系結構允許您實現通過 Internet Inter-Orb Protocol(IIOP)直接與 EJB 通信的客戶機應用程序。這將向除基於浏覽器的用戶接口之外的交互類型敞開大門。
對於 J2EE 環境底層的一些主要概念和模型的理解是極為重要的。接下來的幾小節將介紹 這些主題。
請求-響應
基於 Web 的用戶和應用程序服務器之間的交互遵循使用 HTTP 協議的原始 Web 模型。這 意味著我們要受上面簡要描述過的請求-響應模型的約束。
為了便於進行該通信,引入了新的 Java 類。用於處理該通信的主類就是 HttpServlet 類。該類包含了一組與 HTTP 協議相匹配的方法,其中獲得請求內容的方法是 doGet() 和 doPost() 。
HTTP 協議要麼通過在 URL 中放置參數來向 Web 服務器傳遞信息,要麼獨立於 URL 傳遞 信息。第一種稱作 GET 命令,而第二種稱作 POST 命令。GET 命令的優點是,URL 包含了檢 索請求信息所需的所有信息。因此,可將其加入書簽以便將來重新調用。而 POST 命令獨立 於 URL 發送附加信息,提供了更好的安全性。當需要發送比較大量的信息時,該方法也更為 合適。其缺點就是不能被加入書簽。
doGet() 和 doPost() 接收兩個參數: HttpServletRequest 請求和 HttpServletResponse 響應。這些附加類為您提供了需要從請求中獲得的所有信息。您將使 用響應參數來編寫應答。已提供的方法可以滿足您完成該應答所需的所有功能。
浏覽器和應用程序服務器之間的一切交互都是通過 HttpServlet 類完成的。您得花些時 間去學習上述類中所包含的字段和方法。
模型-視圖-控制器
J2EE 建議使用 MVC 開發模型。該模型背後的思想是:盡可能地將與用戶的交互、處理以 及數據訪問分離開。該模型已經活躍了很長一段時間。我記得它最早出現在 20 世紀 80 年 代的 Smalltalk 語言中。
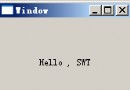
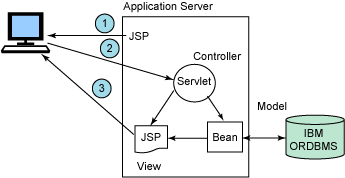
圖 3 說明了該模型與 J2EE 組件的使用。應用程序首先發出一個 JSP(視圖)請求,而 JSP 稍後將返回一個在浏覽器中顯示的頁面。接著,用戶選擇一個動作,向 servlet(控制 器)發送信息。再由 servlet 來決定必須完成什麼操作,它可能需要檢索一個 Java bean( 模型)或 EJB 來提供數據訪問。然後,servlet 可以向 JSP 傳遞一個對 Java bean 的引用 ,以便訪問要格式化和顯示的數據。
圖 3. MVC 模型
Enterprise Java Beans(EJB)
EJB 體系結構提供了開發分布式應用程序的標准模型。一個 EJB 包含兩個接口:Home 和 Remote。home 接口用於創建或查找指定類型的對象。remote 接口是通過 home 接口檢索得 到的,為您提供了對遠程對象的公共方法的訪問。
EJB 有三種類型:會話(session)、消息(message)和實體(entity)。會話 bean 提 供對業務過程的訪問。它們分為兩種類型:有狀態的和無狀態的。有狀態會話 bean 保存特 定客戶機調用之間的信息。無狀態會話 bean 可以被多個客戶機共享,因為它不保存調用之 間的任何特定信息。
消息 bean 是一種無狀態的 bean,提供了用於操縱 JMS 異步消息的業務過程。
實體 bean 代表業務數據及其相關的操縱邏輯。該業務數據必須保存在持久性存儲器(例 如,一個數據庫)中。
EJB 是通過部署描述符進行分布的,部署描述符包括事務屬性、安全性授權和持久性等信 息。我們將在下文另一小節中討論 J2EE 持久性。
面向對象方法(OOA)
面向對象(Object Orientation)改進了軟件的開發,它也是 J2EE 環境中的關鍵部分。 OO 的關鍵包括數據封裝和繼承的概念。關於該主題的書籍有很多,因此,我不會詳細描述該 方法。但是,有一些內容對於本文來說相當重要。
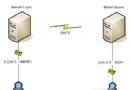
面向對象支持層次結構方法。我們可以看到對象繼承層次結構和對象組合層次結構。圖 4 通過部分醫學數字圖像和通信(Digital Imaging and Communications in Medicine,DICOM )標准,說明了這兩種類型的層次結構。
圖 4. DICOM 層次結構
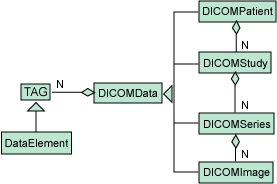
一個 Data 對象(DICOMData)可以特殊化為以下四種對象中的一種:patient、study、 series 或 image。而在圖 4 所展示的另一層次結構中,則可以將 TAG 對象特殊化為 DataElement。這些類型的繼承在 OO 分析、設計和編程中極為普遍。僅僅查看 Java 類就可 以看到一組精巧的對象繼承層次結構。
圖 4 還展示了聚集/組合示例,包括組合層次結構中的多個層次:我們看到,一個 Patient 可以包含多個 study,而一個 study 可以包含多個 series,而一個 series 又可 以包含多個 image。我們還看到所有這些對象都可以包含多個 TAG/DataElement,因為該組 合是在對象繼承層次結構的父類(DICOMData)中表示的。
聚集/組合模型使對象之間不太明顯的區別變得有意義。閱讀 OO 文獻時會發現,在多數 商業應用程序中,具有頻繁搜索並直接操縱的“第一級”對象,以及僅通過第一級對象來訪 問“第二級”對象 -- 如果您不檢索第一級對象,就永遠無法獲得第二級對象。30 年前,這 種典型的層次結構模型主導了數據庫模型。我們將在後面的小節中進一步討論它所帶來的優 點和缺點。
OO 中另一個有趣的主題就是對象持久性。實際上,OO 文獻整個都在討論對象,以及它作 為內存中的對象與其他對象的交互。另一方面,持久性似乎是個很麻煩的問題。主要問題就 是“持久保存對象”。數據庫服務器除了在必要時恢復對象之外,不會添加值。這就是為何 “阻抗失諧”問題對於許多 OO 人員來說顯得如此重要的部分原因。
J2EE 持久性模型
在談論 J2EE 環境中的持久性時,我們很可能要涉及實體 bean。J2EE 環境為實體 bean 提供了兩種持久性模式:bean 管理和容器管理。Bean 管理的持久性將所有的工作交給 EJB 開發人員,讓他們確定如何存儲和檢索特定的對象類型。
容器管理的持久性從 EJB 的實現中去除了持久性的細節。部署描述符中包含的抽象模式 定義了實體 bean 的持久性字段,以及它與其他 bean 之間的關系。這一工作是通過 EJB QL 語言完成的,該語言是 SQL 92 標准的一個子集。
在創建一個實體 bean 時,容器管理的持久性會將其信息保存在數據庫中。每當一個方法 調用修改該 bean 的內容時,這些修改就必須在數據庫中加以反映。當然,這也要考慮目標 實體 bean 的事務屬性。
J2EE 試圖讓對象持久性盡可能地簡單、透明和自動。在此過程中,它希望使持久性盡量 獨立於所有的數據庫產品,而無需考慮使用何種類型的數據庫或持久存儲器。因此,數據庫 被降級為簡單的持久性存儲設備。
IBM 的對象-關系數據庫
IBM 提供了兩種最新型的對象-關系數據庫:DB2® Universal Database™(UDB)和 Informix Dynamic Server™(IDS)。這兩種 都是關系型的數據庫,因而包含了關系模型及其集合處理的長處。它們還包含了對象的概念 ,並且可以擴展數據庫服務器的功能,更好地配合您的業務模型。而數據庫服務器則是一個 用於處理業務數據的可擴展性的架構。這些可擴展性特性與 J2EE 環境中的概念一致,因為 J2EE 確實是一個可擴展的應用架構。
這些數據庫產品在數據庫市場中處於領導地位 。要了解這些產品是如何崛起的,我們必須先看一看關系數據庫為何成為了該行業的主導。 在關系數據庫出現之前,占主導地位的各種數據庫都是按照層次結構來組織的。這應用了 “分而治之”的概念。從層次結構的頂層開始,您要選擇一個指定節點來表示一 個容器對象,如區域或部門,其中包含的是您數據庫中所有數據的一個子集。該對象有可能 包含成員。然後,您可以通過該節點的成員指針來選擇另一個子集。該過程可以一直進行到 您找到了需要操作的指定元素為止。除了可以添加、刪除或修改元素之外,您還可以通過操 縱指向元素或節點的指針,將元素移動到該層次結構中的另一位置上。
層次型數據庫 具有兩大優點:
它們是系統開銷最小的輕量級數據庫,因為它們僅僅返回應用程序 所請求的節點和成員指針。
它們快速地將數據分成較小部分以獲得所需的記錄。
另外,它們還具有一些可改善性能的特點:
針對單個問題的優化:本質上, 層次數據庫就通過一條指定的路徑來優化數據訪問。例如,一家大型銀行可能按區域、部門 和帳戶來劃分單元。那麼,就可以極其高效地找到屬於已知部門和區域的指定帳戶,或者按 區域和部門制作報表或進行分析。但是,要為某個指定客戶找到所有帳戶就比較困難了,因 為該客戶可能有多個過去創建的帳戶。而且,該客戶可能經歷過多次職位和住所的改動,從 而會擁有多個部門和多個區域中的帳戶。大多數公司都要通過他們的數據來解決多重問題。 如果遵循層次模型,他們可以很好地解決某一個問題。而其他問題的解決則可能比較糟糕。 為了取得相當好的性能,可能需要在多個層次中復制數據,從而可能極大地增加數據管理的 復雜性。
對於物理記錄的處理:層次數據庫中所存儲的記錄是由應用程序來直接操縱的。應用程序 必須知道每個字段的次序和類型,因為它必須計算該字段在記錄中的偏移量。修改了記錄結 構就需要修改訪問這些記錄的應用程序。
以編程方式實現對象的重定位:該指針操縱為復制和懸空指針(dangling pointer)等問 題的發生制造了機會。
總的來說,層次模型在某些特定的應用程序中是一種極為可行的模型,IBM IMS 產品的長 久生命力就證明了這一點。關系型數據庫已經超越了持久性存儲設備的角色,它們還解決了 上述層次數據庫的兩個缺點。關系型數據庫的主要特點有:
扁平的層次結構(Flattened hierarchy):關系數據庫以表的形式來表示數據。所有的 表都處於同一層次。這意味著所有的數據都可以直接進行訪問。再回過頭來看上文中的銀行 示例,我們可以直接訪問所有帳戶,並且找到屬於指定客戶的記錄,而不必管其帳戶屬於哪 個部門或區域。
邏輯記錄:表中的列是通過列名而非記錄偏移量來訪問的。操作中只會使用指定的列。這 樣一來,應用程序可以獨立於數據庫中的列號以及各列次序。可以對表進行修改以添加新的 列,且無需修改任何應用程序。這一概念隨著視圖(VIEW)的使用得到了深化,視圖是一種 由一個或多個表的子集所構建的虛表(virtual table)。您可以將視圖的概念與對象接口等 同起來。只要接口保持不變,使用該接口的應用程序就不需要進行修改。
集合操作:不是簡單地檢索特定記錄並返回給應用程序,關系型數據庫具有操作數據的功 能。這些功能包括排序、分組、聚集以及一個操作不同數據類型的大型函數集。
非過程化的查詢語言:關系型數據庫包括一種稱作結構化查詢語言(Structured Query Language,SQL)的數據操作語言。這將允許用戶或應用程序開發人員描述需要操作哪些數據 ,而不是描述如何獲得該數據。然後,數據庫系統必須確定如何實現該請求。優化器使用表 大小、索引可用性以及數據分布等信息來確定響應該查詢的最佳路徑。
關系數據庫還包括事務 ACID 屬性(原子性、一致性、獨立性、持久性)。關系數據庫中 陸續添加了約束、存儲過程、備份/恢復、復制等功能。
IBM 在繼續改進它的 ORDBMS。總的方向包括性能、可用性、可伸縮性、可管理性、開發 生產率、集成信息以及商業智能。通過數據聯邦和自主計算(autonomic computing),在信 息集成和隨需應變計算方面取得了較大突破。IBM 的產品中已經包含了其中的某些功能,不 久,還會出現更多功能來簡化數據管理。
ORDBMS 的“OR”部分是什麼呢?它是關系數據庫的可擴展性部分。我們一旦在概念上完 成這一飛躍,就會了解數據庫的可擴展性是關系數據庫的自然演變的一部分。
很早以前,關系數據庫就包含了有限的可擴展功能。諸如約束、存儲過程等功能都是可擴 展性的一種形式。DB2 UDB 還包含了允許系統和數據庫管理員設計部分處理的“用戶出口” 。存儲過程難道還不足夠嗎?不。它們是為了在數據庫返回數據之後應用過程化處理而設計 的。其好處在於限制數據庫與應用程序之間的數據傳送。存儲過程並未集成在數據庫引擎中 ,因為它們被設計為以過程化的方式一次處理一條記錄。我們還必須區別存儲過程和存儲過 程語言。
DB2 支持用戶用 SQL、Cobol、“C”和 Java 等語言編寫存儲過程。IBM-IDS 包含了一種 存儲過程語言,同時也支持用“C”和 Java 編寫的存儲過程。這些語言的使用已經擴展到了 關系模型中。除了通過編寫過程,在數據庫服務器完成其處理之後操作數據,我們還可以將 該處理包含在數據庫系統的集合處理中。其結果就是將集合處理交給數據庫引擎的簡化函數 。還可以將其執行更好地集成起來,從而更早地應用在處理中,以減少集合處理以及並行執 行查詢過程中的函數集成等後續步驟中的數據處理。這就支持多線程地執行這些函數,而不 必通過復雜的代碼來顯式地利用它。
DB2 UDB 和 IDS 允許您編寫多個具有相同名稱的函數,但必須帶有不同數目或不同類型 的參數。這類似於適用於 integer、decimal、float、double 或其混合類型的加法運算符( “+”),也類似於面向對象中的多態性。除了函數,這兩種數據庫還允許您創建 新的類型,以及通過使用表層次結構創建對象層次結構。所有這些功能共同允許您通過調整 數據庫來配合業務環境,而不是犧牲您的設計來適應數據庫。深入探討您通過充分使用 IBM 數據庫的功能所獲得的所有商業優勢已經超出了本文的范圍。關於可擴展性如何有助於提高 競爭力的示例,請查閱本文最後所給出的一些參考資料。
IBM ORDBMS 數據庫提供了 大量功能,可以簡化軟件開發,減少硬件需求,以及加快進入市場的步伐。您必須在設計中 善加利用,以便從中受益。IBM ORDBMS 不僅僅是一個持久性存儲器,更是一條提高您生產率 和效率的路徑。
非同小可的對象危機
理論上,以及在許多實際案例中,對於 持久對象的操作需要實例化該對象,對其進行操作,以及與持久性存儲器保持同步。這就導 致了容器管理的持久性以及獨立於數據庫的思想:
“使用容器管理的持久性的 好處是,實體 bean 可以在邏輯上獨立於存儲該實體的數據源。 …”
Enterprise JavaBeans™ 規范,版本 2.1,第 143 頁。
該規范還提到數據源可以是關系型的,也可以是非關系型的,如 IMS。當然還可以是 面向對象的數據庫。
任何修改容器管理 bean 的交互都需要與該數據源保持同步,以 確保實體 bean 的一致視圖。對 Enterprise JavaBean(EJB)使用 chatty 接口會顯著地增 加數據庫的交互量,從而可能導致性能問題。
“每次實例化一個對象”的 中心思想有可能會引起性能和容量問題。該問題不是僅限於容器管理的實體 bean 的使用中 ,而是普遍存在於面向對象方法中。讓我們用一個簡單的示例來加以說明。
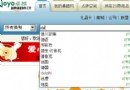
假設有一家專門從事貸款發放的大型銀行。它遍及多個區域,每個區域包括幾十甚至上百 家支行。
圖 5. 銀行貸款機構
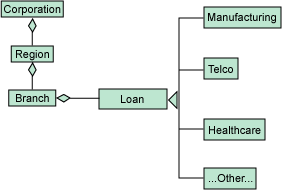
圖 5 說明該銀行對應多個區域,每個區域都有多個支行,而每個支行又進行多項貸款。 它還顯示我們可以獲得不同種類的貸款。
如果該銀行需要獲得一份清單,列出那些在貸款中承擔了過高風險的支行,它就會按區域 來收集該清單。每個區域將搜索其支行,找到那些風險過高的。而支行本身必須查詢每一項 貸款的風險和貸款額,用以計算該支行的平均風險。
以下是一種適宜的對象方式:每個對象封裝自身的信息和處理。支行要獲得貸款風險的惟 一方法就是向該貸款查詢這一信息。該方式比較合理,因為它消除了對象類型之間的緊密耦 合。對象間的通信取決於定義良好的接口。只要該接口保持不變,就可以修改其實現,且不 影響整個系統。
本例中,如果我們考慮:該銀行遍及 10 個區域,每個區域有 100 家支行,而每家支行 又有 10,000 份貸款,我們總共創建了 1000 萬多個對象來響應該查詢。要求每份貸款返回 兩個值:風險級別和貸款額。在區域和支行之間的通信中,這會在兩個對象之間傳遞超過 2000 萬條消息。最後從內存中刪除這些對象需要進行額外處理。
所使用的數目(10/100/10,000)絲毫不過分,我們絕對可以想像將生成更大數量級對象 的系統。這很容易成為一個性能以及容量(例如內存)問題。若通過給應用程序服務器增加 節點來解決該問題,非但解決不了,反而會增加復雜性。
通過利用 DB2 和 IDS 等對象-關系數據庫的長處,即使無法消除該問題,也可以有所緩 解。請記住,大多數面向對象人員僅僅將數據庫看作持久性存儲器。他們習慣於將所有處理 放在對象的代碼中完成,事後才添加數據庫。
如果考慮面向對象是何時成為主流的,我們就可以設想,現在絕大多數 30 出頭或更年輕 的程序員已經被訓練成以這種方式來思考了。由於數據庫僅僅用於“持久保存”對象以及檢 索它,所以系統開銷最小的數據庫在該模型中就占有優勢。這會有利於層次、網絡和對象數 據庫。而對象-關系型的數據庫可以完成比持久保存對象多得多的功能,卻成為永遠不被啟動 的大引擎。這就好比是在一場用賽車對抗自行車的比賽中,卻不允許您發動引擎一樣。
讓我們來解釋一下:面向對象方法是優秀的。問題在於許多架構師和開發人員視野過於狹 隘,不知道可以選擇將處理置於何處。這一選擇結果會影響設計,並且可以帶來重大性能影 響。利用 ORDBMS 的長處可以簡化設計,以及極大地提高結果系統的性能。這相當於加快進 入市場的步伐,以及降低開發和維護的成本。更快的結果還可以帶來重要的商業優勢。
數據庫獨立性
我在前面已提到 J2EE 通過促進數據庫獨立性來提高應用程序的可移植性。並且還進一步 提到可以是任何類型的數據庫:關系(對象-關系)或非關系的。這是整個 J2EE 體系結構的 一個美好目標,但在構建商業應用程序中卻是一種十分危險的方法。
商業應用程序的目標應該是提供對抗競爭者的商業優勢,而非可移植性。可移植性是一個 次要目標。如果需要進行移植,可以將不可移植的部分隔離起來,以便限制所需的工作。我 們需要以盡可能最低的成本獲得盡可能快的響應。如果您針對移植性進行設計,就要設計最 底層的功能,從而放棄所有優勢。這就像雇主拒絕雇用一個高度稱職的人,因為怕他某一天 離開,而下一任雇員的能力可能遠遠不及。按照該邏輯,我們應該雇用最無能的人。否則的 話,我們應該確保限制雇員對公司的貢獻,這樣,如果我們哪天必須用一個遜色一些的人來 接替他時,就不會感到失望。期望越多,您將得到越多。而期望越少,您得到的也會隨著時 間越來越少。
這同樣也適用於企業應用程序。您應該權衡您的數據庫系統的所有功能,並且對於能夠帶 來商業優勢的功能善加利用。您可以在設計中隔離數據庫的交互,以便當您偶爾必須遷移到 另一數據庫時,就只需要完成有限的移植工作。由於數據庫的競爭十分激烈,所以,很可能 您現在計劃使用的獨特的新功能將來會出現在某個競爭對手的數據庫中。或者,在數據庫供 應商為爭取您的業務,協商將如何補償其缺點時,這可能成為其中的一個缺點。因此,設計 要謹慎,但也要贏得成功。
J2EE 復雜性
J2EE 具有許多好處,有助於商業應用程序的開發。它們包括平台獨立性、組件架構、多 層應用程序模型、統一的安全模式以及一個豐富的標准集合,這些標准涉及事務控制、數據 庫訪問和消息傳遞等領域。實際上,J2EE 在一個架構下集成了過去 50 年左右軟件中所取得 的進展。這也付出了一定的代價:復雜性。
盡管 WebSphere Studio Application Developer 等工具明顯地簡化了開發,而且 WebSphere Studio Application Developer 管理控制台提供了控制,在啟動大型項目之前, 我們還是必須確保已經具備了適當的專業知識。最有效的方法就是培訓與聘請專家顧問相結 合。
同樣重要的是,要具有一支包括了各個領域專家的綜合隊伍。在項目啟動之前,要將這支 隊伍聚集在一起。例如,數據庫管理員(DBA)和 SQL 專家應該從一開始就一起討論將如何 使用不同的對象。讓我們用一個示例來加以說明。
圖 4 展示了 DICOM 對象之間的關系。我們看到,每一種類型的 DICOMData 都可以包含 許多其他的 DICOMData 對象。我們可以通過標准的關系方法或使用新的數據類型,在數據庫 中表示該層次結構關系。關於處理層次結構的示例,請參閱參考資料小節。更為迫切的問題 是數據元素的處理。
一個數據元素是由一個標簽(tag)和一個值表示。存在不同類型的值,如字符串、日期 (date)、小數(decimal)等。一個值還可以具有重復字段。一個 DICOMData 對象有可能 包含幾百種不同的數據元素。但實際上,數目要少得多。
將一個 DICOMData 對象表示為一大行幾乎為空的數據元素既不實際,也不可能。那麼, 我們可以將 DICOMData 對象表示為 DICOM 對象本身與數據元素之間的關系。第一種方法是 為每一種類型的數據元素准備一個數據元素表。這會產生 23 個表,而且檢索一個 DICOMData 對象要連接 24 個表。其他的方法可能允許我們將 23 個表縮減為一個。即便如 此,通過關系型數據庫來存儲和檢索 DICOMData 對象也要付出昂貴的代價。
如果數據庫專家恰好從一開始就參與進來了,那麼就可以討論這些問題,並可以揭示那些 使實現更加容易的新信息。結果顯示每種類型的 DICOMData 對象中只有少數元素將用於搜索 。這就允許我們表示 DICOMData 對象中的少量值,並且將所有其他的數據元素組合成一個大 型對象列。在存儲和檢索 DICOMData 對象時,這帶來了顯著的性能提高。
在前一小節中,我們討論了通過向每個支行查詢貸款上所承擔的平均風險度導致的對象爆 炸(見圖 5)。DB2 UDB 和 IDS 的對象-關系功能允許我們擴展數據庫功能,以便在數據庫 中包含風險計算函數。那麼,我們可以使用存儲過程或用戶定義的聚集來計算每個支行的平 均風險。我們甚至可以添加條件,其中定義了不能接受的風險級別,並且規定只檢索處於過 高風險中的支行清單。結果帶來了顯著的性能增長,因為我們不必實例化一百萬個對象,並 且避免了對象之間的多數消息傳遞。在對象人員看到了許多對象創建和通信的地方,數據庫 人員可以找到直接提供對策的辦法。在恰當的地方進行處理將提供更簡單、更高效的解決方 案。
J2EE 的其他方面也增加了它的復雜性。這包括牽涉共享 EJB 的多線程環境。您如何共享 EJB 呢?在一次更新中又如何協調多個 EJB 呢?您的代碼是可重入的,還是設置必須鎖定的 臨界區呢?這將導致許多問題,如數據完整性、鎖定策略以及數據庫人員所熟知的一些問題 。
那麼,存在 EJB 訪問的性能問題,您需要以怎樣的粒度進行才能獲得高性能。您還必須 確定如何監控應用程序以找到性能瓶頸。
J2EE 環境在開發和運行企業應用程序中表現極佳。但由於其復雜性,不宜濫用。如果希 望項目取得成功,您就要在初期組織好一支合適的專家隊伍來共同完成。
尋求解決方案
本文前面所提出的問題沒有理想的解決方案。要從正確的培訓抓起,這樣您才能充分使用 解決方案的所有組件。其中可能包括在 Web 浏覽器中使用 applet、中間件當中的合理設計 、以及利用數據庫系統的長處。
圖 6. 對象集合
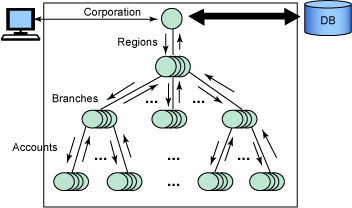
上面的示例說明應該仔細檢查一個對象裡對象集合的使用。我們必須確定是否真的需要一 個集合,或者是否可以用一個或多個通過數據庫操作該對象集合的方法來代替該集合。在有 些情況下,保留該集合將是比較恰當的;而在其他情況下,使用方法將提供更大的好處,例 如性能的提高和復雜性的減小。
圖 6 說明了中間件中對象的創建以及對象之間的通信。如果我們可以直接從數據庫獲得 想要的信息,那麼我們就可以從多個地方獲得性能提高。首先,我們可以通過避免在數據庫 服務器和應用程序服務器中的應用程序之間傳送大量數據來獲得更好的性能。該傳送可以在 網絡連接上的兩台機器之間,通過網絡所連接的同一機器上,或使用共享存儲器所連接的同 一機器上進行。當在兩台機器之間進行通信時,數據傳送要受到以下因素的影響:它必須通 過的多個硬件組件(存儲器、系統總線、網絡控制器等)、網絡延遲、在網絡的不同層上向 機器間傳輸的每個數據包添加附加信息的協議棧。
如果數據是在同一機器上傳送的,它可能仍然要通過網絡協議,並且包括操作數據包所需 的所有處理。通過共享存儲器連接來完成的開銷最低。即便如此,它仍然包括數據庫協議開 銷,以及從服務器空間到應用程序空間的內存復制。與處理器的速度相比,這種內存到內存 的復制相對比較慢。
當應用程序向數據庫請求數據時,會通過數據庫連接串行化其結果。數據庫服務器可以在 內部並行地處理信息,以提供大得多的吞吐量。請記住,諸如 DB2 UDB 和 IDS 等數據庫都 是優化了數據集合操作的專用引擎。其算法已經由具有多年大型商業應用程序支持經驗的專 家進行了優化。所以,利用這些專家經驗,而不是設法重新創建一個是有道理的。
應用程序服務器一旦收到了所有數據,它就需要實例化大量對象,然後逐個與之進行通信 ,獲取進行所需計算必要的少量信息。對於這些對象的調用數目,以及為取得期望結果必須 執行的代碼行數,讓我們了解要取得期望結果需要進行多麼重大的處理。通過將數據庫作為 數據處理引擎,我們可以避免其中大部分開銷。同時,還減少了解決方案的復雜性。
在將所有對象實例化之後,還需要創建從每個對象收集信息的適當處理,按照合適的分組 將該信息分類,以及為最後的結果執行聚集操作。所有這些工作都可以通過使用數據庫來消 除。對象人員經常聲稱對象方法比過程化編程優越。當一個對象必須操作一個對象集合時, 它有效地使用過程化代碼來完成該操作。這就是將集合處理交給數據庫完成的另一個原因。
操作對象的類型和操作類型可以影響是否使用對象集合的決策。我們以前曾看到,一些真 正的第二級對象只有在檢索更高一級的對象時,才能被檢索。這可以說明應該盡可能地將它 們留給數據庫來處理。
某些處理需要從對象獲取信息,如果該信息可以直接從數據庫服務器獲得,我們就可以避 免實例化它們。不僅上面銀行示例中的聚集計算是如此,報表編制也屬於這種情況。在後面 一種情況下,將對象實例化以報告某些信息之後,就再也不需要該對象了。
即使在對象更新它們狀態的情況下,也應該謹慎地考慮對象實例化。它仍然涉及對象創建 、對象之間的消息和新狀態的持久性。從數據庫直接獲取數據可能更合理。與將數據庫中的 對象視為被動的(passive)相反,我們至少應該將其當作半主動(semi-active)的。這種 觀點的改變可能會引入不同的應用程序設計方法,結果將會是充分利用數據庫來實現解決方 案。
結束語
一個強大的 J2EE 應用程序會充分利用它所有組件的長處。這包括浏覽器或用戶接口部分 、應用程序服務器和數據庫引擎。通過將處理置於最為合理的地方,可以減少應用程序的復 雜性,並且極大地提高性能。
數據庫的選型應該是會為您帶來商業優勢的戰略性決策。一旦做出決策,您就必須充分利 用該數據庫服務器來實現這一優勢。數據庫系統至關重要,通過使用數據庫服務器的所有功 能,您可以消除一些數據移動,減少對象的創建和對象間的通信,簡化您的實現,以及更快 地進入市場。充分使用了所有組件功能的均衡實現就不會需要那麼多的硬件和代碼。這就減 少了構建和維護該應用程序的成本,可以將所節省的資金運用到企業的其他地方,從而提高 您的商業競爭力。
我們需要可以將數據庫功能集成到所有 OO 開發階段(包括分析、設計和實現)的更好的 工具。這包括分析、設計和實現。同時,我們必須通過在項目的前期召集數據庫專家,來確 保這些任務的正確完成。