文檔對象模型(Document Object Model,DOM)是公認的 W3C 標准,它被用於與平台及 語言無關的 XML 文檔內容、結構和樣式的動態訪問和更新。它為表示文檔定義了一套標准的 接口集,也為訪問和操縱文檔定義了一套標准的方法。DOM 得到廣泛的支持和普及,並且它 以各種不同的語言實現,包括 Java、Perl、C、C++、VB、Tcl 和 Python。
正如我將在本文所演示的,當基於流的模型(例如 SAX)不能滿足 XML 處理要求時,DOM 是一個極佳的選擇。不幸的是,規范的幾個方面,例如其語言無關性接口和“一切都是節點 (everything-is-a-node)”抽象概念的使用,使其難以使用且易於生成脆弱代碼。這在最 近的幾個大型 DOM 項目的研究中尤其明顯,這些項目是由許多開發人員過去一年所創建的。 下面討論了常見的問題及其補救措施。
文檔對象模型
DOM 規范被設計成可與任何編程語言一起使用。因此,它嘗試使用在所有語言中都可用的 一組通用的、核心的功能部件。DOM 規范同樣嘗試保持其接口定義方面的無關性。這就允許 Java 程序員在使用 Visual Basic 或 Perl 時應用他們的 DOM 知識,反之亦然。
該規范同樣將文檔的每個部分看成由類型和值組成的節點。這為處理文檔的所有方面提供 了完美的概念性框架。例如,下面的 XML 片段
the Italicized portion.
就是通過以下的 DOM 結構表示的:
圖 1:XML 文檔的 DOM 表示
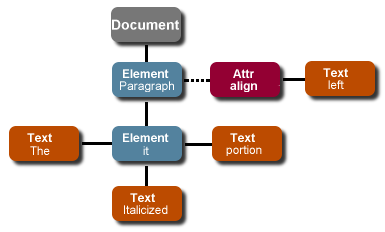
樹的每個 Document、Element、Text 和 Attr 部分都是 DOM Node 。
完美的抽象確實付出了代價。考慮 XML 片段: Value 。您或許會認為文本的值可以通過 普通的 Java String 對象來表示,並且通過簡單的 getValue 調用可訪問。實際上,文本被 當成 tagname 節點下的一個或多個子 Node 。因此,為了獲取文本值,您需要遍歷 tagname 的子節點,將每個值整理成一個字符串。這樣做有充分的理由: tagname 可能包含其它嵌入 的 XML 元素,在這種情況下獲取其文本值沒有多大意義。然而,在現實世界中,我們看到由 於缺乏便利的函數導致頻繁的編碼錯誤占了 80% 的情況,這樣做的確有意義。
設計問題
DOM 語言無關性的缺點是通常在每個編程語言中使用的一整套工作方法和模式不能被使用 。例如,不能使用熟悉的 Java new 構造創建新的 Element ,開發者必須使用工廠構造器方 法。 Node 的集合被表示成 NodeList ,而不是通常的 List 或 Iterator 對象。這些微小 的不便意味著不同尋常的編碼實踐和增多的代碼行,並且它們迫使程序員學習 DOM 的行事方 法而不是用直覺的方法。
DOM 使用“一切都是節點”的抽象。這就意味著幾乎 XML 文檔的每個部分,例如: Document、Element 和 Attr ,全都繼承( extend ) Node 接口。這不僅是概念上完美, 而且還允許每個 DOM 的不同實現通過標准接口使其自身的類可見,並且沒有通過中間包裝類 所導致的性能損失。
由於存在的節點類型數量及其訪問方法缺乏一致性,“一切都是節點”的抽象喪失了一些 意義。例如, insertData 方法被用來設置 CharacterData 節點的值,而通過使用 setValue 方法來設置 Attr (屬性)節點的值。由於對於不同的節點存在不同的接口,模型 的一致性和完美性降低了,而學習曲線增加了。
JDOM
JDOM 是使 DOM API 適應 Java 的研究計劃,從而提供了更自然和易用的接口。由於認識 到語言無關 DOM 構造的棘手本質,JDOM 目標在於使用內嵌的 Java 表示和對象,並且為常 用任務提供便利的函數。
例如,JDOM 直接處理“一切都是節點”和 DOM 特定構造的使用(如 NodeList )。JDOM 將不同的節點類型(如 Document、Element 和 Attribute )定義為不同的 Java 類,這意 味著開發者可以使用 new 構造它們,避免頻繁類型轉換的需要。JDOM 將字符串表示成 Java String ,並且通過普通的 List 和 Iterator 類來表示節點的集合。(JDOM 用其本身類替 代 DOM 類。)
JDOM 為提供更完善的接口做了相當有益的工作。它已經被接受成為 JSR(正式的 Java Specification Request),而且它將來很可能會被包含到核心的 Java 平台中。但是,因其 還不是核心 Java API 的一部分,一些人對於使用它還心存猶豫。這兒還有關於與 Iterator 和 Java 對象頻繁創建相關的性能問題的報告。(請參閱 參考資料)。
如果您對 JDOM 的接受性和可用性已經滿足,並且如果您也沒有將 Java 代碼和程序員轉 移到其它語言的直接需求,JDOM 是個值得探索的好選擇。JDOM 還不能滿足本文探討的項目 所在的公司需要,因而他們使用了非常普遍的 DOM。本文也是這樣做的。
常見編碼問題
幾個大型 XML 項目分析揭示了使用 DOM 中的一些常見問題。下面對其中的幾個進行介紹 。
代碼臃腫
在我們研究中查看的所有項目,本身都出現一個突出的問題:花費許多行代碼行來做簡單 的事情。在某個示例中,使用 16 行代碼檢查一個屬性的值。而同樣的任務,帶有改進的健 壯性和出錯處理,可以使用 3 行代碼實現。DOM API 的低級本質、方法和編程模式的不正確 應用以及缺乏完整 API 的知識,都會致使代碼行數增加。下面的摘要介紹了關於這些問題的 特定實例。
遍歷 DOM
在我們探討的代碼中,最常見的任務是遍歷或搜索 DOM。 清單 1 演示了需要在文檔的 config 節裡查找一個稱為“header”節點的濃縮版本代碼:
清單 1 中,從根開始通過檢索頂端元素遍歷文檔,獲取其第一個子節點( configNode ),並且最終單獨檢查 configNode 的子節點。不幸的是,這種方法不僅冗長,而且還伴隨 著脆弱性和潛在的錯誤。
例如,第二行代碼通過使用 getFirstChild 方法獲取中間的 config 節點。已經存在許 多潛在的問題。根節點的第一個子節點實際上可能並不是用戶正在搜索的節點。由於盲目地 跟隨第一個子節點,我忽視了標記的實際名稱並且可能搜索不正確的文檔部分。當源 XML 文 檔的根節點後包含空格或回車時,這種情況中發生一個頻繁的錯誤;根節點的第一個子節點 實際是 Node.TEXT_NODE 節點,而不是所希望的元素節點。您可以自己試驗一下,從 參考資 料下載樣本代碼並且編輯 sample.xml 文件 ― 在 sample 和 config 標記之間放置一個回 車。代碼立即異常而終止。要正確浏覽所希望的節點,需要檢查每個 root 的子節點,直到 找到非 Text 的節點,並且那個節點有我正在查找的名稱為止。
清單 1 還忽視了文檔結構可能與我們期望有所不同的可能性。例如,如果 root 沒有任 何子節點, configNode 將會被設置為 null ,並且示例的第三行將產生一個錯誤。因此, 要正確浏覽文檔,不僅要單獨檢查每個子節點以及核對相應的名稱,而且每步都得檢查以確 保每個方法調用返回的是一個有效值。編寫能夠處理任意輸入的健壯、無錯的代碼,不僅需 要非常關注細節,而且需要編寫很多行代碼。
最終,如果最初的開發者了解它的話,清單 1 中示例的所有功能應該可以通過利用對 getElementsByTagName 函數的簡單調用實現。這是下面要討論的。
檢索元素中的文本值
在所分析的項目中,DOM 遍歷以後,第二項最常進行的任務是檢索在元素中包含的文本值 。考慮 XML 片段 The Value 。如果已經導航到 sometag 節點,如何獲取其文本值( The Value )呢?一個直觀的實現可能是:
sometagElement.getData();
正如您所猜測到的,上面的代碼並不會執行我們希望的動作。由於實際的文本被存儲為一 個或多個子節點,因此不能對 sometag 元素調用 getData 或類似的函數。更好的方法可能 是:
sometag.getFirstChild().getData();
第二種嘗試的問題在於值實際上可能並不包含在第一個子節點中;在 sometag 內可能會 發現處理指令或其它嵌入的節點,或是文本值包含在幾個子節點而不是單單一個子節點中。 考慮到空格經常作為文本節點表示,因此對 sometag.getFirstChild() 的調用可能僅讓您得 到標記和值之間的回車。實際上,您需要遍歷所有子節點,以核對 Node.TEXT_NODE 類型的 節點,並且整理它們的值直到有完整的值為止。
注意,JDOM 已經利用便利的函數 getText 為我們解決了這個問題。DOM 級別 3 也將有 一個使用規劃的 getTextContent 方法的解答。教訓:盡可能使用較高級的 API 是不會錯的 。
getElementsByTagName
DOM 級別 2 接口包含一個查找給定名稱的子節點的方法。例如,調用:
NodeList names = someElement.getElementsByTagName("name");
將返回一個包含在 someElement 節點中稱為 names 的節點 NodeList 。這無疑比我所討 論的遍歷方法更方便。這也是一組常見錯誤的原因。
問題在於 getElementsByTagName 遞歸地遍歷文檔,從而返回所有匹配的節點。假定您有 一個包含客戶信息、公司信息和產品信息的文檔。所有這三個項中都可能含有 name 標記。 如果調用 getElementsByTagName 搜索客戶名稱,您的程序極有可能行為失常,除了檢索出 客戶名稱,還會檢索出產品和公司名稱。在文檔的子樹上調用該函數可能會降低風險,但由 於 XML 的靈活本質,使確保您所操作的子樹包含您期望的結構,且沒有您正在搜索的名稱的 虛假子節點就變得十分困難。
DOM 的有效使用
考慮到由 DOM 設計強加的限制,如何才能有效和高效的使用該規范呢?下面是使用 DOM 的幾條基本原則和方針,以及使工作更方便的函數庫。
基本原則
如果您遵循幾條基本原則,您使用 DOM 的經驗將會顯著提高:
不要使用 DOM 遍歷文檔。
盡可能使用 XPath 來查找節點或遍歷文檔。
使用較高級的函數庫來更方便地使用 DOM。
這些原則直接從對常見問題的研究中得到。正如上面所討論的,DOM 遍歷是出錯的主要原 因。但它也是最常需要的功能之一。如何通過不使用 DOM 而遍歷文檔呢?
Path
XPath 是尋址、搜索和匹配文檔的各個部分的語言。它是 W3C 推薦標准 (Recommendation),並且在大多數語言和 XML 包中實現。您的 DOM 包可能直接支持 XPath 或通過加載件(add-on)支持。本文的樣本代碼對於 XPath 支持使用 Xalan 包。
XPath 使用路徑標記法來指定和匹配文檔的各個部分,該標記法與文件系統和 URL 中使 用的類似。例如,XPath: /x/y/z 搜索文檔的根節點 x ,其下存在節點 y ,其下存在節點 z 。該語句返回與指定路徑結構匹配的所有節點。
更為復雜的匹配可能同時在包含文檔的結構方面以及在節點及其屬性的值中。語句 /x/y/* 返回父節點為 x 的 y 節點下的任何節點。 /x/y[@name='a'] 匹配所有父節點為 x 的 y 節點,其屬性稱為 name ,屬性值為 a 。請注意,XPath 處理篩選空格文本節點以獲 得實際的元素節點 ― 它只返回元素節點。
詳細探討 XPath 及其用法超出了本文的范圍。請參閱 參考資料獲得一些優秀教程的鏈接 。花點時間學習 XPath,您將會更方便的處理 XML 文檔。
函數庫
當研究 DOM 項目時令我們驚奇的一個發現,是存在的拷貝和粘貼代碼的數量。為什麼有 經驗的開發者沒有使用良好的編程習慣,卻使用拷貝和粘貼方法而不是創建助手(helper) 庫呢?我們相信這是由於 DOM 的復雜性加深了學習的難度,並使開發者要理解能完成他們所 需要的第一段代碼。開發產生構成助手庫規范的函數所需的專門技術需要花費大量的時間。
要節省一些走彎路的時間,這裡是一些將使您自己的庫可以運轉起來的基本助手函數。
findValue
使用 XML 文檔時,最常執行的操作是查找給定節點的值。正如上所討論的,在遍歷文檔 以查找期望的值和檢索節點的值中都出現難度。可以通過使用 XPath 來簡化遍歷,而值的檢 索可以一次編碼然後重用。在兩個較低級函數的幫助下,我們實現了 getValue 函數,這兩 個低級函數是:由 Xalan 包提供的 XPathAPI.selectSingleNode (用來查找和返回與給定 的 XPath 表達式匹配的第一個節點);以及 getTextContents ,它非遞歸地返回包含在節 點中的連續文本值。請注意,JDOM 的 getText 函數,或將出現在 DOM 級別 3 中規劃的 getTextContent 方法,都可用來代替 getTextContents 。 清單 2包含了一個簡化的清單; 您可以通過下載樣本代碼來訪問所有函數(請參閱 參考資料)。
通過同時傳入要開始搜索的節點和指定要搜索節點的 XPath 語句來調用 findValue 。函 數查找第一個與給定 XPath 匹配的節點,並且抽取其文本值。
setValue
另一項常用的操作是將節點的值設置為希望的值,如 清單 3 所示。該函數獲取一個起始 節點和一條 XPath 語句 ― 就象 findValue ― 以及一個用來設置匹配的節點值的字符串。 它查找希望的節點,除去其所有子節點(因此除去包含在其中的任何文本和其它元素),並 將其文本內容設置為傳入的(passed-in)字符串。
appendNode
雖然某些程序查找和修改包含在 XML 文檔中的值,而另一些則通過添加和除去節點來修 改文檔本身的結構。這個助手函數簡化了文檔節點的添加,如 清單 4所示。
該函數的參數有:要將新節點添加到其下的節點,要添加的新節點名稱,以及指定要將節 點添加到其下位置的 XPath 語句(也就是,新節點的父節點應當是哪個)。新節點被添加到 文檔的指定位置。
最終分析
DOM 的語言無關性設計為其帶來了非常廣泛的可應用性並使其在大量的系統和平台上得以 實現。這樣做的代價是:使 DOM 比為每個語言專門設計的 API 更困難且更缺乏直觀性。
DOM 奠定了一個非常有效的基礎,遵循一些簡單的原則就可其上構建易於使用的系統。凝 結了一大群用戶智慧和經驗的 DOM 未來版本正在設計之中,而且極有可能為這裡討論的問題 提供解決方案。如 JDOM 這樣的項目正在修改該 API 以獲得更自然 Java 感覺,而且如本文 中所述的技術可以幫助您使 XML 的操縱更方便、更簡潔並且不易出錯。利用這些項目且遵循 這些用法模式以允許 DOM 成為基於 XML 項目的出色平台。
本文配套源碼