1.簡介
如果你需要實現一個流式的流程,特別是嵌入的,並且你想讓其易於配置、擴展、管理和維護。你是否需要一個功能齊備的BPM引擎呢:引擎都有自己的抽象負載,它對於你正在尋找的簡單流程編排來說似乎過於笨重了;或者有什麼輕量級的替代方案可以使用,讓我們不必采用一個功能齊備的BPM引擎?本文說明了如何使用面向方面編程(AOP)技術來構建並編排高可配置、可擴展的輕量級嵌入式流程流(process flow)。目前例子是基於Spring AOP和Aspect J的,其他AOP技術也可實現同樣的結果。
2.問題
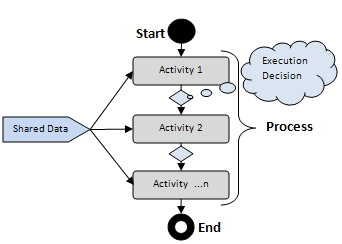
在我們繼續深入討論之前,首先我們需要更好地理解實際的問題,然後試著把我們對問題的理解與一套可用模式、工具和/或技術進行匹配,看看是否能找到一個合適的。我們的問題就是一個流程(process)本身,那麼讓我們好好理解一下它吧。什麼是流程?流程是經過協調的活動的集合,這些活動致使一組目標得到實現。活動(activity)是指令執行的一個單元,它是一個流程的基本組成部分。每個活動操作一部分共享數據(上下文),以實現流程整體目標的一部分。已被實現的流程目標的各部分代表既成的事實(facts),這些事實被用來協調剩余活動的執行。這實質上把流程重新定義為一個在事實集合上進行操作的規則模式,用來協調定義該流程的那些活動的執行。為了讓流程協調活動執行,它必須知道如下屬性:
活動——定義流程的活動
共享數據/上下文——定義共享數據的機制和活動所完成的事實
轉移規則——基於已注冊的事實,定義前一個活動結束之後跟著是哪個活
執行決策——定義執行轉移規則的機制
初始化數據/上下文(可選)——由該流程操作的共享數據的初始化狀態
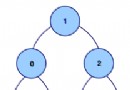
下圖顯示了流程的高層結構:
我們現在可以用如下需求集合來形式化一個流程:
定義把流程裝配為一個活動集合的機制
定義各個活動
定義共享數據的占位符
定義在流程范圍內的這些活動協調執行的機制
定義轉移規則和執行決策機制,根據由活動注冊的事實執行轉移規則
3.架構和設計
我們定義架構將從解決頭4個需求開始:
定義把流程裝配為一個活動集合的機制
定義各個活動
定義共享數據的占位符
定義在流程范圍內的這些活動協調執行的機制
活動是一個無狀態工作者,它應該接收一個包含一些數據(上下文)的token。活動應該通過讀寫來操作這一共享的數據token,同時執行由這個活動所定義的業務邏輯。共享的數據token定義了一個流程的執行上下文。
為了堅持前面我們制定的輕量級原則,沒有理由不把我們的活動定義為實現了POJI(Plan Old Java Interfaces)的POJO(Plain Old Java Objects)。
這裡是Activity接口的定義,它只有一個process(Object obj)方法,其輸入參數代表了一個共享數據(上下文)的占位符。
public interface Activity {
public void process (Object data);
}
一個共享數據的占位符可以是結構化或非結構化(比如Map)對象。這完全取決於你。為簡單起見,通常我們的Activity接口把它定義為java.lang.Object,但是在真實環境中,它或許被表達為某種結構化對象類型,流程的所有參與者都知道這一結構。
流程
因為流程是活動的集合,我們需要定出裝配及執行這種集合的機制。
有許多方式可以達成這一目的。其中之一是把所有活動插入到某種類型的有序集合中,按其預先定義好的順序迭代它調用每個活動。這種方法的可配置性和可擴展性明顯很差,因為流程控制和執行的所有方面(aspects)都將被硬編碼。
我們還可以用某種非傳統的方式來考慮流程:假定流程是一個行為較少的抽象,並沒有具體實現。可是,從一個活動過濾器(Activity Filters)鏈中過濾這種抽象,可以定義這個流程的性質、狀態和行為。
假定我們有一個叫做GenericProcess的類,其定義了process(..)方法:
public class GenericProcess {
public void process(Object obj){
System.out.println("executing process");
}
}
如果我們直接傳遞輸入對象來調用process(..)方法,不會發生什麼事情,因為process(..)方法沒有做什麼事情,上下文的狀態將保持非修改狀態。但是如果我們試圖在調用process(..)之前找到一種方法來引入活動,並讓該活動修改這個輸入對象,那麼process(..)方法仍將保持不變,但是因為輸入對象是由活動預先處理過的,流程上下文的整體結果將會改變。
這種把攔截過濾器(Intercepting Filter)應用到目標資源的技術在攔截過濾模式中有很好的文檔記錄,在今天的企業級應用中被廣泛使用。典型的例子是Servlet過濾器(Filters)。
攔截過濾器模式用一個過濾器封裝了已有應用資源,這個過濾器攔截了請求的接收及響應的傳遞。一個攔截過濾器可以前置處理(pre-process)或重定向(redirect)應用請求,而且可以後置處理(post-process)或替換(replace)應用響應的內容。攔截過濾器還可以改變順序,無需改變源代碼就可以把一個分離的、可聲明部署的服務鏈加入到現有資源——http://java.sun.com/blueprints/patterns/InterceptingFilter.html。
過去,這一架構通常用來解決非功能關注點(concerns),比如安全、事務等等……但是你可以清楚地看到,通過攔截過濾器(代表各個活動)鏈來裝配類流程結構,同樣的方法也可以很容易被應用來解決應用的功能特性。
下圖顯示了對於一個流程(Process)的調用如何被過濾器鏈攔截,其中每個過濾器都與流程的某個活動(Activity)相關聯,這樣,實際的目標流程組件沒有什麼事情可干,使之成為一個空的、可重用的目標對象。改變該過濾器鏈你就得到了自己一個不同的流程。
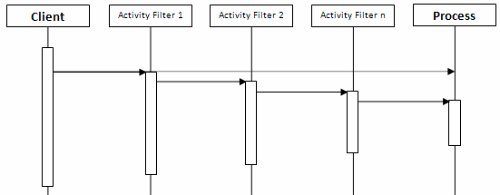
唯一留下來要做的事情就是看看有沒有一個框架,可以幫助我們以優雅的方式裝配類似這樣的東西。
基於代理的(Proxy-based)Spring AOP看起來是理想的選擇,因為它給我們提供了簡單的結構和最重要的東西——執行機制。它將使我們能夠定義一個有序攔截過濾器集合,來代表一個給定流程的各個活動。輸入的流程請求將會由這些過濾器所代理,用活動過濾器(Activity Filters)中的行為實現來裝飾流程。
這樣留給我們的只有下面唯一的需求:
定義轉移規則和執行決策機制,根據由活動注冊的事實執行轉移規則
基於代理的過濾器的美妙之處是轉移機制本身。每當我們調用一個目標對象(流程)時,攔截過濾器將一個接一個的被代理機制所調用。這是自動的,而且在每個活動必須被調用的情況下工作得相當好。但是實際並不總是這種情況。早先我們在問題定義中描述之一是:“已經被實現的流程目標的那部分,表示已完成的事實,它被用來協調剩余活動的執行”——這意味著一個活動完成並不是必須轉移到另一個活動。在實際的流程中,轉移必須嚴格地基於前一個活動已完成和/或未完成的事實。這些事實必須向共享數據占位符注冊,這樣它們就可以被審核。
完成這一點可以簡單到在我們的攔截過濾器中放一個IF語句:
public Object invoke(MethodInvocation invocation){
if (fact(s) exists){
invoke activity
}
}
但是這將產生多個問題。在我們研究是些什麼問題之前,讓我們先搞清楚一件事:在當前的結構中,每個攔截過濾器緊密地與相應的POJO活動耦合在一起。正因為如此,我們可以很容易把所有活動邏輯保持在攔截過濾器本身中。唯一能夠阻止我們這樣做的是我們希望活動保持為POJO,這意味著在攔截過濾器中的代碼將簡單地委派給活動回調(Activity callback)。
這意味著如果我們把轉移求值邏輯放在活動中,我們將從根兒上把這兩個關注點耦合在一起(活動轉移羅輯和活動業務羅輯),這將違背分離關注點的基本架構原則並將導致關注點/代碼耦合(concern/code coupling)。另一個問題則涉及到所有攔截過濾器會重復同一轉移邏輯。我們稱之為關注點/代碼擴散(concern/code scattering)。轉移邏輯橫貫所有攔截過濾器,你可能已經猜到了,AOP再次成為所選技術。
我們所需做的一切就是寫一個around advice,它將使我們能夠攔截對實際過濾器類目標方法的調用,對輸入求值,並作出轉移決策,要麼允許,要麼不允許目標方法執行。唯一要告誡的是我們的目標類本身恰恰就是攔截過濾器。因此本質上我們正在試圖攔截攔截器。不幸的是Spring AOP不能幫上忙,因為它是基於代理的,因此我們的攔截過濾器已經是代理基礎架構的一部分了,我們不能代理這個代理(proxy the proxy)。
但是AOP最好的特性之一就是它可以有多種不同的風格和實現(例如,基於代理的,字節碼編織等等……)。盡管我們不能使用基於代理的AOP來代理另一個代理,但是我們使用字節碼編織AOP,誰也攔不住,它將通過編織(編譯時或裝載時)我們的轉移求值邏輯,來形成我們代理的攔截過濾器,這樣就可以保持轉移和業務邏輯分離。使用像AspectJ這樣的框架很容易做到這一點。這樣做,我們就給我們的架構引入了第二個AOP層,這是非常有意思的實現。我們使用Spring AOP來解決功能關注點,比如用活動編排流程;同時,我們又使用AspectJ來解決非功能關注點,比如活動導航和轉移。
下圖記錄了被顯示為兩個AOP層的流程流的最終結構,其中功能AOP層(Functional AOP Layer)負責從有序的攔截過濾器集合中裝配流程,而非功能AOP層(Non-Functional AOP Layer)則解決轉移控制的問題。
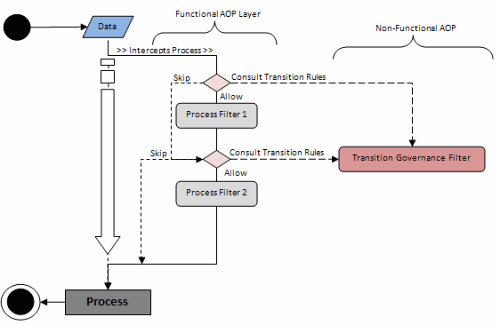
為證明這一架構的工作情況,我們將實現一個簡單的用例——購買物品(Purchase Item),它定義了一個簡單的流程流。
4.用例(購買物品)
想象一下你正在在線購物。你已經選擇了某項物品,把它放入到購物車中,然後前去結賬,給出你的信用卡信息並最終提交購買物品請求(purchase item request)。系統將初始化購買物品流程(Purchase Item process)。
先決條件
流程必須接收包含物品、賬單、配送信息的數據
主流程
1.校驗物品數量
2.獲得貸記授權
3.配送
這個流程當前定義了3個活動,如下圖所示:
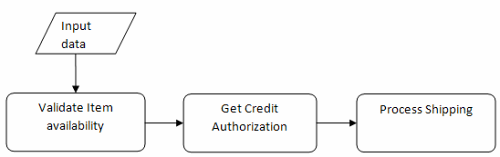
這個圖還顯示了不受控制(ungoverned)的活動轉移。但實際上,如果物品數量不夠會發生什麼?“獲得貸記授權”活動應該執行嗎?“配送”應該隨之進行嗎?
另一個有趣的告誡是:根據條件,貸記授權(credit authorization)可能不會自動完成(授權網絡關閉了),而你或客戶服務代表不得不直接打電話給貸記公司以獲得認證碼。一旦該認證碼被獲得並輸入到系統中,這個流程應該從何處重新開始或繼續呢?從頭來還是直接進入配送環節?我覺得應該進入配送環節,但是怎樣才能做到呢?我們怎麼才能從中間重新啟動該流程,而不用維護和管理許多執行控制呢?
有意思的是,使用AOP我們不需要維護執行控制,也不需要維護流程的流向。它是在通過攔截過濾器鏈時由框架本身來處理的。我們需要做的一切就是提出一種機制,根據注冊事實允許或不允許各個過濾器執行。
“校驗物品數量”將注冊物品數量充足的事實,該事實是“獲得貸記授權”的前提。“獲得貸記授權”也要注冊貸記已授權這一事實,而這又是“配送”活動的前提。存在或缺少事實也將被用來決策何時不執行一個特定活動,這又把我們帶回到了“手工貸記審核”場景,怎麼才能從中間重新啟動流程呢,或者問一個更好的問題: 我們怎樣才能重新啟動該流程,而不重復該流程上下文中已經執行過的活動?
記得嗎,共享的數據token(上下文)也代表了流程的狀態。這一狀態包含了該流程登記的所有事實。這些事實被求值以做出轉移決策。因此,在“手工貸記審核”場景中,如果我們從最開始重新提交整個流程,我們的轉移管理機制,在遇到第一個活動“校驗物品數量”之前,會馬上意識到物品數數量充足事實(item available fact)已經注冊過了,這個活動不應再次重復,因此,它將跳到下一個活動——“貸記審核”。因為貸記已授權事實也已經注冊過了(通過某種手工錄入方式),它將再次跳到下一個活動“配送”,只允許這一活動執行並完成該流程。
在我們進入實際例子之前,有一個更重要的話題還要討論一下,那就是活動被定義的順序。盡管從一開始好像活動的順序在(這些活動所定義的)流程轉移決策中並不起任何作用。
流程中活動的順序只是代表了流程本身的平衡能力——該策略基於事實的可能性和概率,它們的存在將給下一個活動的執行或不執行創造一個理想的環境。改變活動的順序永遠不應影響整個流程。
實例:
Legend:
d - depends
p - produces
Process:
ProcessContext = A(d-1, 2; p-3) -> B (d-1, 3; p-4, 5) -> C(d-4, 5);
按照上面的公式,當流程在給定的ProcessContext內開始時,第一個要考慮的活動是A,在它被調用之前依賴於事實1和2。假定事實1和2存在於 ProcessContext中,活動A將執行並產生事實3。在線上的下一個活動是B,它依賴於事實1和3。我們知道我們的流程在活動A執行之前事實3發生的可能性和概率非常小。可是在活動A被執行之後,事實3存在的可能性和概率則相當高,因此活動B的順序是跟在A後面。
但是如果我們把活動B和A的順序顛倒一下,會有什麼變化?
ProcessContext = B (d-1, 3; p-4, 5) -> A(d-1, 2; p-3) -> C(d-4, 5);
變化不大。當流程被調用時,維護著事實注冊表的ProcessContext將很快斷定已注冊的事實不足以允許活動B被調用,因此它將跳到下一個活動A。假定事實1和2是存在的,對事實進行評估將確定已注冊的事實足以允許調用活動A,等等。活動C也將被跳過,因為它缺少由B產生的先決條件。如果流程再次與同一個的ProcessContext一起被提交,活動B將被調用,因為活動A在流程前一次調用過程中已經注冊了活動B所需的事實,滿足了B執行的前提條件。活動A將被跳過,因為ProcesContext知道活動A已經做了它的工作。活動C也會被調用,因為活動B已經注冊了足夠的事實以滿足活動C的先決條件。
因此,正如你所看到的,變換活動的順序不會改變流程行為,但可影響流程的自動化特征。
5.實例
該例子包含了如下制品:
GenericProcess的實現,正如你所見,它包含的代碼沒什麼意義,事實上它從未會包含任何有意義代碼。這個類的唯一目的就是作為應用代表各個活動的攔截過濾器鏈的目標類。
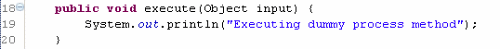
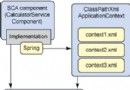
它相應的Spring定義為:
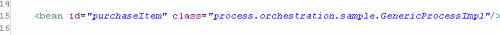
PurchaseItem(購買物品)流程的其他配置包括三部分:

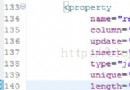
第一部分(第14行)——流程裝配AOP配置,包含把GenericProcessImpl.execute(..)方法定義為連接點(Join Point)的pointcut。你還可以看到我們使用了bean(purchseItem) pointcut表達限定我們正在攔截哪個bean。通過用應用於不同過濾器鏈的不同bean名創建GenericProcessImpl的另一個實例,我們可以定義多個流程。它還包含了對實現為Aopaliance攔截器的活動過濾器的引用。默認的,過濾器按照從頂置底的順序排列,然而為了更清楚,我們還可以使用order屬性。
第二部分(第30行)——通過定義ActivityFilterInterceptor的三個實例來配置活動攔截器。每個實例將被注入後面定義的相應POJO活動bean和事實屬性。事實屬性定義了一個簡單的規則機制,允許我們描述一個簡單的條件,基於此,下面的活動將被允許或不允許執行。例如:validateItemFilter定義了 “!VALIDATED_ITEM”事實規則,它將被解釋為:如果VALIDATED_ITEM事實還未被注冊在事實注冊表中,則允許調用活動。只要validatItemActivity執行了,這一事實將被注冊在事實注冊表中:如果這一事實還未注冊,它將允許這一活動執行;如果事實已經注冊,它將在流程與同一執行上下文一起重新提交時保護該活動不會被重復執行。
第三部分(第47行)——為我們的流程配置三個POJO活動。
ActivityFilterInterceptor——它所做的所有事情就是調用底層POJO活動並把該活動返回的事實進行注冊(第53 行),並且可以讓POJO活動對事實注冊表(Fact Registry)或流程的任何其他底層架構組件的地點保持未知(請見下面代碼片斷)。可是正如我們後面將要看到的,這一攔截器本身的調用是根據每個攔截器配置中所描述的事實規則由AspectJ advice所控制的(第二個AOP層),從而控制各個活動的執行。
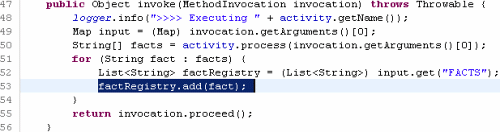
各個POJO活動簡單地返回它們要注冊的所有事實的String數組,然後由自己的攔截器將其注冊到事實注冊表中(見上面代碼片斷)。

TransitionGovernorAspect——是一個AspectJ組件,攔截對每個Spring AOP攔截器(代表各個活動)的調用。它是通過使用Around advise做到這一點的,在其中它對事實規則和當前事實注冊表進行比較,就執行或跳過下面的活動攔截器調用做出決策。可以通過調用它自己的invocation對象(ProceedingJoinPoint thisJoinPoint)的proceed(..)方法做到這一點,或者調用攔截過濾器的invocation對象(MethodInvocation proxyMethodInvocation)的proceed(..)方法來做到這一點。

由於它是用AspectJ aspect實現的,我們需要在META-INF/aop.xml中提供配置(見下面配置片斷)。

因為我們要使用裝載時AOP,我們需要在Spring配置中注冊編織器。我們通過使用context名字空間來做到這一點:
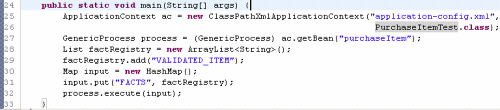
此時,我們已經做好測試准備了。正如你所見,測試沒有什麼特殊的,其步驟是:
獲得ApplicationContext
獲得GenericProcess對象
創建一個事實注冊列表
創建對象(在我們的用例中是Map),代表輸入數據以及執行上下文
調用process方法
由於我們使用的是AspectJ裝載時編織,因此需要提供-javaagent選項作為我們的VM參數。
VM參數是:
-javaagent:lib/spring-agent.jar
spring-agient.jar已經存在於lib目錄中了。
在執行之後你應該看到類似下面的輸出:

正如你從該測試所看到的,初始的事實列表是空的,但是如果你用已有事實填充它,那麼流程流將被改變。
試著把給注冊表增加事實這行代碼的注釋去掉。
在你的測試中的把如下代碼行注釋去掉:
// factRegistry.add("VALIDATED_ITEM");
你的輸出將變為:

6.結論
該方法說明了怎樣使用兩層AOP來裝配、編排並控制流程流(process flow)。第一層是用Spring AOP實現的,將流程裝配為攔截過濾器鏈,其中每個過濾器都被注入了相應活動。第二層是用AspectJ實現的,提供流程的編排及流控制。通過攔截過濾器鏈來代理我們的流程,將使我們能夠定義和維護流程的流向。而代理機制無需像BPM這樣單獨的引擎的,也提供了執行環境。我們通過使用已有技術(Spring AOP)提供的控制和執行機制做到了這一點。
該方法是輕量級、嵌入式的。它使用已有Spring基礎架構並建立在流程是已編排的活動集合的前提之上。每個活動是一個POJO而且完全不知道任何管理它的底層架構/控制器組件。這有幾個優點。除了典型的松耦合架構優點外,隨著像OSGi這樣的技術不斷的普及和采納,保持活動和活動調用控制分離,把活動實現為一個OSGi服務也成為可能,這使得每個活動都成為獨立的單元(部署、更新、卸載等等……)。易於測試是另一個優點。因為活動是POJO,它們可以在使用它們的應用之外作為POJO來測試。他們有定義良好的輸入/輸出契約(它需要的數據以及它預期產生的數據)。你可以單獨測試每個活動。
分離控制邏輯(攔截過濾器)和業務邏輯(POJO活動)將使你能夠給流程事實規則接插更加成熟的規則門面(facade),同樣,測試轉移邏輯也應該不影響由下面活動實現的業務邏輯。
活動是獨立的基本組成部分,可以被在一些其它流程中重復使用。例如“貸記審核”活動可以很容易被重用,將其裝配在某些其它需要貸記審核的流程上。