C# 提供了 DataSet,可以將數據源中的數據讀取到內存中,進行離線操作,然後再同步到數據源。同樣,在 Java 中也提供了類似的實現,即 RowSet。javax.sql.rowset 包下,定義了五個不同的 RowSet 接口,供不同的場合使用。本文將分別對這五個 RowSet 的使用場合以及詳盡用法進行介紹,並且描述使用中可能出現的問題,以提醒讀者在實際使用時繞開這些問題。
RowSet 簡介
javax.sql.rowset 自 JDK 1.4 引入,從 JDK 5.0 開始提供了參考實現。它主要包括 CachedRowSet,WebRowSet,FilteredRowSet,JoinRowSet 和 JdbcRowSet。 除了 JdbcRowSet 依然保持著與數據源的連接之外,其余四個都是 Disconnected RowSet。
相比較 java.sql.ResultSet 而言,RowSet 的離線操作能夠有效的利用計算機越來越充足的內存,減輕數據庫服務器的負擔,由於數據操作都是在內存中進行然後批量提交到數據源,靈活性和性能都有了很大的提高。RowSet 默認是一個可滾動,可更新,可序列化的結果集,而且它作為 JavaBeans,可以方便地在網絡間傳輸,用於兩端的數據同步。
類繼承結構
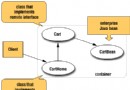
RowSet 繼承自 ResultSet,其他五個 RowSet 接口均繼承自 RowSet。下圖是它們的繼承關系。
圖 1. 繼承結構圖
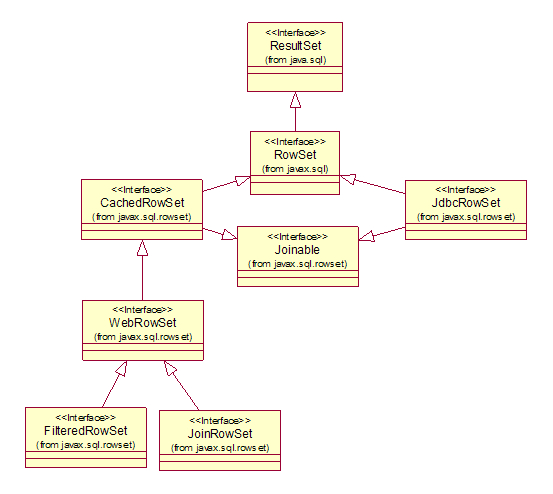
表 1. RowSet 接口說明
CachedRowSet 最常用的一種 RowSet。其他三種 RowSet(WebRowSet,FilteredRowSet,JoinRowSet)都是直接或間接繼承於它並進行了擴展。它提供了對數據庫的離線操作,可以將數據讀取到內存中進行增刪改查,再同步到數據源。可串行化,可作為 JavaBeans 在網絡間傳輸。支持事件監聽,分頁等特性。 WebRowSet 繼承自 CachedRowSet,並可以將 WebRowSet 寫到 XML 文件中,也可以用符合規范的 XML 文件來填充 WebRowSet。 FilteredRowSet 通過設置 Predicate(在 javax.sql.rowset 包中),提供數據過濾的功能。可以根據不同的條件對 RowSet 中的數據進行篩選和過濾。 JoinRowSet 提供類似 SQL JOIN 的功能,將不同的 RowSet 中的數據組合起來。目前在 Java 6 中只支持內聯(Inner Join)。 JdbcRowSet 對 ResultSet 的一個封裝,使其能夠作為 JavaBeans 被使用,是唯一一個保持數據庫連接的 RowSet。
實驗環境
本文示例的實驗環境如下:
Java 環境:Sun JDK 6.0
數據庫:derby-10.3.1.4
數據庫名:TESTDB
數據庫用戶名及密碼:均使用 derby 默認用戶名和密碼。
表及測試數據:創建兩個表:CUSTOMERS 和 ORDERS,並分別插入測試數據。
示例代碼以附件形式提供 下載。
表 2. 表 CUSTOMERS
ID NAME REMARK 1 Tom Tom is VIP 2 Jim null
表 3. 表 ORDERS
ID USER_ID PRODUCT 1 1 Book 2 1 Computer 3 2 Phone
使用 CachedRowSet
填充 CachedRowSet 的兩種方式
CachedRowSet 提供了兩個用來獲取數據的方法,一個是 execute(),另一個是 populate(ResultSet)。
使用 execute() 填充 CachedRowSet 時,需要設置數據庫連接參數和查詢命令 command,如下示例代碼:
清單 1. 使用 execute()
cachedRS.setUrl(DBCreator.DERBY_URL);
cachedRS.setCommand(DBCreator.SQL_SELECT_CUSTOMERS);
// derby 默認用戶名和密碼都是 "APP",也可以不設置。
cachedRS.setUsername("APP"); //$NON-NLS-1$
cachedRS.setPassword("APP"); //$NON-NLS-1$
cachedRS.execute();
cachedRS 根據設置的 url、username、password 三個參數去創建一個數據庫連接,然後執行查詢命令 command,用結果集填充 cachedRS,最後關閉數據庫連接。execute() 還可以直接接受一個已經打開的數據庫連接,假設 conn 為一個已經打開的數據庫連接,下段示例代碼與上段代碼結果一致:
清單 2. 使用 execute(Connection)
cachedRS.execute(conn);
cachedRS.setCommand(DBCreator.SQL_SELECT_CUSTOMERS);
cachedRS.execute();
填充 CachedRowSet 的第二個方法是使用 populate(ResultSet)。
清單 3. 使用 populate(ResultSet)
ResultSet rs = stmt.executeQuery(DBCreator.SQL_SELECT_CUSTOMERS);
cachedRS.populate(rs);
rs.close();
CachedRowSet 本身也是繼承於 ResultSet,因此,也可以用一個有數據的 CachedRowSet 來填充另一個 CachedRowSet。
更新、刪除、插入數據
更新數據。先把游標(cursor)移到要更新的行,根據每列的類型調用對應的 updateXXX(index, updateValue),再調用 updateRow() 方法。此時,只是在內存中更新了該行,同步到數據庫需要調用方法 acceptChanges() 或 acceptChanges(Connection)。如果 CachedRowSet 中保存著原數據庫連接信息,則可以調用 acceptChanges();否則,則應該傳入可用的數據庫連接或重新設置數據庫連接參數。下段示例代碼更新第一行的第二列。
清單 4. 更新
cachedRS.first();
cachedRS.updateString(2, "Hello"); //$NON-NLS-1$
cachedRS.updateRow();
cachedRS.acceptChanges();
刪除數據。把游標移到要刪除的行,調用 deleteRow(),再同步回數據庫即可。
清單 5. 刪除
cachedRS.last();
cachedRS.deleteRow();
cachedRS.acceptChanges();
在刪除數據時,需要注意布爾值 showDeleted 這個屬性的使用。CachedRowSet 提供了 getShowDeleted() 和 setShowDeleted(boolean value) 兩個方法來讀取和設置這個屬性。showDeleted 是用來判斷被標記為刪除且尚未同步到數據庫的行在 CachedRowSet 中是否可見。true 為可見,false 為不可見。默認值為 false。
插入數據。插入操作稍微比更新和刪除復雜。先看下段示例代碼。
清單 6. 新增
cachedRS.last();
cachedRS.moveToInsertRow();
cachedRS.updateInt(1, 3);
cachedRS.updateString(2, "Bob"); //$NON-NLS-1$
cachedRS.updateString(3, "A new user"); //$NON-NLS-1$
cachedRS.insertRow();
cachedRS.moveToCurrentRow();
cachedRS.acceptChanges();
新插入的行位於當前游標的下一行。本例中,先把游標移到最後一行,那麼在新插入數據後,新插入的行就是最後一行了。在新插入行時,一定要先調用方法 moveToInsertRow(),然後調用 updateXXX() 設置各列值,再調用 insertRow(),最後再把游標移到當前行。注意一定要遵循這個步驟,否則將拋出異常。
沖突處理
當我們使用 CachedRowSet 更新數據庫時,有可能因為內存中的數據過期而產生沖突。此時更新數據庫的方法 acceptChanges() 會拋出 SyncProviderException,由此我們可以捕獲產生沖突的原因並手動進行解決。
清單 7. 沖突
ResultSet rs = stmt.executeQuery(DBCreator.SQL_SELECT_CUSTOMERS);
CachedRowSet cachedRS = new CachedRowSetImpl();
cachedRS.populate(rs);
cachedRS.setUrl(DBCreator.DERBY_URL);
// 修改數據庫中的數據
stmt.executeUpdate("UPDATE CUSTOMERS SET NAME = 'Terry' WHERE ID = 1");
// 在 CachedRowSet 中更新同一行
cachedRS.absolute(1);
cachedRS.updateString(3, "Tom is not VIP");
cachedRS.updateRow();
SyncResolver resolver = null;
try {
cachedRS.acceptChanges();
} catch (SyncProviderException e) {
resolver = e.getSyncResolver();
}
while (resolver.nextConflict()) {
System.out.println(resolver.getStatus());
}
我們首先填充 cachedRS,然後在數據庫中直接修改 ID 為 1 的行,將 NAME 字段設為 "Terry",同時用 cachedRS 修改 ID 為 1 的行的 REMARK 字段,最後使用 acceptChanges 跟數據庫進行同步。此時 cachedRS 中記錄的原始值與數據庫中的值不一致,從而產生沖突,拋出 SyncProviderException,數據也會更新失敗。接下來我們通過 SyncProviderException 得到 SyncResolver 實例並遍歷了產生的所有沖突。
SyncResolver 繼承了 RowSet 接口,我們可以像使用一般 RowSet 一樣操作它。SyncResolver 的實例擁有與正在同步的 RowSet 相同的行數和列數。使用 nextConflict() 和 previousConflict() 可以遍歷所有產生的沖突,getStatus() 可以獲得沖突的類型。在 SyncResolve 中定義了四種類型,分別是:DELETE_ROW_CONFLICT,INSERT_ROW_CONFLICT,NO_ROW_CONFLICT,UPDATE_ROW_CONFLICT。上例中產生的是 UPDATE_ROW_CONFLICT。
注:目前 Sun JDK 對 SyncResolver 的支持非常有限,只實現了 SyncResolver 接口中定義的方法,調用從 RowSet 接口繼承的方法都會拋出 UnsupportedOperationException 異常;getConflictValue() 返回都是 null。
事件監聽
一個監聽器需要實現 RowSetListener 接口。RowSetListener 支持三種事件監聽:cursor moved、row changed 和 rowSet changed。假定 Listener 實現了 RowSetListener 接口,看示例代碼。
清單 8. 注冊事件監聽器
Listener listener = new Listener();
cachedRS.addRowSetListener(listener);
updateOnRowSet(cachedRS);
cachedRS.removeRowSetListener(listener);
updateOnRowSet() 所做的操作就是將游標移到第一行,更新,再同步回數據庫。在這個方法中,依次觸發了 Listener 的三個事件。下表列出了 CachedRowSet 中會觸發監聽器的所有方法。
表 4. CachedRowSet 中會觸發監聽器的方法
cursor moved row changed rowSet changed absolute() √ relative() √ next() √ previous() √ first() √ last() √ beforeFirst() √ afterLast() √ updateRow() √ deleteRow() √ insertRow() √ undoDelete() √ undoUpdate() √ undoInsert() √ populate() √ acceptChanges() √ acceptChanges(Connection) √ execute() √ execute(Connection) √ nextPage() √ previousPage() √ restoreOriginal() √ release() √
事務
事務對於保證數據的一致性是非常重要的。CachedRowSet 專門提供了處理事務的接口,從而可以保證同步數據的原子性和一致性。CachedRowSet 默認是不使用事務的。
清單 9. 事務代碼一
cachedRS.absolute(1);
// 第一列不能為 null,更新時將產生沖突
cachedRS.updateNull(1);
cachedRS.updateRow();
cachedRS.next();
cachedRS.updateString(2, "Terry");
cachedRS.updateRow();
try {
cachedRS.acceptChanges(conn);
} catch (SyncProviderException e) {
// expected
}
rs = stmt.executeQuery(DBCreator.SQL_SELECT_CUSTOMERS);
cachedRS = new CachedRowSetImpl();
cachedRS.populate(rs);
printRowSet(cachedRS);
我們更新了 cachedRS 的第一行和第二行,並將第一行第一列錯誤的設置為 null。由於 CachedRowSet 默認不使用事務,第一行沒有更新,而第二行更新成功。我們也可以手動控制事務的作用范圍。
清單 10. 事務代碼二
cachedRS.absolute(1);
cachedRS.updateNull(1);
cachedRS.updateRow();
cachedRS.next();
cachedRS.updateString(2, "Terry");
cachedRS.updateRow();
conn.setAutoCommit(false);
try {
cachedRS.acceptChanges(conn);
cachedRS.commit();
} catch (SyncProviderException e) {
// expected
cachedRS.rollback();
}
conn.setAutoCommit(true);
rs = stmt.executeQuery(DBCreator.SQL_SELECT_CUSTOMERS);
cachedRS = new CachedRowSetImpl();
cachedRS.populate(rs);
printCachedRowSet(cachedRS);
與前面的例子不同的是,這裡我們關閉了自動提交模式,並且在同步失敗後回滾了事務,避免了數據不一致的情況。
需要注意的是,如果需要手動控制事務的范圍,在調用 execute 或 acceptChanges 時必須傳入 Connection,否則再調用 CachedRowSet 的 commit() 或 rollback() 會拋 NullPointerException。實際上 CachedRowSet 依然是通過在內部保存 Connection 的引用來實現事務操作的。
分頁
由於 CachedRowSet 是將數據臨時存儲在內存中,因此對於許多 SQL 查詢,會返回大量的數據。如果將整個結果集全部存儲在內存中會占用大量的內存,有時甚至是不可行的。對此 CachedRowSet 提供了分批從 ResultSet 中獲取數據的方式,這就是分頁。應用程序可以簡單的通過 setPageSize 設置一頁中數據的最大行數。也就是說,如果頁大小設置為 5,一次只會從數據源獲取 5 條數據。下面的代碼示范了如何進行簡單分頁操作。(分頁部分代碼默認 ORDERS 表中有 10 條數據)
清單 11. 分頁代碼一
ResultSet rs = stmt.executeQuery(DBCreator.SQL_SELECT_ORDERS);
CachedRowSet cachedRS = new CachedRowSetImpl();
// 設置頁大小
cachedRS.setPageSize(4);
cachedRS.populate(rs, 1);
while (cachedRS.nextPage()) {
printRowSet(cachedRS);
}
while (cachedRS.previousPage()) {
printRowSet(cachedRS);
}
可以看到只需要在 populate 之前使用 setPageSize 設置頁的大小,就可以輕松實現分頁了。每次調用 nextPage 或 previousPage 進行翻頁後,行游標都會被自動移動到當前頁第一行的前面,並且只能在當前頁內移動。這樣我們對每一頁都可以像新的數據集一樣進行遍歷,非常方便。這裡需要注意的是:
用來填充 CachedRowSet 的 ResultSet 必須是可滾動的(Scrollable)。
populate 必須使用有兩個參數的版本,否則無法進行分頁。讀者可以將 cachedRS.populate(rs, 1); 換成 cachedRS.populate(rs); 看看會有怎樣的情況發生。
ResultSet rs 必須在遍歷完畢後才能關閉,否則翻頁遍歷時會拋 SQLException。
我們注意到在使用分頁遍歷數據集時,nextPage() 是最先被調用的,也就是說頁與行相似,最開始的頁游標是指向第 0 頁的,通過 nextPage() 方法移到第一頁,這樣就可以用非常簡潔的代碼遍歷數據集。那麼如果在第 0 頁時(第一次調用 nextPage)之前使用 next 遍歷當前頁會是怎樣的結果呢?
清單 12. 分頁代碼二
ResultSet rs = stmt.executeQuery(DBCreator.SQL_SELECT_ORDERS);
CachedRowSet cachedRS = new CachedRowSetImpl();
// 設置頁大小
cachedRS.setPageSize(4);
cachedRS.populate(rs, 1);
printRowSet(cachedRS);
while (cachedRS.nextPage()) {
printRowSet(cachedRS);
}
我們看到第一頁被輸出了兩次。也就是說使用 next 始終是可以遍歷第一頁的,而每次 nextPage 後,行游標都會被重置到當前頁的第一行數據之前。對於使用 execute 填充數據的方式,通過 setPageSize 同樣可以實現分頁。
setMaxRows 可以設置 CachedRowSet 可遍歷的最大行數。下面是 setMaxRows 和 setPageSize 同時使用的例子。
清單 13. 分頁代碼三
ResultSet rs = stmt.executeQuery(DBCreator.SQL_SELECT_ORDERS);
CachedRowSet cachedRS = new CachedRowSetImpl();
cachedRS.setPageSize(4);
cachedRS.setMaxRows(7);
cachedRS.populate(rs, 1);
while (cachedRS.nextPage()) {
printRowSet(cachedRS);
}
rs.close();
上面的例子中,分別將頁大小設置為 4,最大行數設置為 7(設置頁大小時,如果最大行數不等於 0,就必須小於等於最大行數),然後遍歷打印所有行,輸出如下。
清單 14. 清單 13 中的代碼執行結果
The data in RowSet:
1 1 Book
2 1 Compute
3 2 Phone
4 2 Java
The data in RowSet:
5 2 Test
6 1 C++
7 2 Perl
我們注意到,雖然滿足 Select 條件的數據有 10 條,但由於我們使用 setMaxRows 設置了允許的最大行數,所以最終我們只得到了 7 條數據。另外 setPageSize 只會改變下一次填充頁時的大小,無法影響當前頁的大小。我們可以在數據填充完畢後再改變頁的大小。
清單 15. 分頁代碼四
ResultSet rs = stmt.executeQuery(DBCreator.SQL_SELECT_ORDERS);
CachedRowSet cachedRS = new CachedRowSetImpl();
cachedRS.setPageSize(4);
cachedRS.populate(rs, 1);
cachedRS.setPageSize(3);
while (cachedRS.nextPage()) {
printRowSet(cachedRS);
}
rs.close();
我們在 populate 數據之前設置的頁大小是 4,在 populate 數據之後又將頁大小設置為 3,然後遍歷輸出結果。
清單 16. 清單 15 中的代碼執行結果
The data in RowSet:
1 1 Book
2 1 Compute
3 2 Phone
4 2 Java
The data in RowSet:
5 2 Test
6 1 C++
7 2 Perl
The data in RowSet:
8 1 Ruby
9 1 Erlang
10 2 Python
我們發現除了第一頁有 4 條數據外,其余頁都只有 3 條數據。實際上 populate 中就已經對第一頁數據進行了填充,並且使用之前設置的 4 作為頁大小。所以 populate 之後設置的頁大小就只能從第二頁開始起作用了。setMaxSize 與此相似,也是在每次填充頁時計算。
應注意的問題
在 JDK 5.0 中,當刪除一行中某列值為 null 時,會拋出 NullPointerException。例如,表 CUSTOMERS 中第二行第三列的值為 null。假設 cachedRS 裡面填充著表 CUSTOMERS 的數據,那麼下段代碼在 JDK 5.0 下運行時會拋出 NullPointerException。在 JDK 6.0 中,此問題已得到修正。
清單 17.
cachedRS.absolute(2);
cachedRS.deleteRow();
cachedRS.acceptChanges();
使用 WebRowSet
WebRowSet 繼承於 CachedRowSet,因此用來填充 CachedRowSet 的方式同樣適用於 WebRowSet。WebRowSet 也可以讀取一個符合規范的 XML 文件,填充自己。假定 CUSTOMERS.xml 是一個符合規范的 XML 文件,裡面存放的是表 CUSTOMERS 的數據。
清單 18. 讀取 XML 文件
WebRowSet newWebRS = new WebRowSetImpl();
newWebRS.readXml(new FileReader("CUSTOMERS.xml"));
相比於 CachedRowSet,WebRowSet 就是添加了對 XML 文件讀寫的支持。它可以將自身數據輸出到 XML 文件,也可以讀取符合規范的 XML 文件,來填充自己。上段示例代碼中已經演示了如何讀取 XML 文件。如下示例代碼則是生成一個 XML 文件。
清單 19. 生成 XML 文件
WebRowSet webRS = new WebRowSetImpl();
CachedRowSetDemo.fillRowSetWithExecute(webRS);
// 輸出到XML文件
FileWriter fileWriter = new FileWriter("CUSTOMERS.xml");
webRS.writeXml(fileWriter);
fillRowSetWithExecute(CachedRowSet) 是一個靜態方法,它的功能是用表 CUSTOMERS 來填充傳入的 CachedRowSet。
應注意的問題
按照規范,當一行被標記為更新時,在輸出到 XML 文件時,應使用標簽 <modifyRow>,但實際輸出為 <currentRow>。
按照規范,當一行中某列被更新時,在輸出到 XML 文件時,應使用標簽 <updateValue>,但實際輸出為 <updateRow>。
按照規范,讀取 XML 文件時,如果某行標簽為 <deleteRow>,在讀到 WebRowSet 中時,該行應被標記為刪除,實際讀取後,狀態丟失。
使用 FilteredRowSet
FilteredRowSet 繼承自 WebRowSet。正如它的名字所示,FilteredRowSet 是一個帶過濾功能的 RowSet。它的過濾規則在 Predicate 中定義。Predicate 也是 javax.sql.rowset 包下的接口,它定義了三個方法:boolean evaluate(Object value, int column),boolean evaluate(Object value, String columnName),boolean evaluate(RowSet rs)。 前兩個方法主要是用來檢查新插入行的值是否符合過濾規則,符合,返回 true;否則,返回 false。FilteredRowSet 在新插入行時,會用這個方法來檢測。如果不符合,會拋出 SQLException。boolean evaluate(RowSet rs) 這個方法則是用來判斷當前 RowSet 裡面的所有數據,是否符合過濾規則。FilteredRowSet 在調用有關移動游標的方法時,會使用這個方法進行檢測。只要符合過濾規則的數據才會顯示出來。下面我們給出了一個非常簡單的 Predicate 實現,它的過濾規則是每行第一列的值只有大於 1 的才是有效行。
清單 20. Rang.java
class Range implements Predicate {
@Override
public boolean evaluate(RowSet rs) {
try {
if (rs.getInt(1) > 1) {
return true;
}
} catch (SQLException e) {
// do nothing
}
return false;
}
@Override
public boolean evaluate(Object value, int column) throws SQLException {
return false;
}
@Override
public boolean evaluate(Object value, String columnName)
throws SQLException {
return false;
}
}
下面這段代碼演示了使用上面定義的 class Range 前後的數據變化。
清單 21. 設置過濾器
FilteredRowSet filterRS = new FilteredRowSetImpl();
CachedRowSetDemo.fillRowSetWithExecute(filterRS);
System.out.println("/*******Before set filter***********/");
CachedRowSetDemo.printRowSet(filterRS);
System.out.println("\n/*******After set filter***********/");
Range range = new Range();
filterRS.setFilter(range);
CachedRowSetDemo.printRowSet(filterRS);
清單 22. 清單 21 中的代碼執行結果
/*******Before set filter***********/
The data in RowSet:
1 Tom Tom is VIP.
2 Jim null
/*******After set filter***********/
The data in RowSet:
2 Jim null
可以看出,在設置了過濾器後,再次打印 FilteredRowSet 中的數據時,由於第一行第一列的值為 1,不符合過濾規則,因此,沒有打印出來。上面實現的這個 Predicate 中,用來檢測新插入行是否符合過濾規則的方法直接返回 false。這樣,在新插入行時,無論插入什麼值時,都將拋出 SQLException。
應注意的問題
當設置了過濾器後,FilteredRowSet.absolute(1) 無論何時都返回 false。按照規范,如果第一行值不符合過濾規則,則移到第二行,依次類推,直到找到第一條符合過濾規則的結果行並返回 true,否則,返回 false。
在 JDK 5.0 下,如果 FilteredRowSet 沒有設置過濾器,那麼在新插入一行時會拋出 NullPointerException。在 JDK 6.0 中,已解決該問題。
使用 JdbcRowSet
JdbcRowSet 是對 ResultSet 的一個簡單的封裝,讓它可以作為一個 JavaBeans 組件來使用。填充 JdbcRowSet 只能通過一種方式,即 execute() 方法。之後可以通過類似於操作 ResultSet 的方法來操作 JdbcRowSet。
清單 23. JdbcRowSet
JdbcRowSet jrs = new JdbcRowSetImpl();
jrs.setCommand(DBCreator.SQL_SELECT_CUSTOMERS);
jrs.setUrl(DBCreator.DERBY_URL);
jrs.execute();
while (jrs.next()) {
for(int i = 1; i <= jrs.getMetaData().getColumnCount(); i++) {
System.out.print(jrs.getObject(i) + " "); //$NON-NLS-1$
}
System.out.println();
}
清單 24. 清單 23 中的代碼執行結果
1 Tom Tom is VIP.
2 Jim null
下面一節裡我們將會看到 JdbcRowSet 如何作為一個 RowSet 和其他的 RowSet 一起使用。
使用 JoinRowSet
支持的聯合方式
JoinRowSet 接口中對五種不同的聯合方式都定義了對應的常數和判斷該實現是否支持的方法,如下表所示。
表 5. 五種聯合方式
聯合方式 對應的常數 判斷是否支持的方法(返回布爾值) 內連接(INNER JOIN) JoinRowSet.INNER_JOIN supportsInnerJoin() 左外連接(LEFT OUTER JOIN) JoinRowSet.LEFT_OUTER_JOIN supportsLeftOuterJoin() 右外連接(RIGHT OUTER JOIN) JoinRowSet.RIGHT_OUTER_JOIN supportsRightOuterJoin() 全外連接(FULL OUTER JOIN) JoinRowSet.FULL_JOIN supportsFullJoin() 交叉連接(CROSS JOIN) JoinRowSet.CROSS_JOIN supportsCrossJoin()
同時還有兩個方法,getJoinType() 返回當前的聯合方式,setJoinType(int) 設置聯合方式。值得注意的是,Java 5 和 Java 6 中都支持內連接 (INNER JOIN) 這一種聯合方式。在 setJoinType 方法中傳入除 Inner_Join 以外的任何一種聯合方式都會拋出 UnsupportedOperationException 的異常。
另外一點需要注意的,雖然默認的聯合方式就是內連接,但是在沒有顯示的調用 setJoinType() 之前調用 getJoinType() 會拋出 ArrayIndexOutOfBoundsException 的異常。 所以一般來講,我們可以不需要調用這幾個方法而直接認為 JoinRowSet 默認並且只允許的聯合方式就是內連接(INNER JOIN)。
如何聯合各種 RowSet
聯合多個 RowSet 的方法其實就是往一個 JoinRowSet 裡調用 add 方法添加其他 RowSet(這個 RowSet 可以是上面提到的五種 RowSet 中的任意一種,包括離線操作的 JdbcRowSet 和 JoinRowSet 本身)的過程。添加一個 RowSet 的同時也必須制定聯合時匹配的列。JoinRowSet 接口中提供了以下幾個 add 方法:
addRowSet(Joinable rowset)
addRowSet(RowSet[] rowset, int[] columnIdx)
addRowSet(RowSet[] rowset, String[] columnName)
addRowSet(RowSet rowset, int columnIdx)
addRowSet(RowSet rowset, String columnName)
下面是一個聯合一個 JdbcRowSet 和一個 CachedRowSet 的簡單例子。
清單 25. 使用 JoinRowSet
// 構造一個CachedRowSet並且填充CUSTOMERS表中的數據。
CachedRowSet cachedRS = new CachedRowSetImpl();
cachedRS.setUrl(DBCreator.DERBY_URL);
cachedRS.setCommand(DBCreator.SQL_SELECT_CUSTOMERS);
cachedRS.execute();
// 構造一個JdbcRowSet並且填充ORDERS表中的數據。
JdbcRowSet jdbcRS = new JdbcRowSetImpl();
jdbcRS.setUrl(DBCreator.DERBY_URL);
jdbcRS.setCommand(DBCreator.SQL_SELECT_ORDERS);
jdbcRS.execute();
// 把cachedRS添加進新構造的JoinRowSet中。
JoinRowSet joinRS = new JoinRowSetImpl();
joinRS.addRowSet(cachedRS, "ID"); //$NON-NLS-1$
// 下面這條被注釋的語句會拋出ClassCastExcepion。
// joinRS.addRowSet(jdbcRS, "ID");
// 把jdbcRS添加進這個JoinRowSet中。
jdbcRS.setMatchColumn("ID"); //$NON-NLS-1$
joinRS.addRowSet(jdbcRS);
// 觀察結果
printRowSet(joinRS);
清單 26. 清單 25 中的代碼執行結果
The data in CachedRowSet:
2 Jim null 1 Compute
1 Tom Tom is VIP. 1 Book
雖然 JoinRowSet 提供了五個不同的 addRowSet 方法,但是對於某些 RowSet,並不是每個方法都能用的。比如當上面添加一個 JdbcRowSet 的時候,你只能調用 addRowSet(Joinable) 這個方法(JdbcRowSet 實現了 Joinable 接口),並且在調用這個方法之前一定要先設置配對的列名或者以 1 為基數的配對列的位置,如下所示。
清單 27. 添加 JdbcRowSet
// 正確的添加一個JdbcRowSet的方法。
jdbcRS.setMatchColumn("ID"); //$NON-NLS-1$
joinRS.addRowSet(jdbcRS);
輸出結果表明此時 JoinRowSet 中的數據正是兩個 RowSet 中的數據的內聯結果。加進去的兩個 RowSet 中的”ID”這一列,在 JoinRowSet 中合並成了一列。如果我們查看最後 JoinRowSet 的列名,會發現這一列的列名變成了”MergedCol”, 其它列名不變。這個時候的 JoinRowSet 可以繼續添加其他的 RowSet,聯合會在 MergedCol 這一列上進行。
清單 28. 查看 JoinRowSet 中列名
for (int i = 1; i <= joinRS.getMetaData().getColumnCount(); i++) {
System.out.println(joinRS.getMetaData().getColumnName(i));
}
清單29. 清單 28 中的代碼執行結果
MergedCol
NAME
REMARK
USER_ID
PRODUCT
JoinRowSet 作為 CachedRowSet 的使用
從前面的繼承結構圖可以看到,JoinRowSet 繼續於 CachedRowSet。因此從理論上來看,JoinRowSet 也可以作為 CachedRowSet 來使用。但是其實 JoinRowSet 很多方法並不是簡單的直接繼承 CachedRowSet 中的方法,而是重寫(Override)了這些方法。最典型的兩個方法是 execute 和 populate。 前面已經提到過,這是兩種填充一個 CachedRowSet 的方法。但是對於 JoinRowSet,這兩個方法卻不起作用,不應該被使用。
另外一個比較特殊的方法是 acceptChanges。當 JoinRowSet 中包含一個 CachedRowSet 的時候,這個方法可以使用,並且效果就相當於在裡面的這個 CachedRowSet 裡面調用。但是當 JoinRowSet 包含兩個或多個 RowSet 的時候,這個方法就不起作用了。這就類似於數據庫多表聯結後形成的視圖(View),一般是不能夠進行更新操作的。
應注意的問題
雖然 JoinRowSet 提供了五個不同的 addRowSet 方法,但是並不是對於每個 RowSet 這五個方法都是可行的。這點前面已經提到過。
程序不能依賴 JoinRowSet 中的數據的順序。JoinRowSet 接口中並沒有能夠控制連接結果排序的方法。它只能保證最後連接結果的正確性,但不能保證順序。
當把一個 RowSet 加入到 JoinRowSet 中,這個作為 addRowSet 方法的參數的 RowSet 的指針位置可能發生變化。另外當這個 RowSet 是 JdbcRowSet 的時候,在通過 addRowSet 方法加入之前,如果該 JdbcRowSet 的指針位置發生變化的時候,也會影響聯合的結果。請看下面這個例子(假設我們已經像前面一樣構造好了一個 CachedRowSet 和一個 JdbcRowSet):
清單 30
// 添加cachedRS.
JoinRowSet joinRS = new JoinRowSetImpl();
joinRS.addRowSet(cachedRS, "ID"); //$NON-NLS-1$
// 在添加jdbcRS之前,改變指針的位置。
jdbcRS.next();
jdbcRS.setMatchColumn("ID"); //$NON-NLS-1$
joinRS.addRowSet(jdbcRS);
// 觀察結果
printRowSet(joinRS);
清單 31. 清單 30 中的代碼執行結果
The data in CachedRowSet:
2 Jim null 1 Compute
由於 jdbcRS 在加入之前,指針位置發生了變化,導致聯結後的結果不一樣了。實際上,由於 jdbcRS 是保持數據庫連接的,所以一般只能夠進行查看下一條數據的操作,而不能查看已經前面的數據,所以當把一個 JdbcRowSet 加入到 JoinRowSet 中時,我們只相當於對這個 JdbcRowSet 從當前位置開始的數據進行了聯結操作,而忽略了處於當前指針位置前面的數據。
那麼,對於 CachedRowSet,情況又是怎麼樣呢?
清單 32
// 添加jdbcRS.
JoinRowSet joinRS = new JoinRowSetImpl();
jdbcRS.setMatchColumn("ID"); //$NON-NLS-1$
joinRS.addRowSet(jdbcRS);
// 在添加cachedRS之前,改變指針的位置。
cachedRS.last();
joinRS.addRowSet(cachedRS, "ID"); //$NON-NLS-1$
// 結果. 此時JoinRowSet中的數據。
printRowSet(joinRS);
清單 33. 清單 32 中的代碼執行結果
The data in CachedRowSet:
2 1 Compute Jim null
1 1 Book Tom Tom is VIP.
由此可見,即使 cachedRS 在加入之前,指針位置發生了變化,也不會影響聯結的結果。這是因為 CachedRowSet 是離線的,可以前後滾動查看數據。
結束語
本文介紹了 javax.sql.rowset 包下五個 RowSet 接口的使用,並重點說明了在使用中可能出現的問題。合理利用 RowSet 提供的離線式數據處理功能可以達到事半功倍的效果。
文章來源:
http://www.ibm.com/developerworks/cn/java/j-lo-java6rowset/