pureQuery 是一種高性能 Java™ 數據訪問平台,其目標主要是簡化數據訪問應用程序的開發和管理。它由工具、API 和運行時組成。本文介紹 pureQuery 帶注釋的方法風格 —— 這是一種簡單、靈活的風格,屬於命名查詢(named-query)范例,可以靜態或動態地執行 SQL。本文先解釋為什麼開發人員要選擇使用帶注釋的方法風格編寫 pureQuery 應用程序,再解釋帶注釋的方法風格與 pureQuery 內聯編程風格之間的差異,並簡要概述 pureQuery 帶注釋的方法的強大特性。
概述
本文討論與帶注釋的方法的編程風格相關的以下主題:
描述帶注釋方法的編程風格
選擇使用帶注釋方法編程風格的原因
使用帶注釋的方法風格開發 pureQuery 應用程序的步驟(立即閱讀該 小節)。
描述代碼生成,給出生成的代碼示例
描述在 pureQuery 接口中定義帶注釋的方法的需求
使用 pureQuery 接口執行 SQL
介紹帶注釋的方法風格的一些選擇特性,例如批處理、生成的 RowHandlers 和 ParameterHandlers、生成的鍵以及使用 XML 配置文件修改代碼生成器的輸出
如果您已經准備好開始編程,那麼可以跳到 技術性崩潰。接下來介紹一個簡單的例子展示為什麼開發人員要選擇使用帶注釋的方法風格開發 pureQuery 應用程序。
什麼是帶注釋的方法編程風格?
為了介紹帶注釋的方法編程風格,首先需要理解這兩種 pureQuery 編程風格的背景知識。
內聯編程風格 的開發目的是為了滿足客戶對快捷、簡便的編程風格的需求,這種風格很容易被熟悉 Java™ Database Connectivity(JDBC)的開發人員掌握 —— 其特點就是可以更快、更簡單地編程。內聯風格最初的目標是減少 JDBC 程序員熟悉的一些重復的編程任務,同時提供一個 API,工具可以輕松地利用該 API 將數據訪問開發與 Java 開發聯系在一起。由於應用程序中定義 SQL 語句的方式,這種編程被稱作 “內聯”。在內聯風格中,SQL 語句是在運行時聲明或構造的,並作為 String 的實例傳遞給公共的 Data 接口方法。內聯風格可以最大化編程速度和開發靈活性,並支持動態執行。後期文章將提供對公共 Data 接口 API 的概述。關於內聯風格的更多信息,可以在 pureQuery 文檔中找到(參見 參考資料)。
本文主要討論帶注釋的方法編程風格,這種風格的演化和內聯編程風格相似,但是它還有另外一個目標,那就是最大化編寫的 pureQuery 應用程序的可配置性和安全性。帶注釋的方法風格是專門為同時支持動態和靜態數據庫訪問而設計的。其目的是滿足對類似於 Java Persistence API(JPA)的用於數據訪問的命名查詢編程接口的客戶需求 —— 更快、更簡單地編程,必要時能夠支持靜態執行。
與內聯編程風格一樣,帶注釋的方法也起源於應用程序定義 SQL 語句的方式。在帶注釋的方法風格中,SQL 字符串被定義為 Java 5.0 的一個元素:pureQuery Annotation。pureQuery 為此目的定義的方法注釋有 @Select (注釋 SQL 查詢)、 @Update (注釋 SQL DML 語句)和 @Call (注釋 SQL CALL 語句)。這些注釋被放在用戶定義接口內的用戶定義方法聲明中。代碼生成器預處理接口,為每個已聲明的、帶有注釋的方法生成實現代碼。生成的實現代碼使用 pureQuery 運行時執行注釋中定義的 SQL 語句。在注釋元素中預先定義 SQL 字符串,可以簡化靜態執行支持。
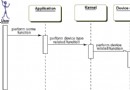
Data Studio 對帶注釋的方法風格的工具支持包括一個代碼生成器,它可以創建用戶編寫的帶注釋的方法的實現。代碼生成的結果就是第二個實現類,該實現類被編譯並用於執行初始接口中聲明的 SQL 語句。圖 1 說明了用戶定義的帶注釋的方法接口、代碼生成器和生成的實現類之間的關系。
圖 1. pureQuery 帶注釋的方法的代碼生成

一個有趣的例子
本節介紹一個虛構的例子:Silver Castles 的數據訪問開發小組,Silver Castles 是一家正在不斷發展的公司,銷售各種銀制產品。該公司正在 Silver Castles 網站上開發一個新的基於 Web 的店面,並且已經決定使用 pureQuery 環境來開發數據訪問應用程序的持久層。當他們觀看了 pureQuery 工具演示 並閱讀了 pureQuery 教程 之後,很快就決定使用 pureQuery。他們了解到,使用 motivating 快速開發、測試和部署用於多平台的基於 Java 的數據訪問持久層非常容易。當這個小組決定何時使用帶注釋的方法編程風格、何時使用內聯編程風格時,還會受到其他一些因素的影響。有一個叫做 Bob 的開發人員決定成為帶注釋的方法編程風格方面的專家。他收集了一些知識,以幫助小組決定何時使用這兩種編程風格,後面介紹了這些知識。
決定使用帶注釋的方法
Bob 首先審視了帶注釋的方法編程風格。幾小時後,他回到小組,並給出一份清單,上面列出帶注釋的方法風格的一些亮點。
范例:
遵從命名查詢的風格,目標是等同或超過現有對象-關系映射器和持久化解決方案的功能
鼓勵將持久層(CRUD)語句與應用程序在帶注釋接口中的其余部分分離。其結果是,開發中對 SQL 語句的更改不會擴散到整個應用程序,也不會影響負責其他層的開發人員。帶注釋的接口為管理整個應用程序的 SQL 語句提供一個集中控制點。
SQL 語句文本是在開發時知道的。但是可以提前對 SQL 語句文本進行分析,以便開發人員優化輸出對象的分配。
靜態支持:
pureQuery 帶注釋的方法編程風格使得執行靜態 SQL 成為一個部署選項,而不是設計選項。帶注釋的方法代碼可以動態地部署,也可以使用 IBM Data Servers 上的靜態 SQL 包來部署,而不必修改任何代碼
從應用程序開發人員和前端應用程序的角度透明轉換到靜態執行。
選擇針對靜態執行進行部署可以獲得靜態 SQL 的全部好處:安全、性能、監控和預運行時優化。
代碼生成:
最小化手動編寫代碼:先聲明接口方法簽名和 SQL 語句,然後由 pureQuery 代碼生成器產生數據訪問代碼實現。
返回查詢結果,由 pureQuery 預處理為多種對象,例如已填充的 pureQuery bean 的 Iterators,或者列名的 Lists,或者列值 Maps。
要對數據訪問進行預處理和後處理,使用 Hook 定制生成的代碼的行為。
使用 XML 配置文件 為每個目標數據庫定義不同的 SQL。
開發和使用帶注釋的方法
下面的清單 1 顯示了 Bob 編寫的 pureQuery 接口的一部分,親自體驗帶注釋的方法風格。他使用該接口向小組成員解釋帶注釋的方法風格的基礎。pureQuery 帶注釋的接口是帶注釋的方法風格的構建塊。pureQuery 接口由以下部分組成:
一個 Java interface 定義包含:
一個或多個方法聲明
對於每個方法聲明,有一個 pureQuery 數據訪問注釋 - @Select、@Update 或 @Call。每個注釋包括一個 SQL 語句,其中包含方法被調用時要執行的 SQL 語句(也可以選擇在一個配置文件、而不是注釋元素中提供該 SQL 語句)。
對於每個方法聲明,有一個 Java 返回類型,表明 pureQuery 運行時將數據訪問結果返回給調用者時需要使用的對象格式。
對於每個方法簽名,有一些 Java 參數類型,包括表明用於執行 SQL 語句的參數的對象類型。
除了以上描述的那些方法聲明或定義外,接口定義文件不包含任何其他方法聲明或定義。定義好 pureQuery 接口之後,應用程序的其他層在概念上可以將該接口當作一個數據庫 —— 可以很容易地通過調用聲明的 Java 數據訪問方法來從 Java 中訪問。當另一個應用程序層調用一個帶注釋的方法時,它將收到執行相關聯的 SQL 語句的結果,形式為一個適當格式化的 Java 對象。開發其他應用程序層時,不需要 SQL 方面的知識。
清單 1. pureQuery 帶注釋的方法風格的接口
package com.ibm.db2.pureQuery;
import java.util.Iterator;
import com.ibm.pdq.annotation.Select;
public interface CustomerData {
// Select all PDQ_SC.CUSTOMERs and populate Customer beans with results
@Select(sql="select CID, NAME, COUNTRY, STREET, CITY, PROVINCE, ZIP, PHONE,
INFO from PDQ_SC.CUSTOMER")
Iterator<Customer> getCustomers();
// Select PDQ_SC.CUSTOMER by parameters and populate Customer bean with results
@Select(sql="select CID, NAME, COUNTRY, STREET, CITY, PROVINCE, ZIP, PHONE,
INFO from PDQ_SC.CUSTOMER where CID = ?")
Customer getCustomer(int cid);
...
}
生成一個實現
定義好上述接口後,Data Studio 中的 pureQuery 項目工具自動將它提供給 pureQuery 代碼生成器。pureQuery 代碼生成器產生該接口的一個實現,放在一個名為 CustomerDataImpl.java 的文件中。為便於讀者查看,清單 2 中給出了生成的文件。注意:生成的文件中的所有代碼(清單 2)都不是由開發人員手動編寫的。
您不需要查看生成的代碼。如果您想看看 Silver Castle 應用程序如何使用以上接口,可以跳到 下一步。接下來,了解更多關於生成的代碼的信息。
代碼生成器和生成的代碼
代碼生成器以用戶定義的 pureQuery 接口為輸入,例如由 SilverCastles 開發人員定義的簡單的 CustomerData。它生成的代碼用來執行針對接口中每個方法進行注釋的每個 SQL 語句。它還生成用於將結果處理為所聲明類型的代碼。生成的代碼調用 pureQuery 運行時來執行每個方法所需的處理。
關於生成的代碼有一些重要的注意事項:
生成的元素:對於每個聲明的方法,生成的元素包括方法定義、一個內部 pureQuery StatementDescriptor、一個生成的 RowHandler 或 ResultHandler ,以及一個內部 pureQuery ParameterHandler。
實現類名稱:生成的實現文件的名稱以初始的用戶定義接口的名稱為基礎,在名稱後面加上 “Impl”。在這個例子中,開發人員編寫了 CustomerData 接口,代碼生成器產生 CustomerDataImpl 類。生成的類實現 CustomerData 接口。數據訪問應用程序的其他層不會使用實現類的名稱;它們總是引用和使用用戶定義接口。但是,知道實現文件的名稱還是有用的,以便檢查生成的代碼。
實現超類:除了實現用戶定義接口外,生成的實現類還擴展內部的 pureQuery 類 BaseData,後者實現外部的 Data 接口。這個超類是 pureQuery 運行時的一部分,負責處理訪問數據庫和處理結果的固定的、重復的操作。
看到生成的代碼時,不要感到困惑。開發人員不需要查看這些代碼,除非他們執意要這麼做。
使用帶注釋的方法
至此,項目已經構建完畢,Data Studio pureQuery 工具已經調用了 pureQuery 代碼生成器,並且接口實現也已經生成並編譯。開發人員現在可以通過調用 pureQuery 帶注釋的接口中聲明的帶注釋的方法,從應用程序的其他層訪問數據。這個過程很簡單。應用程序通過發送給 DataFactory 的一個請求實例化 pureQuery 接口的一個實例(概念上的數據庫)。然後,它調用數據訪問方法,如下所示:
清單 3. 調用帶注釋的方法
...
java.sql.Connection con = ...;
// use the DataFactory to instantiate the CustomerData interface
CustomerData cd = DataFactory.getData(CustomerData.class, con);
// execute the SQL for getCustomers() and get the results in Customer beans
Iterator<Customer> cust = cd.getCustomers();
// the application can now consume the Iterator of Customer beans
...
通過幾行代碼,就訪問了數據庫,執行了所需的 SQL 語句,並將結果處理成方便的 Customer 類的數據 bean 的 Iterator,因此應用程序可以直接使用。更加令人印象深刻的是,即使要實現持久層方法,開發人員也只需聲明這裡所調用的方法。pureQuery 代碼生成器和運行時會處理其余的工作。
分解帶注釋的方法風格
本節將這個示例分解成帶注釋方法編程風格的幾個重要組成部分。pureQuery 文檔包含對這些和其他 pureQuery 編程概念的完整描述(參見 參考資料)。
pureQuery 接口
在以上例子中,用戶定義的 pureQuery 接口被命名為 CustomerData。合理地命名接口,以反映它所代表的信息源,這樣做很有幫助,如 Silver Castles 示例一樣。例如,CustomerData 方法檢索和更新關於公司客戶的信息。
如上所述,pureQuery 接口只包含帶注釋的方法的聲明。
帶注釋的方法的聲明
pureQuery 接口中的每個方法聲明包含以下必要元素:
三個 pureQuery 注釋中的一個:@Select、@Update 或 @Call
對於每個注釋,有一個 sql=<string> 元素,其中的 string 包含一個有效的 SQL 語句,這個 SQL 語句將在方法被調用時執行(可選地,也可以在一個 XML 配置文件中提供 SQL 語句)。
一個標准的 Java 方法聲明
已聲明的返回類型
方法聲明的返回類型表明 SQL 語句的結果返回什麼樣的對象格式。取決於所使用的注釋,受支持的返回類型有所不同。例如,對於查詢,可以返回各種集合和簡單類型。對於更新,可以使用標准的更新計數格式。除了其他格式外, StoredProcedureResult 返回類型可以方便地封裝存儲過程調用的結果。
還可以由 pureQuery 引擎將結果處理成用戶定義 pureQuery bean 的一個集合。在我們的示例中,開發人員聲明的返回類型是 Customer bean 的一個 Iterator。pureQuery 使用一組 bean 約定和需求 將數據庫查詢結果直接映射到用戶定義的 bean 類。pureQuery bean 中的注釋 可以覆蓋默認的映射行為。而且,可以由用戶提供的 RowHandler 將結果手動映射到 bean。否則,生成的 RowHandler 將在把 bean 結果返回給調用者之前,自動執行默認的映射,將結果映射到用戶定義的 bean 類。
聲明的參數類型
帶注釋的方法聲明中的參數類型決定 pureQuery 如何在運行時獲得 SQL 語句參數值。SQL 語句中的參數占位符與帶注釋的方法中聲明的參數之間可能存在一對一的映射,但是也不一定如此。pureQuery 遵從 參數占位符語法規則 來決定如何從帶注釋的方法的參數列表中聲明的參數映射 SQL 語句參數。
與其他數據訪問 API 相比,pureQuery 中的參數可以采用更多種類的類型。例如,一個聲明的 pureQuery bean 參數可以為 一些 SQL 語句參數占位符 提供運行時值。對於 pureQuery 帶注釋的方法,pureQuery bean 和 Java 集合類型都受支持。請查看帶注釋的方法 語法圖,以獲得可能聲明的參數類型的完整列表。帶注釋方法的聲明的參數類型可以在很大程度上影響 SQL 語句的執行。例如,可以通過使用帶注釋的方法 @Update 中的某些參數類型發起批量更新。對於批量更新,需要使用一個集合參數多次執行一條 SQL 語句,每次執行時使用不同的參數值。
帶注釋的方法的參數可以直接使用,也可以賦給變量,以利用 pureQuery 引擎的特定處理功能。批量更新處理是 pureQuery 引擎底層自動優化代碼和改進開發的一個例子。對數據 bean 參數的特殊 pureQuery 處理還可以節省開發時間和精力。例如, @GeneratedKey pureQuery bean 注釋使 pureQuery 引擎可以用插入或更新操作後生成的數據庫值自動更新 bean 參數的字段。
Hook
由於大多數代碼都是使用帶注釋的方法的風格生成的,pureQuery 開發小組中有些人一開始有所顧慮。Bob 解釋道, Hook 在執行生成的代碼期間為進行特殊處理提供了一種簡單的方法。現在不需要手動編寫方法調用,以便將每個應用程序調用圍繞一個帶注釋的接口方法,而是采用另一種方法,定義一個 Hook 以注冊到帶注釋的接口。在進入和退出每個帶注釋的方法時,pureQuery 運行時回調 Hook。這提供了一種回調機制,以便將生成的數據訪問代碼與特殊的處理關聯起來。Hook 定義所需的 pre() 方法,Hook 進行注冊後,在進入一個帶注釋的方法時得到調用。每個 Hook 還將定義一個 post() 方法,當該 Hook 注冊後,在從一個帶注釋的方法返回控制之前,該方法會被立即調用。
Hook 方法為特殊的運行時回調處理提供上下文感知,以防 pre() 和 post() 的用戶定義實現需要它。這種感知是通過 pre() 和 post() 方法調用中的參數獲得的。可以根據這些參數的值設計不同的特殊處理。例如,取決於調用 Hook 方法的接口方法的名稱、提供給那個方法的運行時參數值或者該方法執行的 SQL 語句類型的不同,處理也會有所不同。此外還以 Data 參數的形式提供了 Hook 所注冊的 pureQuery 接口的一個句柄。這些值都可以供 Hook 的實現者查看和修改。此外,返回值在被返回給調用者之前,還可以供 post() 方法的實現者使用。下面是 Bob 為了向 Silver Castles 小組進行演示而編寫的 Hook 處理代碼的一個例子:
清單 4. 用於特殊處理的 Hook
public static class TrackingHook implements Hook {
public void pre(String methodName, Data objectInstance,
SqlStatementType sqlStatementType, Object... parameters) {
System.out.println(methodName + "**Customer data has been accessed**");
}
public void post(String methodName, Data objectInstance,
Object returnValue, SqlStatementType sqlStatementType,
Object... parameters) {
// do nothing
}
}
至此,已經使用 Hook 定義了特殊的處理,開發人員可以通過向進行實例化的接口注冊他們的 Hook 的一個實例,以確保可以運行。清單 5 展示如何注冊一個 Hook:
清單 5. 注冊一個 Hook
...
Connection con = ...;
// use the DataFactory to instantiate the interface and
// provide an instance of Hook to be registered with the instance
CustomerData cd = DataFactory.getData(CustomerData.class, con, new TrackingHook());
// execute the SQL for getCustomers() and get the results,
// the pre() and post() methods are automatically called
Iterator<Customer> cust = cd.getCustomers();
// the application now consumes the Iterator of Customer beans
...
這是有關 Hook 的特殊處理的一個非常簡單的例子。請參閱 pureQuery 文檔中的 Hook 示例,以查看可以使用 Hook 實現的更復雜的類型示例。
針對多目標的開發
Bob 向他的小組解釋了帶注釋的方法的最後一個特性,使用 XML 配置文件 將 SQL 語句與應用程序的 Java 代碼實現完全分離。這樣一來,當將 Java 應用程序部署到一個要求不同 SQL 語句的目標數據庫時,就可以避免重復編寫該 Java 應用程序。例如,如果小組想將同一個應用程序部署到一個遺留數據源上,且該數據源使用稍有不同的模式,那麼他們不需要重新編寫帶注釋的接口或 pureQuery bean。
清單 6 展示了用於初始模式的 SQL 語句。
清單 6. 用於初始模式的 SQL 語句
select CID, NAME, COUNTRY, STREET, CITY, PROVINCE, ZIP, PHONE, INFO
from PDQ_SC.CUSTOMER
清單 7 展示了用於遺留模式的 SQL 語句。
清單 7. 用於遺留模式的 SQL 語句
select CUSTID, NAME, COUNTRY, STREET, CITY, PROV, ZIP, PHONE, INFO
from PDQ_SC.CUSTOMER
注意,在清單 7 中,CID 和 PROVINCE 列的名稱變成了 CUSTID 和 PROV。這改變了用於發出查詢的 SQL 語句,也改變了從結果到 Customer 數據 bean 的默認映射。
清單 8 展示了 customer pureQuery bean。
清單 8. Customer pureQuery bean
package com.ibm.db2.pureQuery;
public class Customer {
// Class variables
protected int cid;
protected String name;
protected String country;
protected String street;
protected String city;
protected String province;
protected String zip;
protected String phone;
protected String info;
...
小組無需編寫新的帶注釋的接口或 Customer bean 類來支持遺留模式,只需使用一個 XML 配置文件向生成器提供附加的輸入,以支持遺留模式。下面列出了 XML 配置文件的一個片段,它展示了如何覆蓋一個 SQL 字符串和用戶定義 bean 類映射。為了將應用程序部署到遺留系統上,小組將初始的帶注釋的接口定義和下面的 XML 文件提供給生成器。生成器產生正確的生成代碼,從而部署到遺留數據庫上:
清單 9. 生成替換代碼的 XML 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<entity-mappings xmlns="http://java.sun.com/xml/ns/persistence/orm">
<named-native-query name=" com.ibm.db2.pureQuery.CustomerData#getCustomers()">
<query><![CDATA[select CUSTID, NAME, COUNTRY, STREET, CITY, PROV, ZIP, PHONE, INFO
from PDQ_SC.CUSTOMER]]>
</query>
</named-native-query>
...
<entity class="com com.ibm.db2.pureQuery.Customer">
<attributes>
<basic name="cid">
<column name="CUSTID" />
</basic>
...
<basic name="province">
<column name="PROV" />
</basic>
...
</attributes>
</entity>
</entity>
</entity-mappings>
結束語
本文概要地介紹了 pureQuery 帶注釋的方法編程風格,以及開發小組選擇使用 pureQuery 帶注釋的方法進行編程的動機。本文還列出了開發帶注釋的方法風格的應用程序所需的步驟。另外也介紹了這種風格的部分特性。
如果您有興趣進一步了解如何開發 pureQuery 帶注釋的方法風格的應用程序,請訪問本文正文和參考資料小節中提供的 pureQuery 在線文檔、其他文章和相關教程的鏈接。