在本系列(共三篇文章)的 第 1 部分 和 第 2 部分 中,我介紹了監控 Java 應用程序的技巧和模式,在這兩部分中我把重點放在了 JVM 和應用程序類上。在這最後一期中,我將介紹從應用程序的依賴項(諸如底層操作系統、網絡或者應用程序的後端數據庫)收集性能與可用性數據的技巧。在文章結尾我將論述管理收集數據的模式以及報告和可視化數據的方法。
基於 Spring 的收集器
在 第 2 部分 中,我實現了一個用於管理監控服務的基本的基於 Spring 的組件模型。該模型的基本原理及益處有:
使用基於 XML 的配置,使得管理大量用於配置更復雜性能數據收集器的參數集變得更加容易。
采用關注點分離 的結構,這樣就可以使用更簡單的組件,這些組件之間的相互交互可以通過注入 Spring 的依賴項來實現。
Spring 給簡單的收集 bean 提供了一個生命周期,該周期由初始化、啟動 和停止 操作組成,還提供了將 Java 管理擴展(Java Management Extension,JMX)管理接口公開給 bean 的選項,這樣就可以在運行時進行控制、監控和故障排除。
下面我將在本文的每個小節中介紹有關基於 Spring 的收集器的更多細節。
監控主機和操作系統
Java 應用程序總是運行於底層硬件和支持 JVM 的操作系統之上。一個全面的監控基礎設施中最關鍵的組成就是從硬件和 OS — 通常是通過 OS 收集 — 那裡收集性能、健康狀況和可用性指標的能力。本節就涵蓋了一些通過在 第 1 部分 中介紹的 ITracer 類獲取這類數據並一直跟蹤到應用程序性能管理系統(application performance management,APM)的技巧。
典型的 OS 性能指標
下面這份摘要列出了典型指標,這些指標跨域操作系統的多個部分相關。雖然數據收集的細節迥異,而且數據的解釋也必須在給定的 OS 上下文中進行,但是這些指標在大多數標准主機上基本都是等效的:
CPU 使用:表示特定主機上的 CPU 的占用情況。單位通常為百分比的使用率,在較低的級別將 CPU 忙碌時間表示為消逝的時鐘時間的某個特定時期的百分比。主機可以有多個 CPU,而 CPU 又可以包含多個內核,但多個內核通常都被 OS 抽象出來代表一個 CPU。例如,一個帶有兩個雙核 CPU 的主機會被說成有四個 CPU。指標通常可以按照每個 CPU 收集或者作為總資源利用率收集,後者表示所有處理器的總體使用情況。到底是要分別監控每一個 CPU 還是監控總體 CPU,通常要取決於軟件的本質及其內部架構。標准的多線程 Java 應用程序通常默認平衡所有 CPU 上的負載,所以監控總體較合適。但在某些情況下,個別 OS 進程是 “特定於” 特定 CPU 的,這時總體指標可能無法捕獲到適當級別的粒度。
CPU 的使用通常被拆分成四個范疇:
系統:執行系統的或者 OS 內核級的活動耗費的處理器時間
用戶:執行用戶活動耗費的處理器時間
I/O 等待:處於空閒狀態等待完成某個 I/O 請求耗費的處理器時間
空閒:暗指沒有進行任何處理器活動
另外兩個相關指標為運行隊列長度(即等候 CPU 時間的請求的待處理事項)和上下文轉換(即將處理器時間分配從一個進程轉換到另一個進程的實例)。
內存:最簡單的內存指標為可用或使用中的物理內存的百分比。其他需要考慮的有虛擬內存、內存分配率和重新分配率以及表明內存有哪些區域被使用的更細粒度的指標。
磁盤與 I/O:磁盤指標為每一個邏輯或物理磁盤設備的可用或使用中的磁盤空間的簡單(但是至關重要的)報告,還有這些設備的讀取和寫入速率。
網絡:指網絡接口上的數據傳輸速率和錯誤發生率,它通常被分為高級的網絡協議范疇,如 TCP 和 IP。
進程與進程組:可以說前面所述的指標都是特定主機的總活動。它們也可以劃分為相同的指標,但是代表個別進程或相關進程組的消耗或活動。監控進程對資源的使用情況有助於解釋主機上的每一個應用程序或者服務消耗的資源比例。有些應用程序只可以實例化一個進程;在其他情況下,一個諸如 Apache 2 Web Server 這樣的服務可以實例化代表一個邏輯服務的一群進程。
代理與無代理
不同的 OS 有著不同的性能數據獲取機制。我將呈現的收集數據的方式很多,但是在監控領域您可能經常要區別的是基於代理的 和無代理的 監控。也就是說在某些情況下,無需在目標主機上安裝其他特定的軟件也可以收集數據。但顯然監控通常都會涉及到某種代理,因為監控總是需要一個接口,數據要通過它來讀取。所以這裡真正區別的是是使用通常出現在給定 OS 中的代理 — 諸如 Linux® 服務器上的 SSH — 還是安裝其他專用於監控和使收集的數據對外部收集器可用的軟件。兩種方法都涉及到如下的權衡標准:
代理需要安裝其他的軟件並可能需要應用定期的維護補丁。在帶有大量主機的環境中,管理軟件工作不利於使用代理。
如果代理實際上是與應用程序相同的進程的一部分的話,哪怕它是一個單獨的進程,代理進程的故障也將會蒙蔽監控。雖然主機本身仍在運行且健康狀況良好,但是 APM 一定會因為無法到達代理而假定主機已停機。
安裝在主機上的代理可能要比無代理遠程監控器的數據收集能力和事件監聽能力強得多。而且,報告總體指標可能需要收集好幾個原始底層指標,遠程收集這些指標的效率會很低。而本地的代理則能夠快速地收集數據,再合計數據,然後將合計的數據提供給遠程監控器。
歸根結底,最佳的解決方案可能就是既實現無代理的監控又實現基於代理的監控:本地代理負責收集大多數指標,而遠程監控器負責檢查諸如服務器的運行情況和本地代理的狀態這樣的基本內容。
代理也可以有不同的選項。自治 代理按照自己的計劃收集數據,反之,響應 代理按請求遞送數據。此外,有些代理只將數據提供給請求程序,而有些則直接或間接地跟蹤數據一直到 APM 系統。
接下來我將呈現監控帶有 Linux 和 UNIX® OS 的主機的技巧。
監控 Linux 和 UNIX 主機
監控代理可以用來實現專門的本機庫以從 Linux 和 UNIX OS 收集性能數據。但是 Linux 和大多數 UNIX 變體都有很多內置數據收集工具,這些工具使得數據可以通過稱為 /proc 的虛擬文件系統進行訪問。該文件看起來像是普通文件系統目錄裡面的普通文本文件,但其實它們是常駐內存型數據結構,是通過文本文件抽取的。由於這種數據可以很容易地通過大量標准命令行的實用工具或自定義的工具來讀取和解析,所以這些文件較易於使用,而且它們的輸出既可以是通用的也可以是專用的。而且它們的性能也非常好,因為本質上它們是直接來源於內存的數據。
常見的用於從 /proc 中抽取性能數據的工具是 ps、sar、iostat 和 vmstat(參見 參考資料 查閱有關這些工具的參考文獻)。因此,一個有效地監控 Linux 和 UNIX 主機的方法就是執行 shell 命令並解析響應。類似的監控器可以用於很多種 Linux 和 UNIX 實現;雖然它們之間都有著些許差異,但是,使用一種可以完全重用收集過程的方式格式化數據是很簡單的。相反,專用的本機庫可能要根據每一個 Linux 和 UNIX 發行版而進行重編碼或重構(但它們正在讀取的 /proc 數據有可能相同)。而編寫專用於監控某一特定情況或可以標准化返回數據的格式這樣的自定義 shell 命令很容易,並且開銷較低。
現在我將展示幾種調用 shell 命令和跟蹤返回數據的方法。
Shell 命令的執行
要在一個 Linux 主機上執行數據收集監控,就一定要調用一個 shell。它可以是 bash、csh、ksh 或其他任何允許調用目標腳本或命令並可以檢索輸出的、受支持的 shell。最通常的選擇包括:
本地 shell:如果目標主機上運行著 JVM 的話,那麼線程可以通過調用 java.lang.Process 來訪問這種 shell。
遠程 Telnet 或 rsh :這兩個服務都允許調用 shell 和 shell 命令,但由於它們的安全性相對較低,所以很少使用它們。它們在大多數現代發行版上的默認狀態為禁用。
安全 Shell(SSH):SSH 是最為常用的遠程 shell。它提供了對 Linux shell 的完全訪問,而且被公認是安全的。在文中基於 Shell 的例子裡,我將主要使用該機制。大多數 OS 都提供 SSH 服務,包括所有 UNIX 系列、Microsoft® Windows®、OS/400 及 z/OS。
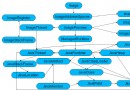
圖 1 展示了本地 shell 與遠程 shell 的基本差異:
圖 1. 本地 shell 與遠程 shell
要用服務器啟動一個無人值守的對話需要進行一些設置。首先必須要創建一個由私鑰和公鑰組成的 SSH 密匙對。然後將公鑰置於目標服務器,私鑰置於遠程監控服務器 —— 數據收集器可以在此獲取該私鑰。完成上述操作之後,數據收集器便能夠提供私鑰及其密碼短語(passphrase),並能夠訪問目標服務器上的安全遠程 shell 了。使用了密匙對之後,目標帳戶的密碼就是多余的了,根本不需要它。具體設置步驟如下:
確保目標主機在本地的已知主機的文件中有入口。這個文件列出了已知 IP 地址或名稱以及為每一個已知 IP 地址或名稱驗證的相關 SSH 公鑰。在用戶級別,該文件通常為用戶主目錄中的 ~/.ssh/known_hosts 文件。
用監控帳戶(例如,monitoruser)連接到目標服務器。
在主目錄中創建一個名為 .ssh 的子目錄。
將目錄改為 e .ssh 目錄並發布 ssh-keygen -t dsa 命令。該命令提示密鑰名和密碼短語。然後會生成兩個叫做 monitoruser_dsa(私鑰)和 monitoruser._dsa.pub(公鑰)的文件。
將私鑰復制到一個安全的可訪問的位置,數據收集器將從這個位置運行。
用 cat monitoruser_dsa.pub >> authorized_keys 命令將私鑰內容追加到 .ssh 目錄中名為 authorized_keys 的文件中。
清單 1 展示了我剛才所描述的過程:
清單 1. 創建一個 SSH 密匙對
whitehen@whitehen-desktop:~$ mkdir .ssh
whitehen@whitehen-desktop:~$ cd .ssh
whitehen@whitehen-desktop:~/.ssh$ ssh-keygen -t dsa
Generating public/private dsa key pair.
Enter file in which to save the key (/home/whitehen/.ssh/id_dsa): whitehen_dsa
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in whitehen_dsa.
Your public key has been saved in whitehen_dsa.pub.
The key fingerprint is:
46:cd:d4:e4:b1:28:d0:41:f3:ea:3b:8a:74:cb:57:e5 whitehen@whitehen-desktop
whitehen@whitehen-desktop:~/.ssh$ cat whitehen_dsa.pub >> authorized_keys
whitehen@whitehen-desktop:~/.ssh$
現在數據收集器已經能夠使用 SSH 連接到目標 Linux 主機,該 SSH 連接名為 whitehen-desktop,它運行著 Ubuntu Linux。
這個例子的數據收集器將使用一個名為 org.runtimemonitoring.spring.collectors.shell.ShellCollector 的通用收集器類來實現。該類的一個實例將以 UbuntuDesktopRemoteShellCollector 這個名稱部署在一個 Spring 上下文中。但要完成整個過程還需要一些其他的依賴項:
需要有一個調度器來每分鐘調用一次收集器。該調度器由 java.util.concurrent.ScheduledThreadPoolExeutor 的一個實例來實現,它既可以提供一個有計劃的回調機制,又可以提供一個線程池。這個調度器將以 CollectionScheduler 這個名稱部署於 Spring。
SSH shell 實現對服務器調用命令並返回結果。這個可以通過 org.runtimemonitoring.spring.collectors.shell.ssh.JSchRemoteShell 的一個實例來實現。這個類是一個名為 org.runtimemonitoring.spring.collectors.shell.IRemoteShell 的 Shell 接口的實現,它將以 UbuntuDesktopRemoteShell 這個名稱部署於 Spring。
該收集器不會硬編碼一組命令及其相關解析例程,而是使用 org.runtimemonitoring.spring.collectors.shell.commands.CommandSet 的一個實例,它將以 UbuntuDesktopCommandSet 這個名稱部署於 Spring 中。命令集從一個 XML 文檔載入,該文檔表述了:
將要用來執行 shell 的目標平台
將要執行的命令
將如何解析返回數據並將其映射到 APM 跟蹤命名空間
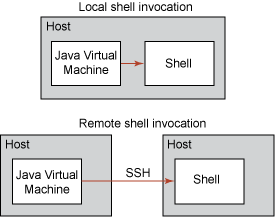
稍候我將提供有關這些定義的更多細節。圖 2 大致解釋了收集器、shell 和命令集三者之間的關系: 圖 2. 收集器、shell 和命令集
下面我將專門介紹一些關於專用於生成性能數據的命令以及它們的配置方法的簡短示例。一個經典的例子就是 sar 命令。Linux 手冊(參見 參考資料)對 sar 的定義是收集、報告或者保存系統活動信息。該命令非常靈活,它有超過 20 個參數,這些參數可以結合起來使用。一個簡單的選擇就是調用 sar -u 1 3,它報告了在三個時間間隔內(一個時間間隔為一秒)度量的 CPU 使用。清單 2 展示了它的輸出:
清單 2. sar 命令的輸出
whitehen@whitehen-desktop:~$ sar -u 1 3
Linux 2.6.22-14-generic (whitehen-desktop) 06/02/2008
06:53:24 PM CPU %user %nice %system %iowait %steal %idle
06:53:25 PM all 0.00 0.00 0.00 0.00 0.00 100.00
06:53:26 PM all 0.00 35.71 0.00 0.00 0.00 64.29
06:53:27 PM all 0.00 20.79 0.99 0.00 0.00 78.22
Average: all 0.00 18.73 0.33 0.00 0.00 80.94
該輸出可以劃分成開頭、標題、三個時間間隔的數據讀數和一個讀數匯總平均值。這裡的目標是要執行該 shell 命令、捕獲輸出,然後解析輸出並跟蹤到 APM 系統。輸出數據的格式是夠簡單的,但卻可能根據具體的版本而不同(輕微或顯著的不同),而且其他 sar 選項也會返回完全不同的數據(更不用說其他的命令了,它們當然會返回不同的數據格式)。例如,清單 3 展示了一個顯示活動的 socket 行為的 sar 執行:
清單 3. 顯示 socket 行為的 sar
whitehen@whitehen-desktop:~$ sar -n SOCK 1
Linux 2.6.22-14-generic (whitehen-desktop) 06/02/2008
06:55:10 PM totsck tcpsck udpsck rawsck ip-frag
06:55:11 PM 453 7 9 0 0
Average: 453 7 9 0 0
因此,現在所需要的是一個解決方案:怎樣在不重新編碼收集器的情況下快速配置不同的數據。還可以將諸如 totsck 這樣的含糊詞語翻譯成像 Total Used Sockets 這樣的更易讀的短語,以免收集到的記錄會干擾 APM 系統。
在某些情況下,您可以選擇以 XML 格式獲取這個數據。例如,SysStat 包(參見 參考資料)中的 sadf 命令會以 XML 格式生成很多被經常收集的 Linux 監控數據。XML 格式增加了數據的可預測性和結構,並真正排除了分析數據、將數據映射到跟蹤名稱空間和解碼模糊詞語的需要。然而,這些工具對於您想監控的可以訪問 shell 的系統可能是不可用的,因此需要一種靈活的文本解析和映射解決方案。
承接上面兩個關於 sar 的應用的例子,接下來我將呈現一個設置 Spring bean 定義以監控這些數據的例子。所有引用的例子都包含在本文的示例代碼中(參見 下載)。
首先,SpringCollector 實現的主要入口點為 org.runtimemonitoring.spring.collectors.SpringCollector。它采用了一個參數:Spring bean 配置文件所在的目錄的名稱。SpringCollector 載入了任何帶有 .xml 擴展名的文件,並將他們當作 bean 描述符。該目錄為位於項目根目錄中的 ./spring-collectors 目錄(稍後我將在本文中概述此目錄中的所有文件。有多個文件可以選擇,而且可以將所有的定義捆綁成一個,但要用虛構的函數單獨隔開,以保持一定的順序)。這個例子中的三個 bean 定義代表 shell 收集器、shell 和命令集。清單 4 展示了它們的描述符:
清單 4. shell 收集器、shell 與命令集的 Bean 描述符
<!-- The Collector -->
<bean id="UbuntuDesktopRemoteShellCollector"
class="org.runtimemonitoring.spring.collectors.shell.ShellCollector"
init-method="springStart">
<property name="shell" ref="UbuntuDesktopRemoteShell"/>
<property name="commandSet" ref="UbuntuDesktopCommandSet"/>
<property name="scheduler" ref="CollectionScheduler"/>
<property name="tracingNameSpace" value="Hosts,Linux,whitehen-desktop"/>
<property name="frequency" value="5000"/>
</bean>
<!-- The Shell -->
<bean id="UbuntuDesktopRemoteShell"
class="org.runtimemonitoring.spring.collectors.shell.ssh.JSchRemoteShell"
init-method="init"
destroy-method="close">
<property name="userName" value="whitehen"/>
<property name="hostName" value="whitehen-desktop"/>
<property name="port" value="22"/>
<property name="knownHostsFile"
value="C:/Documents and Settings/whitehen/.ssh/known_hosts"/>
<property name="privateKey"
value="C:/keys/whitehen/ubuntu-desktop/whitehen_dsa"/>
<property name="passphrase" value="Hello World"/>
</bean>
<!-- The CommandSet -->
<bean id="UbuntuDesktopCommandSet"
class="org.runtimemonitoring.spring.collectors.shell.commands.CommandSet">
<constructor-arg type="java.net.URL"
value="file:///C:/projects//RuntimeMonitoring/commands/xml/UbuntuDesktop.xml"/>
</bean>
清單 4 中的 CommandSet 只有一個 id(UbuntuDesktopCommandSet)和另一個 XML 文件的 URL。這是因為命令集太大,我不想因為它們而使 Spring 文件顯得很混亂。稍後我將描述 CommandSet。
清單 3 中的第一個 bean 為 UbuntuDesktopRemoteShellCollector。它的 bean id 值可以是任意的描述性的值,但是當從另一個 bean 引用該 bean 時需要保持一致。這個例子中的類為 org.runtimemonitoring.spring.collectors.shell.ShellCollector,它是一個通過類似於 Shell 的接口來收集數據的通用類。其他重要屬性有:
shell :收集器用來從 shell 命令調用和檢索數據的 shell 類的實例。Spring 用 UbuntuDesktopCommandSet 的 bean id 來注入該 Shell 的實例。
commandSet :代表一組命令和相關解析、跟蹤名稱空間映射指令的 CommandSet 實例。Spring 用 UbuntuDesktopRemoteShell 的 bean id 注入該命令集的示例。
scheduler :一個調度線程池的引用,該線程池管理數據收集的調度,將這項工作具體分配給一個線程來完成。
tracingNameSpace :跟蹤名稱空間的前綴,它控制著這些指標將被跟蹤到 APM 樹中的哪個位置。
frequency :數據收集頻率,以毫秒為單位。
清單 4 中的第二個 bean 為 shell,它是一個名為 org.runtimemonitoring.spring.collectors.shell.ssh.JSchRemoteShell 的 SSH shell 的實現。該類使用從 JCraft.com(參見 參考資料)下載的 JSch 來實現。它的其他重要屬性有:
userName :用戶用來連接到 Linux 服務器的名稱
hostName :連接到的 Linux 服務器的名稱(或 IP 地址)。
port :Linux 服務器端口,sshd 在這個端口上監聽。
knownHostFile :一個包含主機名稱和 SSH 服務器的 SSH 證書的文件,該 SSH 服務器對於運行 SSH 客戶機的本地主機是 “已知的”(有趣的是,SSH 中的這個安全機制恰好顛倒了傳統的安全結構,使用這種機制,除非主機是 “已知的” 並可以給出匹配的證書,否則客戶機不會信任主機,並拒絕連接)。
privateKey :用來驗證 SSH 服務器的 SSH 私鑰文件。
passPhrase :用來解鎖私鑰的密碼短語。它的外表與密碼類似,只是它沒有被傳送到服務器,而且它只用於本地解密私鑰。
清單 5 展示了 CommandSet 的內部細節:
清單 5. CommandSet 內部細節
<CommandSet name="UbuntuDesktop">
<Commands>
<Command>
<shellCommand>sar -u 1</shellCommand>
<paragraphSplitter>\n\n</paragraphSplitter>
<Extractors>
<CommandResultExtract>
<paragraph id="1" name="CPU Utilization"/>
<columns entryName="1" values="2-7" offset="1">
<remove>PM</remove>
</columns>
<tracers default="SINT"/>
<filterLine>Average:.*</filterLine>
<lineSplit>\n</lineSplit>
</CommandResultExtract>
</Extractors>
</Command>
<Command>
<shellCommand>sar -n SOCK 1</shellCommand>
<paragraphSplitter>\n\n</paragraphSplitter>
<Extractors>
<CommandResultExtract>
<paragraph id="1" name="Socket Activity"/>
<columns values="1-5" offset="1">
<remove>PM</remove>
<namemapping from="ip-frag" to="IP Fragments"/>
<namemapping from="rawsck" to="Raw Sockets"/>
<namemapping from="tcpsck" to="TCP Sockets"/>
<namemapping from="totsck" to="Total Sockets"/>
<namemapping from="udpsck" to="UDP Sockets"/>
</columns>
<tracers default="SINT"/>
<filterLine>Average:.*</filterLine>
<lineSplit>\n</lineSplit>
</CommandResultExtract>
</Extractors>
</Command>
</Commands>
</CommandSet>
CommandSet 負責管理 shell 命令和解析指令。由於每一個 Linux 或 UNIX 系統的輸出 —— 即便是對相同命令的輸出 —— 都會有些不同,因此每一種類型的受監控的主機通常都會有一個對應的 CommandSet。要使用 XML 詳述 CommandSet 背後的每一個選項,可能要占用很長的篇幅,因為它一直在不斷演變,而且會根據情況的不同而改變,因此我只簡短的概述一下其中一些標記,內容如下:
<shellCommand> :定義將要傳給 shell 的實際命令。
<paragraphSplitter> :有些命令,或組成多個命令鏈的命令,可能會返回多個文本片段。這些文本片段被稱為段落。正則表達式(regex)在這裡指定了劃分段落的標准。命令對象將結果分成多個段落,並將所需段落傳遞到底層提取器。
<Extractors> 和其中包含的 <CommandResultExtract> 標記:這些結構定義解析和映射。
<paragraph> :提取器使用 id 屬性中的基於零的索引來定義它想要從結果中抽取的段落,所有從該段落中跟蹤的指標都被歸入到以該段落名定義的跟蹤名稱空間中。
<columns> :如果定義了 entryName 的話,那麼每一行中編入索引的列都會被添加到跟蹤名稱空間。這是針對左側列包含一個指標分界的情況而言的。例如,sar 的一個選項將會分別為每一個 CPU 報告 CPU 使用,CPU 編號列於第二列中。在 清單 5 中,entryName 提取出 all 限定符,該限定符表明報告為所有 CPU 的總體匯總。values 屬性代表每一行中需要被跟蹤的行,而 offset 負責保持數據行中的列數和相應標題間的平衡。
<tracers> :它定義默認跟蹤類型,並允許為與指定的標題或 entryName 有關的值定義不同的跟蹤器類型。
<filterLine> :如果定義了它,regex 會忽略整行文本不匹配的數據行。
<lineSplit> :它定義用於解析每一個段落中各行的分隔 regex。
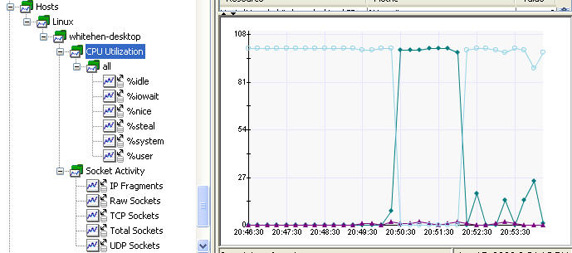
圖 3 展示了這個例子的 APM 樹:
圖 3. Ubuntu Desktop 監控的 APM 樹
如果不喜歡這個樹的外觀的話,您還有其他的選擇。發送到服務器的命令很容易修改,可以修改它們使其傳遞一連串的 grep、awk 和 sed 命令,以此來將數據重新格式化為很少需要解析的格式。例如,參見清單 6:
清單 6. 格式化命令內部的命令輸出
whitehen@whitehen-desktop:~$ sar -u 1 | grep Average | \
awk '{print "SINT/User:"$3"/System:"$5"/IOWait:"$6}'
SINT/User:34.00/System:66.00/IOWait:0.00
另外一個可以提供最佳配置、靈活性和性能的選擇就是使用動態腳本,這種方法在其他格式化工具不可用或輸出格式極其笨拙的情況下尤為適用。在接下來的例子中,我配置了一個 Telnet shell 用以從 Cisco CSS 負載均衡器中收集負載均衡狀態數據。輸出格式和內容對於任何種類的標准化解析來說都是很重要的問題,而這個 shell 支持的命令有限。清單 7 展示了命令的輸出:
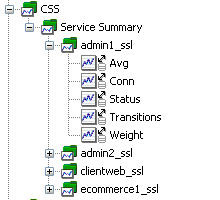
清單 7. CSS Telnet 命令的輸出
Service Name State Conn Weight Avg State
Load Transitions
ecommerce1_ssl Alive 0 1 255 0
ecommerce2_ssl Down 0 1 255 0
admin1_ssl Alive 0 1 2 2982
admin2_ssl Down 0 1 255 0
clientweb_ssl Alive 0 1 255 0
清單 8 展示了用於執行和解析命令的命令集。注意 <preFormatter beanName="FormatCSSServiceResult"/> 標記。它引用了一個包含幾行 Groovy 腳本的 Spring bean。Telnet shell 命令的原始輸出被傳給 Groovy 腳本,然後返回值以一種更友好的格式被傳給命令數據提取器。還要注意的是,為了標記為 Status 的列中的值,跟蹤器類型被覆蓋成了 STRING 類型。眼光尖銳的讀者將會注意到這個列不存在,但是 Groovy 腳本的一部分工作就是解決兩個列均使用 State 名的問題(您知道這其中的原委),所以 Groovy 腳本將第一個列重命名為 Status。
清單 8. CSS CommandSet
<CommandSet name="CiscoCSS">
<Commands>
<Command>
<shellCommand>show service summary</shellCommand>
<paragraphSplitter>\n\n\n\n</paragraphSplitter>
<preFormatter beanName="FormatCSSServiceResult"/>
<Extractors>
<CommandResultExtract>
<paragraph id="0" name="Service Summary" header="true"/>
<columns entryName="0" values="1-5" offset="0"/>
<tracers default="SINT">
<tracer type="STRING">Status</tracer>
</tracers>
<lineSplit>\n</lineSplit>
</CommandResultExtract>
</Extractors>
</Command>
</Commands>
</CommandSet>
Groovy bean 的益處有很多。首先,它的腳本是動態配置的,所以可以在運行時更改它。其次,該 bean 可以檢測出源發生了變更,並會在下一次調用它時調用 Groovy 編譯器,所以它的性能是足夠好的。此外,此種語言含有豐富的解析功能,且容易編寫。清單 9 展示了包含內聯源代碼文本的 Groovy bean:
清單 9. Groovy 格式化 bean
<bean id="FormatCSSServiceResult"
class="org.runtimemonitoring.spring.groovy.GroovyScriptManager"
init-method="init" lazy-init="false">
<property name="sourceCode"><value><![CDATA[
String[] lines = formatTarget.toString().split("\r\r\n");
StringBuffer buff = new StringBuffer();
lines.each() {
if(!(
it.contains("Load Transitions") ||
it.contains("show service summary") ||
it.trim().length() < 1)) {
buff.append(it).append('\n');
}
}
return buff.toString()
.replaceFirst("State", "Status")
.replaceFirst("Service Name", "ServiceName")
.replace("State", "Transitions");
]]></value>
</property>
</bean>
圖 4 展示了 CSS 監控的 APM 指標樹
圖 4. CSS 監控的 APM 樹
SSH 連接
最後一個要考慮的有關 Linux/UNIX shell 收集的問題就是 SSH 連接的問題了。所有 Shell 類的基本接口為 org.runtimemonitoring.spring.collectors.shell.IShell。它定義了一個名為 issueOSCommand() 的方法的兩種變體,命令在這個方法中被作為參數傳遞並且返回結果。在我的使用遠程 SSH 類 org.runtimemonitoring.spring.collectors.shell.ssh.JSchRemoteShell 的例子中,底層 shell 調用建立在 Apache Ant 中 SSHEXEC 任務的實現的基礎上(參見 參考資料)。這種方法的優點在於它很簡單,但是它有一個不可避免的缺點:要為每一個發出的命令創建一個新的連接。這顯然會降低效率。一個遠程的 shell 只可以每分鐘輪詢一次,但每一個輪詢周期可以執行幾個命令來獲取監控數據的適當范圍。問題是要在監控時窗期間(跨多個輪詢周期)保持開放會話是很難的。它需要更詳細地檢查和解析返回數據,提供不同的 shell 類型以及不斷顯示 shell 提示,當然 shell 提示不包括在預期返回值中。
目前為止,我一直努力處理長期存活的會話 shell 實現。另外一個選擇就是折衷:即為每一個輪詢周期模式保留一個連接,但同時試著用一個命令捕獲所有數據。這個可以通過追加命令或者(在某些情況下)通過對一個命令使用多個選項來實現。例如,我的 SuSE Linux 服務器上的 sar 版本擁有一個 -A 選項,該選項返回一個包含 sar 支持的所有指標的示例;該命令與 sar -bBcdqrRuvwWy -I SUM -n FULL -P ALL 等效。返回的數據將擁有多個段落,但是用一個命令集來解析它應該沒有問題。要查看這樣的例子,請參見本文中名為 Suse9LinuxEnterpriseServer.xml 的示例代碼中的命令集定義(參見 下載)。
監控時窗
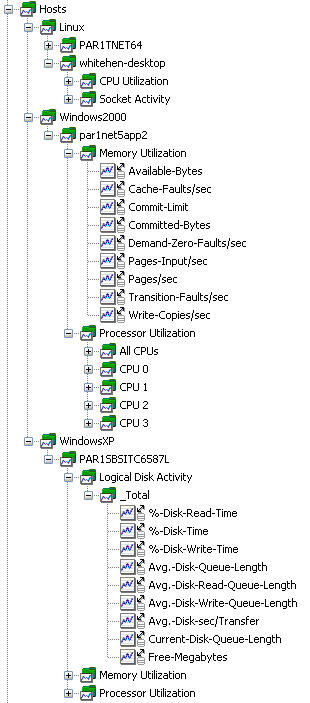
Microsoft Windows 與 Linux/UNIX 之間的本質差別必然導致性能數據收集也迥然各異。Windows 本身幾乎沒有可以提供豐富的性能報告數據的命令行工具。性能數據也無法通過像相對簡單的 /proc 文件系統這樣的東西來獲取。Windows Performance Manager(WPM)— 也稱為 SysMon、System Monitor 或者 Performance Monitor — 是從 Windows 主機獲取性能度量的標准接口。它的功能很強大而且擁有大量有用的指標。此外,很多基於 Windows 的軟件包都通過 WPM 發布了它們自己的指標。Windows 還通過 WPM 提供了制圖、報告和警報設施. 圖 5 展示了一個 WPM 實例的屏幕截圖:
圖 5. Windows Performance Manager
WPM 管理一組性能計數器,即引用了某一具體指標的復合命名的對象。組成復合名稱的有:
性能對象:性能指標的廣義范疇,如:處理器 或內存。
實例:當有多個可能成員時,某些性能對象要用一個實例來劃分。例如,處理器既有代表單個 CPU 的實例,又有總實例。相反,內存則是一個 “純” 性能對象,這是因為內存只有一個表現形式。
計數器:實例(如果可用的話)以及性能對象內部的指標的粒度名。例如,處理器實例 0 有一個名為 % Idle Time 的計數器。
根據這些名稱片段,表達這些對象的命名約定和語法為:
帶實例: \性能對象(實例名)\計數器名
不帶實例: \性能對象\計數器名
WPM 最大的缺點就是它訪問這個數據有些困難,尤其是遠程獲取,如果是非 Windows 平台的話,那麼困難更大。我將呈現很多使用基於 ITracer 的收集器捕獲 WPM 數據的方法。下面總結了一些主要方法:
讀取日志文件:可以配置 WPM 以將所有收集的指標記錄在日志文件中,然後就可以讀取、解析和跟蹤該日志文件。
數據庫查詢:可以配置 WPM 以將所有收集的指標記錄在 SQL Server 數據庫中,收集到的指標可以在這個數據庫中被讀取、解析和跟蹤。
Win32 API:使用 Win32 API(.NET、C++、Visual Basic 等)編寫的客戶機可以使用 WPM 的 API 直接連接到 WPM。
自定義代理:自定義代理可以安裝在目標 Windows 服務器上,該目標 Windows 服務器要能夠為外部請求 —— 請求非 Windows 客戶機中的 WPM 數據 —— 充當代理服務器。
簡單網絡管理協議(Simple Network Management Protocol,SNMP):SNMP 是一個代理的一個實例,該代理更加強調它對設備、主機等的監控能力。稍後我將在本文中論述 SNMP。
WinRM:WinRM 是 WS-Management 規范的 Windows 實現,它概述了如何使用 Web 服務來管理系統。由於 Web 服務是獨立於語言和平台的,因此 WinRM 必然會給非 Windows 客戶機提供 WPM 指標訪問。雖然 WinRM 可以被當作是代理的另一種形式,但它將成為 Windows 2008 的標准配置,這將把它推向無代理解決方案的舞台。最有趣的是,Java Specification Request 262(Web Services Connector for JMX Agent)承諾要與基於 Windows 的、WS-Management 服務直接交互。
在接下來的例子中,我將使用本地 Windows shell 和代理實現呈現一個理論上的概念驗證。
本地 Windows shell
作為一個簡單的概念驗證,我已經創建了一個可使用 C# 執行的名為 winsar.exe 的 Windows 命令行。它的用途是提供一些與 Linux/UNIX sar 命令相同的對性能統計的命令行訪問。使用該命令行的語法很簡單:winsar.exe Category Counter Raw Instance .
實例名是強制使用的,除非計數器不是實例計數器,非實例計數器名稱可以全是(*)。計數器名也是強制使用的,但也可以全是(*)。Raw 是 true 或者 false。清單 10 展示了使用基於實例的計數器和非基於實例的計數器的例子:
清單 10. 使用了非基於實例的和基於實例的計數器的 winsar
C:\NetProjects\WinSar\bin\Debug>winsar Memory "% Committed Bytes In Use" false
%-Committed-Bytes-In-Use
79.57401
C:\NetProjects\WinSar\bin\Debug>winsar LogicalDisk "Current Disk Queue Length" false C:
Current-Disk-Queue-Length
C: 2
因為我的目的是重建某種類似 sar 的東西,數據是以雜亂無章的(非格式化的)表格形式輸出的,因此可以使用標准 shell 命令集來解析這些數據輸出。對於基於實例的計數器來說,實例位於數據行的第一列,計數器名位於標題行。而對於非基於實例的計數器來說,數據行的第一個字段中無名稱。為了能夠清晰解析,任何帶有空格的名稱都填充 “-” 字符。這樣做雖然會很難看但卻可以使解析比較容易。
為這些統計信息(為進行演示而進行了刪減)設置一個收集器是相當簡單的。shell 實現是一個 org.runtimemonitoring.spring.collectors.shell.local.WindowsShell,命令集引用了 winsar.exe 和參數。shell 還可以被實現為使用 SSH 的遠程 shell,要使用 SSH 需要在目標 Windows 主機上安裝一個 SSH 服務器。然而,這個解決方案的效率非常低,這主要的原因是由於該實現是基於 .NET 的;在如此短暫的時間內反復啟動 Common Language Runtime(CLR)是一種低效的實踐。
另一個可能的解決方案是用原生 C++ 重寫 winsar。這個就交給 Windows 編程專家來實現吧。.NET 解決方案的效率是可以提高的,但是程序必須要作為後台進程而一直運行,還要以其他某種方式提供對 WPM 數據的請求,並不會在每一個請求結束後終止。為了達到這個目標,我實現了 winsar 中的第二個選項,在這個選項中由 -service 參數來啟動程序、讀入一個名為 winsar.exe.config 的配置文件並通過 Java Message Service(JMS)監聽請求。除了個別項外,文件的內容非常清楚明了。jmsAssembly 項指一個 .NET 匯編的名稱,該 .NET 匯編包含著 JBoss 4.2.2 客戶機庫(它提供 JMS 功能)的一個 .NET 版本。這個匯編是使用 IKVM(參見 參考資料)創建的。respondTopic 引用了公共主題的名稱,響應是在該公共主題中發布的,而不是使用私有主題來發布,因此其他監聽器也可以接收到數據。commandSet 是一個命令集的引用,該命令集可供一般接收者用來解析和跟蹤數據。清單 11 展示了 winsar.exe.config 文件:
清單 11. winsar.exe.config 文件
<configuration>
<appSettings>
<add key="java.naming.factory.initial"
value="org.jnp.interfaces.NamingContextFactory"/>
<add key="java.naming.factory.url.pkgs"
value="org.jboss.naming:org.jnp.interfaces"/>
<add key="java.naming.provider.url" value="10.19.38.128:1099"/>
<add key="connectionFactory" value="ConnectionFactory"/>
<add key="listenTopic" value="topic/StatRequest"/>
<add key="respondTopic" value="topic/StatResponse"/>
<add key="jmsAssembly" value="JBossClient422g" />
<add key="commandSet" value="WindowsServiceCommandSet" />
</appSettings>
</configuration>
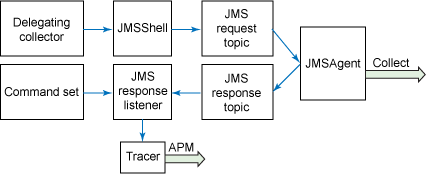
在 Spring 中實現這個收集器以使用該服務在概念上和設置 shell 是一回事。事實上,收集器本身就是 org.runtimemonitoring.spring.collectors.shell.ShellCollector 的一個名為 org.runtimemonitoring.spring.collectors.shell.DelegatingShellCollector 的擴展。不同的是這個 shell 扮演著一個普通收集器的角色,並發出對數據的請求,但是數據是通過 JMS 接收的,通過另一個組件解析和跟蹤的。被實現的名為 org.runtimemonitoring.spring.collectors.shell.jms.RemoteJMSShell 的 Shell 在行為上類似 shell,但它通過 JMS 分配命令,如圖 6 所示:
圖 6. 委托收集器
由於這種策略看起來非常適合全面部署代理,所以相同的基於 JMS 的代理是用 Java 代碼實現的,它可以部署於任何支持 JVM 的 OS 上。圖 7 展示了一個 JMS 發布/訂閱性能數據收集系統:
圖 7. JMS 發布/訂閱監控
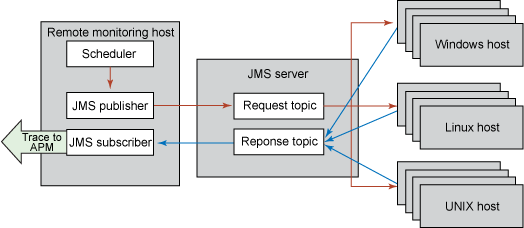
另外 JMS 代理發揮功能的方式也不同。本例中解釋的模式展示的是目標主機上的一個請求監聽 代理,因為這些代理在啟動後不會執行任何操作,直到它們從中央監控系統接收到一個請求才執行。然而,這些代理可以按照自己的計劃自主地 收集數據並將它發布到相同的 JMS 服務器。監聽代理的優勢有兩個:第一,可以配置收集參數並保存在一個中央位置,而不用發送到每一個目標主機。第二(雖然在本例中沒有實現),由於中央請求監聽器發出請求,所以監聽器可以在特定的已知服務器沒有響應的情況下觸發一個報警條件。圖 8 顯示了組合服務器的 APM 樹:
圖 8. Windows 和 Linux 服務器的 APM 樹
winsar 是一個簡單的、早期的原型,它有幾個缺點,包括:
通過編程訪問一些 WPM 計數器(如處理器對象)會生成空的或原始的指標。所以諸如 CPU % Utilization 這樣的指標是可以直接讀取的。所需要解決的是如何在規定的時間段內多次讀取這些指標,然後就可以計算出 CPU 使用了。winsar 沒有這個功能,但是諸如 NSClient 和 NC_Net(參見 參考資料)這樣的類似代理卻可以提供這個功能:
誠然,將 JMS 作為遠程代理的傳輸機制有它的妙處,但是也有局限。NSClient 和 NC_Net both 使用低級但簡單的套接字協議來請求和接收數據。這些服務的本來用途之一就是要將 Windows 數據提供給 Nagios,這是一個幾乎排斥 Linux 平台的網絡監控系統,因此來自客戶端的圖像中實際上可能沒有 Win32 API。
最後,就像我在前面提到的,SpringCollector 應用程序用一個參數引導,它是一個含有配置 XML 文件的目錄。這個目錄為 /conf/spring-collectors,它位於示例代碼包的根目錄中。前面的例子中使用的具體文件為:
shell-collectors.jmx:它包含所有 shell 收集器的定義。
management.xml:它包含 JMX 管理 bean 和收集調度器。
commandsets.xml:它包含 shell 收集器的命令集的定義。這些定義引用了 /commands 中的外部 XML 文件。
shells.xml:它包含所有 shell 的定義。
jms.xml:它包含 JMS 連接工廠和主題的定義,還有 Java Naming 和 Directory Interface(JNDI)上下文。
groovy.xml:它包含 Groovy 格式化程序 bean。
我對 OS 監控的論述就到此為止了。接下來,我將介紹數據庫系統的監控。
用 JDBC 監控數據庫系統
我經常遇到這種情況,就是認為 DBA 以及他們的工具和應用程序的職責僅僅是監控數據庫。然而,要為性能和可用性數據實現非孤立的、集中式 APM 儲存庫,需要在 DBA 的工作中再補充 一些監視整合的 APM 的工作。我將展示一些用名為 JDBCCollector 的 Spring 收集器來收集數據(這些數據在某種情況下很可能沒有受到監控,而且是非常有用的指標)的技術。
您應該考慮的數據收集的廣義范疇為:
簡單的可用性和響應時間:這是一個簡單的機制,可以用它來定期連接到數據庫、發布一個簡單的查詢並跟蹤響應時間,或者在連接失敗時跟蹤服務器停機指標。連接失敗不一定表明數據庫正在經歷硬停機,但它至少可以肯定應用程序一端的通信有問題。孤立的數據庫監控可能永遠無法指示出數據庫連通性問題,但是記住這個還是很有用的,因為可以從那裡 連接到一個服務並不意味著也可以從這裡 連接。
上下文數據:回顧一下 第 1 部分 中的上下文跟蹤 的概念,您可以從應用程序數據的周期性采樣獲得一些有用的信息。在很多情況下,數據庫中的數據活動模式和應用程序設施的行為或性能有著很大的聯系。
數據庫性能表:很多數據庫以表或視圖的形式,抑或是通過儲存過程來公開內部性能和載入指標。同樣,數據可以輕松地通過 JDBC 訪問。這個領域顯然覆蓋了傳統 DBA 監控,但是數據庫性能通常與應用程序性能的聯系非常緊密,以至於如果收集兩組指標卻不通過一個整合系統來關聯它們的話,這簡直就是一種巨大的浪費。
JDBCCollector 非常簡單。基本上,它由一個查詢和一串映射語句組成,它定義了將查詢的結果映射到跟蹤名稱空間的方式。思考一下清單 12 中的 SQL:
清單 12. 一個簡單的 SQL 查詢
SELECT schemaname, relname,
SUM(seq_scan) as seq_scan,
SUM(seq_tup_read) as seq_tup_read
FROM pg_stat_all_tables
where schemaname = 'public'
and seq_scan > 0
group by schemaname, relname
order by seq_tup_read desc
該查詢選擇一個表格中的四個列。我想將每一個從查詢返回的行映射到一個跟蹤名稱空間,這個名稱空間由每行的一部分數據組成。切記名稱空間是由片斷名稱加上指標名稱組成的。使用字母值和/或行標記來指定這些值也就定義了映射。行標記代表編號列中的值,如 {2}。處理片斷和指標名稱時,字母值保持原樣不變,而標記在查詢結果中使用當前行的各個列值動態替換,如圖 9 所示:
圖 9. JDBCCollector 映射
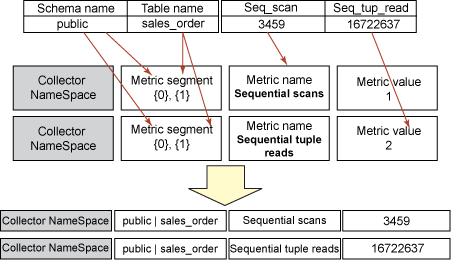
在圖 9 中,我呈現的是對查詢的一行響應,但每為每一個返回的行定義一次映射,映射過程就會發生一次。片斷的值是 {1}、{2},所以跟蹤名稱空間的片段的部分是 {"public", "sales_order"}。指標名是字母值,因而保持不變,指標值在第一次映射時被定義為 1,在第二次映射時被定義為 2,它們分別代表著 3459 和 16722637。具體的實現該過程便可以進一步澄清它。
使用 JDBC 的上下文跟蹤
運行的數據庫中的應用程序數據也許包含有用的且有趣的上下文數據。應用程序數據本身並不一定是與性能相關的,但如果抽樣這些數據,把它與表示 Java 類的性能、JVM 的健康狀況和服務器性能統計信息的歷史指標聯系起來的話,就可以清楚地了解系統在某一具體的時間段內到底在做些什麼。假想您現在正在監控一個極其繁忙的電子商務 Web 站點。您的客戶所發出的訂單被記錄在一個名為 sales_order 的表中,該表還記錄了一個惟一的 ID 和發出訂單的時間戳。你可以通過抽樣在最後 n 分鐘內輸入的記錄數來得出提交訂單的速率。
這裡是 ITracer 的增量(delta)功能的又一個用武之地,因為我可以設置 JDBCCollector 來從某個特定時間點開始查詢行數,並將這個值作為一個增量而跟蹤它。結果會得到一個可以描述您的網站有多繁忙的指標(或許還有很多其他指標)。這個指標也會成為一個頗有價值的歷史參考。例如,如果知道輸入的訂單數達到每個周期 50 個時數據庫的速度就會減慢的話,那麼將會很有用。硬性的、特定的經驗數據可以簡化容量和增長情況的規劃。
接下來我將要實現這個例子。JDBCCollector 使用與前面的例子相同的調度器 bean,它還有一個與我在 第 2 部分 中涉及到的完全相同的 JDBC DataSource。這些數據庫收集器是在 /conf/spring-collectors/jdbc-collectors.xml 文件中定義的。清單 13 展示了第一個收集器:
清單 13. 訂單執行速率收集器
<bean name="OrderFulfilmentRateLast5s"
class="org.runtimemonitoring.spring.collectors.jdbc.JDBCCollector"
init-method="springStart">
<property name="dataSource" ref="RuntimeDataSource" />
<property name="scheduler" ref="CollectionScheduler" />
<property name="query">
<value><![CDATA[
select count(*) from sales_order
where order_date > ? and order_date < ?
]]></value>
</property>
<property name="logErrors" value="true" />
<property name="tracingNameSpace" value="Database Context" />
<property name="objectName"
value="org.runtime.db:name=OrderFulfilmentRateLast5s,type=JDBCCollector" />
<property name="frequency" value="5000" />
<property name="binds">
<map>
<entry><key><value>1</value></key><ref bean="RelativeTime"/></entry>
<entry><key><value>2</value></key><ref bean="CurrentTime"/></entry>
</map>
</property>
<property name="queryMaps">
<set>
<bean class="org.runtimemonitoring.spring.collectors.jdbc.QueryMap">
<property name="valueColumn" value="0"/>
<property name="segments" value="Sales Order Activity"/>
<property name="metricName" value="Order Rate"/>
<property name="metricType" value="SINT"/>
</bean>
</set>
</property>
</bean>
<bean name="RelativeTime"
class="org.runtimemonitoring.spring.collectors.jdbc.RelativeTimeStampProvider">
<property name="period" value="-5000" />
</bean>
<bean name="CurrentTime"
class="org.runtimemonitoring.spring.collectors.jdbc.RelativeTimeStampProvider">
<property name="period" value="10" />
</bean>
這個例子中的收集器 bean 名為 OrderFulfilmentRateLast5s,類為 org.runtimemonitoring.spring.collectors.jdbc.JDBCCollector。標准 scheduler 收集器被注入,它被當作 JDBC DataSource 的一個引用,RuntimeDataSource。query 定義要執行的 SQL。SQL 查詢既可以把字母值用作參數也可以使用綁定變量(就像在這個例子中一樣)。這個例子是人為構造的,因為 order_date 的兩個值很容易用 SQL 語法來表示,但是通常情況下,只有需要提供某些外部值時才會用到綁定變量。
為了提供綁定外部值的能力,我需要先實現 org.runtimemonitoring.spring.collectors.jdbc.IBindVariableProvider 接口,然後再將該類作為一個 Spring 管理的 bean 來實現。在這個例子中,我使用了 org.runtimemonitoring.spring.collectors.jdbc.RelativeTimeStampProvider 的兩個實例,還有一個通過被傳遞的 period 屬性來提供當前時間戳偏移量的 bean。這些 bean 是 RelativeTime,它返回當前時間減去 5 秒得出的值,還有 CurrentTime,它返回 “現在” 時間加上 10 毫秒的值。這些 bean 的引用通過 binds 屬性(一個映射)注入到收集器 bean。映射中的每一個入口值都要與要使用該映射的 SQL 語句中的綁定變量相匹配,這一點至關重要,如若不然就會發生錯誤或意外的結果。
實際上,我利用了這些綁定變量來獲取在大約最後 5 秒鐘輸入系統的銷售訂單數。這需要對生產表格執行大量查詢,因此要適當調節收集的頻率和時間窗口(即,Relative 的時間段)以避免在數據庫上實現不恰當的負載。為了幫助正確地調節這些設置,收集器跟蹤收集時間一直到 APM 系統,所以運行時間可以用來度量查詢開銷。更高級的收集器實現會減緩收集的頻率,因為監控查詢的運行時間增加了。
上面所呈現的映射是通過 queryMaps 屬性定義的,該定義使用了一個 org.runtimemonitoring.spring.collectors.jdbc.QueryMap 類型的內部 bean。它有四個簡單的屬性:
valueColumn :應該作為跟蹤值而綁定的每一行中的列的索引,該索引是基於零的。在這個例子中,我綁定了 count(*) 的值。
segments :跟蹤名稱空間片斷,它被定義為一個單個字母。
metricName :指標名稱的跟蹤名稱空間,同樣被定義成一個字母。
metricType :ITracer 指標類型,它被定義為一個 sticky int。
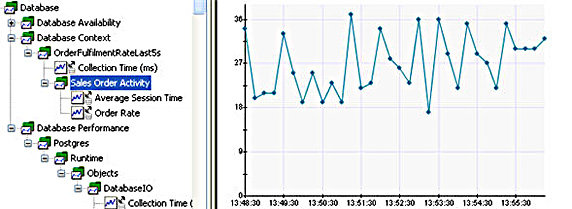
如果想從每一個執行的查詢跟蹤多個值,收集器允許為每一個收集器定義多個 queryMap。接下來我將向您展示的例子會使用 rowToken 把返回數據的值注入跟蹤名稱空間,但是現在的例子使用的是字母值。但是,要設計一個使用相同查詢的例子的話,我會將查詢改為 select count(*), 'Sales Order Activity', 'Order Rate' from sales_order where order_date > ? and order_date < ?。這使得我所期望的片斷和指標名稱返回於查詢中。要想映射它們,我可以將 segments 配置為 {1},將 metricName 設置為 {2}。在某些擴展的情況中,metricType 甚至可能來源於數據庫,而且值也可以用 rowToken 來表示。圖 10 顯示了這些收集的指標的 APM 樹:
圖 10. 銷售訂單速率監控
數據庫性能監控
JDBCCollector 可以使用相同的進程來從數據庫性能視圖中獲取和跟蹤性能數據。在這個使用了 PostgreSQL 的例子中,這些表 — 稱為統計視圖 — 的名稱的前綴為 pg_stat。很多其他的數據庫也都擁有類似的視圖,並可以使用 JDBC 來訪問。在這個例子中,我將使用同一個繁忙的電子商務網站並設置一個 JDBCCollector 來監控最為繁忙的 5 個表上的表格和索引活動。具體的 SQL 展示在清單 14 中:
清單 14. 表格與索引活動監控器
<bean name="DatabaseIO"
class="org.runtimemonitoring.spring.collectors.jdbc.JDBCCollector"
init-method="springStart">
<property name="dataSource" ref="RuntimeDataSource" />
<property name="scheduler" ref="CollectionScheduler" />
<property name="availabilityNameSpace"
value="Database,Database Availability,Postgres,Runtime" />
<property name="query">
<value><![CDATA[
SELECT schemaname, relname, SUM(seq_scan) as seq_scan,
SUM(seq_tup_read) as seq_tup_read,
SUM(idx_scan) as idx_scan, SUM(idx_tup_fetch) as idx_tup_fetch,
COALESCE(idx_tup_fetch,0) + seq_tup_read
+ seq_scan + COALESCE(idx_scan, 0) as total
FROM pg_stat_all_tables
where schemaname = 'public'
and (COALESCE(idx_tup_fetch,0) + seq_tup_read
+ seq_scan + COALESCE(idx_scan, 0)) > 0
group by schemaname, relname, idx_tup_fetch,
seq_tup_read, seq_scan, idx_scan
order by total desc
LIMIT 5 ]]>
</value>
</property>
<property name="tracingNameSpace"
value="Database,Database Performance,Postgres,Runtime,Objects,{beanName}"
/>
<property name="frequency" value="20000" />
<property name="queryMaps">
<set>
<bean class="org.runtimemonitoring.spring.collectors.jdbc.QueryMap">
<property name="valueColumn" value="2"/>
<property name="segments" value="{0},{1}"/>
<property name="metricName" value="SequentialScans"/>
<property name="metricType" value="SDLONG"/>
</bean>
<bean class="org.runtimemonitoring.spring.collectors.jdbc.QueryMap">
<property name="valueColumn" value="3"/>
<property name="segments" value="{0},{1}"/>
<property name="metricName" value="SequentialTupleReads"/>
<property name="metricType" value="SDLONG"/>
</bean>
<bean class="org.runtimemonitoring.spring.collectors.jdbc.QueryMap">
<property name="valueColumn" value="4"/>
<property name="segments" value="{0},{1}"/>
<property name="metricName" value="IndexScans"/>
<property name="metricType" value="SDLONG"/>
</bean>
<bean class="org.runtimemonitoring.spring.collectors.jdbc.QueryMap">
<property name="valueColumn" value="5"/>
<property name="segments" value="{0},{1}"/>
<property name="metricName" value="IndexTupleReads"/>
<property name="metricType" value="SDLONG"/>
</bean>
</set>
</property>
</bean>
查詢每隔 20 分鐘為最繁忙的 5 個表檢索如下的值:
數據庫模式的名稱
表的名稱
順序掃描的總數
順序掃描檢索出的元組總數
索引掃描的總數
索引掃描檢索出的元組總數
後四列是持續增長的值,所以我使用的是 SDLONG 類型的指標,它是一個 sticky 增量 long。注意,在 清單 14 中,我配置了四個 QueryMap 來將四列值映射到跟蹤名稱空間。