可以使用 4 種不同的策略配置 IBM Developer Kit for the Java 5.0 Platform(IBM SDK)中的垃圾收集(GC)。本文(關於 GC 的兩篇文章的第一篇)介紹不同的垃圾收集策略並討論它們的性質。在閱讀本文之前,您應該對 Java 平台中的垃圾收集有基本的認識。第 2 部分將給出一種選擇策略的量化方法,以及一些示例。
為什麼要有不同的 GC 策略?
能夠使用不同的策略使開發人員增加了對應用程序的控制能力。有許多種 GC 算法,每種算法各有優缺點,這取決於工作負載的類型。(如果您不熟悉 GC 算法的一般性主題,那麼請參見 參考資料 中其他讀物的鏈接。在 IBM SDK 5.0 中,可以用 4 種策略 之一配置垃圾收集,每種策略都使用自己的算法。默認策略對於大多數應用程序已經足夠了。如果對應用程序的性能沒有特別的要求,那麼您對本文(和下一篇文章)的內容可能不感興趣;可以在不改變 GC 策略的情況下運行 IBM SDK 5.0。但是,如果應用程序需要最優的性能,或者很關注 GC 停頓時間的長度,那麼請讀下去。您會看到最新的版本比以前的版本提供了更多選擇。
那麼,為什麼不讓 Java 運行時的 IBM 實現自動地替您做出選擇呢?因為這不總是可行的。運行時很難了解您的需要。在某些情況下,希望應用程序有很高的吞吐量;而在其他情況下,希望減少停頓時間。
表 1 列出可用的策略並解釋每種策略應該在何時使用。後面幾節分別詳細描述每種策略的性質。
策略 選項 描述 針對吞吐量進行優化 -Xgcpolicy:optthruput (可選) 默認策略。對於吞吐量比短暫的 GC 停頓更重要的應用程序,通常使用這種策略。每當進行垃圾收集時,應用程序都會停頓。 針對停頓時間進行優化 -Xgcpolicy:optavgpause 通過並發地執行一部分垃圾收集,在高吞吐量和短 GC 停頓之間進行折中。應用程序停頓的時間更短。 分代並發 -Xgcpolicy:gencon 以不同方式處理短期存活的對象和長期存活的對象。采用這種策略時,具有許多短期存活對象的應用程序會表現出更短的停頓時間,同時仍然產生很好的吞吐量。 子池 -Xgcpolicy:subpool 采用與默認策略相似的算法,但是采用一種比較適合多處理器計算機的分配策略。建議對於有 16 個或更多處理器的 SMP 計算機使用這種策略。這種策略只能在 IBM pSeries® 和 zSeries® 平台上使用。需要擴展到大型計算機上的應用程序可以從這種策略中受益。
一些術語的定義
吞吐量是應用程序處理的數據量。衡量吞吐量的標准是與具體應用程序相關的。
停頓時間是垃圾收集器將所有應用程序線程停下來,從而對堆進行收集所經歷的時間。
在本文中,用表 1 中命令行選項中的縮寫來表示這些策略:optthruput 表示針對吞吐量進行優化,optavgpause 表示針對停頓時間進行優化,gencon 表示分代並發,subpool 表示子池。
何時應該考慮采用非默認的 GC 策略?
建議您總是先使用默認 GC 策略。在放棄默認策略之前,需要了解在哪些情況下應該采用其他策略。表 2 給出了一些原因:
切換到 原因 optavgpause 我的應用程序無法忍受那麼長的 GC 停頓時間。如果 GC 停頓時間能夠減少的話,性能降低一些也可以接受。
我的應用程序正在一個 64 位平台上運行並使用非常大的堆 —— 超過 3 或 4GB。
我的應用程序是一個 GUI 應用程序,我很關注用戶響應時間。
gencon 我的應用程序分配了許多短期存活的對象。
堆空間出現碎片化。
我的應用程序是基於事務的(也就是說,在事務提交之後,事務中的對象就不再存活了)。
subpool 在大型多處理器計算機上,我遇到了可伸縮性問題。
我要強調一點:即使出現了表 2 中提到的原因,也不足以 斷言替代策略的性能會更好;它們只是提示。在所有情況下,都應該實際運行應用程序,並度量吞吐量和/或響應時間以及 GC 停頓時間。本系列的下一部分將給出進行這種測試的示例。
本文余下的幾節詳細描述 GC 策略之間的差異。
optthruput
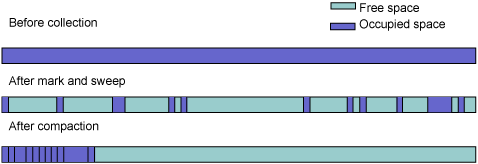
optthruput 是默認策略。它是一個追蹤收集器,稱為標志-掃描-緊湊排列(mark-sweep-compact) 收集器。在 GC 期間總是會運行標志和掃描階段,但是緊湊排列只在某些情況下發生。標志階段會尋找所有存活的對象並加上標志。掃描階段會刪除所有未加標志的對象。第三個可選的步驟是緊湊排列(compaction)。在某些情況下可能會發生緊湊排列;最常見的情況是系統無法回收足夠的空閒空間。
如果非常頻繁地分配和釋放對象,導致在堆上只留下小塊的空閒內存,這時就出現了碎片化。整個堆上可能有大量的空閒空間,但是連續區域很小,導致分配失敗。緊湊排列 就是將所有對象向下移動到堆的開頭,一個挨一個地排列,讓它們之間沒有間隔空間。這會消除堆的碎片化,但這是一種代價昂貴的任務,所以只在必要時執行。
圖 1 描述三個不同階段之後的堆布局:標志、掃描和緊湊排列。深色區域表示對象,淺色區域表示空閒空間。
標志和掃描
標志 階段遍歷所有可以從線程堆棧、靜態值、interned 字符串和 JNI 引用引用的對象。在這個過程中,創建一個標志位矢量,它定義所有存活對象的開頭。
掃描 階段使用標志階段生成的標志位矢量,從而識別哪些堆存儲塊可以回收供以後的分配使用;這些塊被添加到空閒列表中。
圖 1. 垃圾收集前後的堆布局
不同 GC 階段的工作細節超出了本文的范圍;我主要關注確保您理解運行時性質。關於更多細節,請閱讀 Diagnostics Guide。
圖 2 展示執行時間在應用程序線程(即 mutator)和 GC 線程之間如何分布。水平軸是經歷的時間,垂直軸包含線程,其中 n 表示計算機上處理器的數量。對於這個圖示,假設應用程序在每個處理器上使用一個線程。GC 由藍色框表示,這說明 mutator 停止,GC 線程正在運行。這些收集線程占用 100% 的 CPU 資源,mutator 線程空閒。這個圖有點兒過分籠統了,這是為了便於與本文中的其他策略進行比較。實際上,GC 的持續時間和頻率依賴於應用程序和工作負載。
圖 2. 在 optthruput 策略中 CPU 時間在 mutator 和 GC 線程之間的分布

mutator 與 GC 線程
mutator 線程就是分配對象的應用程序。也可以把 mutator 稱為應用程序。GC 線程是內存管理的一部分,它們執行垃圾收集。
堆鎖和線程分配緩存
optthruput 策略使用連續的堆區域,應用程序中的所有線程共享這個區域。線程需要排他地訪問堆,以便為新對象保留空間。這個鎖稱為堆鎖(heap lock),它們確保任意時刻只有一個線程能夠分配對象。在有多個 CPU 的計算機上,這個鎖會造成伸縮性問題,因為可能同時出現多個分配請求,但是每個請求需要排他地訪問堆鎖。
為了緩解這個問題,每個線程保留一小塊內存,稱為線程分配緩存(thread allocation cache) (也稱為線程局部堆,TLH)。這塊存儲空間是一個線程專用的,所以在其中進行分配時不使用堆鎖。當分配緩存滿了之後,線程使用堆鎖向堆請求新的分配緩存。
堆的碎片化會妨礙線程獲得較大的 TLH,所以 TLH 會很快被填滿,導致應用程序線程頻繁地向堆請求新的分配緩存。在這種情況下,堆鎖就成了瓶頸;如果出現這樣的情況,gencon 或 subpool 策略可能是比較好的替代方案。
optavgpause
對於許多應用程序,吞吐量不如響應時間那麼重要。假設一個應用程序要求在 100 毫秒內完成對工作項目的處理。如果 GC 停頓時間在 100 毫秒級別,那麼在 GC 期間就無法在規定時間內完成處理。垃圾收集的一個問題是,停頓時間會增加處理項目花費的最大時間。大型堆(在 64 位平台上可用)會加劇這種影響,因為垃圾收集要處理更多的對象。
optavgpause 是一個替代的 GC 策略,其設計目的是使停頓時間最小化。它並不保證特定的停頓時間,但是停頓時間會比默認 GC 策略產生的停頓時間短。它采用的思路是在應用程序運行的同時並發地執行一些垃圾收集工作。這通過兩種手段來實現:
並發的標志和掃描(concurrent mark and sweep):在堆被填滿以前,每個 mutator 會讓出時間對對象加標志(並發標志)。GC 仍然會停止應用程序的運行,但是停頓時間會顯著縮短。在 GC 之後,mutator 線程會讓出時間進行掃描(並發掃描)。
後台 GC 線程:在應用程序空閒時,一個(或多個)低優先級的後台 GC 線程會執行標志工作。
根據應用程序的不同,與默認 GC 策略相比,吞吐量性能會有 5% 到 10% 的下降。
圖 3 展示在使用 optavgpause 策略時執行時間在 GC 線程和 mutator 線程之間如何分布。沒有顯示後台追蹤線程,因為它應該不會影響應用程序的性能。
圖 3. 在 optavgpause 策略中 CPU 時間在 mutator 和 GC 線程之間的分布
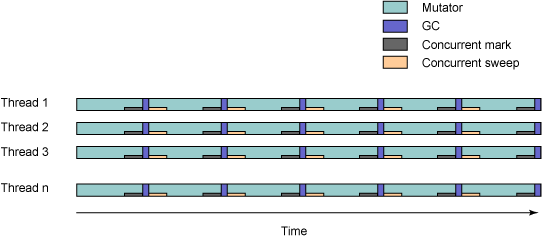
圖中的灰色區域表示啟用了並發追蹤,每個 mutator 線程必須放棄它的一部分處理時間。每個並發階段之後進行一次完整的垃圾收集,垃圾收集完成在並發階段沒有完成的標志和掃描工作。由此導致的停頓時間應該會比一般 GC(optthruput)短得多,這在圖 3 中表現為 GC 框的時間跨度更小。從 GC 結束到並發階段開始之間的間隔是變化的,但是這個階段對性能沒有顯著影響。
optavgpause
對於許多應用程序,吞吐量不如響應時間那麼重要。假設一個應用程序要求在 100 毫秒內完成對工作項目的處理。如果 GC 停頓時間在 100 毫秒級別,那麼在 GC 期間就無法在規定時間內完成處理。垃圾收集的一個問題是,停頓時間會增加處理項目花費的最大時間。大型堆(在 64 位平台上可用)會加劇這種影響,因為垃圾收集要處理更多的對象。
optavgpause 是一個替代的 GC 策略,其設計目的是使停頓時間最小化。它並不保證特定的停頓時間,但是停頓時間會比默認 GC 策略產生的停頓時間短。它采用的思路是在應用程序運行的同時並發地執行一些垃圾收集工作。這通過兩種手段來實現:
並發的標志和掃描(concurrent mark and sweep):在堆被填滿以前,每個 mutator 會讓出時間對對象加標志(並發標志)。GC 仍然會停止應用程序的運行,但是停頓時間會顯著縮短。在 GC 之後,mutator 線程會讓出時間進行掃描(並發掃描)。
後台 GC 線程:在應用程序空閒時,一個(或多個)低優先級的後台 GC 線程會執行標志工作。
根據應用程序的不同,與默認 GC 策略相比,吞吐量性能會有 5% 到 10% 的下降。
圖 3 展示在使用 optavgpause 策略時執行時間在 GC 線程和 mutator 線程之間如何分布。沒有顯示後台追蹤線程,因為它應該不會影響應用程序的性能。
圖 3. 在 optavgpause 策略中 CPU 時間在 mutator 和 GC 線程之間的分布
圖中的灰色區域表示啟用了並發追蹤,每個 mutator 線程必須放棄它的一部分處理時間。每個並發階段之後進行一次完整的垃圾收集,垃圾收集完成在並發階段沒有完成的標志和掃描工作。由此導致的停頓時間應該會比一般 GC(optthruput)短得多,這在圖 3 中表現為 GC 框的時間跨度更小。從 GC 結束到並發階段開始之間的間隔是變化的,但是這個階段對性能沒有顯著影響。
subpool
subpool 策略可以幫助在多處理器系統上提高性能。正如前面提到的,只能在 IBM pSeries 和 zSeries 計算機上使用這種策略。堆布局與 optthruput 策略相同,但是空閒列表的結構不一樣。不是為整個堆使用一個空閒列表,而是有多個列表,稱為子池(subpool)。每個池按照大小進行排序。特定大小的分配請求可以由此大小的池快速地滿足。使用原子性(與平台相關的)高性能指令將空閒列表項彈出這個列表,避免了串行訪問。圖 7 展示了如何按照大小組織空閒存儲塊:
圖 7. 按照大小排序的子池空閒塊
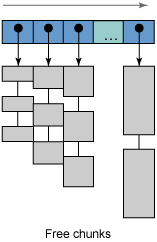
當 JVM 啟動時或進行了緊湊排列時,不使用子池,因為有大塊的堆空間空閒著。在這些情況下,每個處理器用自己專用的小型堆來滿足請求。當發生第一次垃圾收集時,掃描階段開始填充子池,後續的分配主要使用子池。
subpool 策略可以減少分配對象花費的時間。原子性指令確保在不需要全局堆鎖的情況下執行分配。處理器局部的小型堆會提高效率,因為減少了緩存沖突。這會直接影響可伸縮性,尤其是在多處理器系統上。在不能使用 subpool 的平台上,分代的 GC 可以提供相似的好處。
結束語
本文描述了 IBM SDK 5.0 中的不同 GC 策略以及它們的一些性質。默認策略對於大多數應用程序是足夠的;但是,在某些情況下,其他策略的性能更好。我介紹了應該考慮切換到 optavgpause、gencon 或 subpool 的一些一般場景。在對策略進行評估時,對應用程序性能進行度量是非常重要的,第 2 部分將詳細演示這個評估過程。