Java開發人員可以做出的最重要的架構性決策之一就是如何使用Java異常模型。Java異常一直以來就是社群中許多爭議的靶子。有人爭論到,在Java語言中的異常檢查已是一場失敗的試驗。本文將辨析,失敗的原因不在於Java異常模型,而在於Java類庫的設計者未能充分了解到方法失敗的兩個基本原因。
本文倡導一種對異常條件本質的思考方式,並描述一些有助於設計的模式。最後,本文還將在AOP模型中,作為相互滲透的問題,來討論異常的處理。當你能正確使用異常時,它們會有極大的好處。本文將幫助你做到這一點。
為何異常是如此重要
Java應用中的異常處理在很大程度上揭示了其所基於架構的強度。架構是在應用程序各個層次上所做出並遵循的決定。其中最重要的一個就是決定應用程序中的類,亞系統,或層之間溝通的方式。Java異常是Java方法將另類執行結果交流出去的方式,所以值得在應用架構中給予特殊關注。
一個衡量Java設計師水平和開發團隊紀律性的好方法就是讀讀他們應用程序裡的異常處理代碼。首先要注意的是有多少代碼用於捕獲異常,寫進日志文件,決定發生了什麼,和在不同的異常間跳轉。干淨,簡捷,關聯性強的異常處理通常表明開發團隊有著穩定的使用Java異常的方式。當異常處理代碼的數量甚至要超過其他代碼時,你可以看出團隊之間的交流合作有很大的問題(可能在一開始就不存在),每個人都在用他們自己的方式來處理異常。
對突發異常的處理結果是可以預見的。如果你問問團隊成員為什麼異常會被拋出,捕獲,或在特定的一處代碼裡忽視了異常的發生,他們的回答通常是,“我沒有別的可做”。如果你問當他們編寫的異常真的發生了會怎麼樣,他們會皺皺眉,你得到的回答類似於這樣,“我不知道。我們從沒測試過。”
你可以從客戶端的代碼判斷一個java的組件是否有效利用了java的異常。如果它們包含著大堆的邏輯去弄清楚在何時一筆操作失敗了,為何失敗,是否有彌補的余地,那麼原因很有可能要歸咎於組件的報錯設計。錯誤的報錯系統會在客戶端產生大量的“記錄然後忘掉”的代碼,這些代碼鮮有用途。最差的是弄擰的邏輯,嵌套的try/catch/finally代碼塊,和一些其他的混亂而導致脆弱而難於管理的應用程序。
事後再來解決Java異常的問題,或根本就不解決,是軟件項目產生混亂並導致滯後的主要原因。異常處理是一個在設計的各個部分都急需解決的問題。對異常處理建立一個架構性的約定是項目中首要做出的決定。合理使用Java異常模型對確保你的應用簡單,易維護,和正確有著長遠的影響。
解析異常
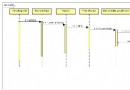
正確使用Java異常模型所包含的內容一直以來有著很大的爭議。Java不是第一種支持異常算法語義的;但是,它卻是第一種通過編譯器來執行聲明和處理某些異常的規則的語言。許多人都認為編譯時的異常檢查對精確的軟件設計頗有幫助。圖1顯示的Java異常的等級。
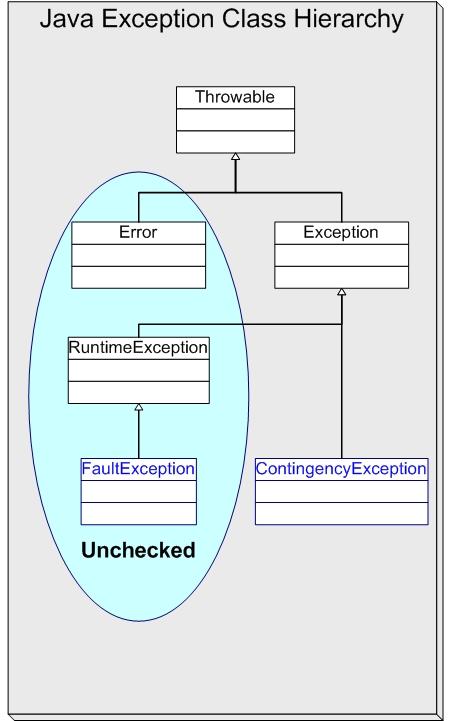
圖1:Java異常的等級
通常,Java編譯器強迫拋出基於java.lang.Throwable的異常的方法要在它聲明中的“throws”部分加上那個異常。而且,編譯器還會證實客戶端的方法或者捕獲已聲明的異常,或者特別聲明自己也拋出同樣的異常。這些簡單的規則對世界范圍的Java程序員都有深遠的影響。
編譯器放松了對Throwable繼承樹中兩個分支的異常檢查。java.long.Error和java.lang.RuntimeException的子類免於編譯時的檢查。在這兩類中,軟件工程師通常對運行中異常更感興趣。“不檢查”的異常指的是這一組,以便和所有其它“檢查”的異常區別開。
我可以想象那些接受“檢查”的異常的人,也會很看重Java的數據類型。畢竟,編譯器對數據類型施加的限制鼓勵嚴格的編碼和精確的思維。編譯時的類型檢查對減少運行時的嚴重問題有幫助。編譯時的異常檢查也能起到類似的作用,它會提醒開發人員某個方法可能會有預想不到的結果需要處理好。
早期的建議是盡可能的使用“檢察的異常”,以此來最大限度的利用編譯器提供的幫助來寫出無錯誤的軟件。Java類庫API的設計者們都認同這一點,他們廣泛地使用“檢察的異常”來模擬類庫方法中幾乎所有的緊急應變措施。在J2SE5.1 API規格中,“檢察的異常”類型已2比1的比率超過了“未檢查的異常”類型。
對程序員而言,看上去在Java類庫中大多數的常用方法對每一個可能的失敗都聲明了“檢察的異常”。例如,java.io包
對IOException這個“檢察的異常”就有著很大的依賴。至少有63個Java類庫包,或直接,或通過十幾個下面的子類,拋出這個異常。
I/O的失敗極其稀有,但是卻很嚴重。而且,一旦發生,從你所寫的代碼裡基本上是無法補救的。Java程序員意識到他們不得不提供IOException或類似的不可補救的事件,而一個簡單的Java類庫方法的調用就可能讓這些事件發生。捕獲這些異常給本來簡單的代碼帶來了一定的晦澀,因為即使在捕獲的代碼塊裡也基本上幫不上忙。但是不加以捕獲又可能更糟糕,因為編譯器要求你的方法必須要拋出那些異常。這樣你的實施細則就不得不暴露在外了,而通常好的面向對象的設計都是要隱藏細節的。
這樣一個不可能贏的局面導致了我們今天所警告的絕大多數臭名卓著的異常處理的顛覆性格局。同時也衍生了很多正確或錯誤的補救之道。
一些Java界的知名人物開始質疑Java的“檢察的異常”的模型是否是一個失敗的試驗。有一些東西肯定是失敗的,但是這和在Java語言裡加入對異常的檢查是毫無關聯的。失敗是由於在Java API的設計者們的思維裡,大多數失敗的情形是雷同的,所以可以通過同一種異常傳達出去。
故障和應變
讓我們來考慮在一個假想的銀行應用中的CheckingAccount類。一個CheckingAcccount屬於一個用戶,記載著用戶的存款余額,也能接受存款,接受止兌的通知,和處理匯入的支票。一個CheckingAcccount對象必須協調同步線程的訪問,因為任何一個線程都可能改變它的狀態。CheckingAcccount類裡processCheck的方法會接受一個Check對象為參數,通常從帳戶余額裡減去支票的金額。但是一個管理支票清算的用戶端程序調用processCheck方法時,必須有兩種可能的應變措施。一,CheckingAccount對象裡可能對該支票已有一個止付的命令;二,帳戶的余額可能不足已滿足支票的金額。
所以,processCheck的方法對來自客戶端的調用可以有3種方式回應。正常的是處理好支票,並把方法簽名裡聲明的結果返回給調用方。兩種應變的回應則是需要與支票清算端溝通的在銀行領域實實在在存在的情況。processCheck方法所有3種返回結果都是按照典型的銀行支票帳戶的行為而精心設計的。
在Java裡,一個自然的方法來表示上述緊急的應變是定義兩種異常,比如StopPaymentException(止付異常)和InsufficientFundsException(余額不足異常)。一個客戶端如果忽略這些異常是不對的,因為這些異常在正常操作的情況下一定會被拋出。他們如同方法的簽名一樣反映了方法的全面行為。
客戶端可以很容易的處理好這兩種異常。如果對支票的兌付被停止了,客戶端把該支票交付特別處理。如果是因為資金不足,用戶端可以從用戶的儲蓄帳戶裡轉移一些資金到支票帳戶裡,然後再試一次。
在使用CheckingAccount的API時,這些應變都是可以預計的和自然的結果。他們並不是意味著軟件或運行環境的失敗。這些異常和由於CheckingAccount類中一些內部實施細則引起的真正失敗是不同的。
設想CheckingAccount對象在數據庫裡保持著一個恆定的狀態,並使用JDBC API來對之訪問。在那個API裡,幾乎所有的數據庫訪問方法都有可能因為和CheckingAccount實施無關的原因而失敗。比如,有人可能忘了把數據庫服務器運行起來,一個未有連上的網絡數據線,訪問數據庫的密碼改變了,等等。
JDBC依靠一種“檢查的異常”,SQLException,來匯報任何可能的錯誤。可能出錯的絕大多數原由都是數據庫的配置,連接,或其所在的硬件設施。對processCheck方法而言,它對上述錯誤是無計可施的。這不應該,因為processCheck至少了解它自己的實施細則。在調用棧裡上游的方法能處理這些問題的可能就更小。
CheckingAccount這個例子說明了一個方法不能成功返回它想要的結果的兩個基本原因。這裡是兩個描述性的術語:
應變
與實際預料相符,一個方法給出另外一種回應,而這種回應可以表達成該方法所要達到的目的之一。這個方法的調用者預料到這個情況的出現,並有相對的應付之道。
故障
在未經計劃的情況下,一個方法不能達到它的初衷,這是一個不訴諸該方法的實施細則就很難搞清的情況。
應用這些術語,對processCheck方法而言,一個止付的命令和一個超額的提取是兩種可能的應變。而SQLException反映了可能的故障。processCheck方法的調用者應該能夠提供應變,但卻不一定能有效的處理好可能發生的故障。
Java異常的匹配
在建立應用架構中Java異常的規則時,以應變和故障的方式仔細考慮好“什麼可能會出錯”是有長遠意義的。
條件 應變 故障 被考慮成 設計的一部分 一個糟糕的意外 預計到會發生 經常發生 絕不發生 關注方 上游對該方法的調用者 需要修好這個問題的人 舉例 另一種返回方式 程序bug,硬件系統故障,配置錯誤,丟失的文件,服務器沒有運行 最好的匹配 一個檢查的異常 一個未檢查的異常
應變情況恰如其分地匹配給了Java檢查的異常。因為它們是方法的語義算法合同中不可缺少的一部分,在這裡借助於編譯器的幫助來確保它們得到解決是很有道理的。如果你發現編譯器堅持應變的異常必須要處理或者在不方便的時候必須要聲明會給你帶來些麻煩,你在設計上幾乎肯定要做些重構了。這其實是件好事。
出現故障的情況對開發人員而言是蠻有意思的,但對軟件邏輯而言卻並非如此。那些軟件”消化問題“的專家們需要關於故障的信息以便來解決問題。因此,未檢查的異常是表示故障的很好方式。他們讓故障的通知原封不動地從調用棧上所有的方法濾過,到達一個專門來捕獲它們的地方,並得到它們自身包含的有利於診斷的信息,對整個事件提供一個有節制的優雅的結論。產生故障的方法不需要來聲明(異常),上游的調用方法不需要捕獲它們,方法的實施細則被正確的隱藏起來- 以最低的代碼復雜度。
新一些的Java API,比如像Spring架構和Java Data Ojects類庫對檢查的異常幾乎沒有依賴。Hibernate ORM架構在3.0版本裡重新定義了一些關鍵功能來去除對檢查的異常的使用。這就意味著在這些架構舉報的絕大部分異常都是不可恢復的,歸咎於錯誤的方法調用代碼,或是類似於數據庫服務器之類的底層部件的失敗。特別的,強迫一個調用方來捕獲或聲明這些異常幾乎沒有任何好處。
設計裡的故障處理
在你的計劃裡,承認你需要去做就邁好了有效處理好故障的第一步。對那些堅信自己能寫出無懈可擊的軟件的工程師們來說,承認這一點是不容易的。這裡是一些有幫助的思考方式。首先,如果錯誤俯拾即是,應用的開發時間將很長,當然前提是程序員自己的bug自己修理。第二,在Java類庫中,過度使用檢查的異常來處理故障情形將迫使你的代碼要應對好故障,即使你的調用次序完全正確。如果沒有一個故障處理的架構,湊合的異常處理將導致應用中的信息丟失。
一個成功的故障處理架構一定要達到下面的目標:
減少代碼的復雜性
捕獲和保存診斷性信息
對合適的人提醒注意
優雅地退出行動
故障是應用的真實意圖的干擾。因此,用來處理它們的代碼應盡量的少,理想上,把它們和應用的語義算法部分隔離開。故障的處理必須滿足那些負責改正它們的人的需要。開發人員需要知道故障發生了,並得到能幫助他們搞清為何發生的信息。即使一個故障,在定義上而言,是不可補救的,好的故障處理會試著優雅地結束引起故障的活動。
對故障情況使用未檢查的異常
在做框架上的決定時,用未檢查的異常來代表故障情況是有很多原因的。Java的運行環境對代碼的錯誤會拋出“運行時異常”的子類,比如,ArithmeticException或ClassCastException。這為你的框架設了一個先例。未檢查的異常讓上游的調用方法不需要為和它們目的不相關的情況而添加代碼,從而減少了混亂。
你的故障處理策略應該認識到Java類庫的方法和其他API可能會使用檢查的異常來代表對你的應用而言只可能是故障的情況。在這種情形下,采用設計約定來捕獲API異常,將其以故障來看待,拋出一個未檢查的異常來指示故障的情況和捕獲診斷的信息。
在這種情況下拋出的特定異常類型應該由你的框架來定義。不要忘記一個故障異常的主要目的是傳遞記錄下來的診斷信息,以便讓人們來想出出錯的原因。使用多個故障異常類型可能有些過,因為你的架構對它們都一視同仁。多數情況下,一條好的,描述性強的信息將單一的故障類型嵌入就夠用了。使用Java基本的RuntimeException來代表故障情況是很容易的。截止到Java1.4,RuntimeException,和其他的拋出類型一樣,都支持異常的嵌套,這樣你就可以捕獲和報出導向故障的檢查的異常。
你也許會為了故障報告的目的而定義你自己的未檢查的異常。這樣做可能是必要的,如果你使用Java1.3或更早的版本,它們都不支持異常的嵌套。實施一個類似的嵌套功能來捕獲和轉換你應用中構成故障的檢查的異常是很簡單的。你的應用在報錯時可能需要一個特殊的行為。這可能是你在架構中創建RuntimeException子類的另一個原因。
建立一個故障的屏障
對你的故障處理架構而言,決定拋出什麼樣的異常,何時拋出是重要的決定。同樣重要的是,何時來捕獲一個故障異常,之後再怎麼辦。這裡的目的是讓你應用中的功能性部分不需要處理故障。把問題分開來處理通常都是一件好事情,有一個中央故障處理機制長遠來看是很有裨益的。
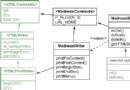
在故障屏障的模式裡,任何應用組件都可以拋出故障異常,但是只有作為“故障屏障”的組件才捕獲異常。采用此種模式去除了大多數程序員為了在本地處理故障而插入的復雜的代碼。故障屏障邏輯上位於調用棧的上層,這樣在一個默認的行動被激發前,一個異常向上舉報的行為就被阻止了。根據不同的應用類型,默認的行動所指也不同。對一個獨立的Java應用而言,這個行動指活著的線程被停止。對一個位於應用服務器上的Web應用而言,這個行動指應用服務器向浏覽器送出不友好的(甚至令人尴尬的)回應。
一個故障屏障組件的第一要務就是記錄下故障異常中包含的信息以為將來所用。到現在為止,一個應用日志是做成此事的首選。異常的嵌套的信息,棧日志,等等,都是對診斷有價值的信息。傳遞故障信息最差的地方是通過用戶界面。把應用的使用者卷進查錯的進程對你,對你的用戶而言都不好。如果你真的很想把診斷信息放上用戶界面,那可能意味著你的日志策略需要改進。
故障屏障的下一個要務是以一種可控的方式來結束操作。這具體的意義要取決於你應用的設計,但通常包括產生一個可通用的回應給可能正在等待的客戶端。如果你的應用是一個Web service,這就意味著在回應中用soap:Server的<faultcode>和通用的失敗信息<faultstring>來建立一個SOAP故障元素<fault>。如果你的應用於浏覽器交流,這個屏障就會安排好一個通用的HTML回應來表明需求是不能被處理的。
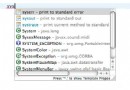
在一個Struts的應用裡,你的故障屏障會以一種全局異常處理器的形式出現,並被配置成處理RuntimeException的任何子類。你的故障屏障類將延伸org.apache.struts.action.ExceptionHandler類,必要的話,重寫它的方法來實施用戶自己的特別處理。這樣就會處理好不小心產生的故障情況和在處理一個Struts動作時發現的故障。圖2顯示的就是應變和故障異常。
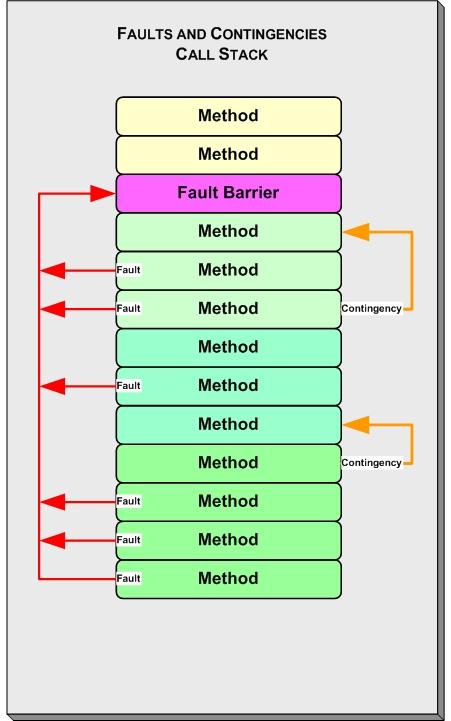
圖2 應變和故障異常
如果你使用的是Spring MVC架構,你可以繼承SimpleMappingExceptionResolver類,並配置成處理RuntimeException和它的子類們,這樣很容易的就建起了故障屏障。通過重寫resolveException的方法,你可以在使用父類的方法來把需求導引到一個發出通用錯誤提示的view組件之前,加入你需要的用戶化的處理。
當你的架構包含了故障屏障,程序員都知曉了後,再寫出一次性的故障異常的沖動就會銳減。結果就是應用中出現更干淨,更易於維護的代碼。
架構中應變的處理
將故障處理交與屏障後,主要組件間的應變交流變得容易多了。一個應變代表著與主要返回結果同等重要的另外一種方法結果。因此,檢查的異常類型是一個能夠很好地傳遞應變情況的存在並提供必要的信息來與它競爭的工具。這個方式借助於Java編譯器的幫助來提醒程序員關於他們所用的API的方方面面以及提供全套的方法輸出的必要性。
僅僅使用方法的返回值類型來傳遞簡單的應變是可能的。比如,返回一個空引用,而不是一個具體的對象,可以意味著對象由於一個已定義的原因不能被建立。Java I/O的方法通常返回一個整數值-1,而不是字節的值或字節的數來表示文件的結尾。如果你的方法的語義簡單到可以允許的地步,另一種返回值的方法是可以使用的,因為它摒棄了異常帶來的額外的花銷。不足之處是方法的調用方要檢測一下返回的值來判斷是主要結果,還是應變結果。但是,編譯器沒有辦法來保證方法調用者會使用這個判斷。
如果一個方法有一個void的返回類型,異常是唯一的方法來表示應變發生了。如果一個方法返回的是一個對象的引用,那麼返回值只可能是空或非空(null and non-null)。如果一個方法返回一個整數型,選擇與主要返回值不沖突的,可以表示多種應變情況的數值是可能的。但是這樣的話,我們就進入了錯誤代碼檢查的世界,而這正式Java異常模式所著力避免的。
提供一些有用的信息
定義不同的故障報告的異常類型是沒什麼道理的,因為故障屏障對所有異常類型一視同仁。應變異常就有很大的不同,因為它們的原意是要向方法調用者傳遞各種情況。你的架構可能會指出這些異常應該繼承java.lang.Exception或一個指定的基類。
不要忘記你的異常應該是百分百的Java類型,你可以用它來存放為你的特殊目的服務的特殊字段,方法,甚至是構造器。比如,被假想的processCheck()方法拋出的InsufficientFundsException這個異常類型就應該包含著一個OverdraftProtection的對象,它能夠從另外一個帳戶裡把短缺的資金轉過來。
日志還是不要日志
記錄下故障異常是有用處的,因為日志的目的是在一些需要改正的情況下,日志可以吸引人們的注意力。但對應變異常而言卻並非如此。應變異常可能代表的只是極少數情況,但是在你的應用裡,每一個情況還是會發生的。它們意味著你的應用正在如最初的設計般正常工作著。經常把日志代碼加進應變的捕獲塊裡會使你的代碼晦澀難懂,而又沒有實際的好處。如果一個應變代表了一重要的事件,在拋出一個異常應變來警醒調用者之前,產生一筆日志,記錄下這個事件可能會讓這個方法更好些。
異常的各個方面在Aspect Oriented Programming(AOP)的術語裡,故障和應變的處理是互相滲透的問題。比如,要實施故障屏障的模式,所有參與的類必須遵循通用規格:
故障屏障方法必須存活在遍歷參與類的方法調用圖的最前端
參與類必須使用未檢查的異常來表示故障情況
參與類必須使用故障屏障期望得到的有針對性的未檢查的異常類型
參與類必須捕獲並從低端方法中把在執行情境下注定的故障轉換成檢查的異常
參與類不能干擾故障異常被傳遞到故障屏障的過程
這些問題超越了那些本不相干的類的邊界。結果就是少數零散的故障處理代碼,以及屏障類和參與類間暗含的耦合(這已經比不使用模式進步多了!)。AOP讓故障處理的問題被封裝在通用的可以作用到參與類的層面上。如AspectJ和Spring AOP這樣的Java AOP架構認為異常的處理是添加故障處理行為的切入點。這樣,把參與者綁定在故障屏障的模式可以放松些。故障的處理可以存活在一個獨立的,不相干的方面裡,從而摒棄了屏障方法需要放在方法激活次序的最前頭的要求。
如果在你的架構裡利用了AOP,故障和應變的處理是理想的在應用裡用到的在方面上的候選。對故障和應變的處理在AOP架構下的使用做一個完整的勘探將是將來論文裡一個很有意思的題目。
結論雖然Java異常模型自它出現以來就激發了熱烈的討論,如果使用正確的話,它的價值還是很大的。作為一個設計師,你的任務是建立好規格來最大限度地利用好這個模型。以故障和應變的方式來考量異常可以幫助你做出正確的決定。合理使用好Java異常模型可以讓你的應用簡單,易維護,和正確。AOP技術將故障和應變定位為相互滲透的問題,這個方法可能會對你的架構提供一些幫助。
引用
Sun's Exception Tutorial Java異常的基本知識
Does Java Need Checked Exception? Bruce Eckel對Java中檢查的異常的異議
Exceptional Java 關於異常的很好的討論,有架構式的異常規則來模仿
The Exceptions Debate 來自於developerWorks的關於異常的來龍去脈
The Apache Struts Web Application Framework Struts的信息源
The Spring Framework Spring框架的信息源
Wikipedia: Aspect Oriented Programming 一個很好的對AOP概念的介紹
The AspectJ Project AspectJ的信息源
作者Barry Ruzek被Open Group提名為注冊IT設計師的大師。他有著30多年的開發操作系統和企業應用的經驗。