Java 語言可能是使用最廣泛的依賴於垃圾收集的編程語言,但是它並不是第 一個。垃圾收集已經成為了包括 Lisp、Smalltalk、Eiffel、Haskell、ML、 Scheme和 Modula-3 在內的許多編程語言的一個集成部分,並且從 20 世紀 60 年代早期就開始使用了。在 Java 理論與實踐的本篇文章中,Brian Goetz 描述 了垃圾收集最常用的技術。
垃圾收集的好處是無可爭辯的 ―― 可靠性提高、使內存管理與類接口設計 分離,並使開發者減少了跟蹤內存管理錯誤的時間。著名的懸空指針和內存洩漏 問題在 Java 程序中再也不會發生了(Java 程序可能會出現某種形式的內存洩 漏,更精確地說是非故意的對象保留,但是這是一個不同的問題)。不過,垃圾 收集不是沒有代價的 ―― 其中包括對性能的影響、暫停、配置復雜性和不確定 的結束 (nondeterministic finalization)。
一個理想的垃圾收集實現應該是完全不可見的 ―― 沒有垃圾收集暫停、沒 有因為垃圾收集而產生的 CPU 時間損失、垃圾收集器不會與虛擬內存或者緩存 有負面的互動,並且堆不需要大於應用程序的 駐留空間(即堆占用)。當然, 沒有十全十美的垃圾收集器,但是垃圾收集器在過去十年中已經有了很大改進。
選項與選擇
1.3 JDK 包括三種不同的垃圾收集策略,1.4.1 JDK 包括六種垃圾收集策略 以及 12 種以上用於配置和優化垃圾收集的命令行選項。它們有什麼不同?為什 麼需要有這麼多選項?
不同的垃圾收集實現使用不同的策略來識別和收回不可到達的對象,它們與 用戶程序和調度器以不同的方式互動。不同類型的應用程序對於垃圾收集有不同 的要求 ―― 實時應用程序會將要求收集暫停的持續時間短並且有限制,而企業 應用程序可能允許更長時間和可預測性更低的暫停以獲得更高的吞吐能力。
垃圾收集如何工作?
有幾種垃圾收集的基本策略:引用計數、標記-清除、標記-整理 (mark- compact) 和復制。此外,一些算法可以以 增量 方式完成它們的工作(不需要 一次收集整個堆,使得收集暫停時間更短),一些算法可以在用戶程序運行時運 行( 並發收集)。其他算法則必須在用戶程序暫停時一次進行整個收集(即所 謂的 stop-the-world收集器)。最後,還有混合型的收集器,如 1.2 和以後版 本的 JDK 使用的分代收集器,它對堆的不同區域使用不同的收集算法。
在對垃圾收集算法進行評價時,我們可能要考慮以下所有標准:
暫停時間。收集器是否停止所有工作來進行垃圾收集?要停止多長時間?暫 停是否有時間限制?
暫停的可預測性。垃圾收集暫停是否規劃為在用戶程序方便而不是垃圾收集 器方便的時間發生?
CPU 占用。總的可用 CPU 時間用在垃圾收集上的百分比是多少?
內存大小。許多垃圾收集算法需要將堆分割成獨立的內存空間,其中一些空 間在某些時刻對用戶程序是不可訪問的。這意味著堆的實際大小可能比用戶程序 的最大堆駐留空間要大幾倍。
虛擬內存交互。在具有有限物理內存的系統上,一個完整的垃圾收集在垃圾 收集過程中可能會錯誤地將非常駐頁面放到內存中來進行檢查。因為頁面錯誤的 成本很高,所以垃圾收集器正確管理引用的區域性 (locality) 是很必要的。
緩存交互。即使在整個堆可以放到主內存中的系統上 ―― 實際上幾乎所有 Java 應用程序都可以做到這一點,垃圾收集也常常會有將用戶程序使用的數據 沖出緩存的效果,從而影響用戶程序的性能。
對程序區域性的影響。雖然一些人認為垃圾收集器的工作只是收回不可到達 的內存,但是其他人認為垃圾收集器還應該盡量改進用戶程序的引用區域性。整 理收集器和復制收集器在收集過程中重新安排對象,這有可能改進區域性。
編譯器和運行時影響。一些垃圾收集算法要求編譯器或者運行時環境的重要 配合,如當進行指針分配時更新引用計數。這增加了編譯器的工作,因為它必須 生成這些簿記指令,同時增加了運行時環境的開銷,因為它必須執行這些額外的 指令。這些要求對性能有什麼影響呢?它是否會干擾編譯時優化呢?
不管選擇什麼算法,硬件和軟件的發展使垃圾收集更具有實用性。20 世紀 70 和 80 年代的經驗研究表明,對於大型 Lisp 程序,垃圾收集消耗 25% 到 40% 的運行時。垃圾收集還不能做到完全不可見,這肯定還有很長的路要走。
基本算法
所有垃圾收集算法所面臨的問題是相同的 ―― 找出由分配器分配的,但是 用戶程序不可到達的內存塊。不可到達是什麼意思?可以以兩種方式之一訪問內 存塊 ―― 或者用戶程序在 根 (root)中有對這一內存塊的引用,或者在另一個 可到達的塊中有對這個塊的引用。在 Java 程序中,根是對靜態變量中或者活躍 的堆棧框架上的本地變量中所包含的對象的引用。可到達的對象集是指向關系下 根集的傳遞閉包。
引用計數
最直觀的垃圾收集策略是引用計數。引用計數很簡單,但是需要編譯器的重 要配合,並且增加了賦值 函數 (mutator)的開銷(這個術語是針對用戶程序的 ,是從垃圾收集器的角度來看的)。每一個對象都有一個關聯的引用計數 ―― 對該對象的活躍引用的數量。如果對象的引用計數是零,那麼它就是垃圾(用戶 程序不可到達它),並可以回收。每次修改指針引用時(比如通過賦值語句), 或者當引用超出范圍時,編譯器必須生成代碼以更新引用的對象的引用計數。如 果對象的引用計數變為零,那麼運行時就可以立即收回這個塊(並且減少被回收 的塊所引用的所有塊的引用計數),或者將它放到遲延收集隊列中。
許多 ANSI C++ 庫類,比如 string ,使用了引用計數來提供垃圾收集的特 性。通過重載賦值操作符並利用 C++ 作用域提供的確定性結束,C++ 程序可以 將 string 類當成是被收集的垃圾那樣使用。引用計數很簡單,很適用於增量收 集,收集過程一般會得到好的引用區域性,但是出於幾個理由,它很少在生產垃 圾收集器中使用,如它不能回收不可到達的循環結構(彼此直接或者間接引用的 幾個對象,如循環鏈接的列表或者包含指向父節點的反向指針的樹)。
跟蹤收集器
JDK 中的標准垃圾收集器都沒有使用引用計數,相反,它們都使用某種形式 的 跟蹤收集器 (tracing collector)。跟蹤收集器停止所有工作(盡管不需要 在收集的整個過程中都這樣)並開始跟蹤對象,從根集開始沿著引用跟蹤,直到 檢查了所有可到達的對象。可以在程序注冊表中、每一個線程堆棧中的(基於堆 棧的)局部變量中以及靜態變量中找到根。
標記-清除收集器
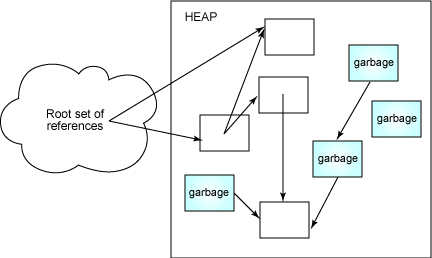
最早由 Lisp 的發明人 John McCarthy 於 1960 年提出的最基本的跟蹤收集 器形式是 標記―清除收集器,它停止所有工作,收集器從根開始訪問每一個活 躍的節點,標記它所訪問的每一個節點。走過所有引用後,收集就完成了,然後 就對堆進行清除(即對堆中的每一個對象進行檢查),所有沒有標記的對象都作 為垃圾回收並返回空閒列表。圖 1 展示了垃圾收集之前的堆,陰影塊是垃圾, 因為用戶程序不能到達它們:
圖 1. 可到達和不可到達的對象
標記-清除實現起來很簡單,可以容易地回收循環的結構,並且不像引用計數 那樣增加編譯器或者賦值函數的負擔。但是它也有不足 ―― 收集暫停可能會很 長,在清除階段整個堆都是可訪問的,這對於可能有頁面交換的堆的虛擬內存系 統有非常負面的性能影響。
標記-清除的最大問題是,每一個活躍的(即已分配的)對象,不管是不是可 到達的,在清除階段都是可以訪問的。因為很多對象都可能成為垃圾,這意思著 收集器花費大量精力去檢查並處理垃圾。標記-清除收集器還容易使堆產生碎片 ,這會產生區域性問題並可以造成分配失敗,即使看來有足夠的自由內存可用。
復制收集器
在另一種形式的跟蹤收集器 ―― 復制收集器中,堆被分成兩個大小相等的 半空間,其中一個包含活躍的數據,另一個未使用。當活躍的空間占滿以後,程 序就會停止,活躍的對象被從活躍的空間復制到不活躍的空間中。空間的角色就 會轉換,原來不活躍的空間成為了新的活躍空間。
復制收集的優點是只訪問活躍的對象,這意味著不會檢查垃圾對象,也不需 要將它們頁交換到內存中或者送到緩存中。復制收集器的收集周期時間是由活躍 對象的數量決定的。不過,復制收集器因為要將數據從一個空間復制到另一個空 間、調整所有引用以指向新備份而增加了成本。特別是,長壽的對象在每次收集 時都要來回復制。
堆整理
復制收集器有另一個好處,活躍對象集會被整理到堆的底部。這不僅改進了 用戶程序的引用區域性並消除了堆碎片,而且極大地減少了對象分配的成本 ― ― 對象分配變成了在堆頂部的指針上增加指針。不需要維護自由列表或者後備 列表,或者使用性能最佳或者第一合適的算法 ―― 分配 N 字節就是在堆頂部 指針上加 N 並返回前一個值這麼簡單,如清單 1 所示:
清單 1. 復制收集器中廉價的內存分配
void *malloc(int n) {
if (heapTop - heapStart < n)
doGarbageCollection();
void *wasStart = heapStart;
heapStart += n;
return wasStart;
}
為非垃圾收集語言實現了復雜內存管理方案的開發人員可能會對復制收集器 中廉價的內存分配感到吃驚 ―― 就是指針加法這麼簡單。以前的 JVM 實現沒 有使用復制收集器 ―― 這可能是對象分配是昂貴的這一想法是如此普遍的原因 之一,開發人員仍然下意識地假設分配成本與其他語言(如 C)類似,而事實上 在 Java 運行時中可能要廉價得多。不但是分配成本減少了,而且對於在下次收 集之前成為垃圾的對象,解除分配的成本為零,因為既不會訪問也不會復制垃圾 對象。
標記-整理收集器
復制算法的性能很優異,但是它有一個缺點是需要兩倍於標記-清除收集器所 需要的內存。標記-整理 算法結合了標記-清除和復制,避免了這個問題,代價 是增加了一些收集復雜性。與標記-清除類似,標記-整理是兩階段過程,在標記 階段訪問並標記每個活躍對象。然後,復制標記的對象,使所有活躍對象被整理 到堆的底部。如果每一次收集時進行徹底的整理,那麼得到的堆就類似於復制收 集器的結果 ―― 在堆的活躍部分與自由部分有明確的界線,這樣分配成本與復 制收集器相當。長壽的對象趨向於沉在堆的底部,這樣就不會像在復制收集器中 那樣反復復制它們。
選擇哪一種呢?
那麼 JDK 使用了哪種方式進行垃圾收集呢?在某種意義上,使用了所有的方 式。早期的 JDK 使用了單線程的標記-清除或者標記-清除-整理收集器。1.2 及 以後的 JDK 使用了混合的方式,稱為 分代收集,其中根據對象的年齡將堆分為 幾個部分,不同的代是用不同的收集算法收集的。
分代收集證明是非常高效的,盡管在運行時它需要更多的簿記。在下一個月 的 Java 理論與實踐 中,除了介紹 1.4.1 JVM 提供的所有其他垃圾收集選項之 外,我們還將探討分代收集是如何工作的以及 1.4.1 JVM 是如何使用它的。在 下下篇文章中,我們將分析垃圾收集對性能的影響,包括揭示與內存管理有關的 性能神話。