ConcurrentHashMap 是 Doug Lea的 util.concurrent 包的一部分,它提供 比Hashtable 或者 synchronizedMap 更高程度的並發性。而且,對於大多數成 功的 get() 操作它會設法避免完全鎖定,其結果就是使得並發應用程序有著非 常好的吞吐量。這個月,BrianGoetz 仔細分析了 ConcurrentHashMap的代碼, 並探討 Doug Lea 是如何在不損失線程安全的情況下取得這麼驕人成績的。
在7月份的那期 Java理論與實踐(“ Concurrent collections classes”) 中,我們簡單地回顧了可伸縮性的瓶頸,並討論了怎麼用共享數據結構的方法獲 得更高的並發性和吞吐量。有時候學習的最好方法是分析專家的成果,所以這個 月我們將分析 Doug Lea的 util.concurrent 包中的 ConcurrentHashMap的實現 。JSR 133 將指定 ConcurrentHashMap的一個版本,該版本針對 Java 內存模型 (JMM)作了優化,它將包含在JDK 1.5的 java.util.concurrent 包中。 util.concurrent 中的版本在老的和新的內存模型中都已通過線程安全審核。
針對吞吐量進行優化
ConcurrentHashMap 使用了幾個技巧來獲得高程度的並發以及避免鎖定,包 括為不同的 hash bucket(桶)使用多個寫鎖和使用 JMM的不確定性來最小化鎖 被保持的時間――或者根本避免獲取鎖。對於大多數一般用法來說它是經過優化 的,這些用法往往會檢索一個很可能在map 中已經存在的值。事實上,多數成功 的 get() 操作根本不需要任何鎖定就能運行。(警告:不要自己試圖這樣做! 想比 JMM 聰明不像看上去的那麼容易。 util.concurrent 類是由並發專家編寫 的,並且在JMM 安全性方面經過了嚴格的同行評審。)
多個寫鎖
我們可以回想一下,Hashtable(或者替代方案 Collections.synchronizedMap )的可伸縮性的主要障礙是它使用了一個 map 范圍(map-wide)的鎖,為了保證插入、刪除或者檢索操作的完整性必須保持這 樣一個鎖,而且有時候甚至還要為了保證迭代遍歷操作的完整性保持這樣一個鎖 。這樣一來,只要鎖被保持,就從根本上阻止了其他線程訪問 Map,即使處理器 有空閒也不能訪問,這樣大大地限制了並發性。
ConcurrentHashMap 摒棄了單一的 map 范圍的鎖,取而代之的是由 32 個鎖 組成的集合,其中每個鎖負責保護 hash bucket的一個子集。鎖主要由變化性操 作( put() 和remove() )使用。具有 32 個獨立的鎖意味著最多可以有 32 個 線程可以同時修改 map。這並不一定是說在並發地對 map 進行寫操作的線程數 少於 32 時,另外的寫操作不會被阻塞――32 對於寫線程來說是理論上的並發 限制數目,但是實際上可能達不到這個值。但是,32 依然比 1 要好得多,而且 對於運行於目前這一代的計算機系統上的大多數應用程序來說已經足夠了。  
map 范圍的操作
有 32 個獨立的鎖,其中每個鎖保護 hash bucket的一個子集,這樣需要獨 占訪問 map的操作就必須獲得所有32個鎖。一些 map 范圍的操作,比如說 size() 和isEmpty(), 也許能夠不用一次鎖整個 map(通過適當地限定這些操 作的語義),但是有些操作,比如 map 重排(擴大 hash bucket的數量,隨著 map的增長重新分布元素),則必須保證獨占訪問。Java 語言不提供用於獲取可 變大小的鎖集合的簡便方法。必須這麼做的情況很少見,一旦碰到這種情況,可 以用遞歸方法來實現。
JMM概述
在進入 put() 、 get() 和remove()的實現之前,讓我們先簡單地看一下 JMM。JMM 掌管著一個線程對內存的動作(讀和寫)影響其他線程對內存的動作 的方式。由於使用處理器寄存器和預處理 cache 來提高內存訪問速度帶來的性 能提升,Java 語言規范(JLS)允許一些內存操作並不對於所有其他線程立即可 見。有兩種語言機制可用於保證跨線程內存操作的一致性―― synchronized 和 volatile。
按照 JLS的說法,“在沒有顯式同步的情況下,一個實現可以自由地更新主 存,更新時所采取的順序可能是出人意料的。”其意思是說,如果沒有同步的話 ,在一個給定線程中某種順序的寫操作對於另外一個不同的線程來說可能呈現出 不同的順序, 並且對內存變量的更新從一個線程傳播到另外一個線程的時間是 不可預測的。
雖然使用同步最常見的原因是保證對代碼關鍵部分的原子訪問,但實際上同 步提供三個獨立的功能――原子性、可見性和順序性。原子性非常簡單――同步 實施一個可重入的(reentrant)互斥,防止多於一個的線程同時執行由一個給 定的監視器保護的代碼塊。不幸的是,多數文章都只關注原子性方面,而忽略了 其他方面。但是同步在JMM 中也扮演著很重要的角色,會引起 JVM 在獲得和釋 放監視器的時候執行內存壁壘(memory barrier)。
一個線程在獲得一個監視器之後,它執行一個 讀屏障(read barrier)―― 使得緩存在線程局部內存(比如說處理器緩存或者處理器寄存器)中的所有變量 都失效,這樣就會導致處理器重新從主存中讀取同步代碼塊使用的變量。與此類 似,在釋放監視器時,線程會執行一個 寫屏障(write barrier)――將所有修 改過的變量寫回主存。互斥獨占和內存壁壘結合使用意味著只要您在程序設計的 時候遵循正確的同步法則(也就是說,每當寫一個後面可能被其他線程訪問的變 量,或者讀取一個可能最後被另一個線程修改的變量時,都要使用同步),每個 線程都會得到它所使用的共享變量的正確的值。
如果在訪問共享變量的時候沒有同步的話,就會發生一些奇怪的事情。一些 變化可能會通過線程立即反映出來,而其他的則需要一些時間(這由關聯緩存的 本質所致)。結果,如果沒有同步您就不能保證內存內容必定一致(相關的變量 相互間可能會不一致),或者不能得到當前的內存內容(一些值可能是過時的) 。避免這種危險情況的常用方法(也是推薦使用的方法)當然是正確地使用同步 。然而在有些情況下,比如說在像 ConcurrentHashMap 之類的一些使用非常廣 泛的庫類中,在開發過程當中還需要一些額外的專業技能和努力(可能比一般的 開發要多出很多倍)來獲得較高的性能。
ConcurrentHashMap 實現
如前所述, ConcurrentHashMap 使用的數據結構與 Hashtable 或 HashMap 的實現類似,是 hash bucket的一個可變數組,每個 ConcurrentHashMap 都由 一個 Map.Entry 元素鏈構成,如清單1所示。與 Hashtable 和HashMap 不同的 是, ConcurrentHashMap 沒有使用單一的集合鎖(collection lock),而是使 用了一個固定的鎖池,這個鎖池形成了bucket 集合的一個分區。
清單1. ConcurrentHashMap 使用的 Map.Entry 元素
protected static class Entry implements Map.Entry {
protected final Object key;
protected volatile Object value;
protected final int hash;
protected final Entry next;
...
}
不用鎖定遍歷數據結構
與 Hashtable 或者典型的鎖池 Map 實現不同, ConcurrentHashMap.get() 操作不一定需要獲取與相關bucket 相關聯的鎖。如果不使用鎖定,那麼實現必 須有能力處理它用到的所有變量的過時的或者不一致的值,比如說列表頭指針和 Map.Entry 元素的域(包括組成每個 hash bucket 條目的鏈表的鏈接指針)。
大多並發類使用同步來保證獨占式訪問一個數據結構(以及保持數據結構的 一致性)。 ConcurrentHashMap 沒有采用獨占性和一致性,它使用的鏈表是經 過精心設計的,所以其實現可以 檢測 到它的列表是否一致或者已經過時。如果 它檢測到它的列表出現不一致或者過時,或者干脆就找不到它要找的條目,它就 會對適當的bucket 鎖進行同步並再次搜索整個鏈。這樣做在一般的情況下可以 優化查找,所謂的一般情況是指大多數檢索操作是成功的並且檢索的次數多於插 入和刪除的次數。
使用不變性
不一致性的一個重要來源是可以避免得,其方法是使 Entry 元素接近不變性 ――除了值字段(它們是易變的)之外,所有字段都是 final的。這就意味著不 能將元素添加到 hash 鏈的中間或末尾,或者從 hash 鏈的中間或末尾刪除元素 ――而只能從 hash 鏈的開頭添加元素,並且刪除操作包括克隆整個鏈或鏈的一 部分並更新列表的頭指針。所以說只要有對某個 hash 鏈的一個引用,即使可能 不知道有沒有對列表頭節點的引用,您也可以知道列表的其余部分的結構不會改 變。而且,因為值字段是易變的,所以能夠立即看到對值字段的更新,從而大大 簡化了編寫能夠處理內存潛在過時的 Map的實現。
新的 JMM 為 final 型變量提供初始化安全,而老的 JMM 不提供,這意味著 另一個線程看到的可能是 final 字段的默認值,而不是對象的構造方法提供的 值。實現必須能夠同時檢測到這一點,這是通過保證 Entry 中每個字段的默認 值不是有效值來實現的。這樣構造好列表之後,如果任何一個 Entry 字段有其 默認值(零或空),搜索就會失敗,提示同步 get() 並再次遍歷鏈。
檢索操作
檢索操作首先為目標 bucket 查找頭指針(是在不鎖定的情況下完成的,所 以說可能是過時的),然後在不獲取 bucket 鎖的情況下遍歷 bucket 鏈。如果 它不能發現要查找的值,就會同步並試圖再次查找條目,如清單2所示:
清單2. ConcurrentHashMap.get() 實現
public Object get(Object key) {
int hash = hash(key); // throws null pointer exception if key is null
// Try first without locking...
Entry[] tab = table;
int index = hash & (tab.length - 1);
Entry first = tab[index];
Entry e;
for (e = first; e != null; e = e.next) {
if (e.hash == hash && eq(key, e.key)) {
Object value = e.value;
// null values means that the element has been removed
if (value != null)
return value;
else
break;
}
}
// Recheck under synch if key apparently not there or interference
Segment seg = segments[hash & SEGMENT_MASK];
synchronized(seg) {
tab = table;
index = hash & (tab.length - 1);
Entry newFirst = tab[index];
if (e != null || first != newFirst) {
for (e = newFirst; e != null; e = e.next) {
if (e.hash == hash && eq(key, e.key))
return e.value;
}
}
return null;
}
}
刪除操作
因為一個線程可能看到 hash 鏈中鏈接指針的過時的值,簡單地從鏈中刪除 一個元素不足以保證其他線程在進行查找的時候不繼續看到被刪除的值。相反, 從清單3我們可以看到,刪除操作分兩個過程――首先找到適當的 Entry 對象並 把其值字段設為 null ,然後對鏈中從頭元素到要刪除的元素的部分進行克隆, 再連接到要刪除的元素之後的部分。因為值字段是易變的,如果另外一個線程正 在過時的鏈中查找那個被刪除的元素,它會立即看到一個空值,並知道使用同步 重新進行檢索。最終,原始 hash 鏈中被刪除的元素將會被垃圾收集。
清單3. ConcurrentHashMap.remove() 實現
protected Object remove(Object key, Object value) {
/*
Find the entry, then
1. Set value field to null, to force get() to retry
2. Rebuild the list without this entry.
All entries following removed node can stay in list, but
all preceding ones need to be cloned. Traversals rely
on this strategy to ensure that elements will not be
repeated during iteration.
*/
int hash = hash(key);
Segment seg = segments[hash & SEGMENT_MASK];
synchronized(seg) {
Entry[] tab = table;
int index = hash & (tab.length-1);
Entry first = tab[index];
Entry e = first;
for (;;) {
if (e == null)
return null;
if (e.hash == hash && eq(key, e.key))
break;
e = e.next;
}
Object oldValue = e.value;
if (value != null && !value.equals(oldValue))
return null;
e.value = null;
Entry head = e.next;
for (Entry p = first; p != e; p = p.next)
head = new Entry(p.hash, p.key, p.value, head);
tab[index] = head;
seg.count--;
return oldValue;
}
}
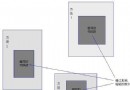
圖1為刪除一個元素之前的 hash 鏈:
圖1. Hash鏈

圖2為刪除元素3之後的鏈:
圖2. 一個元素的刪除過程
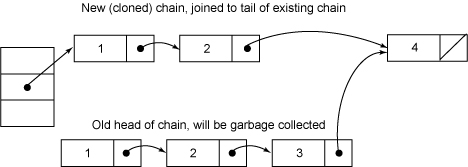
插入和更新操作
put()的實現很簡單。像 remove() 一樣, put() 會在執行期間保持 bucket 鎖,但是由於 put() 並不是都需要獲取鎖,所以這並不一定會阻塞其他讀線程 的執行(也不會阻塞其他寫線程訪問別的 bucket)。它首先會在適當的 hash 鏈中搜索需要的鍵值。如果能夠找到, value 字段(易變的)就直接被更新。 如果沒有找到,新會創建一個用於描述新 map的新 Entry 對象,然後插入到 bucket 列表的頭部。
弱一致的迭代器
由 ConcurrentHashMap 返回的迭代器的語義又不同於 ava.util 集合中的迭 代器;而且它又是 弱一致的(weakly consistent)而非 fail-fast的(所謂 fail-fast 是指,當正在使用一個迭代器的時候,如何底層的集合被修改,就會 拋出一個異常)。當一個用戶調用 keySet().iterator() 去迭代器中檢索一組 hash 鍵的時候,實現就簡單地使用同步來保證每個鏈的頭指針是當前值。 next() 和hasNext() 操作以一種明顯的方式定義,即遍歷每個鏈然後轉到下一 個鏈直到所有的鏈都被遍歷。弱一致迭代器可能會也可能不會反映迭代器迭代過 程中的插入操作,但是一定會反映迭代器還沒有到達的鍵的更新或刪除操作,並 且對任何值最多返回一次。 ConcurrentHashMap 返回的迭代器不會拋出 ConcurrentModificationException 異常。
動態調整大小
隨著 map 中元素數目的增長,hash 鏈將會變長,因此檢索時間也會增加。 從某種意義上說,增加 bucket的數目和重排其中的值是非常重要的。在有些像 Hashtable 之類的類中,這很簡單,因為保持一個應用到整個 map的獨占鎖是可 能的。在ConcurrentHashMap 中,每次一個條目插入的時候,如果鏈的長度超過 了某個阈值,鏈就被標記為需要調整大小。當有足夠多的鏈被標記為需要調整大 小以後, ConcurrentHashMap 就使用遞歸獲取每個 bucket 上的鎖並重排每個 bucket 中的元素到一個新的、更大的 hash 表中。多數情況下,這是自動發生 的,並且對調用者透明。
不鎖定?
要說不用鎖定就可以成功地完成 get() 操作似乎有點言過其實,因為 Entry 的 value 字段是易變的,這是用來檢測更新和刪除的。在機器級,易變的和同 步的內容通常在最後會被翻譯成相同的緩存一致原語,所以這裡會有 一些 鎖定 ,雖然只是細粒度的並且沒有調度,或者沒有獲取和釋放監視器的 JVM 開銷。 但是,除語義之外,在很多通用的情況下,檢索的次數大於插入和刪除的次數, 所以說由 ConcurrentHashMap 取得的並發性是相當高的。
結束語
ConcurrentHashMap 對於很多並發應用程序來說是一個非常有用的類,而且 對於理解 JMM 何以取得較高性能的微妙細節是一個很好的例子。 ConcurrentHashMap 是編碼的經典,需要深刻理解並發和JMM 才能夠寫得出。使 用它,從中學到東西,享受其中的樂趣――但是除非您是Java 並發方面的專家 ,否則的話您自己不應該這