從重構的角度學習bridge設計模式
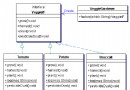
Bridge模式是一個在實際系統中經常應用的模式。它最能體現設計模式的原則針對接口進行編程,和使用聚合不使用繼承這兩個原則。
由於我們過分的使用繼承,使類的結構過於復雜,不易理解,難以維護。特別是在Java中由於不能同時繼承多個類,這樣就會造成多層繼承,維護更難。
Bridge模式是解決多層繼承的根本原因。如果你在實現應用中一個類,需要繼承兩個以上的類,並且這兩者之間又持有某種關系,它們兩個都會有多種變化。
Bridge模式是把這兩個類,分解為一個抽象,一個實現,使它們兩個分離,這樣兩種類可以獨立的變化。
抽象就是,把一個實體的共同概念(相同的步驟),抽取出來(分解出幾個相互獨立的步驟),作為一個過程。如我們把數據庫的 操作抽象為一個過程,有幾個步驟,創建SQL語句,發送到數據庫處理,取得結果。
實現就是怎樣完成這個抽象步驟,如發送到數據庫,需要結合具體的數據庫,考慮怎樣完成這個步驟等。並且同一步驟可能存在不同的實現,如對不同的數據庫需要不同的實現。
現在我們假設一個情況,也是WEB中經常遇到的,在一個page有輸入框,如客戶信息的姓名,地址等,輸入信息後,然後按查找按鈕,把查找的結果顯示出來。
我們現在假設查找客戶信息和帳戶信息,它們在不同的表中。
但是我們的系統面對兩種人群,總部的它們信息保存到oracle數據庫,但是各個分公司的數據保存在Sybase中,數據庫的位置等各不相同,這兩種的操作不同。
下面是我們一般首先會使用的方式,使用if else進行,判斷,這樣使用系統難以維護,難以擴展,不妨你增加一種查詢,或者一種數據庫試試?
public class SearchAction(){
public Vector searchData(string ActionType,String DbType){
String SQL="";
if(ActionType.equal("查找客戶信息")){
//如果是查詢客戶信息,拼SQL語句從客戶表中讀取數據
SQL="select * from Customer "
if(dbType.equal("oracle")){
//從總部數據庫讀取,數據庫為Oracle
String connect_string ="jdbc:oracle:thin:hr/hr@localhost:1521:HRDB";
DriverManager.registerDriver (new oracle.jdbc.OracleDriver());
Connection conn = DriverManager.getConnection (connect_string);
// Create a statement
Statement stmt = conn.createStatement ();
ResultSet rset = stmt.executeQuery (SQL);
//以下省略部分動態從數據庫中取出數據,組裝成Vector,返回
..................................
...................................
}else(dbType.equal("sybase")){
//從分公司數據庫讀取,數據庫為Sybase
String connect_string ="jdbc:sybase:Tds:cai/cai@192.168.1.12:1521:FIN";
DriverManager.registerDriver (new com.sybase.jdbc.SybDriver());
Connection conn = DriverManager.getConnection (connect_string);
// Create a statement
Statement stmt = conn.createStatement ();
ResultSet rset = stmt.executeQuery (SQL);
//以下省略部分動態從數據庫中取出數據,組裝成Vector,返回
..................................
...................................
}
}else if(ActionType.equal("查找帳戶信息")){
//如果是查詢帳戶信息,拼接SQL語句從帳戶表中讀取數據
SQL="select * from Account "
if(dbType.equal("oracle")){
..........................
..........................
(作者注:此處省略從oracle讀取,約300字)
}else if(dbType.equal("Sybase")){
..........................
..........................
(作者注:此處省略從Sybase讀取,約300字)
}
}
}
}
如果你認為這寫的比較弱智,應該進行使用函數,但是你也會大量使用if else。
於是我們進行重構,首先我們學習過DAO模式,就是把數據讀取進行分裡,我們定義一個共同的接口,它負責數據庫的操作,然後根據不同的數據庫進行實現,在我們的查詢操作中,使用接口,進行操作,這樣就可以不用考慮具體的實現,我們只管實現過程。
查詢共同接口:
public interface searchDB{
public Vector searchFromDB(String SQL)
}
Oracle數據庫的查詢實現
public class searchDBOracleImpl{
public Vector searchFromDB(String SQL){
//從總部數據庫讀取,數據庫為Oracle
String connect_string ="jdbc:oracle:thin:hr/hr@localhost:1521:HRDB";
DriverManager.registerDriver (new oracle.jdbc.OracleDriver());
ResultSet rset = stmt.executeQuery (SQL);
.............................
............................
}
}
Sybase數據庫的查詢實現
public class searchDBSysbaseImpl{
public Vector searchFromDB(String SQL){
//從分公司數據庫讀取,數據庫為Sysbase
String connect_string ="jdbc:sybase:Tds:cai/cai@192.168.1.12:1521:FIN";
DriverManager.registerDriver (new com.sybase.jdbc.SybDriver());
ResultSet rset = stmt.executeQuery (SQL);
.............................
............................
}
}
這樣在我們的查詢中就可以使用接口searchDB,但是創建有是一個問題,因為我們不能靜態的確定,查詢的數據庫類型,必須動態確定,於是我們又想到使用簡單工廠方法,來分別創建這裡的具體實現,根據類別,創建
public class searchFactory{
public static searchDB createSearch(int DBType){
if(DBType.equal("oracle")){
return searchDBOracleImpl();
}else if(DBType.equal("sybase")){
return searchDBSysbaseImpl();
}
}
}
於是我們的查詢代碼可以改變為這樣了;
public class SearchAction(){
public Vector searchData(string ActionType,String DbType){
String SQL="";
if(ActionType.equal("查找客戶信息")){
//如果是查詢客戶信息,拼SQL語句從客戶表中讀取數據
SQL="select * from Customer "
searchDB obj=searchFactory.createSearch(DbType);
return obj.searchFromDB(SQL);
}else if(ActionType.equal("查找帳戶信息")){
//如果是查詢帳戶信息,拼接SQL語句從帳戶表中讀取數據
SQL="select * from Account "
searchDB obj=searchFactory.createSearch(DbType);
return obj.searchFromDB(SQL);
}
}
}
是不是簡單一些,如果增加一個新的數據庫,對我們只需增加一個新的數據庫實現便可,老的代碼,不需改變,這樣便實現開-閉原則(Open-closed原則),在我們的查詢查詢中使用的是接口,這就是設計模式的原則,針對接口進行編程,並且使用聚合,而不是直接的繼承大家,可以考慮使用繼承來完成該工作怎樣實現。上面是把實現進行分離,實現可以動態變化!
我們把查詢的操作的具體數據庫實現進行了分離,增強了靈活性,但是我們的查詢。仍然使用了if else這樣仍然不易進行擴展,於是我們進行抽象一個查詢操作的過程,把它分成幾個具體步驟,創建SQL語句,發送到數據庫,執行查詢,返回結果。
它們雖然是不同的查詢,SQL各不相同,不同數據庫執行不同,返回結果的內容不同。但是這個過程卻是不變的,於是我們聲明一個抽象類,來完成這個過程。
public abstract class searchAction{
searchDB obj;
//兩個步驟
public searchDB createSearchImple(int DbType){
return searchFactory.createSearch(DbType);
}
public abstract String createSQL();
//查詢過程,最後返回結果
public vector searchResult(int DbType){
obj=createSearchImple(DbType);
return obj.searchFromDB(createSQL())
}
}
//我們客戶查詢,操作
public class searchCustomerAction{
public String createSQL(){
return "select * from Customer"
}
}
//我們的帳戶查詢操作
public class searchAccountAction{
public String createSQL(){
return "select * from account"
}
}
這樣我們的查詢編程簡單的創建SQL語句,我們應該再創建一個工廠方法,來完成創建它們
public class actionFactory{
public static searchAction ceateAction(int actionType){
if(actionType.equal("customer")){
return searchCustomerAction();
}else if(actionType.equal("account")){
return searchAccountAction();
}
}
}
這樣我們把查詢操作的過程進行了抽象,定義了步驟,和具體過程,經過我們的兩次改變把抽象部分和實現部分進行分離,使他們都可以獨立的變化,增強靈活性。
我們再看當初查詢實現,現在經過這兩次的地修改,變成了什麼模樣?如下:
public class SearchAction(){
public Vector searchData(string ActionType,String DbType){
searchAction action=actionFactory.ceateAction(ActionType);
return action.searchResult(DbType);
}