早期 Java 版本使用 16 位 char 數據類型表示 Unicode 字符。這種設計方 法有時比較合理,因為所有 Unicode 字符擁有的值都小於 65,535 (0xFFFF), 可以通過 16 位表示。但是,Unicode 後來將最大值增加到 1,114,111 (0x10FFFF)。由於 16 位太小,不能表示 Unicode version 3.1 中的所有 Unicode 字符,32 位值 — 稱為碼位(code point) — 被用於 UTF-32 編碼模式。
但與 32 位值相比,16 位值的內存使用效率更高, 因此 Unicode 引入了一個種新設計方法來允許繼續使用 16 位值。UTF-16 中采 用的這種設計方法分配 1,024 值給 16 位高代理(high surrogate),將另外 的 1,024 值分配給 16 位低代理(low surrogate)。它使用一個高代理加上一 個低代理 — 一個代理對(surrogate pair) — 來表示 65,536 (0x10000) 和 1,114,111 (0x10FFFF) 之間的 1,048,576 (0x100000) 值 (1,024 和 1,024 的乘積)。
Java 1.5 保留了 char 類型的行為來表 示 UTF-16 值(以便兼容現有程序),它實現了碼位的概念來表示 UTF-32 值。這個擴展(根據 JSR 204:Unicode Supplementary Character Support 實現) 不需要記住 Unicode 碼位或轉換算法的准確值 — 但理解代理 API 的正 確用法很重要。
東亞國家和地區近年來增加了它們的字符集中的字符數 量,以滿足用戶需求。這些標准包括來自中國的國家標准組織的 GB 18030 和來 自日本的 JIS X 0213。因此,尋求遵守這些標准的程序更有必要支持 Unicode 代理對。本文解釋相關 Java API 和編碼選項,面向計劃重新設計他們的軟件, 從只能使用 char 類型的字符轉換為能夠處理代理對的新版本的讀者。
順序訪問
順序訪問是在 Java 語言中處理字符串的一個基本操作。在 這種方法下,輸入字符串中的每個字符從頭至尾按順序訪問,或者有時從尾至頭 訪問。本小節討論使用順序訪問方法從一個字符串創建一個 32 位碼位數組的 7 個技術示例,並估計它們的處理時間。
示例 1-1:基准測試(不支持代 理對)
清單 1 將 16 位 char 類型值直接分配給 32 位碼位值,完全沒 有考慮代理對:
清單 1. 不支持代理對
int[] toCodePointArray(String str) { // Example 1-1
int len = str.length(); // the length of str
int[] acp = new int[len]; // an array of code points
for (int i = 0, j = 0; i < len; i++) {
acp[j++] = str.charAt(i);
}
return acp;
}
盡管這個示例不支持代理對,但它提供了一個處理時間基准來比 較後續順序訪問示例。
示例 1-2:使用 isSurrogatePair()
清單 2 使用 isSurrogatePair() 來計算代理對總數。計數之後,它分配足夠的內存 以便一個碼位數組存儲這個值。然後,它進入一個順序訪問循環,使用 isHighSurrogate() 和 isLowSurrogate() 確定每個代理對字符是高代理還是低 代理。當它發現一個高代理後面帶一個低代理時,它使用 toCodePoint() 將該 代理對轉換為一個碼位值並將當前索引值增加 2。否則,它將這個 char 類型值 直接分配給一個碼位值並將當前索引值增加 1。這個示例的處理時間比 示例 1 -1 長 1.38 倍。
清單 2. 有限支持
int[] toCodePointArray(String str) { // Example 1-2
int len = str.length(); // the length of str
int[] acp; // an array of code points
int surrogatePairCount = 0; // the count of surrogate pairs
for (int i = 1; i < len; i++) {
if (Character.isSurrogatePair(str.charAt(i - 1), str.charAt(i))) {
surrogatePairCount++;
i++;
}
}
acp = new int[len - surrogatePairCount];
for (int i = 0, j = 0; i < len; i++) {
char ch0 = str.charAt(i); // the current char
if (Character.isHighSurrogate(ch0) && i + 1 < len) {
char ch1 = str.charAt(i + 1); // the next char
if (Character.isLowSurrogate(ch1)) {
acp[j++] = Character.toCodePoint(ch0, ch1);
i++;
continue;
}
}
acp[j++] = ch0;
}
return acp;
}
清單 2 中更新軟件的方法很幼稚。它比較麻煩,需要大量修改 ,使得生成的軟件很脆弱且今後難以更改。具體而言,這些問題是:
需 要計算碼位的數量以分配足夠的內存
很難獲得字符串中的指定索引的正 確碼位值
很難為下一個處理步驟正確移動當前索引
一個改進後的算法出現在下一個示例中。
示例:基本支持
Java 1.5 提供了 codePointCount()、codePointAt() 和 offsetByCodePoints() 方法來分別處理 示例 1-2 的 3 個問題。清單 3 使用 這些方法來改善這個算法的可讀性:
清單 3. 基本支持
int[] toCodePointArray(String str) { // Example 1- 3
int len = str.length(); // the length of str
int[] acp = new int[str.codePointCount(0, len)];
for (int i = 0, j = 0; i < len; i = str.offsetByCodePoints(i, 1)) {
acp[j++] = str.codePointAt(i);
}
return acp;
}
但是,清單 3 的處理時間比 清單 1 長 2.8 倍。
示例 1-4:使用 codePointBefore()
當 offsetByCodePoints() 接收一個負數 作為第二個參數時,它就能計算一個距離字符串頭的絕對偏移值。接下來, codePointBefore() 能夠返回一個指定索引前面的碼位值。這些方法用於清單 4 中從尾至頭遍歷字符串:
清單 4. 使用 codePointBefore() 的基本支持
int[] toCodePointArray(String str) { // Example 1-4
int len = str.length(); // the length of str
int[] acp = new int[str.codePointCount(0, len)];
int j = acp.length; // an index for acp
for (int i = len; i > 0; i = str.offsetByCodePoints(i, -1)) {
acp[--j] = str.codePointBefore(i);
}
return acp;
}
這個示例的處理時間 — 比 示例 1-1 長 2.72 倍 — 比 示例 1-3 快一些。通常,當您比較零而不是非零值時,JVM 中的代 碼大小要小一些,這有時會提高性能。但是,微小的改進可能不值得犧牲可讀性 。
示例 1-5:使用 charCount()
示例 1-3 和 1-4 提供基本的代 理對支持。他們不需要任何臨時變量,是健壯的編碼方法。要獲取更短的處理時 間,使用 charCount() 而不是 offsetByCodePoints() 是有效的,但需要一個 臨時變量來存放碼位值,如清單 5 所示:
清單 5. 使用 charCount() 的優化支持
int[] toCodePointArray(String str) { // Example 1-5
int len = str.length(); // the length of str
int[] acp = new int[str.codePointCount(0, len)];
int j = 0; // an index for acp
for (int i = 0, cp; i < len; i += Character.charCount(cp)) {
cp = str.codePointAt (i);
acp[j++] = cp;
}
return acp;
}
清單 5 的處理時間降低到比 示例 1-1 長 1.68 倍。
示例 1-6:訪問一個 char 數組
清單 6 在使用 示例 1-5 中展 示的優化的同時直接訪問一個 char 類型數組:
清單 6. 使用一個 char 數組的優化支持
int[] toCodePointArray(String str) { // Example 1-6
char[] ach = str.toCharArray(); // a char array copied from str
int len = ach.length; // the length of ach
int[] acp = new int [Character.codePointCount(ach, 0, len)];
int j = 0; // an index for acp
for (int i = 0, cp; i < len; i += Character.charCount(cp)) {
cp = Character.codePointAt(ach, i);
acp[j++] = cp;
}
return acp;
}
char 數組 是使用 toCharArray() 從字符串復制而來的。性能得到改善,因為對數組的直 接訪問比通過一個方法的間接訪問要快。處理時間比 示例 1-1 長 1.51 倍。但 是,當調用時,toCharArray() 需要一些開銷來創建一個新數組並將數據復制到 數組中。String 類提供的那些方便的方法也不能被使用。但是,這個算法在處 理大量數據時有用。
示例 1-7:一個面向對象的算法
這個示例的 面向對象算法使用 CharBuffer 類,如清單 7 所示:
清單 7. 使用 CharSequence 的面向對象算法
int[] toCodePointArray(String str) { // Example 1-7
CharBuffer cBuf = CharBuffer.wrap(str); // Buffer to wrap str
IntBuffer iBuf = IntBuffer.allocate( // Buffer to store code points
Character.codePointCount(cBuf, 0, cBuf.capacity ()));
while (cBuf.remaining() > 0) {
int cp = Character.codePointAt(cBuf, 0); // the current code point
iBuf.put(cp);
cBuf.position (cBuf.position() + Character.charCount(cp));
}
return iBuf.array();
}
與前面的示例不同,清單 7 不 需要一個索引來持有當前位置以便進行順序訪問。相反,CharBuffer 在內部跟 蹤當前位置。Character 類提供靜態方法 codePointCount() 和 codePointAt() ,它們能通過 CharSequence 接口處理 CharBuffer。CharBuffer 總是將當前位 置設置為 CharSequence 的頭。因此,當 codePointAt() 被調用時,第二個參 數總是設置為 0。處理時間比 示例 1-1 長 2.15 倍。
處理時間比較
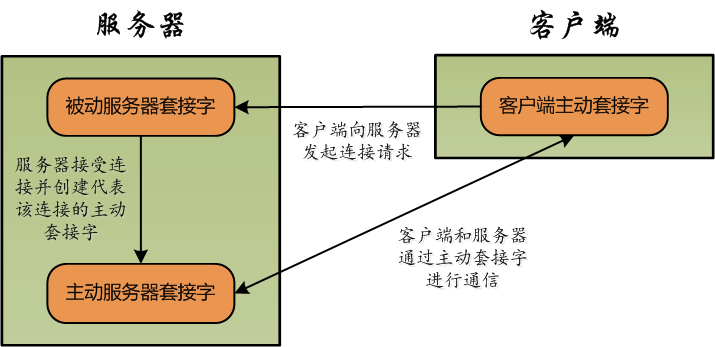
這些順序訪問示例的計時測試使用了一個包含 10,000 個代理對和 10,000 個非代理對的樣例字符串。碼位數組從這個字符串創建 10,000 次。測 試環境包括:
OS:Microsoft Windows® XP Professional SP2
Java:IBM Java 1.5 SR7
CPU:Intel® Core 2 Duo CPU T8300 @ 2.40GHz
Memory:2.97GB RAM
表 1 展示了示例 1-1 到 1-7 的絕 對和相對處理時間以及關聯的 API:
表 1. 順序訪問示例的處理時間和 API
隨機訪問
隨機訪問是直接訪問一個字符串中 的任意位置。當字符串被訪問時,索引值基於 16 位 char 類型的單位。但是, 如果一個字符串使用 32 位碼位,那麼它不能使用一個基於 32 位碼位的單位的 索引訪問。必須使用 offsetByCodePoints() 來將碼位的索引轉換為 char 類型 的索引。如果算法設計很糟糕,這會導致很差的性能,因為 offsetByCodePoints() 總是通過使用第二個參數從第一個參數計算字符串的內 部。在這個小節中,我將比較三個示例,它們通過使用一個短單位來分割一個長 字符串。
示例 2-1:基准測試(不支持代理對)
清單 8 展示如 何使用一個寬度單位來分割一個字符串。這個基准測試留作後用,不支持代理對 。
清單 8. 不支持代理對
String[] sliceString(String str, int width) { // Example 2-1
// It must be that "str != null && width > 0".
List<String> slices = new ArrayList<String>();
int len = str.length(); // (1) the length of str
int sliceLimit = len - width; // (2) Do not slice beyond here.
int pos = 0; // the current position per char type
while (pos < sliceLimit) {
int begin = pos; // (3)
int end = pos + width; // (4)
slices.add(str.substring(begin, end));
pos += width; // (5)
}
slices.add(str.substring(pos)); // (6)
return slices.toArray(new String[slices.size()]); }
sliceLimit 變量對分割位置有所限制,以避免在剩余的字符串不足以分割當前寬度單位時拋 出一個 IndexOutOfBoundsException 實例。這種算法在當前位置超出 sliceLimit 時從 while 循環中跳出後再處理最後的分割。
示例 2-2: 使用一個碼位索引
清單 9 展示了如何使用一個碼位索引來隨機訪問一個 字符串:
清單 9. 糟糕的性能
String[] sliceString (String str, int width) { // Example 2-2
// It must be that "str != null && width > 0".
List<String> slices = new ArrayList<String>();
int len = str.codePointCount(0, str.length()); // (1) code point count [Modified]
int sliceLimit = len - width; // (2) Do not slice beyond here.
int pos = 0; // the current position per code point
while (pos < sliceLimit) {
int begin = str.offsetByCodePoints(0, pos); // (3) [Modified]
int end = str.offsetByCodePoints(0, pos + width); // (4) [Modified]
slices.add(str.substring(begin, end));
pos += width; // (5)
}
slices.add(str.substring (str.offsetByCodePoints(0, pos))); // (6) [Modified]
return slices.toArray(new String[slices.size()]); }
清 單 9 修改了 清單 8 中的幾行。首先,在 Line (1) 中,length() 被 codePointCount() 替代。其次,在 Lines (3)、(4) 和 (6) 中,char 類型的 索引通過 offsetByCodePoints() 用碼位索引替代。
基本的算法流與 示 例 2-1 中的看起來幾乎一樣。但處理時間根據字符串長度與示例 2-1 的比率同 比增加,因為 offsetByCodePoints() 總是從字符串頭到指定索引計算字符串內 部。
示例 2-3:減少的處理時間
可以使用清單 10 中展示的方法 來避免 示例 2-2 的性能問題:
清單 10. 改進的性能
String[] sliceString(String str, int width) { // Example 2-3
// It must be that "str != null && width > 0".
List<String> slices = new ArrayList<String>();
int len = str.length(); // (1) the length of str
int sliceLimit // (2) Do not slice beyond here. [Modified]
= (len >= width * 2 || str.codePointCount(0, len) > width)
? str.offsetByCodePoints(len, -width) : 0;
int pos = 0; // the current position per char type
while (pos < sliceLimit) {
int begin = pos; // (3)
int end = str.offsetByCodePoints(pos, width); // (4) [Modified]
slices.add(str.substring(begin, end));
pos = end; // (5) [Modified]
}
slices.add(str.substring(pos)); // (6)
return slices.toArray(new String [slices.size()]); }
首先,在 Line (2) 中,(清單 9 中的 )表達式 len-width 被 offsetByCodePoints(len,-width) 替代。但是,當 width 的值大於碼位的數量時,這會拋出一個 IndexOutOfBoundsException 實 例。必須考慮邊界條件以避免異常,使用一個帶有 try/catch 異常處理程序的 子句將是另一個解決方案。如果表達式 len>width*2 為 true,則可以安全 地調用 offsetByCodePoints(),因為即使所有碼位都被轉換為代理對,碼位的 數量仍會超過 width 的值。或者,如果 codePointCount(0,len)>width 為 true,也可以安全地調用 offsetByCodePoints()。如果是其他情況, sliceLimit 必須設置為 0。
在 Line (4) 中,清單 9 中的表達式 pos + width 必須在 while 循環中使用 offsetByCodePoints(pos,width) 替換。需 要計算的量位於 width 的值中,因為第一個參數指定當 width 的值。接下來, 在 Line (5) 中,表達式 pos+=width 必須使用表達式 pos=end 替換。這避免 兩次調用 offsetByCodePoints() 來計算相同的索引。源代碼可以被進一步修改 以最小化處理時間。
處理時間比較
圖 1 和圖 2 展示了示例 2-1 、2-2 和 2-3 的處理時間。樣例字符串包含相同數量的代理對和非代理對。當 字符串的長度和 width 的值被更改時,樣例字符串被切割 10,000 次。
圖 1. 一個分段的常量寬度
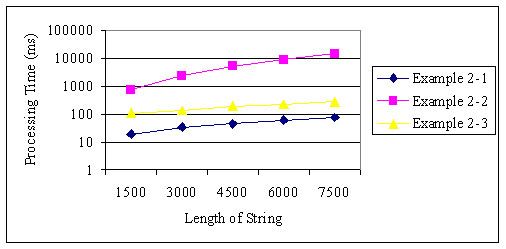
圖 2. 分段的常量計數
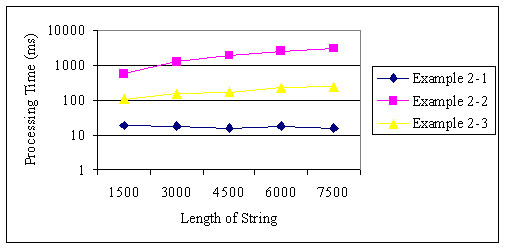
示例 2-1 和 2-3 按照長度比例增加了它們的處理時間,但 示例 2-2 按照長度的平方比例增加了處理時間。當字符串長度和 width 的值增加而分段 的數量固定時,示例 2-1 擁有一個常量處理時間,而示例 2-2 和 2-3 以 width 的值為比例增加了它們的處理時間。
信息 API
大多數處理 代理的信息 API 擁有兩種名稱相同的方法。一種接收 16 位 char 類型參數, 另一種接收 32 為碼位參數。表 2 展示了每個 API 的返回值。第三列針對 U+53F1,第 4 列針對 U+20B9F,最後一列針對 U+D842(即高代理),而 U+20B9F 被轉換為 U+D842 加上 U+DF9F 的代理對。如果程序不能處理代理對, 則值 U+D842 而不是 U+20B9F 將導致意想不到的結果(在表 2 中以粗斜體表示 )。
表 2. 用於代理的信息 API
Character.
UnicodeBlock
Character.UnicodeBlock of(int cp)
CJK_UNIFIED_IDEOGRAPHS
CJK_UNIFIED_IDEOGRAPHS_EXTENSI ON_B
HIGH_SURROGATES
Font
boolean canDisplay(int cp)
(取決於 Font 實例)
FontMetrics
int charWidth(int cp)
(取決於 FontMetrics 實例)
String
int indexOf(int cp)
(取決於 String 實例)
int lastIndexOf(int cp)
(取決於 String 實例)
其他 API
本小節介紹前面的小節中沒有討論 的代理對相關 API。表 3 展示所有這些剩余的 API。所有代理對 API 都包含在 表 1、2 和 3 中。
表 3. 其他代理 API
IllegalFormat
CodePointException
IllegalFormatCodePointException (int cp)
int getCodePoint()
清單 11 展示了從一個碼位創建一個字符串的 5 種 方法。用於測試的碼位是 U+53F1 和 U+20B9F,它們在一個字符串中重復了 100 億次。清單 11 中的注釋部分顯示了處理時間:
清單 11. 從一個碼位 創建一個字符串的 5 種方法
int cp = 0x20b9f; // CJK Ideograph Extension B
String str1 = new String(new int []{cp}, 0, 1); // processing time: 206ms
String str2 = new String(Character.toChars(cp)); // 187ms
String str3 = String.valueOf(Character.toChars(cp)); // 195ms
String str4 = new StringBuilder ().appendCodePoint(cp).toString(); // 269ms
String str5 = String.format("%c", cp); // 3781ms
str1、str2、str3 和 str4 的處理時間沒有明顯不同。相反,創建 str5 花費的時間要長得多,因為它使用 String.format(),該方法支持基 於本地和格式化信息的靈活輸出。str5 方法應該只用於程序的末尾來輸出文本 。
結束語
Unicode 的每個新版本都包含了通過代理對表示的新定 義的字符。東亞字符集標准並不是這樣的字符的惟一來源。例如,移動電話中還 需要支持 Emoji 字符(表情圖釋),還有各種古字符需要支持。您從本文收獲 的技術和性能分析將有助於您在您的 Java 應用程序中支持所有這些字符。