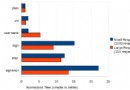
當關系數據庫試圖在一個單一表中存儲數 TB 的數據時,總性能經常會降低。顯然,對所有數據編索引不僅對於讀而且對於寫都很耗時。因為 NoSQL 數據商店尤其適合存儲大型數據(如 Google 的 Bigtable),顯然 NoSQL 是一種非關系數據庫方法。對於傾向於使用 ACID-ity 和實體結構關系數據庫的開發人員及需要這種結構的項目來說,切分是一個令人振奮的可選方法。
切分 是數據庫分區的一個分支,但是它不是本地數據庫技術 — 切分發生在應用程序級別。在各種切分實現中,Hibernate Shards 是 Java™ 技術世界中最受歡迎的一個。這個靈活絕妙的項目可以讓您使用映射至邏輯數據庫的 POJO 對切分數據集進行幾乎無縫操作(我將在下文簡要介紹 “幾乎” 的原因)。使用 Hibernate Shards 時,您無須將您的 POJO 特別映射至切分 — 您可以像使用 Hibernate 方法對任何常見關系數據庫進行映射時一樣對其進行映射。Hibernate Shards 可以為您管理低級別的切分任務。
到目前為止,在本 系列 中,我已經使用了一個基於比賽和參賽者類推關系的簡單域展示了各種數據庫存儲技術。本月,我將繼續使用這個熟悉的示例介紹一種實用的切分技術,然後在 Hibernate Shards 中對其進行實現。注意:與切分相關的主要工作與 Hibernate 沒有太大關系;事實上,Hibernate Shards 的編碼工作比較簡單。其中關鍵的部分在於判斷 如何進行切分以及對什麼進行切分。
關於本系列
自 Java 技術首次誕生以來,Java 開發格局已發生了翻天覆地的變化。得益於成熟的開源框架和可靠的租賃部署基礎設施,現在可以迅速而經濟地組裝、測試、運行和維護 Java 應用程序。在 本系列 中,Andrew Glover 探索使這種新的 Java 開發風格成為可能的各種技術和工具。
切分簡介
數據庫切分 是一個固有的關系流程,可以通過一些邏輯數據塊將一個表的行分為不同的小組。例如,如果您正在根據時間戳對一個名為 foo 的超大型表進行分區,2010 年 8 月之前的所有數據都將進入分區 A,而之後的數據則全部進入分區 B。分區可以加快讀寫速度,因為它們的目標是單獨分區中的較小型數據集。
分區功能並不總是可用的(MySQL 直到 5.1 版本後才支持),而且其需要的商業系統的成本也讓人望而卻步。更重要的是,大部分分區實現在同一個物理機上存儲數據,所以受到硬件基礎的影響。除此之外,分區也不能鑒別硬件的可靠性或者說缺乏可靠性。因此,很多智慧的人們開始尋找進行伸縮的新方法。
切分 實質上是數據庫級別的分區:它不是通過數據塊分割數據表的行,而是通過一些邏輯數據元素對數據庫本身進行分割(通常跨不同的計算機)。也就是說,切分不是將數據表 分割成小塊,而是將整個數據庫 分割成小塊。
切分的一個典型示例是基於根據區域對一個存儲世界范圍客戶數據的大型數據庫進行分割:切分 A 用於存儲美國的客戶信息,切分 B 用戶存儲亞洲的客戶信息,切分 C 歐洲,等。這些切分分別處於不同的計算機上,且每個切分將存儲所有相關數據,如客戶喜好或訂購歷史。
切分的好處(如分區一樣)在於它可以壓縮大型數據:單獨的數據表在每個切分中相對較小,這樣就可以支持更快速的讀寫速度,從而提高性能。切分還可以改善可靠性,因為即便一個切分意外失效,其他切分仍然可以服務數據。而且因為切分是在應用程序層面進行的,您可以對不支持常規分區的數據庫進行切分處理。資金成本較低同樣也是一個潛在優勢。
切分和策略
像很多其他技術一樣,進行切分時也需要作出部分妥協。因為切分不是一項本地數據庫技術 — 也就是說,必須在應用程序中實現 —在開始切分之前需要制定出您的切分策略。進行切分時主鍵和跨切分查詢都扮演重要角色,主要通過定義您不可以做什麼實現。
主鍵
切分利用多個數據庫,其中所有數據庫都獨立起作用,不干涉其他切分。因此,如果您依賴於數據庫序列(如自動主鍵生成),很有可能在一個數據庫集中將出現同一個主鍵。可以跨分布式數據庫協調序列,但是這樣會增加系統的復雜程度。避免相同主鍵最安全的方法就是讓應用程序(應用程序將管理切分系統)生成主鍵。
跨切分查詢
大部分切分實現(包括 Hibernate Shards)不支持跨切分查詢,這就意味著,如果您想利用不同切分的兩個數據集,就必須處理額外的長度。(有趣的是,Amazon 的 SimpleDB 也禁止跨域查詢)例如,如果將美國客戶信息存儲在切分 1 中,還需要將所有相關數據存儲在此。如果您嘗試將那些數據存儲在切分 2 中,情況就會變得復雜,系統性能也可能受影響。這種情況還與之前提到的一點有關 — 如果您因為某種原因需要進行跨切分連接,最好采用一種可以消除重復的方式管理鍵!
很明顯,在建立數據庫前必須全面考慮切分策略。一旦選擇了一個特定的方向之後,您差不多就被它綁定了 — 進行切分後很難隨便移動數據了。
避免不成熟切分
切分最好在後期實現。如不成熟優化一樣,基於預期數據增長的切分可能是災難的溫床。成功的切分實現基於對於應用程序數據隨時間增長的理解,以及之後對於未來的推斷。一旦對數據進行切分後,移動數據會非常困難。
一個策略示例
因為切分將您綁定在一個線型數據模型中(也就是說,您無法輕松連接不同切分中的數據),您必須對如何在每個切分中對數據進行邏輯組織有一個清晰的概念。這可以通過聚焦域中的主要節點實現。如在一個電子商務系統中,主要節點可以是一個訂單或者一個客戶。因此,如果您選擇 “客戶” 作為切分策略的節點,那麼與客戶有關的所有數據將移動至各自的切分中,但是您仍然必須選擇將這些數據移動至哪個切分。
對於客戶來說,您可以根據所在地(歐洲、亞洲、非洲等)切分,或者您也可以根據其他元素進行切分。這由您決定。但是,您的切分策略應該包含將數據均勻分布至所有切分的方法。切分的總體概念是將大型數據集分割為小型數據集;因此,如果一個特定的電子商務域包含一個大型的歐洲客戶集以及一個相對小的美國客戶集,那麼基於客戶所在地的切分可能沒有什麼意義。
回到比賽 — 使用切分!
現在讓我們回到我經常提到的賽跑應用程序示例中,我可以根據比賽或參賽者進行切分。在本示例中,我將根據比賽進行切分,因為我看到域是根據參加不同比賽的參賽者進行組織的。因此,比賽是域的根。我也將根據比賽距離進行切分,因為比賽應用程序包含不同長度和不同參賽者的多項比賽。
請注意:在進行上述決定時,我已經接受了一個妥協:如果一個參賽者參加了不止一項比賽,他們分屬不同的切分,那該怎麼辦呢?Hibernate Shards (像大多數切分實現一樣)不支持跨切分連接。我必須忍受這些輕微不便,允許參賽者被包含在多個切分中 — 也就是說,我將在參賽者參加的多個比賽切分中重建該參賽者。
為了簡便起見,我將創建兩個切分:一個用於 10 英裡以下的比賽;另一個用於 10 英裡以上的比賽。
實現 Hibernate Shards
Hibernate Shards 幾乎可以與現有 Hibernate 項目無縫結合使用。唯一問題是 Hibernate Shards 需要一些特定信息和行為。比如,需要一個切分訪問策略、一個切分選擇策略和一個切分處理策略。這些是您必須實現的接口,雖然部分情況下,您可以使用默認策略。我們將在後面的部分逐個了解各個接口。
ShardAccessStrategy
執行查詢時,Hibernate Shards 需要一個決定首個切分、第二個切分及後續切分的機制。Hibernate Shards 無需確定查詢什麼(這是 Hibernate Core 和基礎數據庫需要做的),但是它確實意識到,在獲得答案之前可能需要對多個切分進行查詢。因此,Hibernate Shards 提供了兩種極具創意的邏輯實現方法:一種方法是根據序列機制(一次一個)對切分進行查詢,直到獲得答案為止;另一種方法是並行訪問策略,這種方法使用一個線程模型一次對所有切分進行查詢。
為了使問題簡單,我將使用序列策略,名稱為 SequentialShardAccessStrategy。我們將稍後對其進行配置。
ShardSelectionStrategy
當創建一個新對象時(例如,當通過 Hibernate 創建一個新 Race 或 Runner 時),Hibernate Shards 需要知道需將對應的數據寫入至哪些切分。因此,您必須實現該接口並對切分邏輯進行編碼。如果您想進行默認實現,有一個名為 RoundRobinShardSelectionStrategy 的策略,它使用一個循環策略將數據輸入切分中。
對於賽跑應用程序,我需要提供根據比賽距離進行切分的行為。因此,我們需要實現 ShardSelectionStrategy 接口並提供依據 Race 對象的 distance 采用 selectShardIdForNewObject 方法進行切分的簡易邏輯。(我將稍候在 Race 對象中展示。)
運行時,當在我的域對象上調用某一類似 save 的方法時,該接口的行為將被深層用於 Hibernate 的核心。
清單 1. 一個簡單的切分選擇策略
import org.hibernate.shards.ShardId;
import org.hibernate.shards.strategy.selection.ShardSelectionStrategy;
public class RacerShardSelectionStrategy implements ShardSelectionStrategy {
public ShardId selectShardIdForNewObject(Object obj) {
if (obj instanceof Race) {
Race rce = (Race) obj;
return this.determineShardId(rce.getDistance());
} else if (obj instanceof Runner) {
Runner runnr = (Runner) obj;
if (runnr.getRaces().isEmpty()) {
throw new IllegalArgumentException("runners must have at least one race");
} else {
double dist = 0.0;
for (Race rce : runnr.getRaces()) {
dist = rce.getDistance();
break;
}
return this.determineShardId(dist);
}
} else {
throw new IllegalArgumentException("a non-shardable object is being created");
}
}
private ShardId determineShardId(double distance){
if (distance > 10.0) {
return new ShardId(1);
} else {
return new ShardId(0);
}
}
}
如您在 清單 1 中所看到的,如果持久化對象是一場 Race,那麼其距離被確定,而且(因此)選擇了一個切分。在這種情況下,有兩個切分:0 和 1,其中切分 1 中包含 10 英裡以上的比賽,切分 0 中包含所有其他比賽。
如果持久化一個 Runner 或其他對象,情況會稍微復雜一些。我已經編碼了一個邏輯規則,其中有三個原則:
一名 Runner 在沒有對應的 Race 時無法存在。
如果 Runner 被創建時參加了多場 Races,這名 Runner 將被持久化到尋找到的首場 Race 所屬的切分中。(順便說一句,該原則對未來有負面影響。)
如果還保存了其他域對象,現在將引發一個異常。
然後,您就可以擦掉額頭的熱汗了,因為大部分艱難的工作已經搞定了。隨著比賽應用程序的增長,我所使用的邏輯可能會顯得不夠靈活,但是它完全可以順利地完成這次演示!
ShardResolutionStrategy
當通過鍵搜索一個對象時,Hibernate Shards 需要一種可以決定首個切分的方法。將需要使用 SharedResolutionStrategy 接口對其進行指引。
如我之前提到的那樣,切分迫使您重視主鍵,因為您將需要親自管理這些主鍵。幸運的是,Hibernate 在提供鍵或 UUID 生成方面表現良好。因此 Hibernate Shards 創造性地提供一個 ID 生成器,名為 ShardedUUIDGenerator,它可以靈活地將切分 ID 信息嵌入到 UUID 中。
如果您最後使用 ShardedUUIDGenerator 進行鍵生成(我在本文中也將采取這種方法),那麼您也可以使用 Hibernate Shards 提供的創新 ShardResolutionStrategy 實現,名為 AllShardsShardResolutionStrategy,這可以決定依據一個特定對象的 ID 搜索什麼切分。
配置好 Hibernate Shards 工作所需的三個接口後,我們就可以對切分示例應用程序的第二步進行實現了。現在應該啟動 Hibernate 的 SessionFactory 了。
配置 Hibernate Shards
Hibernate 的其中一個核心接口對象是它的 SessionFactory。Hibernate 的所有神奇都是在其配置 Hibernate 應用程序過程中通過這個小對象實現的,例如,通過加載映射文件和配置。如果您使用了注釋或 Hibernate 珍貴的 .hbm 文件,那麼您還需要一個 SessionFactory 來讓 Hibernate 知道哪些對象是可以持久化的,以及將它們持久化到 哪裡。
因此,使用 Hibernate Shards 時,您必須使用一個增強的 SessionFactory 類型來配置多個數據庫。它可以被命名為 ShardedSessionFactory,而且它當然是 SessionFactory 類型的。當創建一個 ShardedSessionFactory 時,您必須提供之前配置好的三個切分實現類型(ShardAccessStrategy、ShardSelectionStrategy 和 ShardResolutionStrategy)。您還需提供 POJO 所需的所有映射文件。(如果您使用一個基於備注的 Hibernate POJO 配置,情況可能會有所不同。)最後,一個 ShardedSessionFactory 示例需要每個切分都對應多個 Hibernate 配置文件。
創建一個 Hibernate 配置
我已經創建了一個 ShardedSessionFactoryBuilder 類型,它有一個主要方法 createSessionFactory,可以創建一個配置合理的 SessionFactory。之後,我將將所有的一切都與 Spring 連接在一起(現在誰不使用一個 IOC 容器?)。現在,清單 2 顯示了 ShardedSessionFactoryBuilder 的主要作用:創建一個 Hibernate 配置:
清單 2. 創建一個 Hibernate 配置
private Configuration getPrototypeConfig(String hibernateFile, List<String>
resourceFiles) {
Configuration config = new Configuration().configure(hibernateFile);
for (String res : resourceFiles) {
configs.addResource(res);
}
return config;
}
如您在 清單 2 中所看到的,可以從 Hibernate 配置文件中創建了一個簡單的 Configuration。該文件包含如下信息,如使用的是什麼類型的數據庫、用戶名和密碼等,以及所有必須的資源文件,如 POJO 所用的 .hbm 文件。在進行切分的情況下,您通常需要使用多個數據庫配置,但是 Hibernate Shards 支持您僅使用一個 hibernate.cfg.xml 文件,從而簡化了整個過程(但是,如您在 清單 4 中所看到的,您將需要對使用的每一個切分准備一個 hibernate.cfg.xml 文件)。
下一步,在清單 3 中,我將所有的切分配置都收集到了一個 List 中:
清單 3. 切分配置列表
List<ShardConfiguration> shardConfigs = new ArrayList<ShardConfiguration>();
for (String hibconfig : this.hibernateConfigurations) {
shardConfigs.add(buildShardConfig(hibconfig));
}
Spring 配置
在 清單 3 中,對 hibernateConfigurations 的引用指向了 Strings List,其中每個 String 都包含了 Hibernate 配置文件的名字。該 List 通過 Spring 自動連接。清單 4 是我的 Spring 配置文件中的一段摘錄:
清單 4. Spring 配置文件中的一部分
<bean id="shardedSessionFactoryBuilder"
class="org.disco.racer.shardsupport.ShardedSessionFactoryBuilder">
<property name="resourceConfigurations">
<list>
<value>racer.hbm.xml</value>
</list>
</property>
<property name="hibernateConfigurations">
<list>
<value>shard0.hibernate.cfg.xml</value>
<value>shard1.hibernate.cfg.xml</value>
</list>
</property>
</bean>
如您在 清單 4 中所看到的,ShardedSessionFactoryBuilder 正在與一個 POJO 映射文件和兩個切分配置文件連接。清單 5 中是 POJO 文件的一段摘錄:
清單 5. 比賽 POJO 映射
<class name="org.disco.racer.domain.Race" table="race"dynamic-update="true"
dynamic-insert="true">
<id name="id" column="RACE_ID" unsaved-value="-1">
<generator class="org.hibernate.shards.id.ShardedUUIDGenerator"/>
</id>
<set name="participants" cascade="save-update" inverse="false" table="race_participants"
lazy="false">
<key column="race_id"/>
<many-to-many column="runner_id" class="org.disco.racer.domain.Runner"/>
</set>
<set name="results" inverse="true" table="race_results" lazy="false">
<key column="race_id"/>
<one-to-many class="org.disco.racer.domain.Result"/>
</set>
<property name="name" column="NAME" type="string"/>
<property name="distance" column="DISTANCE" type="double"/>
<property name="date" column="DATE" type="date"/>
<property name="description" column="DESCRIPTION" type="string"/>
</class>
請注意,清單 5 中的 POJO 映射的唯一獨特方面是 ID 的生成器類 — 這就是 ShardedUUIDGenerator,它(如您想象的一樣)將切分 ID 信息嵌入到 UUID 中。這就是我的 POJO 映射中切分的唯一獨特方面。
切分配置文件
下一步,如清單 6 中所示,我已經配置了一個切分 — 在本示例中,除切分 ID 和連接信息外,切分 0 和切分 1 的文件是一樣的。
清單 6. Hibernate Shards 配置文件
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="HibernateSessionFactory0">
<property name="dialect">org.hibernate.dialect.HSQLDialect</property>
<property name="connection.driver_class">org.hsqldb.jdbcDriver</property>
<property name="connection.url">
jdbc:hsqldb:file:/.../db01/db01
</property>
<property name="connection.username">SA</property>
<property name="connection.password"></property>
<property name="hibernate.connection.shard_id">0</property>
<property name="hibernate.shard.enable_cross_shard_relationship_checks">true
</property>
</session-factory>
</hibernate-configuration>
如其名字所示,enable_cross_shard_relationship_checks 屬性對跨切分關系進行了檢查。根據 Hibernate Shards 文檔記錄,該屬性非常耗時,在生成環境中應該關閉。
最後,ShardedSessionFactoryBuilder 通過創建 ShardStrategyFactory ,然後添加三個類型(包括 清單 1 中的 RacerShardSelectionStrategy),將一切都整合到了一起,如清單 7 中所示:
清單 7. 創建 ShardStrategyFactory
private ShardStrategyFactory buildShardStrategyFactory() {
ShardStrategyFactory shardStrategyFactory = new ShardStrategyFactory() {
public ShardStrategy newShardStrategy(List<ShardId> shardIds) {
ShardSelectionStrategy pss = new RacerShardSelectionStrategy();
ShardResolutionStrategy prs = new AllShardsShardResolutionStrategy(shardIds);
ShardAccessStrategy pas = new SequentialShardAccessStrategy();
return new ShardStrategyImpl(pss, prs, pas);
}
};
return shardStrategyFactory;
}
最後,我執行了那個名為 createSessionFactory 的絕妙方法,在本示例中創建了一個 ShardedSessionFactory,如清單 8 所示:
清單 8. 創建 ShardedSessionFactory
public SessionFactory createSessionFactory() {
Configuration prototypeConfig = this.getPrototypeConfig
(this.hibernateConfigurations.get(0), this.resourceConfigurations);
List<ShardConfiguration> shardConfigs = new ArrayList<ShardConfiguration>();
for (String hibconfig : this.hibernateConfigurations) {
shardConfigs.add(buildShardConfig(hibconfig));
}
ShardStrategyFactory shardStrategyFactory = buildShardStrategyFactory();
ShardedConfiguration shardedConfig = new ShardedConfiguration(
prototypeConfig, shardConfigs,shardStrategyFactory);
return shardedConfig.buildShardedSessionFactory();
}
使用 Spring 連接域對象
現在可以深呼吸一下了,因為我們馬上就成功了。到目前為止,我已經創建一個可以合理配置 ShardedSessionFactory 的生成器類,其實就是實現 Hibernate 無處不在的 SessionFactory 類型。ShardedSessionFactory 完成了切分中所有的神奇。它利用我在 清單 1 中所部署的切分選擇策略,並從我配置的兩個切分中讀寫數據。(清單 6 顯示了切分 0 和切分 1 的配置幾乎相同。)
現在我需要做的就是連接我的域對象,在本示例中,因為它們依賴於 Hibernate,需要一個 SessionFactory 類型進行工作。我將僅使用我的 ShardedSessionFactoryBuilder 提供一種 SessionFactory 類型,如清單 9 中所示:
清單 9. 在 Spring 中連接 POJO
<bean id="mySessionFactory"
factory-bean="shardedSessionFactoryBuilder"
factory-method="createSessionFactory">
</bean>
<bean id="race_dao" class="org.disco.racer.domain.RaceDAOImpl">
<property name="sessionFactory">
<ref bean="mySessionFactory"/>
</property>
</bean>
如您在 清單 9 中所看到的,我首先在 Spring 中創建了一個類似工廠的 bean;也就是說,我的 RaceDAOImpl 類型有一個名為 sessionFactory 的屬性,是 SessionFactory 類型。之後,mySessionFactory 引用通過在 ShardedSessionFactoryBuilder 上調用 createSessionFactory 方法創建了一個 SessionFactory 示例,如 清單 4 中所示。
當我為我的 Race 對象示例使用 Spring(我主要將其作為一個巨型工廠使用,以返回預配置的對象)時,一切事情就都搞定了。雖然沒有展示,RaceDAOImpl 類型是一個利用 Hibernate 模板進行數據存儲和檢索的對象。我的 Race 類型包含一個 RaceDAOImpl 示例,它將所有與數據商店相關的活動都推遲至此。很默契,不是嗎?
請注意,我的 DAO 與 Hibernate Shards 在代碼方面並沒有綁定,而是通過配置進行了綁定。配置(如 清單 5 中的)將它們綁定在一個特定切分 UUID 生成方案中,也就是說了我可以在需要切分時從已有 Hibernate 實現中重新使用域對象。
切分:使用 easyb 的測試驅動
接下來,我需要驗證我的切分實現可以工作。我有兩個數據庫並通過距離進行切分,所以當我創建一場馬拉松時(10 英裡以上的比賽),該 Race 示例應在切分 1 中找到。一個小型的比賽,如 5 公裡的比賽(3.1 英裡),將在切分 0 中找到。創建一場 Race 後,我可以檢查單個數據庫的記錄。
在清單 10 中,我已經創建了一場馬拉松,然後繼續驗證記錄確實是在切分 1 中而非切分 0 中。使事情更加有趣(和簡單)的是,我使用了 easyb,這是一個基於 Groovy 的行為驅動開發架構,利用自然語言驗證。easyb 也可以輕松處理 Java 代碼。即便不了解 Groovy 或 easyb,您也可以通過查看清單 10 中的代碼,看到一切如期進行。(請注意,我幫助創建了 easyb,並且在 developerWorks 中對這個話題發表過文章。)
清單 10. 一個驗證切分正確性的 easyb 故事中一段摘錄
scenario "races greater than 10.0 miles should be in shard 1 or db02", {
given "a newly created race that is over 10.0 miles", {
new Race("Leesburg Marathon", new Date(), 26.2,
"Race the beautiful streets of Leesburg!").create()
}
then "everything should work fine w/respect to Hibernate", {
rce = Race.findByName("Leesburg Marathon")
rce.distance.shouldBe 26.2
}
and "the race should be stored in shard 1 or db02", {
sql = Sql.newInstance(db02url, name, psswrd, driver)
sql.eachRow("select race_id, distance, name from race where name=?",
["Leesburg Marathon"]) { row ->
row.distance.shouldBe 26.2
}
sql.close()
}
and "the race should NOT be stored in shard 0 or db01", {
sql = Sql.newInstance(db01url, name, psswrd, driver)
sql.eachRow("select race_id, distance, name from race where name=?",
["Leesburg Marathon"]) { row ->
fail "shard 0 contains a marathon!"
}
sql.close()
}
}
當然,我的工作還沒有完 — 我還需要創建一個短程比賽,並驗證其位於切分 0 中而非切分 1 中。您可以在本文提供的 代碼下載 中看到該驗證操作!
切分的利弊
切分可以增加應用程序的讀寫速度,尤其是如果您的應用程序包含大量數據 — 如數 TB — 或者您的域處於無限制發展中,如 Google 或 Facebook。
在進行切分之前,一定要確定應用程序的規模和增長對其有利。切分的成本(或者說缺點)包括對如何存儲和檢索數據的特定應用程序邏輯進行編碼的成本。進行切分後,您多多少少都被鎖定在您的切分模型中,因為重新切分並非易事。
如果能夠正確實現,切分可以用於解決傳統 RDBMS 規模和速度問題。切分對於綁定於關系基礎架構、無法繼續升級硬件以滿足大量可伸縮數據存儲要求的組織來說是一個非常成本高效的決策。
下載