摘要
JDK1.1包括了新的數據庫存 取(JDBC)及組件(JavaBeans)的應用程序接口(APIs)。這兩個API結合在一起,可用來開發通用 數據庫代碼。通過用唯一的一個類去存取任何一種JDBC數據庫(封裝於不同組件中的各個應用 程序有著其具體的編碼),用戶就不必因為數據庫結構一點點的細小變化去修改數據庫編碼。
一個關系數據庫基本上包括一系 列相互關連的表,在每一個表中存有一類與應用系統相關的數據。例如一個地址簿數據庫中,可 能有關於人員、住址、電話號碼等方面的表。在數據庫中,每一個這樣的實體將被作為一系列的 字符串,整數及其它原始數據類型存貯起來。數據庫中,表的定義將描述每一種與實體相關的信 息如何在一個表的字段中存儲。例如,你可以在一個名為“人”的表中,有兩個字段別表示所存字 符串為“姓”和“名”。每一張表應當有一個或幾個字段值作為標識,確保每條記錄的唯一性。這些 標識或“鍵”可以用來連接存在於不同表中的信息。例如你可以在“人員”表中,為每個人指定唯 一的“人員號碼”的鍵值,並在“地址”表中的相應字段中使用同一個鍵值。這樣,你可以通過對兩 個表中的“人員號碼”字段值的匹配,使每一個人和他的地址關聯起來。
關系數據庫系統出現於七十年代, 時至今日,它仍然是存儲巨量數據的主要方式。因而,Java軟件工具有必要具備處理關系數據庫 的能力。
關系數據庫要想被某個Java應用 程序利用,首先需要解決兩個問題。第一:需要某些基礎的中間件來建立與數據庫的連接,向數 據庫發出SQL查詢等等;第二:操縱數據庫的處理結果要與操縱任何一種Java信息一樣方便—— 作為一個對象。前一個問題已被SUN及幾個數據庫產商解決;後一個問題則有待我們進一步去探 究。
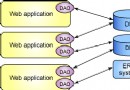
在為普通的程序開發業務定義大 量的APIs這項工作上,SUN一直保持著與許多軟件公司的合作關系。在JDK1.1APIs中,JDBC 的API是最早建立起來的。而且,它已得到了為數眾多的應用。這些應用中,有的是100%的 純Java,有的則是Java和其它程序的混合體,如:用現有的ODBC數據源進行連接(參看 圖1)。JavaSoft已將一個關於現有的JDBC驅動程序的介紹放在它的Web站點 上(http://splash.javasoft.com/jdbc/jdbc.drivers.html)。
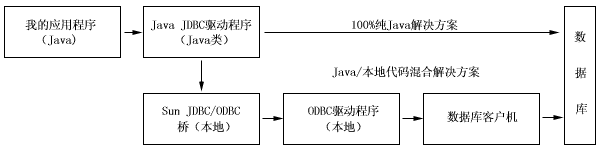
圖1一個典型的JDBC或JDBC/ODBC配置
注意:此圖已被簡化。另外的組件 已包括其中(如ODBD驅動程序)
非常明顯,這些應用的優缺點取決 於你的環境和設置,在此我不准備對它們的各種情況進行逐一論述。在下面的內容中,我們假 定,在你的機器中已擁有某種Java開發環境,並且你已正確地安裝並測試過某個JDBC驅動程序, 或者運用過某種JDBC驅動程序及SUN的JDBC/ODBC橋。
JDBCAPI
JDBCAPI作為一個單獨的Java 包(或類庫,即java.sql)出現,包括有一系列的類。這些類提供了處理某個關系數據庫的中間 件。本質上講,它們使得你可以關聯某個數據庫,並向其發出查詢。你可以對這些查詢結果進行 處理,檢索你數據庫的meta-信息(meta-information),並且處理在此間可能發生的各種異常情況。
讓我們來看一個簡 單的JDBC例子,看一看應用了JavaJDBC之後,查詢會得到怎樣的簡化。表1是一個極其簡單的數 據庫。在清單1中的編碼是一段最簡單的對關系數據庫進行SQL查詢所需的Java語句。
人員 # 名 姓 43674 Sandor Spruit 90329 John Doe 65435 Donald DuckString ur1="jdbc:odbc:sample";
String query="SELECT * FROM PERSON";
boolean more;
try
{
Class.forName("sun.jdbc.odbc.jdbcOdbcDriver");
Connection con = DriverManager.getConnection(ur1,"sandor","guest");
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(query);
While (more = rs,next())
{
int number = rs.getInt("PERSON#");
String firstName = rs.getString("FIRST_NAME");
String lastName = rs.getString("LAST_NAME");
System.out.printIn(number + " " + firstName + " " + lastName);
}
rs.close();
stmt.close();
con.close();
}
catch(SQLException ex)
{
ex.printStackTrace();
}
清單1:一個應用了JDBC的SQL查詢
這段編碼的含義是:先裝入SUN 的JDBC/ODBC驅動程序,然後與被jdbc:odbc:sample指定的數據庫建立起一個關聯,最後對該數 據庫進行一個簡單的SELECT查詢。如果沒有遇到查詢異常(SQLException),程序將循環地從結 果集(Result Set)中每次抽出一條數據庫記錄,並將其顯示在屏幕上。
好了,現在我們來看一看這段程序 還有哪些不足?在清單1的這類程序中,存在著兩個根本性的錯誤:
1.這種編碼用到了數量眾多的 數據庫meta-信息,而這些信息都只能手工編碼到程序中。當你想要取一個數值時,你必須提前 知道你將取到的數值是一個整數、浮點數、還是一個雙精度數。這將會使得編寫一個可以處理任 何一個數據庫的類變得十分困難;並且每一個數據庫的細小調整都會逼你去仔細地檢查和修改 程序。
2.數據庫中的信息總是作為一 個單個的RecordSet(記錄集)實例來傳遞,而這種實例並不是一個真正的對象。RecordSet類( 與其它的數據庫類封裝沒什麼差別)更象一個指針或游標,借助方法,它能夠提供存取數據信息 的途徑。RecordSet中的實例實際上並不包括信息,它們僅僅表示獲得信息的方式。這正說明了 當你要調用另外的Record Set方法去獲取某些真實的數據信息的時候,你必須通過Record Set去 做更多的工作(利用RecordSet.NEXT()去移動指針)。實際上,JDBC類的確僅僅傳遞這類聯系松 散的字段。即使你完全了解數據庫的所有內部細節,這也沒有任何價值,因為在Java提供了存儲 和處理信息的方法。
所以,理想的狀態是,有一種好的 方法,能夠逐一地從數據庫中抽取記錄或字段(通過Record Set),並且將取到的信息“填”入到新 生成的對象之中。
這一解決方式的關鍵在於關系數 據庫(RDB)和面向對象的數據模型(ODB)之間的相似性。RDB中的表和ODB中的類的作用很相似, 而記錄和對象也有著某些相同的屬性。你可以將記錄看作是用來初始化某個對象的數據元素的 數據組。如果你已將記錄從數據庫中抽取出來,就必須調用類構造函數來生成上面所說的對象。 若能夠將每一條記錄自動地傳到適當的構造函數中,就可以輕而易舉地由記錄來構造對象。
在開發一個小的應用程序時,有可 能將每一個記錄傳遞給某個構造函數,以此來生成新的對象。你可以經常利用對象參照來操縱 從數據庫中抽取的任何數據。因為你通過Record Set所得到的每一個對象最終都 是java.lang.Object的擴充。你可以定義一個BibClass,使其具有各類的共同屬性,Big Class類 操作將利用Javainstanceof算子來實時決定運行中所遇到的數據庫信息,並且通過一個大 的switch選擇,跳到相應的程序段中。
你也可以定義一個相似的帶有多 個構造函數的BigClass,每個構造函數有差別不太大的調用參數。你可以 用BigClass(int,int),BigClass(int,float)等等,取決於你從RecordSet中循環取出的數據的 類型(這一方法當然將會包括許多冗余代碼)。
然而,以上兩種方法都不能真正解 決問題。因為記錄和構造函數在程序中的關系仍將是僵硬的。若想得到通用的數據庫編碼,必須 自動地建立數據庫和構造函數二者的關聯。
Java的性能對於此時的我們就如 雪中送碳。清單2中的程序片段只需一個類名就可以建造一個Java類。這樣,我們就可以憑借類 和表的名稱來識別那些可以處理從表中抽取出的記錄的構造函數。利用標准的JDBC類,可以容 易地獲得所有表的表名,在此,我們將要充分利用這個Java小技巧。只要簡單地為每個數據庫表 開辟一個Java類,使類名和表名相互匹配,無論何時,每當從表中抽取出一條記錄的時候,通過 將表名傳遞給Class.forName(),程序將自動生成一個對象。
Class c = class.forName("Person");
Person p = (Person)c.newInstance();
System。out.println("... just created a " + c.getName();
清單2:一個簡單的Class.forName()例子
然而,此處還有一些問題。由於對 某些特定的類來說,forName()函數需要調用參數為void的構造函數,所以不能將RecordSet變 量直接傳遞給構造函數。在這裡,我們需要一個初始化函數,把從數據庫中抽取出的記錄作 為RESULTSET參數,將其值賦予對象的數據元素。一個好的方法是引入超級類,並將其作為所有 數據庫表相關類的通用父類。實際上,這個超級類在數據庫查詢中充當著重要的角色,我們將在 下面展示這一點。
查詢數據庫
利用上面的方法可以由記錄生成 對象,但是你仍然得用SQL語句來查詢數據庫,這需要對數據庫結構有深入的了解。這還是沒有 解決問題,雖然我們能夠自動地匹配數據庫表和類的名字,但是還是必須手工編寫SQL語句。這 就是說每次修改數據庫結構後,將不得不手工編輯這些查詢語句。不過,我們仍然可以利用前文 所述的方法來越過這個障礙。通常而言,查詢關系數據庫時,你將會用到屬於主鍵或索引的字段 名和值。一言弊之,如果某人向你提供了適當的字段名和字段值,你就可以從相應的數據庫中抽 取符合要求的記錄(或字段)。而DatabaseMetaData對象不但可以被用於檢索一系列的表名(見 上所述),而且可以獲得一系列的主鍵及索引字段。上面的問題由此可以迎刃而解。
通過填入一系列適當的(字段名,字段值)對,可以利用相對而言少得多的代碼實現對關系數據庫的查詢。你可以將對子中的所有字段名和數據庫中的主健及索引字段相匹配。每當你找到了名字列表中相應的主健或索引字 段,可以根據相應的數值來生成一個SQL語句,執行它來獲取RecordSet,並通過Class.forName()構造機制將結果轉化為對象。
實現這一想法要求可以以(名,值)對的方式對與數據庫表相關的每個類的數據元素進行存取。但是這種方法只有通過上節所述的通用父類才能趨於完美。清單3和4利用偽碼表示了這一方法。
Open the database connection 清單3: 初始化數據庫連接的偽碼
Retrieve a list of user defined tables
for each table
{
Check where there is a corresponding class file
if(it is availabe)
{
load the class file
Retrieve lists of key fields and indeces for this table
Store these lists in hashtables for easy access
}
else throw an exception
}
Take an object A containing a series of (name,value) pairs
for each table T
{
for each (name,value) pair
{
if(name matches primary_key_field or index_field)
store a refrence to both name and value
}
if all key_fields were found
create a query string using key names and values
else if all index_fields were found
create a query string using index names and values
execute the query to obtain a ResultSet
For each record in the ResultSet
{
Create an object of the class associated with table T
initialize the object using the record's contents
Add the object to the results, e。g。, attach it to A
}
}
清單4:描述數據庫查詢的偽碼
Java鏡像和Java beans
Java1.1開發套件(JDK)的引入, 為我們帶來了許多強大的新性能,例如全新的用戶界面接口類。有兩個新的JDKAPI尤其值得注 意:鏡像機制(java.lang.reflect包)和JavaBeans組件的應用程序接口(java.beans包)。這兩 個API將會幫助我們創建高明的數據庫類,使我們可以利用有關類的meta-信息,以此來解決開 發通用數據庫類中的問題。
擁有forName()和newInstance() 方法的Class類,僅僅是鏡象(reflection)功能的一個簡單例子。真正重要的是,forName()字符 串參數不必須是源程序中出現的字符串。只要給出一個名字(這個名字可從任何地方取來), 你就可以載入並實例化任何一個類。對於我們的數據庫類,我們可以直接從數據庫自身的表名 中得到類名。這就是說,與數據庫表相關的Java類名並不需要出現在源程序中。相應地,當表名 改變或某個表被加入到數據庫中時,不需要修改源碼,只要確信帶有新名字的類已存在你的系 統中。
鏡像類意味著可以在實時運行中 獲取、存儲和處理Java程序中的類信息。它們的實例能夠象任何Java對象一樣被運用,你可以象 修改字符串和整數一樣,去修改類、數據類型、返回類型、方法參照和參數。在源程序級,這個鏡 像的概念看起來並沒有什麼價值——因為可以應用你自己的編碼直接存取你所需要的有關類、 方法及參數的所有信息。但是,鏡像(reflection)將會在java的編譯文件中發揮作 用。JavaBeansAPI的作用是:通過應用程序的構造機制利用來自於全然不同的開發者或產商所 編寫的類。
JavaBeans規范為類成員的名字 制定一系列的條例。以確保方法函數的名字能系統地描述它們的功能。任何一個符合規則 的Java類都可以被一個Bean的內化實例(通過鏡像)檢查,以揭示其行為的重要特征——諸如對 於什麼樣的事件類將有所響應,以及該類將會產生什麼樣的事件等等。任何符合這些規范的類 都是高效的Bean,因而是一個組件。在理論上,這意味著你可以從各種來源收集一系列beans,當 需要它們時可以將其其實時地綁在一起。
一個Bean的例子
在下面一個名為Translation 的Bean中,有一個構造函數和兩個方法來操作一個名為“language”的屬性。這裡我想強調的是, 既然你可以通過檢查一個類的代碼來了解它的構造函數、方法及屬性,那麼Bean的內化 器(Introspector)也能做到。
public class Translation extends Object
{
int language;
public translation()
{
}
public int getlanguage()
{
return(language);
}
public void setLanguage( int language)
{
this。language=language;
}
}
清單5:一個非常簡單的Bean
一個BeanIntro spector能夠提供 許多數組的Property Descriptor實例,這些實例包含所有Bean的屬性的類型信息,即例子中 由get/set方法所定義的類型。你可以調用這些方法(利用reflection)來讀或寫這些屬性。
鏡像機制(reflection facilities)為我們檢查原本松散的類和數據庫表的完整性提供了的更好方法。實際上,僅僅 通過類名和一個表匹配並不一定能夠保證一些類內部的一致性。一個與表相關的類顯然應當具 備存儲數據庫表中所有字段的數據元素。一個類可能有適當的名字,但其初始化代碼可能會省 略。它可能只有一個正確的名字,而其數據成員可能有不同的名字或者是不同的類型。使用JDBC 的DatabaseMetaData及鏡像機制可以檢查它們是否完全匹配!
引用一些JDBC調用去獲得現實中 必須的數據庫信息,通過正確的名字去檢查你系統中的類,並且通過鏡像去比較表和類的屬性, 這實實在在是一塊香餅!
結論和啟示
JDBC,鏡像和Java Beans三者的結 合,能夠方便地從關系數據庫中存取記錄並利用記錄來初始化組件(不僅僅是對象)。為了實現 上述操作,無需修改你的數據庫,只需確認你的類符合Bean規范,並使類屬性和表字段相互匹 配。Beans還有其它一些簡單的技巧,可使編程更加有趣。Beans能夠提供自己的用戶界面組件, 並且Beans規范還包括一個名為Customizers的東西。你可以引入另外的類專門地去察看、編輯 和自行定制一個Bean類的實例。(關於定制Beans,請參看下一期《定制你的Java》
總之,我們可以為數據庫類編寫自 行定義的類,應用程序能夠從關系數據庫中抽取數據,通過實例化某個類得到新的實例,並引入 相關的圖形用戶界面(GUI)組件來查看和編輯數據。所有這些都由通用代碼完成,因而能夠處理 任何數據庫。利用Java編寫的、功能齊全的數據庫查看/編輯器正迎我們而來。