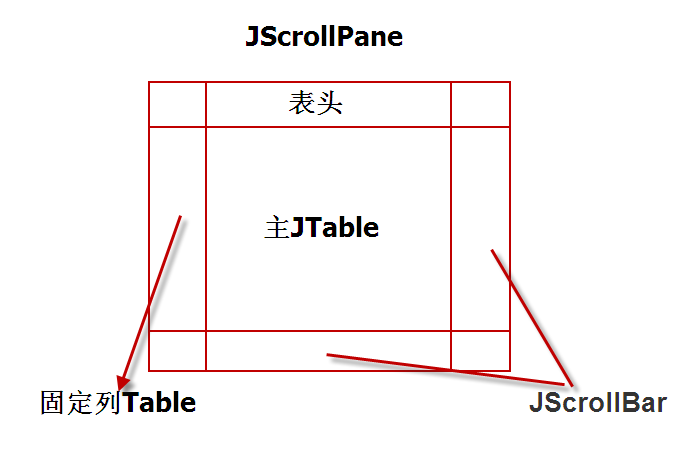
對於本書每一個完整的代碼列表(不是代碼段),大家無疑會注意到它們都用特殊的注釋記號起始與結束('//:'和'///:~')。之所以要包括這種標志信息,是為了能將代碼從本書自動提取到兼容的源碼文件中。在我的前一本書裡,我設計了一個系統,可將測試過的代碼文件自動合並到書中。但對於這本書,我發現一種更簡便的做法是一旦通過了最初的測試,就把代碼粘貼到書中。而且由於很難第一次就編譯通過,所以我在書的內部編輯代碼。但如何提取並測試代碼呢?這個程序就是關鍵。如果你打算解決一個文字處理的問題,那麼它也很有利用價值。該例也演示了String類的許多特性。
我首先將整本書都以ASCII文本格式保存成一個獨立的文件。CodePackager程序有兩種運行模式(在usageString有相應的描述):如果使用-p標志,程序就會檢查一個包含了ASCII文本(即本書的內容)的一個輸入文件。它會遍歷這個文件,按照注釋記號提取出代碼,並用位於第一行的文件名來決定創建文件使用什麼名字。除此以外,在需要將文件置入一個特殊目錄的時候,它還會檢查package語句(根據由package語句指定的路徑選擇)。
但這樣還不夠。程序還要對包(package)名進行跟蹤,從而監視章內發生的變化。由於每一章使用的所有包都以c02,c03,c04等等起頭,用於標記它們所屬的是哪一章(除那些以com起頭的以外,它們在對不同的章進行跟蹤的時候會被忽略)——只要每一章的第一個代碼列表包含了一個package,所以CodePackager程序能知道每一章發生的變化,並將後續的文件放到新的子目錄裡。
每個文件提取出來時,都會置入一個SourceCodeFile對象,隨後再將那個對象置入一個集合(後面還會詳盡講述這個過程)。這些SourceCodeFile對象可以簡單地保存在文件中,那正是本項目的第二個用途。如果直接調用CodePackager,不添加-p標志,它就會將一個“打包”文件作為輸入。那個文件隨後會被提取(釋放)進入單獨的文件。所以-p標志的意思就是提取出來的文件已被“打包”(packed)進入這個單一的文件。
但為什麼還要如此麻煩地使用打包文件呢?這是由於不同的計算機平台用不同的方式在文件裡保存文本信息。其中最大的問題是換行字符的表示方法;當然,還有可能存在另一些問題。然而,Java有一種特殊類型的IO數據流——DataOutputStream——它可以保證“無論數據來自何種機器,只要使用一個DataInputStream收取這些數據,就可用本機正確的格式保存它們”。也就是說,Java負責控制與不同平台有關的所有細節,而這正是Java最具魅力的一點。所以-p標志能將所有東西都保存到單一的文件裡,並采用通用的格式。用戶可從Web下載這個文件以及Java程序,然後對這個文件運行CodePackager,同時不指定-p標志,文件便會釋放到系統中正確的場所(亦可指定另一個子目錄;否則就在當前目錄創建子目錄)。為確保不會留下與特定平台有關的格式,凡是需要描述一個文件或路徑的時候,我們就使用File對象。除此以外,還有一項特別的安全措施:在每個子目錄裡都放入一個空文件;那個文件的名字指出在那個子目錄裡應找到多少個文件。
下面是完整的代碼,後面會對它進行詳細的說明:
//: CodePackager.java
// "Packs" and "unpacks" the code in "Thinking
// in Java" for cross-platform distribution.
/* Commented so CodePackager sees it and starts
a new chapter directory, but so you don't
have to worry about the directory where this
program lives:
package c17;
*/
import java.util.*;
import java.io.*;
class Pr {
static void error(String e) {
System.err.println("ERROR: " + e);
System.exit(1);
}
}
class IO {
static BufferedReader disOpen(File f) {
BufferedReader in = null;
try {
in = new BufferedReader(
new FileReader(f));
} catch(IOException e) {
Pr.error("could not open " + f);
}
return in;
}
static BufferedReader disOpen(String fname) {
return disOpen(new File(fname));
}
static DataOutputStream dosOpen(File f) {
DataOutputStream in = null;
try {
in = new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream(f)));
} catch(IOException e) {
Pr.error("could not open " + f);
}
return in;
}
static DataOutputStream dosOpen(String fname) {
return dosOpen(new File(fname));
}
static PrintWriter psOpen(File f) {
PrintWriter in = null;
try {
in = new PrintWriter(
new BufferedWriter(
new FileWriter(f)));
} catch(IOException e) {
Pr.error("could not open " + f);
}
return in;
}
static PrintWriter psOpen(String fname) {
return psOpen(new File(fname));
}
static void close(Writer os) {
try {
os.close();
} catch(IOException e) {
Pr.error("closing " + os);
}
}
static void close(DataOutputStream os) {
try {
os.close();
} catch(IOException e) {
Pr.error("closing " + os);
}
}
static void close(Reader os) {
try {
os.close();
} catch(IOException e) {
Pr.error("closing " + os);
}
}
}
class SourceCodeFile {
public static final String
startMarker = "//:", // Start of source file
endMarker = "} ///:~", // End of source
endMarker2 = "}; ///:~", // C++ file end
beginContinue = "} ///:Continued",
endContinue = "///:Continuing",
packMarker = "###", // Packed file header tag
eol = // Line separator on current system
System.getProperty("line.separator"),
filesep = // System's file path separator
System.getProperty("file.separator");
public static String copyright = "";
static {
try {
BufferedReader cr =
new BufferedReader(
new FileReader("Copyright.txt"));
String crin;
while((crin = cr.readLine()) != null)
copyright += crin + "\n";
cr.close();
} catch(Exception e) {
copyright = "";
}
}
private String filename, dirname,
contents = new String();
private static String chapter = "c02";
// The file name separator from the old system:
public static String oldsep;
public String toString() {
return dirname + filesep + filename;
}
// Constructor for parsing from document file:
public SourceCodeFile(String firstLine,
BufferedReader in) {
dirname = chapter;
// Skip past marker:
filename = firstLine.substring(
startMarker.length()).trim();
// Find space that terminates file name:
if(filename.indexOf(' ') != -1)
filename = filename.substring(
0, filename.indexOf(' '));
System.out.println("found: " + filename);
contents = firstLine + eol;
if(copyright.length() != 0)
contents += copyright + eol;
String s;
boolean foundEndMarker = false;
try {
while((s = in.readLine()) != null) {
if(s.startsWith(startMarker))
Pr.error("No end of file marker for " +
filename);
// For this program, no spaces before
// the "package" keyword are allowed
// in the input source code:
else if(s.startsWith("package")) {
// Extract package name:
String pdir = s.substring(
s.indexOf(' ')).trim();
pdir = pdir.substring(
0, pdir.indexOf(';')).trim();
// Capture the chapter from the package
// ignoring the 'com' subdirectories:
if(!pdir.startsWith("com")) {
int firstDot = pdir.indexOf('.');
if(firstDot != -1)
chapter =
pdir.substring(0,firstDot);
else
chapter = pdir;
}
// Convert package name to path name:
pdir = pdir.replace(
'.', filesep.charAt(0));
System.out.println("package " + pdir);
dirname = pdir;
}
contents += s + eol;
// Move past continuations:
if(s.startsWith(beginContinue))
while((s = in.readLine()) != null)
if(s.startsWith(endContinue)) {
contents += s + eol;
break;
}
// Watch for end of code listing:
if(s.startsWith(endMarker) ||
s.startsWith(endMarker2)) {
foundEndMarker = true;
break;
}
}
if(!foundEndMarker)
Pr.error(
"End marker not found before EOF");
System.out.println("Chapter: " + chapter);
} catch(IOException e) {
Pr.error("Error reading line");
}
}
// For recovering from a packed file:
public SourceCodeFile(BufferedReader pFile) {
try {
String s = pFile.readLine();
if(s == null) return;
if(!s.startsWith(packMarker))
Pr.error("Can't find " + packMarker
+ " in " + s);
s = s.substring(
packMarker.length()).trim();
dirname = s.substring(0, s.indexOf('#'));
filename = s.substring(s.indexOf('#') + 1);
dirname = dirname.replace(
oldsep.charAt(0), filesep.charAt(0));
filename = filename.replace(
oldsep.charAt(0), filesep.charAt(0));
System.out.println("listing: " + dirname
+ filesep + filename);
while((s = pFile.readLine()) != null) {
// Watch for end of code listing:
if(s.startsWith(endMarker) ||
s.startsWith(endMarker2)) {
contents += s;
break;
}
contents += s + eol;
}
} catch(IOException e) {
System.err.println("Error reading line");
}
}
public boolean hasFile() {
return filename != null;
}
public String directory() { return dirname; }
public String filename() { return filename; }
public String contents() { return contents; }
// To write to a packed file:
public void writePacked(DataOutputStream out) {
try {
out.writeBytes(
packMarker + dirname + "#"
+ filename + eol);
out.writeBytes(contents);
} catch(IOException e) {
Pr.error("writing " + dirname +
filesep + filename);
}
}
// To generate the actual file:
public void writeFile(String rootpath) {
File path = new File(rootpath, dirname);
path.mkdirs();
PrintWriter p =
IO.psOpen(new File(path, filename));
p.print(contents);
IO.close(p);
}
}
class DirMap {
private Hashtable t = new Hashtable();
private String rootpath;
DirMap() {
rootpath = System.getProperty("user.dir");
}
DirMap(String alternateDir) {
rootpath = alternateDir;
}
public void add(SourceCodeFile f){
String path = f.directory();
if(!t.containsKey(path))
t.put(path, new Vector());
((Vector)t.get(path)).addElement(f);
}
public void writePackedFile(String fname) {
DataOutputStream packed = IO.dosOpen(fname);
try {
packed.writeBytes("###Old Separator:" +
SourceCodeFile.filesep + "###\n");
} catch(IOException e) {
Pr.error("Writing separator to " + fname);
}
Enumeration e = t.keys();
while(e.hasMoreElements()) {
String dir = (String)e.nextElement();
System.out.println(
"Writing directory " + dir);
Vector v = (Vector)t.get(dir);
for(int i = 0; i < v.size(); i++) {
SourceCodeFile f =
(SourceCodeFile)v.elementAt(i);
f.writePacked(packed);
}
}
IO.close(packed);
}
// Write all the files in their directories:
public void write() {
Enumeration e = t.keys();
while(e.hasMoreElements()) {
String dir = (String)e.nextElement();
Vector v = (Vector)t.get(dir);
for(int i = 0; i < v.size(); i++) {
SourceCodeFile f =
(SourceCodeFile)v.elementAt(i);
f.writeFile(rootpath);
}
// Add file indicating file quantity
// written to this directory as a check:
IO.close(IO.dosOpen(
new File(new File(rootpath, dir),
Integer.toString(v.size())+".files")));
}
}
}
public class CodePackager {
private static final String usageString =
"usage: java CodePackager packedFileName" +
"\nExtracts source code files from packed \n" +
"version of Tjava.doc sources into " +
"directories off current directory\n" +
"java CodePackager packedFileName newDir\n" +
"Extracts into directories off newDir\n" +
"java CodePackager -p source.txt packedFile" +
"\nCreates packed version of source files" +
"\nfrom text version of Tjava.doc";
private static void usage() {
System.err.println(usageString);
System.exit(1);
}
public static void main(String[] args) {
if(args.length == 0) usage();
if(args[0].equals("-p")) {
if(args.length != 3)
usage();
createPackedFile(args);
}
else {
if(args.length > 2)
usage();
extractPackedFile(args);
}
}
private static String currentLine;
private static BufferedReader in;
private static DirMap dm;
private static void
createPackedFile(String[] args) {
dm = new DirMap();
in = IO.disOpen(args[1]);
try {
while((currentLine = in.readLine())
!= null) {
if(currentLine.startsWith(
SourceCodeFile.startMarker)) {
dm.add(new SourceCodeFile(
currentLine, in));
}
else if(currentLine.startsWith(
SourceCodeFile.endMarker))
Pr.error("file has no start marker");
// Else ignore the input line
}
} catch(IOException e) {
Pr.error("Error reading " + args[1]);
}
IO.close(in);
dm.writePackedFile(args[2]);
}
private static void
extractPackedFile(String[] args) {
if(args.length == 2) // Alternate directory
dm = new DirMap(args[1]);
else // Current directory
dm = new DirMap();
in = IO.disOpen(args[0]);
String s = null;
try {
s = in.readLine();
} catch(IOException e) {
Pr.error("Cannot read from " + in);
}
// Capture the separator used in the system
// that packed the file:
if(s.indexOf("###Old Separator:") != -1 ) {
String oldsep = s.substring(
"###Old Separator:".length());
oldsep = oldsep.substring(
0, oldsep. indexOf('#'));
SourceCodeFile.oldsep = oldsep;
}
SourceCodeFile sf = new SourceCodeFile(in);
while(sf.hasFile()) {
dm.add(sf);
sf = new SourceCodeFile(in);
}
dm.write();
}
} ///:~
我們注意到package語句已經作為注釋標志出來了。由於這是本章的第一個程序,所以package語句是必需的,用它告訴CodePackager已改換到另一章。但是把它放入包裡卻會成為一個問題。當我們創建一個包的時候,需要將結果程序同一個特定的目錄結構聯系在一起,這一做法對本書的大多數例子都是適用的。但在這裡,CodePackager程序必須在一個專用的目錄裡編譯和運行,所以package語句作為注釋標記出去。但對CodePackager來說,它“看起來”依然象一個普通的package語句,因為程序還不是特別復雜,不能偵查到多行注釋(沒有必要做得這麼復雜,這裡只要求方便就行)。
頭兩個類是“支持/工具”類,作用是使程序剩余的部分在編寫時更加連貫,也更便於閱讀。第一個是Pr,它類似ANSI C的perror庫,兩者都能打印出一條錯誤提示消息(但同時也會退出程序)。第二個類將文件的創建過程封裝在內,這個過程已在第10章介紹過了;大家已經知道,這樣做很快就會變得非常累贅和麻煩。為解決這個問題,第10章提供的方案致力於新類的創建,但這兒的“靜態”方法已經使用過了。在那些方法中,正常的違例會被捕獲,並相應地進行處理。這些方法使剩余的代碼顯得更加清爽,更易閱讀。
幫助解決問題的第一個類是SourceCodeFile(源碼文件),它代表本書一個源碼文件包含的所有信息(內容、文件名以及目錄)。它同時還包含了一系列String常數,分別代表一個文件的開始與結束;在打包文件內使用的一個標記;當前系統的換行符;文件路徑分隔符(注意要用System.getProperty()偵查本地版本是什麼);以及一大段版權聲明,它是從下面這個Copyright.txt文件裡提取出來的:
////////////////////////////////////////////////// // Copyright (c) Bruce Eckel, 1998 // Source code file from the book "Thinking in Java" // All rights reserved EXCEPT as allowed by the // following statements: You may freely use this file // for your own work (personal or commercial), // including modifications and distribution in // executable form only. Permission is granted to use // this file in classroom situations, including its // use in presentation materials, as long as the book // "Thinking in Java" is cited as the source. // Except in classroom situations, you may not copy // and distribute this code; instead, the sole // distribution point is http://www.BruceEckel.com // (and official mirror sites) where it is // freely available. You may not remove this // copyright and notice. You may not distribute // modified versions of the source code in this // package. You may not use this file in printed // media without the express permission of the // author. Bruce Eckel makes no representation about // the suitability of this software for any purpose. // It is provided "as is" without express or implied // warranty of any kind, including any implied // warranty of merchantability, fitness for a // particular purpose or non-infringement. The entire // risk as to the quality and performance of the // software is with you. Bruce Eckel and the // publisher shall not be liable for any damages // suffered by you or any third party as a result of // using or distributing software. In no event will // Bruce Eckel or the publisher be liable for any // lost revenue, profit, or data, or for direct, // indirect, special, consequential, incidental, or // punitive damages, however caused and regardless of // the theory of liability, arising out of the use of // or inability to use software, even if Bruce Eckel // and the publisher have been advised of the // possibility of such damages. Should the software // prove defective, you assume the cost of all // necessary servicing, repair, or correction. If you // think you've found an error, please email all // modified files with clearly commented changes to: // Bruce@EckelObjects.com. (please use the same // address for non-code errors found in the book). //////////////////////////////////////////////////
從一個打包文件中提取文件時,當初所用系統的文件分隔符也會標注出來,以便用本地系統適用的符號替換它。
當前章的子目錄保存在chapter字段中,它初始化成c02(大家可注意一下第2章的列表正好沒有包含一個打包語句)。只有在當前文件裡發現一個package(打包)語句時,chapter字段才會發生改變。
1. 構建一個打包文件
第一個構建器用於從本書的ASCII文本版裡提取出一個文件。發出調用的代碼(在列表裡較深的地方)會讀入並檢查每一行,直到找到與一個列表的開頭相符的為止。在這個時候,它就會新建一個SourceCodeFile對象,將第一行的內容(已經由調用代碼讀入了)傳遞給它,同時還要傳遞BufferedReader對象,以便在這個緩沖區中提取源碼列表剩余的內容。
從這時起,大家會發現String方法被頻繁運用。為提取出文件名,需調用substring()的過載版本,令其從一個起始偏移開始,一直讀到字串的末尾,從而形成一個“子串”。為算出這個起始索引,先要用length()得出startMarker的總長,再用trim()刪除字串頭尾多余的空格。第一行在文件名後也可能有一些字符;它們是用indexOf()偵測出來的。若沒有發現找到我們想尋找的字符,就返回-1;若找到那些字符,就返回它們第一次出現的位置。注意這也是indexOf()的一個過載版本,采用一個字串作為參數,而非一個字符。
解析出並保存好文件名後,第一行會被置入字串contents中(該字串用於保存源碼清單的完整正文)。隨後,將剩余的代碼行讀入,並合並進入contents字串。當然事情並沒有想象的那麼簡單,因為特定的情況需加以特別的控制。一種情況是錯誤檢查:若直接遇到一個startMarker(起始標記),表明當前操作的這個代碼列表沒有設置一個結束標記。這屬於一個出錯條件,需要退出程序。
另一種特殊情況與package關鍵字有關。盡管Java是一種自由形式的語言,但這個程序要求package關鍵字必須位於行首。若發現package關鍵字,就通過檢查位於開頭的空格以及位於末尾的分號,從而提取出包名(注意亦可一次單獨的操作實現,方法是使用過載的substring(),令其同時檢查起始和結束索引位置)。隨後,將包名中的點號替換成特定的文件分隔符——當然,這裡要假設文件分隔符僅有一個字符的長度。盡管這個假設可能對目前的所有系統都是適用的,但一旦遇到問題,一定不要忘了檢查一下這裡。
默認操作是將每一行都連接到contents裡,同時還有換行字符,直到遇到一個endMarker(結束標記)為止。該標記指出構建器應當停止了。若在endMarker之前遇到了文件結尾,就認為存在一個錯誤。
2. 從打包文件中提取
第二個構建器用於將源碼文件從打包文件中恢復(提取)出來。在這兒,作為調用者的方法不必擔心會跳過一些中間文本。打包文件包含了所有源碼文件,它們相互間緊密地靠在一起。需要傳遞給該構建器的僅僅是一個BufferedReader,它代表著“信息源”。構建器會從中提取出自己需要的信息。但在每個代碼列表開始的地方還有一些配置信息,它們的身份是用packMarker(打包標記)指出的。若packMarker不存在,意味著調用者試圖用錯誤的方法來使用這個構建器。
一旦發現packMarker,就會將其剝離出來,並提取出目錄名(用一個'#'結尾)以及文件名(直到行末)。不管在哪種情況下,舊分隔符都會被替換成本地適用的一個分隔符,這是用String replace()方法實現的。老的分隔符被置於打包文件的開頭,在代碼列表稍靠後的一部分即可看到是如何把它提取出來的。
構建器剩下的部分就非常簡單了。它讀入每一行,把它合並到contents裡,直到遇見endMarker為止。
3. 程序列表的存取
接下來的一系列方法是簡單的訪問器:directory()、filename()(注意方法可能與字段有相同的拼寫和大小寫形式)和contents()。而hasFile()用於指出這個對象是否包含了一個文件(很快就會知道為什麼需要這個)。
最後三個方法致力於將這個代碼列表寫進一個文件——要麼通過writePacked()寫入一個打包文件,要麼通過writeFile()寫入一個Java源碼文件。writePacked()需要的唯一東西就是DataOutputStream,它是在別的地方打開的,代表著准備寫入的文件。它先把頭信息置入第一行,再調用writeBytes()將contents(內容)寫成一種“通用”格式。
准備寫Java源碼文件時,必須先把文件建好。這是用IO.psOpen()實現的。我們需要向它傳遞一個File對象,其中不僅包含了文件名,也包含了路徑信息。但現在的問題是:這個路徑實際存在嗎?用戶可能決定將所有源碼目錄都置入一個完全不同的子目錄,那個目錄可能是尚不存在的。所以在正式寫每個文件之前,都要調用File.mkdirs()方法,建好我們想向其中寫入文件的目錄路徑。它可一次性建好整個路徑。
4. 整套列表的包容
以子目錄的形式組織代碼列表是非常方便的,盡管這要求先在內存中建好整套列表。之所以要這樣做,還有另一個很有說服力的原因:為了構建更“健康”的系統。也就是說,在創建代碼列表的每個子目錄時,都會加入一個額外的文件,它的名字包含了那個目錄內應有的文件數目。
DirMap類可幫助我們實現這一效果,並有效地演示了一個“多重映射”的概述。這是通過一個散列表(Hashtable)實現的,它的“鍵”是准備創建的子目錄,而“值”是包含了那個特定目錄中的SourceCodeFile對象的Vector對象。所以,我們在這兒並不是將一個“鍵”映射(或對應)到一個值,而是通過對應的Vector,將一個鍵“多重映射”到一系列值。盡管這聽起來似乎很復雜,但具體實現時卻是非常簡單和直接的。大家可以看到,DirMap類的大多數代碼都與向文件中的寫入有關,而非與“多重映射”有關。與它有關的代碼僅極少數而已。
可通過兩種方式建立一個DirMap(目錄映射或對應)關系:默認構建器假定我們希望目錄從當前位置向下展開,而另一個構建器讓我們為起始目錄指定一個備用的“絕對”路徑。
add()方法是一個采取的行動比較密集的場所。首先將directory()從我們想添加的SourceCodeFile裡提取出來,然後檢查散列表(Hashtable),看看其中是否已經包含了那個鍵。如果沒有,就向散列表加入一個新的Vector,並將它同那個鍵關聯到一起。到這時,不管采取的是什麼途徑,Vector都已經就位了,可以將它提取出來,以便添加SourceCodeFile。由於Vector可象這樣同散列表方便地合並到一起,所以我們從兩方面都能感覺得非常方便。
寫一個打包文件時,需打開一個准備寫入的文件(當作DataOutputStream打開,使數據具有“通用”性),並在第一行寫入與老的分隔符有關的頭信息。接著產生對Hashtable鍵的一個Enumeration(枚舉),並遍歷其中,選擇每一個目錄,並取得與那個目錄有關的Vector,使那個Vector中的每個SourceCodeFile都能寫入打包文件中。
用write()將Java源碼文件寫入它們對應的目錄時,采用的方法幾乎與writePackedFile()完全一致,因為兩個方法都只需簡單調用SourceCodeFile中適當的方法。但在這裡,根路徑會傳遞給SourceCodeFile.writeFile()。所有文件都寫好後,名字中指定了已寫文件數量的那個附加文件也會被寫入。
5. 主程序
前面介紹的那些類都要在CodePackager中用到。大家首先看到的是用法字串。一旦最終用戶不正確地調用了程序,就會打印出介紹正確用法的這個字串。調用這個字串的是usage()方法,同時還要退出程序。main()唯一的任務就是判斷我們希望創建一個打包文件,還是希望從一個打包文件中提取什麼東西。隨後,它負責保證使用的是正確的參數,並調用適當的方法。
創建一個打包文件時,它默認位於當前目錄,所以我們用默認構建器創建DirMap。打開文件後,其中的每一行都會讀入,並檢查是否符合特殊的條件:
(1) 若行首是一個用於源碼列表的起始標記,就新建一個SourceCodeFile對象。構建器會讀入源碼列表剩下的所有內容。結果產生的句柄將直接加入DirMap。
(2) 若行首是一個用於源碼列表的結束標記,表明某個地方出現錯誤,因為結束標記應當只能由SourceCodeFile構建器發現。
提取/釋放一個打包文件時,提取出來的內容可進入當前目錄,亦可進入另一個備用目錄。所以需要相應地創建DirMap對象。打開文件,並將第一行讀入。老的文件路徑分隔符信息將從這一行中提取出來。隨後根據輸入來創建第一個SourceCodeFile對象,它會加入DirMap。只要包含了一個文件,新的SourceCodeFile對象就會創建並加入(創建的最後一個用光輸入內容後,會簡單地返回,然後hasFile()會返回一個錯誤)。