使用Lucene實現一個簡單的布爾搜索功能。本站提示廣大學習愛好者:(使用Lucene實現一個簡單的布爾搜索功能)文章只能為提供參考,不一定能成為您想要的結果。以下是使用Lucene實現一個簡單的布爾搜索功能正文
什麼是lucene
Lucene是apache軟件基金會jakarta項目組的一個子項目,是一個開放源代碼的全文檢索引擎工具包,但它不是一個完整的全文檢索引擎,而是一個全文檢索引擎的架構,提供了完整的查詢引擎和索引引擎,部分文本分析引擎(英文與德文兩種西方語言)。
Lucene是一個全文搜索框架,而不是應用產品。因此它並不像www.baidu.com 或者google Desktop那麼拿來就能用,它只是提供了一種工具讓你能實現這些產品。
在布爾查詢的對象中,包含一個子句的集合,各個子句間都是如“與”、“或”這樣的布爾邏輯。Lucene中所遇到的各種復雜查詢,最終都可以表示成布爾型的查詢。下面代碼就是實現了一個簡單的布爾查詢。
package LuceneSearch;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.TermQuery;
/**
* 布爾搜索測試
* @author sdu20
*
*/
public class BooleanQueryTest {
static final String INDEX_STORE_PATH = "E:\\編程局\\Java編程處\\Index\\";
public static void main(String[] args) {
// TODO Auto-generated method stub
try{
IndexWriter writer = new IndexWriter(INDEX_STORE_PATH,new StandardAnalyzer(),true);
writer.setUseCompoundFile(false);
//創建8個文檔
Document doc1 = new Document();
Document doc2 = new Document();
Document doc3 = new Document();
Document doc4 = new Document();
Document doc5 = new Document();
Document doc6 = new Document();
Document doc7 = new Document();
Document doc8 = new Document();
Field f1 = new Field("bookname","鋼鐵是怎樣煉成的",Field.Store.YES,Field.Index.TOKENIZED);
Field f2 = new Field("bookname","英雄兒女",Field.Store.YES,Field.Index.TOKENIZED);
Field f3 = new Field("bookname","浮生六記",Field.Store.YES,Field.Index.TOKENIZED);
Field f4 = new Field("bookname","太平廣記",Field.Store.YES,Field.Index.TOKENIZED);
Field f5 = new Field("bookname","文化苦旅",Field.Store.YES,Field.Index.TOKENIZED);
Field f6 = new Field("bookname","白夜行",Field.Store.YES,Field.Index.TOKENIZED);
Field f7 = new Field("bookname","白毛女",Field.Store.YES,Field.Index.TOKENIZED);
Field f8 = new Field("bookname","子不語",Field.Store.YES,Field.Index.TOKENIZED);
doc1.add(f1);
doc2.add(f2);
doc3.add(f3);
doc4.add(f4);
doc5.add(f5);
doc6.add(f6);
doc7.add(f7);
doc8.add(f8);
writer.addDocument(doc1);
writer.addDocument(doc2);
writer.addDocument(doc3);
writer.addDocument(doc4);
writer.addDocument(doc5);
writer.addDocument(doc6);
writer.addDocument(doc7);
writer.addDocument(doc8);
writer.close();
System.out.println("創建索引成功");
IndexSearcher searcher = new IndexSearcher(INDEX_STORE_PATH);
//創建兩個詞條對象
Term t1 = new Term("bookname","生");
Term t2 = new Term("bookname","記");
TermQuery q1 = new TermQuery(t1);
TermQuery q2 = new TermQuery(t2);
BooleanQuery query = new BooleanQuery();
query.add(q1,BooleanClause.Occur.MUST);
query.add(q2,BooleanClause.Occur.MUST);
Hits hits = searcher.search(query);
for(int i = 0;i<hits.length();i++){
System.out.println(hits.doc(i));
}
System.out.println("搜索成功");
}catch(Exception e){
System.out.println(e.getStackTrace());
}
}
}
BooleanClause.Occur類主要有3種表示,即MUST、MUST_NOT和SHOULD。MUST與MUST_NOT不難理解,一看名字就知道是什麼意思,而SHOULD是一個比較特殊的約束,當它與MUST聯用時,它將失去意義。檢索的結果為MUST子句的檢索結果。當它與MUST_NOT聯用時,SHOULD的功能就與MUST一樣,就退變為MUST和MUST_NOT的查詢結果。當SHOULD與SHOULD聯用時,它們就表示一種“或”關系。最終檢索結果為所有檢索子句的檢索結果的並集。
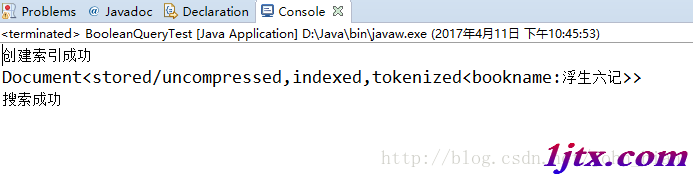
上面代碼就是查詢索引中有“生”字和“記”字的文檔,程序運行結果截圖如下
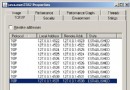
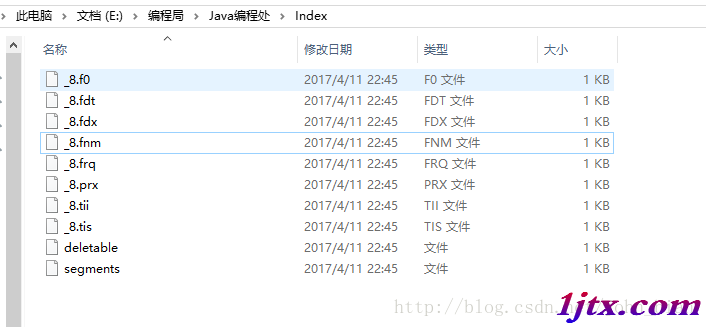
索引目錄文件夾下截圖如下
以上所述是小編給大家介紹的使用Lucene實現一個簡單的布爾搜索功能,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對網站的支持!