java容器詳細解析。本站提示廣大學習愛好者:(java容器詳細解析)文章只能為提供參考,不一定能成為您想要的結果。以下是java容器詳細解析正文
前言:在java開發中我們肯定會大量的使用集合,在這裡我將總結常見的集合類,每個集合類的優點和缺點,以便我們能更好的使用集合。下面我用一幅圖來表示
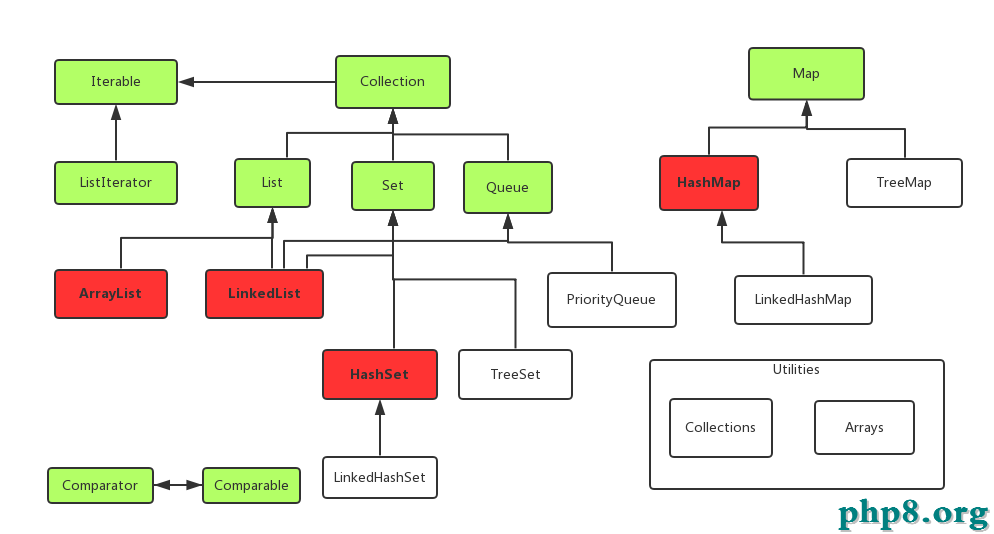
其中淡綠色的表示接口,紅色的表示我們經常使用的類。
1:基本概念
Java容器類類庫的用途是保存對象,可以將其分為2個概念。
1.1:Collection
一個獨立元素的序列,這些元素都服從一條或多條規則。其中List必須按照插入的順序保存元素、Set不能有重復的元素、Queue按照排隊規則來確定對象的產生順序(通常也是和插入順序相同)
1.2:Map
一組成對的值鍵對對象,允許用鍵來查找值。ArrayList允許我們用數字來查找值,它是將數字和對象聯系在一起。而Map允許我們使用一個對象來查找某個對象,它也被稱為關聯數組。或者叫做字典。
2:List
List承諾可以將元素維護在特定的序列中。List接口在Collection的基礎上加入了大量的方法,使得可以在List中間可以插入和移除元素。下面主要介紹2種List
2.1:基本的ArrayList
它的優點在於隨機訪問元素快,但是在中間插入和移除比較慢
那麼現在我們就一起來看看為什麼ArrayList隨機訪問快,而插入移除比較慢。先說關於ArrayList的初始化。
ArrayList有三種方式進行初始化如下
private transient Object[] elementData;
public ArrayList() {
this(10);
}
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
我們可以看出ArrayList其實就是采用的是數組(默認是長度為10的數組)。所有ArrayList在讀取的時候是具有和數組一樣的效率,它的時間復雜度為1。
插入尾部就是elementData[size++] = e;當然中間會進行擴容。現在主要說插入中間為什麼相對來說比較慢源碼如下
public void add(int index, E element) {
rangeCheckForAdd(index);//驗證(可以不考慮)
ensureCapacityInternal(size + 1); // Increments modCount!!(超過當前數組長度進行擴容)
System.arraycopy(elementData, index, elementData, index + 1,
size - index);(核心代碼)
elementData[index] = element;
size++;
}
System.arraycopy(elementData, index, elementData, index + 1)第一個參數是源數組,源數組起始位置,目標數組,目標數組起始位置,復制數組元素數目。那麼這個意思就是從index索性處每個元素向後移動一位,最後把索引為index空出來,並將element賦值給它。這樣一來我們並不知道要插入哪個位置,所以會進行匹配那麼它的時間賦值度就為n。
2.2:LinkedList
它是通過代價較低在List中間進行插入和移除,提供了優化的順序訪問,但是在隨機訪問方面相對較慢。但是他的特性功能要比ArrayList強大的多。支持Queue和Stack
ListedList采用的是鏈式存儲。鏈式存儲就會定一個節點Node。包括三部分前驅節點、後繼節點以及data值。所以存儲存儲的時候他的物理地址不一定是連續的。
我們看下它的中間插入實現
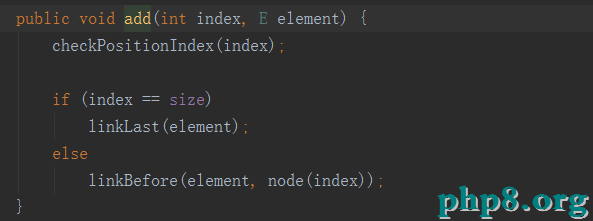

從代碼我們可以看出先獲取插入索引元素的前驅節點,然後把這個元素作為後繼節點,然後在創建新的節點,而新的節點前驅節點和獲取前驅節點相同,而後繼節點則等於要移動的這個元素。所以這裡是不需要循環的,從而在插入和刪除的時候效率比較高。
我們在來看看查詢(我們可以分析出它的效率要比ArrayList低了不少)
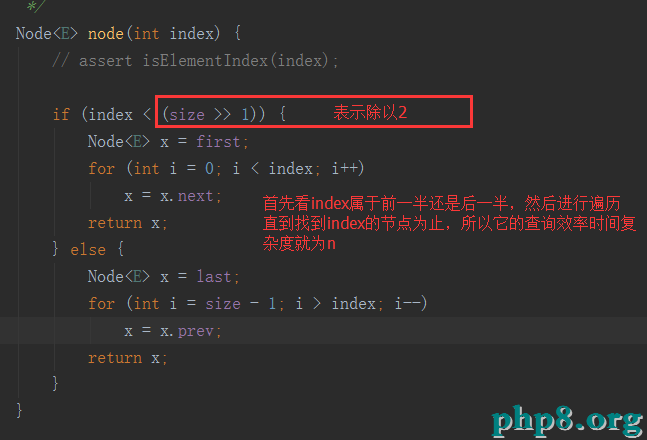
3:Set
Set也是一個集合,但是他的特點是不可以有重復的對象,所以Set最常用的就是測試歸屬性,很容易的詢問出某個對象是否存在Set中。並且Set是具有和Collection完全一樣的接口,沒有額外的功能,只是表現的行為不同。
3.1:HashSet
HashSet查詢速度比較快,但是存儲的元素是隨機的並沒有排序,下面我寫一段程序看一下
public static void main(String[] args){
/**
* 沒有順序可循,這是因為hashset采用的是散列(處於速度考慮)
*/
Random random=new Random(47);
Set<Integer> intset=new HashSet<Integer>();
for (int i=0;i<10000;i++){
intset.add(random.nextInt(30));
}
System.out.print(intset);
}

3.2:TreeSet
TreeSet是將元素存儲紅-黑樹結構中,所以存儲的結果是有順序的(所以如果你想要自己存儲的集合有順序那麼選擇TreeSet)
public static void main(String[] args){
Random random=new Random(47);
Set<Integer> intset=new TreeSet<Integer>();
for (int i=0;i<10000;i++){
intset.add(random.nextInt(30));
}
System.out.print(intset);
}

關於LinkedHashSet後面再說。
4:Queue
Queue是隊列,隊列是典型的先進先出的容器,就是從容器的一端放入元素,從另一端取出,並且元素放入容器的順序和取出的順序是相同的。LinkedList提供了對Queue的實現,LinkedList向上轉型為Queue。其中Queue有offer、peek、element、pool、remove等方法
offer是將元素插入隊尾,返回false表示添加失敗。peek和element都將在不移除的情況下返回對頭,但是peek在對頭為null的時候返回null,而element會拋出NoSuchElementException異常。poll和remove方法將移除並返回對頭,但是poll在隊列為null,而remove會拋出NoSuchElementException異常,以下是例子
public static void main(String[] args){
Queue<Integer> queue=new LinkedList<Integer>();
Random rand=new Random();
for (int i=0;i<10;i++){
queue.offer(rand.nextInt(i+10));
}
printQ(queue);
Queue<Character> qc=new LinkedList<Character>();
for (char c:"HelloWorld".toCharArray()){
qc.offer(c);
}
System.out.println(qc.peek());
printQ(qc);
List<String> mystrings=new LinkedList<String>();
mystrings.add("1");
mystrings.get(0);
Set<String> a=new HashSet<String>();
Set<String> set=new HashSet<String>();
set.add("1");
}
public static void printQ(Queue queue){
while (queue.peek
從上面的輸出的結果我們可以看出結果並不是一個順序的,沒有規則的,這個時候如果想讓隊列按照規則輸出那麼這個時候我們就要考慮優先級了,這個時候我們就應該使用PriorityQueue,這個時候如果在調用offer方法插入一個對象的時候,這個對象就會按照優先級在對列中進行排序,默認的情況是自然排序,當然我們可以通過Comparator來修改這個順序(在下一篇講解)。PriorityQueue可以確保當你調用peek、pool、remove方法時,獲取的元素將是對列中優先級最高的元素。ok我們再次通過代碼查看
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue = new PriorityQueue<Integer>();
Random rand = new Random();
for (int i = 0; i < 10; i++) {
priorityQueue.offer(rand.nextInt(i + 10));
}
QueueDemo.printQ(priorityQueue);
List<Integer>ints= Arrays.asList(25,22,20,18,14,9,3,1,1,2,3,9,14,18,21,23,25);
priorityQueue=new PriorityQueue<Integer>(ints);
QueueDemo.printQ(priorityQueue);
}

從輸出可以看到,重復是允許的,最小值擁有最高優先級(如果是String,空格也可以算作值,並且比字母具有更高的優先級)如果你想消除重復,可以采用Set進行存儲,然後把Set作為priorityQueue對象的初始值即可。
5:Map
Map在實際開發中使用非常廣,特別是HashMap,想象一下我們要保存一個對象中某些元素的值,如果我們在創建一個對象顯得有點麻煩,這個時候我們就可以用上map了,HashMap采用是散列函數所以查詢的效率是比較高的,如果我們需要一個有序的我們就可以考慮使用TreeMap。這裡主要介紹一下HashMap的方法,大家注意HashMap的鍵可以是null,而且鍵值不可以重復,如果重復了以後就會對第一個進行鍵值進行覆蓋。
put進行添加值鍵對,containsKey驗證主要是否存在、containsValue驗證值是否存在、keySet獲取所有的鍵集合、values獲取所有值集合、entrySet獲取鍵值對。
public static void main(String[] args){
//Map<String,String> pets=new HashMap<String, String>();
Map<String,String> pets=new TreeMap<String, String>();
pets.put("1","張三");
pets.put("2","李四");
pets.put("3","王五");
if (pets.containsKey("1")){
System.out.println("已存在鍵1");
}
if (pets.containsValue("張三")){
System.out.println("已存在值張三");
}
Set<String> sets=pets.keySet();
Set<Map.Entry<String , String>> entrySet= pets.entrySet();
Collection<String> values= pets.values();
for (String value:values){
System.out.println(value+";");
}
for (String key:sets){
System.out.print(key+";");
}
for (Map.Entry entry:entrySet){
System.out.println("鍵:"+entry.getKey());
System.out.println("值:"+entry.getValue());
}
}
6:Iterator和Foreach
現在foreach語法主要作用於數組,但是他也可以應用於所有的Collection對象。Collection之所以能夠使用foreach是由於繼承了Iterator這個接口。下面我寫段代碼供大家查看
public class IteratorClass {
public Iterator<String> iterator(){
return new Itr();
}
private class Itr implements Iterator<String>{
protected String[] words=("Hello Java").split(" ");
private int index=0;
public boolean hasNext() {
return index<words.length;
}
public String next() {
return words[index++];
}
public void remove() {
}
}
}
Iterator iterators=new IteratorClass().iterator();
for (Iterator it=iterator;iterators.hasNext();) {
System.out.println(iterators.next());
}
while (iterators.hasNext()){
System.out.println(iterators.next());
}
從中我們可以看出foreach循環最終是轉換成 for (Iterator it=iterator;iterators.hasNext();)只不過jdk幫我們隱藏我們無法查看。下面我們在來分析一個問題,關於List刪除問題。我們大多肯定使用過for循環或者foreach循環去刪除,但是結果很明顯會出現錯誤,那麼現在我們一起分析為啥會出現錯誤。
1:使用for循環刪除(出現錯誤分析)
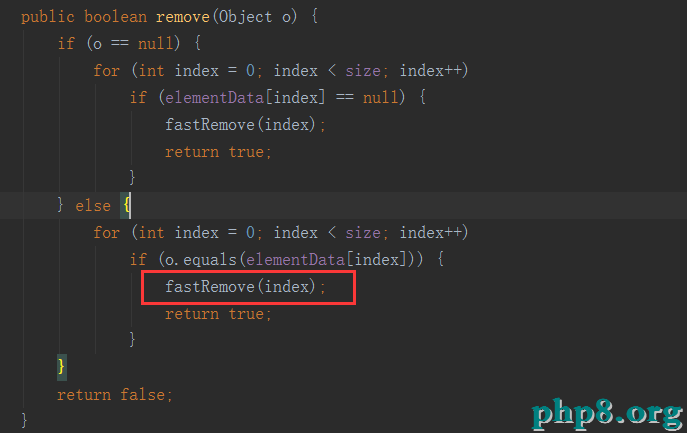
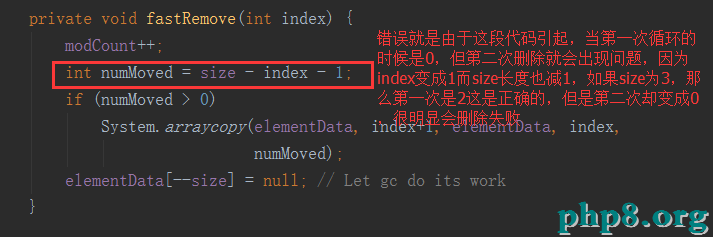
2:foreach循環刪除(錯誤分析)
從上面我們得知foreach最終是會轉成Iterator的所以它首先會通過next來獲取元素,我們看代碼
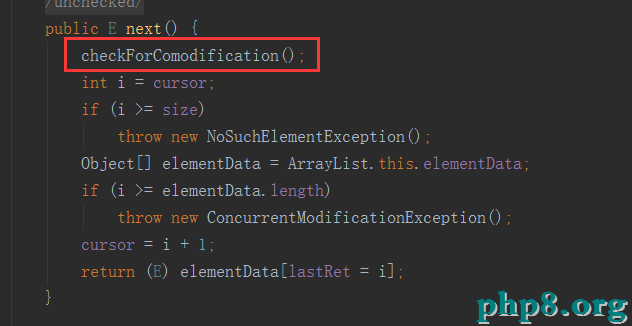
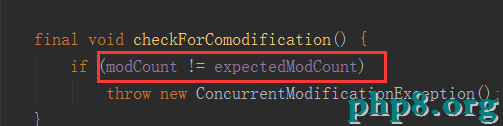
請看for循環刪除那段代碼,沒刪除一次modCount會++,所以第二次在次刪除的時候modCount由於增加和expectedModCount不等所以無法獲取元素也就無法刪除。
3:正確的刪除方式
采用迭代器代碼如下
Iterator<String> iterator=userList.iterator();
while (iterator.hasNext()){
iterator.next();
iterator.remove();
}
請記住一定要加上iterator.next();這是因為在源碼中有一個lastRed,通過它來記錄是否是最後一個元素,如果不加上iterator.next()那麼lastRed=-1,在刪除驗證的時候有這麼一段代碼if (lastRet < 0)throw new IllegalStateException();所以就會拋出異常。
7:Collections和Arrays
這裡只介紹2個常用的Collections.addAll和Arrays.asList
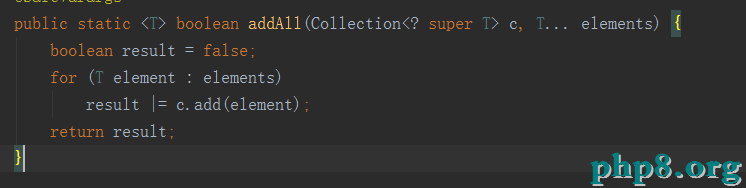
addAll:
asList采用的是數組

可以看出最終轉換成ArrayList。
8:總結
1):數組是將數字和對象聯系起來,它保存明確的對象,查詢對象時候不需要對查詢結果進行轉換,它可以是多維的,可以保存基本類型的數據,但是數組一旦生成,其容量不能改變。所以數組是不可以直接刪除和添加元素。
2):Collection保存單一的元素,而Map保存相關聯的值鍵對,有了Java泛型,可以指定容器存放對象類型,不會將錯誤類型的對象放在容器中,取元素時候也不需要轉型。而且Collection和Map都可以自動調整其尺寸。容器不可以持有基本類型。
3):像數組一樣,List也建立數字索性和對象的關聯,因此,數組和List都是排好序的容器,List可以自動擴容
4):如果需要大量的隨機訪問就要使用ArrayList,如果要經常從中間插入和刪除就要使用LinkedList。
5):各種Queue和Stack由LinkedList支持
6):Map是一種將對象(而非數字)與對象相關聯的設計。HashMap用於快速訪問,TreeMap保持鍵始終處於排序狀態,所以不如HashMap快,而LinkedHashMap保持元素插入的順序,但是也通過散列提供了快速訪問的能力
7):Set不接受重復的元素,HashSet提供最快的訪問能力,TreeSet保持元素排序狀態,LinkedHashSet以插入順序保存元素。
以上就是本文的全部內容,希望本文的內容對大家的學習或者工作能帶來一定的幫助,同時也希望多多支持!
[db:作者簡介][db:原文翻譯及解析]