Java GC 機制與內存分配策略詳解。本站提示廣大學習愛好者:(Java GC 機制與內存分配策略詳解)文章只能為提供參考,不一定能成為您想要的結果。以下是Java GC 機制與內存分配策略詳解正文
Java GC 機制與內存分配策略詳解
收集算法是內存回收的方法論,垃圾收集器是內存回收的具體實現
自動內存管理解決的是:給對象分配內存 以及 回收分配給對象的內存
為什麼我們要了解學習 GC 與內存分配呢?
在 JVM 自動內存管理機制的幫助下,不再需要為每一個new操作寫配對的delete/free代碼。但出現內存洩漏和溢出的問題時,如果不了解虛擬機是怎樣使用內存的,那麼排查錯誤將是一項非常艱難的工作。
GC(垃圾收集器)在對堆進行回收前,會先確定哪些對象“存活”,哪些已經“死去”。那麼就有了 對象存活判定算法 。
對象存活判定算法
引用計數算法:
算法思想:給對象中添加一個引用計數器,每當有一個地方引用它時,計數器值加1,當引用失效時,計數器值減1,任何時刻計數器為0的對象就是不可能再被使用的。
優點:實現簡單,判斷效率也很高
缺點:很難解決對象之間相互循環引用的問題
可達性分析算法:
算法思想:通過一系列的“GC Roots”對象作為起始點,從這些節點開始向下搜索,搜索所走過的路徑稱為引用鏈,當一個對象到 GC Roots 沒有任何引用鏈相連時,則證明此對象是不可用的。
如圖:object5、object6、object7雖然互相有關聯,但是它們到GC Roots是不可達的,所以它們將會被判定為是可回收的對象。
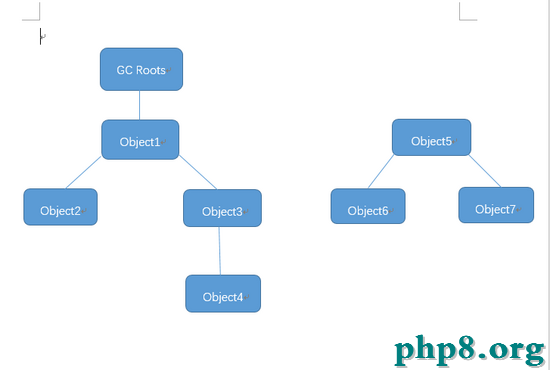
可作為 GC Roots 的對象包括以下:
1.虛擬機棧中引用的對象
2.方法區中類靜態屬性引用的對象
3.方法區中常量引用的對象
4.本地方法棧中 JNI 引用的對象
生存還是死亡?
即使在可達性分析算法中不可達的對象,也並非是“非死不可”的,這時候他們暫時處於“緩刑”階段,要真正宣告一個對象死亡,至少要經歷兩次標記過程:
如果對象在進行可達性分析後發現沒有與GC Roots相連接的引用鏈,那它將會被第一次標記並且進行一次篩選,篩選的條件是此對象是否有必要執行finalize()方法,當對象沒有覆蓋finalize()方法,或者finalize()方法已經被虛擬機調用過,虛擬機將這兩種情況都視為“沒有必要執行”。
如果這個對象被判定為有必要執行finalize()方法,那麼這個對象將會放置在一個叫做F-Queue的隊列中,並在稍後由一個由虛擬機自動建立的、低優先級的Finalizer線程去執行它,這裡所謂的“執行”是指虛擬機會觸發這個方法,但並不承諾會等待它運行結束,這樣做的原因是:如果一個對象在finalize()方法中執行緩慢,或者發生了死循環,將很可能會導致F-Queue隊列中其他對象永久處於等待,甚至導致整個內存回收系統的奔潰。
finalize()方法是對象逃脫死亡命運的最後一次機會,稍後GC將對F-Queue中的對象進行第二次小規模的標記,如果對象要在finalize()方法中成功拯救自己,只需重新與引用鏈上的任何一個對象建立關聯即可,比如把自己(this關鍵字)賦值給某個類變量或者對象的成員變量,那在第二次標記時它將被移除出“即將回收“的集合,如果對象這時候還沒有逃脫,那基本上它就真的被回收了。
另外,任何一個對象的finalize()方法都只會被系統自動調用一次。finalize()能做的所有工作,使用try-finally或者其他方式都可以做的更好,更及時,所以建議大家完全可以忘掉Java語言中有這個方法的存在。詳見《深入理解Java虛擬機》
垃圾收集算法
標記-清除算法:
算法分為“標記“和”清除“兩個階段:
首先標記出所有需要回收的對象,在標記完成後統一回收所有被標記的對象
不足之處:
1.效率問題,標記和清除兩個過程的效率都不高。
2.空間問題:標記清除之後會產生大量不連續的內存碎片,空間碎片太多可能會導致以後在程序運行過程中需要分配較大對象時,無法找到足夠的連續內存而不得不提前觸發另一次垃圾收集動作
復制算法:
算法實現:將可用內存按容量劃分為大小相等的兩塊,每次只使用其中的一塊。當這一塊的內存用完了,就將還存活著的對象復制到另一塊上面,然後再把已使用過的內存空間一次清理掉。
這樣使得每次都是對整個半區進行內存回收,內存分配時也就不用考慮內存碎片等復雜情況,只要移動堆頂指針,按順序分配內存即可。實現簡單,運行高效。算法的代價是講內存縮小為了原來的一半,未免太高了點。
標記-整理算法:
算法實現:標記出所有需要回收的對象、讓所有存活的對象都向一端移動。然後直接清理掉端邊界以外的內存。
分代收集算法:
算法實現:根據對象存活周期的不同將內存劃分為幾塊,一般是把Java堆分為新生代和老年代,這樣就可以根據各個年代的特點采用最適當的收集算法。
在新生代中,每次垃圾收集時都發現有大批對象死去,只有少量存活,那就選用復制算法。只需要付出少量存活對象的復制成本就可以完成收集。
而老年代中因為對象存活率高、沒有額外空間對它進行分配擔保,就必須使用“標記-清理“或者”標記-整理“算法來進行回收。
新生代 :分為三個空間,一個Eden空間 ,兩個Survivor空間。
絕大多數最新被創建的對象會被分配到這裡,由於大部分對象在創建後會很快變得不可到達,所以很多對象被創建在新生代,然後消失。對象從這個區域消失的過程我們稱之為”minor GC“。
老年代 :對象沒有變得不可達,並且從新生代中存活下來,會被拷貝到這裡。其所占用的空間要比新生代多。也正由於其相對較大的空間,發生在老年代上的GC要比新生代少得多。對象從老年代中消失的過程,我們稱之為”major GC“(或者”full GC“)
絕大多數剛剛被創建的對象會存放在Eden空間。在Eden空間執行了第一次GC之後,存活的對象被移動到其中一個Survivor空間。此後,在Eden空間執行GC之後,存活的對象會被堆積在同一個Survivor空間。當一個Survivor空間飽和,還在存活的對象會被移動到另一個Survivor空間。之後會清空已經飽和的那個Survivor空間。
在以上的步驟中重復幾次依然存活的對象,就會被移動到老年代。
垃圾收集器
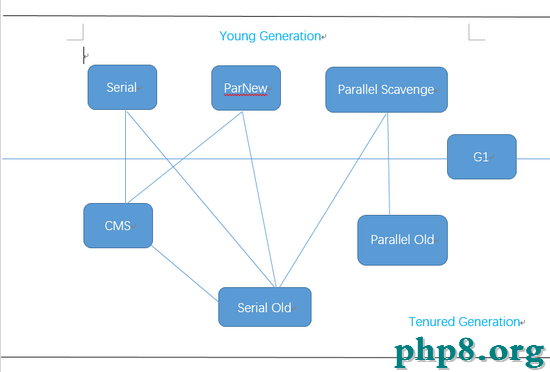
如圖是作用於不同分代的垃圾收集器,如果兩個收集器之間存在連線,就可以搭配使用。虛擬機所在的區域,則表示它是屬於新生代收集器還是老年代收集器。
學習各種垃圾收集器之前先了解下“Stop the World“。“Stop the World“會在任何一種GC算法中發生。“Stop the World“意味著 JVM 因為要執行GC而停止了應用程序的執行。當“Stop the World“發生時,除了GC所需的線程以外,所有線程都處於等待狀態,直到GC任務完成。GC優化很多時候就是指減少“Stop the World“發生的時間。
“Stop the World“這樣理解很形象:你媽媽在給你打掃房間的時候,肯定也會讓你老老實實地在椅子上或者房間外等待著,如果她一邊打掃,你一邊亂扔紙屑,這房間還能打掃完?
Serial收集器:單線程,新生代收集器,使用復制算法。它只會使用一個CPU或一條收集線程去完成垃圾收集工作,在進行垃圾收集時,必須“Stop the World“,暫停替他所有的工作線程,直到它收集結束。
ParNew收集器:Serial收集器的多線程版本,控制參數、收集算法、Stop the World、對象分配規則、回收策略都與Serial收集器完全一樣
Parallel Scavenge收集器:生代收集器,使用復制算法,並行多線程。
Serial Old收集器:Serial收集器的老年代版本,單線程,使用標記-整理算法。
Parallel Old收集器:Parallel Scavenge收集器的老年代版本,多線程,使用標記-整理算法
CMS收集器:一種以獲取最短回收停頓時間為目標的收集器,基於“標記-清除”算法。運作過程分四個步驟:初始標記 、並發標記、重新標記、並發清除。
初始標記、重新標記這兩個步驟仍然需要“Stop the World”。初始標記僅僅只是標記一下GC Roots能直接關聯到的對象,速度很快。並發標記階段就是進行GC Roots Tracing 的過程,而重新標記階段則是為了修正並發標記期間因為用戶程序繼續運作而導致標記產生變動的那一部分對象的標記記錄,這一階段的停頓時間一般會比初始標記階段稍長一些,但遠比並發標記的時間段。
整個過程中耗時最長的並發標記和並發清除過程,收集器線程都可以與用戶線程一起工作,所以,CMS收集器的內存回收過程是與用戶線程一起並發執行的。
優點:並發收集,低停頓
缺點:對CPU資源非常敏感、無法處理浮動垃圾、基於標記清除算法,收集結束時有大量控件碎片產生
G1收集器:G1收集器是當今收集器技術發展最前沿成果之一,一種面向服務端應用的垃圾收集器。
G1的特點:並行與並發、分代手機、空間整合、可預測的停頓
運作過程如下:初始標記、並發標記、最終標記、篩選回收。
初始標記階段僅僅只是標記一下GC Roots能直接關聯到的對象,並且修改TAMS的值,讓下一階段用戶程序並發運行時,能在正確可用的Region中創建新對象,這階段需要停頓線程,但耗時很短。
並發標記階段是從GC Roots開始對堆中對象進行可達性分析,找出存活的對象,這階段耗時較長,但可與用戶程序並發執行。
而最終標記階段則是則是為了修正在並發標記期間因用戶程序繼續運作而導致標記產生變動的那一部分標記記錄,虛擬機將這段時間對象變化記錄在線程Remembered Set Logs裡面。最終標記階段需要把Remembered Set Logs的數據合並到Remembered Set中,這階段需要停頓線程,但是可並行執行。
最後在篩選回收階段首先對各個Region的回收價值和成本進行排序。根據用戶所期望的GC停頓時間來制定回收計劃。
內存分配與回收策略
對象優先在Eden分配:大多數情況下,對象在新生代Eden區中分配。當Eden區沒有足夠空間進行分配時,虛擬機將發起一次Minor GC。
大對象直接進入老年代:大對象是指需要大量連續內存控件的Java對象,最典型的大對象就是那種很長的字符串以及數組。
長期存活的對象將進入老年代:虛擬機采用了分代收集的思想來管理內存,那麼內存回收時就必須能識別哪些對象應放在新生代,哪些對象應放在老年代。為了做到這點,虛擬機給每個對象定義了一個對象年齡計數器。如果對象在Eden出生並經過第一次Minor GC後仍然存活,並且能被Survivor容納的話,將被移動到Survivor空間中,並且對象年齡設為1,對象在Survivor區中每“熬過”一次Minor GC,年齡就增加1歲,當它的年齡增加到一定程度(默認為15歲),就將會被晉升到老年代。
動態對象年齡判定:虛擬機並不是永遠要求對象的年齡必須達到了MaxTenuringThreshold才能晉升老年代,如果在Survivor空間中相同年齡所有對象大小的總和大於Survivor空間的一半,年齡大於或等於該年齡的對象就可以直接進入老年代,無須等到MaxTenuringThreshold中要求的年齡。
空間分配擔保:在發生Minor GC之前,虛擬機會先檢查老年代最大可用的連續空間是否大於新生代所有對象總空間,如果這個條件成立,那麼Minor GC可以確保是安全的。如果不成立,則虛擬機會查看HandlePromotionFailure設置值是否允許擔保失敗。
總結
內存回收與垃圾收集器在很多時候都是影響系統性能、並發能力的主要因素之一,虛擬機之所以提供多種不同的收集器以及提供大量的調節參數,是因為只有根據實際應用需求、實現方式選擇最優的收集方式才能獲取最高的性能。沒有固定收集器、參數組合,也沒有最優的調優方法,虛擬機也就沒有什麼必然的內存回收行為。
以上是我學習《深入理解Java虛擬機》一書的整理筆記。
參考資料《深入理解Java虛擬機》
感謝閱讀,希望能幫助到大家,謝謝大家對本站的支持!