java簡略網頁抓取的完成辦法。本站提示廣大學習愛好者:(java簡略網頁抓取的完成辦法)文章只能為提供參考,不一定能成為您想要的結果。以下是java簡略網頁抓取的完成辦法正文
本文實例講述了java簡略網頁抓取的完成辦法。分享給年夜家供年夜家參考。詳細剖析以下:
配景引見
一 tcp簡介
1 tcp 完成收集中點對點的傳輸
2 傳輸是經由過程ports和sockets
ports供給了分歧類型的傳輸(例如 http的port是80)
1)sockets可以綁定在特定端口上,而且供給傳輸功效
2)一個port可以銜接多個socket
二 URL簡介
URL 是對可以從互聯網上獲得的資本的地位和拜訪辦法的一種簡練的表現,是互聯網上尺度資本的地址。
互聯網上的每一個文件都有一個獨一的URL,它包括的信息指出文件的地位和閱讀器應當怎樣處置它。
綜上,我們要抓取網頁的內容本質上就是經由過程url來抓取網頁內容。
Java供給了兩種辦法:
一種是直接從URL讀取網頁
一種是經由過程 URLConnection來讀取網頁
個中的URLConnection是以http為焦點的類,供給了許多關於銜接http的函數
本文將給出基於URLConnection的實例代碼。
在此之前我們先來看下關於url的異常。不懂得java異常機制的請參看上一篇博文。
結構URL的異常MalformedURLException發生前提:url的字符串為空或許是不克不及識別的協定
樹立 URLConnection的異常 IOException發生前提: openConnection掉敗,留意openConnection時 代碼還未銜接長途,只是為銜接長途做預備
綜上所述,終究代碼以下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
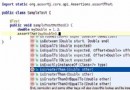
public class SimpleNetSpider {
public static void main(String[] args) {
try{
URL u = new URL("http://docs.oracle.com/javase/tutorial/networking/urls/");
URLConnection connection = u.openConnection();
HttpURLConnection htCon = (HttpURLConnection) connection;
int code = htCon.getResponseCode();
if (code == HttpURLConnection.HTTP_OK)
{
System.out.println("find the website");
BufferedReader in=new BufferedReader(new InputStreamReader(htCon.getInputStream()));
String inputLine;
while ((inputLine = in.readLine()) != null)
System.out.println(inputLine);
in.close();
}
else
{
System.out.println("Can not access the website");
}
}
catch(MalformedURLException e )
{
System.out.println("Wrong URL");
}
catch(IOException e)
{
System.out.println("Can not connect");
}
}
}
願望本文所述對年夜家的Java法式設計有所贊助。