JAVA渣滓搜集器與內存分派戰略詳解。本站提示廣大學習愛好者:(JAVA渣滓搜集器與內存分派戰略詳解)文章只能為提供參考,不一定能成為您想要的結果。以下是JAVA渣滓搜集器與內存分派戰略詳解正文
引言
渣滓搜集技巧其實不是Java說話開創的,1960年出生於MIT的Lisp是第一門真正應用內存靜態分派和渣滓搜集技巧的說話。渣滓搜集技巧須要斟酌的三個成績是:
1、哪些內存須要收受接管
2、甚麼時刻收受接管
3、若何收受接管
java內存運轉時區域的散布,個中法式計數器,虛擬機棧,當地辦法區都是跟著線程而生,隨線程而滅,所以這幾個區域就不須要過量斟酌收受接管成績。然則堆和辦法區就紛歧樣了,只要在法式運轉時代我們才曉得會創立哪些對象,這部門內存的分派和收受接管都是靜態的。渣滓搜集器所存眷的就是這部門內存。
一 對象逝世亡判據
渣滓搜集器在對一個對象收受接管之前,起首要斷定對象在法式中能否還有應用的能夠性,充要前提就是沒有被法式可拜訪援用再指向這個對象實例。最簡略的方法就是給對象實例添加中添加一個援用計數器,每當有一個援用指向它時,計數器就加一,當援用掉效時,計數器就減一,假如計數器值為0則解釋沒有援用指向它,可以停止收受接管。然則這個辦法上鉤數器為0其實不是一個需要前提,例如,生成兩個對象實例,每一個對象實例的屬性都指向對方,那末這個兩個對象實例分離起碼有一個援用。
java采取的是可達性剖析算法,即找一部門對象作為"GC Roots"節點,從這些節點開端向下搜刮,當某個對象到"GC Roots"節點沒有可達途徑時,解釋此對象是弗成用的。在java中作為"GC Roots"的節點包含:虛擬機棧中援用的對象,辦法區靜態屬性援用的對象,辦法區常量援用的對象,當地辦法區中當地挪用所援用的對象。
援用擴大
假如reference類型的數據中存儲的數值是另外一塊內存的肇端地址,那末這塊內存就代表著一個援用。一個對象在這類狀況下,只能有被援用和沒有被援用兩種狀況。java對援用概念停止了擴大,將援用分為強援用(new),軟援用(softReference),弱援用(WeakReference),虛援用(PhantomReference)。假如強援用存在,則渣滓搜集器不會收受接管該對象。假如體系行將產生內存溢出異常,那末渣滓收受接管集器則會收受接管軟援用對象。弱援用對象只能存活到下一次渣滓搜集之前。虛援用對象不會對其生計時光組成任何影響。
對象的自我救贖
在渣滓搜集器發明某一個對象到"GC Roots"途徑弗成達時,先會斷定該對象能否籠罩finalize()辦法,或能否履行過finalize()辦法。假如籠罩了且沒有履行過該辦法,則會將該對象放到低優先級的Finalizer線程中去履行finalize()辦法,假如在finalize()辦法中該對象又被援用,則會有一次逃走被收受接管的命運。
辦法區的收受接管
辦法區中重要收受接管放棄的常量和無用的類。關於常量,假如沒有援用指向常量,則該常量會被收受接管。關於類的收受接管則費事很多,起首要斷定該類是無用的類,無用的類要知足三個前提:1一切類的實例被收受接管2加載該類的ClassLoader曾經被收受接管3Class沒有被援用,不會經由過程反射拜訪該類的辦法。
二 渣滓收受接管算法
標志-消除算法(Mark-Sweep)
該算法分為兩個階段:起首標志處要收受接管的對象,標志完成後同一收受接管一切被標志的對象。
存在的成績:1 標志和消除效力都不高 2 標志消除後會發生年夜量內存碎片,分派年夜對象時能夠觸發另外一次渣滓搜集。
復制算法(Copying)
該算法將內存分為兩個等年夜小的區域,每次只應用一個區域。當一個區域快用完了,就將這個區域中存活的對象復制到另外一個區域
長處是防止了內存碎片的發生,缺陷是糟蹋內存空間。
有公司研討注解,重生代的對象98%都是朝生暮逝世,所以虛擬機把重生代內存劃分為一個較年夜的Eden空間和兩個較小的Survivor空間。每次只是用Eden空間和一個Survior空間,當停止復制清算時,將Survivor空間和Eden空間中存活的對象復制到另外一塊Survivor空間。當Survivor空間不敷用時,就會依附老年月停止分派擔保。
標志-整頓算法(Mark-Compact)
針對老年月對象存活率高的情形,復制算法顯著不適合,因而采取標志整頓算法,標志和標志消除算法雷同,二後邊的整頓則是讓一切存活的對象都向一端挪動,然後清算失落界限外的內存。
分代搜集
以後虛擬機都采取分代搜集,分代的根據是對象的存活周期。普通重生代存活率低,采取復制算法。老年月存活率高采取標志整頓或標志消除。
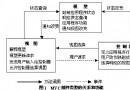
三渣滓搜集器
因為虛擬機采取了分代搜集,所以針對分歧代搜集器也分歧。上圖是HotSpot虛擬機的渣滓搜集器,連線表現可以協同任務。
Serial搜集器,復制算法,它是一個單線程的搜集器,而且在停止搜集時會暫停其他線程,它默許是client形式下的重生代搜集器。
ParNew搜集器是Serial搜集器的多線程版,它是第一款並發搜集器。
Parallel Scavenge搜集器可以准確掌握吞吐量(用戶代碼運轉時光/(用戶代碼時光+渣滓搜集時光))
SerialOld搜集器是serial搜集器的老年版,采取標志整頓算法,異樣是單線程搜集器。
ParallelOld是ParallelScavenge搜集器的老年版,應用多線程和標志整頓算法。
CMS搜集器是以最短收受接管停留時光為目的的搜集器,采取標志消除算法,在看重呼應速度的體系中得以運用。然則缺陷是對CPU資本敏感,沒法處置浮動渣滓,易發生內存碎片。
G1搜集器是最新推出的搜集器,可運用在JDK1.7u4及以上版本。它將內存分為多個Region,重生代和老年月分離包括多個Region。G1跟蹤各個Region,斷定渣滓價值年夜小,優先收受接管價值最年夜的Region。
四 內存分派與收受接管戰略
對象的分派,就是在堆上分派,對象重要分派在重生代的Eden區域中,假如啟動了當地線程分派緩沖,則按線程優先在TLAB平分配。多數情形也有能夠直接分派到老年月。
對象在Eden區域分派時,當Eden區域沒有足夠空間,虛擬機遇提議一次重生代渣滓搜集。
假如對象須要年夜量持續內存空間,例如String類型和數組。年夜對象關於虛擬機內存分派來講是一個壞新聞,朝生暮逝世的年夜對象是要命的壞新聞。常常湧現年夜對象會招致屢次動身渣滓搜集。關於這類對象,可以設置參數將年夜對象直接存入老年月。
每個對象都有一個年紀計數器,當對象在Eden區域出身,每經由一次GC,而且存入Survivor,計數器加一。昔時齡增長到必定水平(默許15),則會被存入老年月。同時,假如Survivor空間中雷同年紀對象占空間跨越50%,則也會直接進入老年月。
總結
渣滓搜集算法:復制算法,標志-消除算法,標志-清算算法。
渣滓搜集器特色:重生代用復制,老年月用標志清算,CMS用標志消除。
Eden空間年夜小和Survivor空間年夜小默許比率為8:1,即重生代10%的空間用來寄存復制後的對象。
以上就是本文的全體內容,願望年夜家可以或許愛好。