深刻解析Java中的編碼轉換和編碼息爭碼操作。本站提示廣大學習愛好者:(深刻解析Java中的編碼轉換和編碼息爭碼操作)文章只能為提供參考,不一定能成為您想要的結果。以下是深刻解析Java中的編碼轉換和編碼息爭碼操作正文
1、Java編碼轉換進程
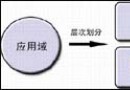
我們老是用一個java類文件和用戶停止最直接的交互(輸出、輸入),這些交互內容包括的文字能夠會包括中文。不管這些java類是與數據庫交互,照樣與前端頁面交互,他們的性命周期老是如許的:
(1)、法式員在操作體系上經由過程編纂器編寫法式代碼而且以.java的格局保留操作體系中,這些文件我們稱之為源文件。
(2)、經由過程JDK中的javac.exe編譯這些源文件構成.class類。
(3)、直接運轉這些類或許安排在WEB容器中運轉,獲得輸入成果。
這些進程是從微觀下面來不雅察的,懂得這個確定是不可的,我們須要真正來懂得java是若何來編碼和被解碼的:
第一步:當我們用編纂器編寫java源文件,法式文件在保留時會采取操作體系默許的編碼格局(普通我們中文的操作體系采取的是GBK編碼格局)構成一個.java文件。java源文件是采取操作體系默許支撐的file.encoding編碼格局保留的。上面代碼可以檢查體系的file.encoding參數值。
System.out.println(System.getProperty("file.encoding"));
第二步:當我們應用javac.exe編譯我們的java文件時,JDK起首會確認它的編譯參數encoding來肯定源代碼字符集,假如我們不指定該編譯參數,JDK起首會獲得操作體系默許的file.encoding參數,然後JDK就會把我們編寫的java源法式從file.encoding編碼格局轉化為JAVA外部默許的UNICODE格局放入內存中。
第三步:JDK將下面編譯好的且保留在內存中信息寫入class文件中,構成.class文件。此時.class文件是Unicode編碼的,也就是說我們罕見的.class文件中的內容不管是中文字符照樣英文字符,他們都曾經轉換為Unicode編碼格局了。
在這一步中對對JSP源文件的處置方法有點兒分歧:WEB容器挪用JSP編譯器,JSP編譯器起首會檢查JSP文件能否設置了文件編碼格局,假如沒有設置則JSP編譯器會挪用挪用JDK采取默許的編碼方法將JSP文件轉化為暫時的servlet類,然後再編譯為.class文件並堅持莅臨時文件夾中。
第四步:運轉編譯的類:在這裡會存在一下幾種情形
(1)、直接在console上運轉。
(2)、JSP/Servlet類。
(3)、java類與數據庫之間。
這三種情形每種情形的方法都邑分歧,
1.Console上運轉的類
這類情形下,JVM起首會把保留在操作體系中的class文件讀入到內存中,這個時刻內存中class文件編碼格局為Unicode,然後JVM運轉它。假如須要用戶輸出信息,則會采取file.encoding編碼格局對用戶輸出的信息停止編碼同時轉換為Unicode編碼格局保留到內存中。法式運轉後,將發生的成果再轉化為file.encoding格局前往給操作體系並輸入到界面去。全部流程以下:
在下面全部流程中,但凡觸及的編碼轉換都不克不及湧現毛病,不然將會發生亂碼。
2.Servlet類
因為JSP文件終究也會轉換為servlet文件(只不外存儲的地位分歧罷了),所以這裡我們也將JSP文件歸入個中。
當用戶要求Servlet時,WEB容器會挪用它的JVM來運轉Servlet。起首JVM會把servlet的class加載到內存中去,內存中的servlet代碼是Unicode編碼格局的。然後JVM在內存中運轉該Servlet,在運轉進程中假如須要接收從客戶端傳遞過去的數據(如表單和URL傳遞的數據),則WEB容器會接收傳入的數據,在吸收進程中假如法式設定了傳入參數的的編碼則采取設定的編碼格局,假如沒有設置則采取默許的ISO-8859-1編碼格局,吸收的數據後JVM會將這些數據停止編碼格局轉換為Unicode而且存入到內存中。運轉Servlet後發生輸入成果,同時這些輸入成果的編碼格局依然為Unicode。緊接著WEB容器會將發生的Unicode編碼格局的字符串直接發送置客戶端,假如法式指定了輸入時的編碼格局,則依照指定的編碼格局輸入到閱讀器,不然采取默許的ISO-8859-1編碼格局。全部進程流程圖以下:
3.數據庫部門
我們曉得java法式與數據庫的銜接都是經由過程JDBC驅動法式來銜接的,而JDBC驅動法式默許的是ISO-8859-1編碼格局的,也就是說我們經由過程java法式向數據庫傳遞數據時,JDBC起首會將Unicode編碼格局的數據轉換為ISO-8859-1的編碼格局,然後在存儲在數據庫中,即在數據庫保留數據時,默許格局為ISO-8859-1。
2、編碼&解碼
上面將停止java在那些場所須要停止編碼息爭碼操作,並詳序中央的進程,進一步控制java的編碼息爭碼進程。在java中重要有四個場景須要停止編碼解碼操作:
(1):I/O操作
(2):內存
(3):數據庫
(4):javaWeb
上面重要引見後面兩種場景,數據庫部門只需設置准確編碼格局就不會有甚麼成績,javaWeb場景過量須要懂得URL、get、POST的編碼,servlet的解碼,所以javaWeb場景下節LZ引見。
1.I/O操作
在後面LZ就提過亂碼成績不過就是轉碼進程中編碼格局的不同一發生的,好比編碼時采取UTF-8,解碼采取GBK,但最基本的緣由是字符到字節或許字節到字符的轉換出成績了,而這中情形的轉換最重要的場景就是I/O操作的時刻。固然I/O操作重要包含收集I/O(也就是javaWeb)和磁盤I/O。收集I/O下節引見。
起首我們先看I/O的編碼操作。
InputStream為字節輸出流的一切類的超類,Reader為讀取字符流的籠統類。java讀取文件的方法分為按字撙節讀取和按字符流讀取,個中InputStream、Reader是這兩種讀取方法的超類。
按字節
我們普通都是應用InputStream.read()辦法在數據流中讀取字節(read()每次都只讀取一個字節,效力異常慢,我們普通都是應用read(byte[])),然後保留在一個byte[]數組中,最初轉換為String。在我們讀取文件時,讀取字節的編碼取決於文件所應用的編碼格局,而在轉換為String進程中也會觸及到編碼的成績,假如二者之間的編碼格局分歧能夠會湧現成績。例如存在一個成績test.txt編碼格局為UTF-8,那末經由過程字撙節讀取文件時所取得的數據流編碼格局就是UTF-8,而我們在轉化成String進程中假如不指定編碼格局,則默許應用體系編碼格局(GBK)來解碼操作,因為二者編碼格局紛歧致,那末在結構String進程確定會發生亂碼,以下:
File file = new File("C:\\test.txt");
InputStream input = new FileInputStream(file);
StringBuffer buffer = new StringBuffer();
byte[] bytes = new byte[1024];
for(int n ; (n = input.read(bytes))!=-1 ; ){
buffer.append(new String(bytes,0,n));
}
System.out.println(buffer);
輸入成果為亂碼....
test.txt中的內容為:我是 cm。
要想不湧現亂碼,在結構String進程中指定編碼格局,使得編碼解碼時二者編碼格局堅持分歧便可:
buffer.append(new String(bytes,0,n,"UTF-8"));
按字符
其實字符流可以看作是一種包裝流,它的底層照樣采取字撙節來讀取字節,然後它應用指定的編碼方法將讀取字節解碼為字符。在java中Reader是讀取字符流的超類。所以從底層下去看按字節讀取文件和按字符讀取沒甚麼差別。在讀取的時刻字符讀取每次是讀取留個字節,字撙節每次讀取一個字節。
字節&字符轉換
字節轉換為字符必定少不了InputStreamReader。API說明以下:InputStreamReader 是字撙節通向字符流的橋梁:它應用指定的 charset 讀取字節並將其解碼為字符。它應用的字符集可以由稱號指定或顯式給定,或許可以接收平台默許的字符集。 每次挪用 InputStreamReader 中的一個 read() 辦法都邑招致從底層輸出流讀取一個或多個字節。要啟用從字節到字符的有用轉換,可以提早從底層流讀取更多的字節,使其跨越知足以後讀取操作所需的字節。API說明異常清晰,InputStreamReader在底層讀取文件時依然采取字節讀取,讀取字節後它須要依據一個指定的編碼格局來解析為字符,假如沒有指定編碼格局則采取體系默許編碼格局。
String file = "C:\\test.txt";
String charset = "UTF-8";
// 寫字符換轉成字撙節
FileOutputStream outputStream = new FileOutputStream(file);
OutputStreamWriter writer = new OutputStreamWriter(outputStream, charset);
try {
writer.write("我是 cm");
} finally {
writer.close();
}
// 讀取字節轉換成字符
FileInputStream inputStream = new FileInputStream(file);
InputStreamReader reader = new InputStreamReader(
inputStream, charset);
StringBuffer buffer = new StringBuffer();
char[] buf = new char[64];
int count = 0;
try {
while ((count = reader.read(buf)) != -1) {
buffer.append(buf, 0, count);
}
} finally {
reader.close();
}
System.out.println(buffer);
2.內存
起首我們看上面這段簡略的代碼
String s = "我是 cm"; byte[] bytes = s.getBytes(); String s1 = new String(bytes,"GBK"); String s2 = new String(bytes);
在這段代碼中我們看到了三處編碼轉換進程(一次編碼,兩次解碼)。先看String.getTytes():
public byte[] getBytes() {
return StringCoding.encode(value, 0, value.length);
}
外部挪用StringCoding.encode()辦法操作:
static byte[] encode(char[] ca, int off, int len) {
String csn = Charset.defaultCharset().name();
try {
// use charset name encode() variant which provides caching.
return encode(csn, ca, off, len);
} catch (UnsupportedEncodingException x) {
warnUnsupportedCharset(csn);
}
try {
return encode("ISO-8859-1", ca, off, len);
} catch (UnsupportedEncodingException x) {
// If this code is hit during VM initialization, MessageUtils is
// the only way we will be able to get any kind of error message.
MessageUtils.err("ISO-8859-1 charset not available: "
+ x.toString());
// If we can not find ISO-8859-1 (a required encoding) then things
// are seriously wrong with the installation.
System.exit(1);
return null;
}
}
encode(char[] paramArrayOfChar, int paramInt1, int paramInt2)辦法起首挪用體系的默許編碼格局,假如沒有指定編碼格局則默許應用ISO-8859-1編碼格局停止編碼操作,進一步深刻以下:
String csn = (charsetName == null) ? "ISO-8859-1" : charsetName;
異樣的辦法可以看到new String 的結構函數外部是挪用StringCoding.decode()辦法:
public String(byte bytes[], int offset, int length, Charset charset) {
if (charset == null)
throw new NullPointerException("charset");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charset, bytes, offset, length);
}
decode辦法和encode對編碼格局的處置是一樣的。
關於以上兩種情形我們只須要設置同一的編碼格局普通都不會發生亂碼成績。
3.編碼&編碼格局
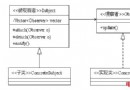
起首先看看java編碼類圖
起首依據指定的chart設置ChartSet類,然後依據ChartSet創立ChartSetEncoder對象,最初再挪用 CharsetEncoder.encode 對字符串停止編碼,分歧的編碼類型都邑對應到一個類中,現實的編碼進程是在這些類中完成的。上面時序圖展現具體的編碼進程:
經由過程這編碼的類圖和時序圖可以懂得編碼的具體進程。上面將經由過程一段簡略的代碼對ISO-8859-1、GBK、UTF-8編碼
public class Test02 {
public static void main(String[] args) throws UnsupportedEncodingException {
String string = "我是 cm";
Test02.printChart(string.toCharArray());
Test02.printChart(string.getBytes("ISO-8859-1"));
Test02.printChart(string.getBytes("GBK"));
Test02.printChart(string.getBytes("UTF-8"));
}
/**
* char轉換為16進制
*/
public static void printChart(char[] chars){
for(int i = 0 ; i < chars.length ; i++){
System.out.print(Integer.toHexString(chars[i]) + " ");
}
System.out.println("");
}
/**
* byte轉換為16進制
*/
public static void printChart(byte[] bytes){
for(int i = 0 ; i < bytes.length ; i++){
String hex = Integer.toHexString(bytes[i] & 0xFF);
if (hex.length() == 1) {
hex = '0' + hex;
}
System.out.print(hex.toUpperCase() + " ");
}
System.out.println("");
}
}
輸入:
6211 662f 20 63 6d 3F 3F 20 63 6D CE D2 CA C7 20 63 6D E6 88 91 E6 98 AF 20 63 6D
經由過程法式我們可以看到“我是 cm”的成果為:
char[]:6211 662f 20 63 6d ISO-8859-1:3F 3F 20 63 6D GBK:CE D2 CA C7 20 63 6D UTF-8:E6 88 91 E6 98 AF 20 63 6D
圖以下: