Java HashMap的任務道理。本站提示廣大學習愛好者:(Java HashMap的任務道理)文章只能為提供參考,不一定能成為您想要的結果。以下是Java HashMap的任務道理正文
年夜部門Java開辟者都在應用Map,特殊是HashMap。HashMap是一種簡略但壯大的方法去存儲和獲得數據。但有若干開辟者曉得HashMap外部若何任務呢?幾天前,我浏覽了java.util.HashMap的年夜量源代碼(包含Java 7 和Java 8),來深刻懂得這個基本的數據構造。在這篇文章中,我會說明java.util.HashMap的完成,描寫Java 8完成中添加的新特征,並評論辯論機能、內存和應用HashMap時的一些已知成績。
外部存儲
Java HashMap類完成了Map<K, V>接口。這個接口中的重要辦法包含:
V put(K key, V value) V get(Object key) V remove(Object key) Boolean containsKey(Object key)
HashMap應用了一個外部類Entry<K, V>來存儲數據。這個外部類是一個簡略的鍵值對,並帶有額定兩個數據:
一個指向其他進口(譯者注:援用對象)的援用,如許HashMap可以存儲相似鏈接列表如許的對象。
一個用來代表鍵的哈希值,存儲這個值可以免HashMap在每次須要時都從新生成鍵所對應的哈希值。
上面是Entry<K, V>在Java 7下的一部門代碼:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
…
}
HashMap將數據存儲到多個單向Entry鏈表中(有時也被稱為桶bucket或許容器orbins)。一切的列表都被注冊到一個Entry數組中(Entry<K, V>[]數組),這個外部數組的默許長度是16。
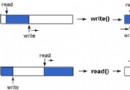
上面這幅圖描寫了一個HashMap實例的外部存儲,它包括一個nullable對象構成的數組。每一個對象都銜接到別的一個對象,如許就組成了一個鏈表。
一切具有雷同哈希值的鍵都邑被放到統一個鏈表(桶)中。具有分歧哈希值的鍵終究能夠會在雷同的桶中。
當用戶挪用 put(K key, V value) 或許 get(Object key) 時,法式管帳算對象應當在的桶的索引。然後,法式會迭代遍歷對應的列表,來尋覓具有雷同鍵的Entry對象(應用鍵的equals()辦法)。
關於挪用get()的情形,法式會前往值所對應的Entry對象(假如Entry對象存在)。
關於挪用put(K key, V value)的情形,假如Entry對象曾經存在,那末法式會將值調換為新值,不然,法式會在單向鏈表的表頭創立一個新的Entry(從參數中的鍵和值)。
桶(鏈表)的索引,是經由過程map的3個步調生成的:
起首獲得鍵的散列碼。
法式反復散列碼,來阻攔針對鍵的蹩腳的哈希函數,由於這有能夠會將一切的數據都放到外部數組的雷同的索引(桶)上。
法式拿到反復後的散列碼,並對其應用數組長度(最小是1)的位掩碼(bit-mask)。這個操作可以包管索引不會年夜於數組的年夜小。你可以將其看作是一個經由盤算的優化取模函數。
上面是生成索引的源代碼:
// the "rehash" function in JAVA 7 that takes the hashcode of the key
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// the "rehash" function in JAVA 8 that directly takes the key
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// the function that returns the index from the rehashed hash
static int indexFor(int h, int length) {
return h & (length-1);
}
為了更有用地任務,外部數組的年夜小必需是2的冪值。讓我們看一下為何:
假定數組的長度是17,那末掩碼的值就是16(數組長度-1)。16的二進制表現是0…010000,如許關於任何值H來講,“H & 16”的成果就是16或許0。這意味著長度為17的數組只能運用到兩個桶上:一個是0,別的一個是16,如許不是很有用率。然則假如你將數組的長度設置為2的冪值,例如16,那末按位索引的任務釀成“H & 15”。15的二進制表現是0…001111,索引公式輸入的值可以從0到15,如許長度為16的數組便可以被充足應用了。例如:
假如H = 952,它的二進制表現是0..01110111000,對應的索引是0…01000 = 8
假如H = 1576,它的二進制表現是0..011000101000,對應的索引是0…01000 = 8
假如H = 12356146,它的二進制表現是0..0101111001000101000110010,對應的索引是0…00010 = 2
假如H = 59843,它的二進制表現是0..01110100111000011,它對應的索引是0…00011 = 3
這類機制關於開辟者來講是通明的:假如他選擇一個長度為37的HashMap,Map會主動選擇下一個年夜於37的2的冪值(64)作為外部數組的長度。
主動調劑年夜小
在獲得索引後,get()、put()或許remove()辦法會拜訪對應的鏈表,來檢查針對指定鍵的Entry對象能否曾經存在。在不做修正的情形下,這個機制能夠會招致機能成績,由於這個辦法須要迭代全部列表來檢查Entry對象能否存在。假定外部數組的長度采取默許值16,而你須要存儲2,000,000筆記錄。在最好的情形下,每一個鏈表會有125,000個Entry對象(2,000,000/16)。get()、remove()和put()辦法在每次履行時,都須要停止125,000次迭代。為了不這類情形,HashMap可以增長外部數組的長度,從而包管鏈表中只保存很少的Entry對象。
當你創立一個HashMap時,你可以經由過程以下結構函數指定一個初始長度,和一個loadFactor:
</pre> public HashMap(int initialCapacity, float loadFactor) <pre>
假如你不指定參數,那末默許的initialCapacity的值是16, loadFactor的默許值是0.75。initialCapacity代表外部數組的鏈表的長度。
當你每次應用put(…)辦法向Map中添加一個新的鍵值對時,該辦法會檢討能否須要增長外部數組的長度。為了完成這一點,Map存儲了2個數據:
Map的年夜小:它代表HashMap中記載的條數。我們在向HashMap中拔出或許刪除值時更新它。
閥值:它等於外部數組的長度*loadFactor,在每次調劑外部數組的長度時,該閥值也會同時更新。
在添加新的Entry對象之前,put(…)辦法會檢討以後Map的年夜小能否年夜於閥值。假如年夜於閥值,它會創立一個新的數組,數組長度是以後外部數組的兩倍。由於新數組的年夜小曾經產生轉變,所以索引函數(就是前往“鍵的哈希值 & (數組長度-1)”的位運算成果)也隨之轉變。調劑數組的年夜小會創立兩個新的桶(鏈表),而且將一切現存Entry對象從新分派到桶上。調劑數組年夜小的目的在於下降鏈表的年夜小,從而下降put()、remove()和get()辦法的履行時光。關於具有雷同哈希值的鍵所對應的一切Entry對象來講,它們會在調劑年夜小後分派到雷同的桶中。然則,假如兩個Entry對象的鍵的哈希值紛歧樣,但它們之前在統一個桶上,那末在調劑今後,其實不能包管它們仍然在統一個桶上。
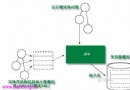
這幅圖片描寫了調劑前和調劑後的外部數組的情形。在調劑數組長度之前,為了獲得Entry對象E,Map須要迭代遍歷一個包括5個元素的鏈表。在調劑數組長度以後,異樣的get()辦法則只須要遍歷一個包括2個元素的鏈表,如許get()辦法在調劑數組長度後的運轉速度進步了2倍。
線程平安
假如你曾經異常熟習HashMap,那末你確定曉得它不是線程平安的,然則為何呢?例如假定你有一個Writer線程,它只會向Map中拔出曾經存在的數據,一個Reader線程,它會從Map中讀取數據,那末它為何不任務呢?
由於在主動調劑年夜小的機制下,假如線程試著去添加或許獲得一個對象,Map能夠會應用舊的索引值,如許就不會找到Entry對象地點的新桶。
在最蹩腳的情形下,當2個線程同時拔出數據,而2次put()挪用會同時動身數組主動調劑年夜小。既然兩個線程在同時修正鏈表,那末Map有能夠在一個鏈表的外部輪回中加入。假如你試著去獲得一個帶有外部輪回的列表中的數據,那末get()辦法永久不會停止。
HashTable供給了一個線程平安的完成,可以阻攔上述情形產生。然則,既然一切的同步的CRUD操作都異常慢。例如,假如線程1挪用get(key1),然後線程2挪用get(key2),線程2挪用get(key3),那末在指准時間,只能有1個線程可以獲得它的值,然則3個線程都可以同時拜訪這些數據。
從Java 5開端,我們就具有一個更好的、包管線程平安的HashMap完成:ConcurrentHashMap。關於ConcurrentMap來講,只要桶是同步的,如許假如多個線程不應用統一個桶或許調劑外部數組的年夜小,它們可以同時挪用get()、remove()或許put()辦法。在一個多線程運用法式中,這類方法是更好的選擇。
鍵的不變性
為何將字符串和整數作為HashMap的鍵是一種很好的完成?重要是由於它們是弗成變的!假如你選擇本身創立一個類作為鍵,但不克不及包管這個類是弗成變的,那末你能夠會在HashMap外部喪失數據。
我們來看上面的用例:
你有一個鍵,它的外部值是“1”。
你向HashMap中拔出一個對象,它的鍵就是“1”。
HashMap從鍵(即“1”)的散列碼中生成哈希值。
Map在新創立的記載中存儲這個哈希值。
你修改鍵的外部值,將其變成“2”。
鍵的哈希值產生了轉變,然則HashMap其實不曉得這一點(由於存儲的是舊的哈希值)。
你試著經由過程修正後的鍵獲得響應的對象。
Map管帳算新的鍵(即“2”)的哈希值,從而找到Entry對象地點的鏈表(桶)。
情形1: 既然你曾經修正了鍵,Map會試著在毛病的桶中尋覓Entry對象,沒有找到。
情形2: 你很榮幸,修正後的鍵生成的桶和舊鍵生成的桶是統一個。Map這時候會在鏈表中停止遍歷,已找到具有雷同鍵的Entry對象。然則為了尋覓鍵,Map起首會經由過程挪用equals()辦法來比擬鍵的哈希值。由於修正後的鍵會生成分歧的哈希值(舊的哈希值被存儲在記載中),那末Map沒有方法在鏈表中找到對應的Entry對象。
上面是一個Java示例,我們向Map中拔出兩個鍵值對,然後我修正第一個鍵,並試著去獲得這兩個對象。你會發明從Map中前往的只要第二個對象,第一個對象曾經“喪失”在HashMap中:
public class MutableKeyTest {
public static void main(String[] args) {
class MyKey {
Integer i;
public void setI(Integer i) {
this.i = i;
}
public MyKey(Integer i) {
this.i = i;
}
@Override
public int hashCode() {
return i;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof MyKey) {
return i.equals(((MyKey) obj).i);
} else
return false;
}
}
Map<MyKey, String> myMap = new HashMap<>();
MyKey key1 = new MyKey(1);
MyKey key2 = new MyKey(2);
myMap.put(key1, "test " + 1);
myMap.put(key2, "test " + 2);
// modifying key1
key1.setI(3);
String test1 = myMap.get(key1);
String test2 = myMap.get(key2);
System.out.println("test1= " + test1 + " test2=" + test2);
}
}
上述代碼的輸入是“test1=null test2=test 2”。如我們希冀的那樣,Map沒有才能獲得經由修正的鍵 1所對應的字符串1。
Java 8 中的改良
在Java 8中,HashMap中的外部完成停止了許多修正。切實其實如斯,Java 7應用了1000行代碼來完成,而Java 8中應用了2000行代碼。我在後面描寫的年夜部門內容在Java 8中仍然是對的,除應用鏈表來保留Entry對象。在Java 8中,我們依然應用數組,但它會被保留在Node中,Node中包括了和之前Entry對象一樣的信息,而且也會應用鏈表:
上面是在Java 8中Node完成的一部門代碼:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
那末和Java 7比擬,究竟有甚麼年夜的差別呢?好吧,Node可以被擴大成TreeNode。TreeNode是一個紅黑樹的數據構造,它可以存儲更多的信息,如許我們可以在O(log(n))的龐雜度下添加、刪除或許獲得一個元素。上面的示例描寫了TreeNode保留的一切信息:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
final int hash; // inherited from Node<K,V>
final K key; // inherited from Node<K,V>
V value; // inherited from Node<K,V>
Node<K,V> next; // inherited from Node<K,V>
Entry<K,V> before, after;// inherited from LinkedHashMap.Entry<K,V>
TreeNode<K,V> parent;
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev;
boolean red;
紅黑樹是自均衡的二叉搜刮樹。它的外部機制可以包管它的長度老是log(n),不論我們是添加照樣刪除節點。應用這類類型的樹,最重要的利益是針對外部表中很多數據都具有雷同索引(桶)的情形,這時候對樹停止搜刮的龐雜度是O(log(n)),而關於鏈表來講,履行雷同的操作,龐雜度是O(n)。
如你所見,我們在樹中確切存儲了比鏈表更多的數據。依據繼續准繩,外部表中可以包括Node(鏈表)或許TreeNode(紅黑樹)。Oracle決議依據上面的規矩來應用這兩種數據構造:
- 關於外部表中的指定索引(桶),假如node的數量多於8個,那末鏈表就會被轉換成紅黑樹。
- 關於外部表中的指定索引(桶),假如node的數量小於6個,那末紅黑樹就會被轉換成鏈表。
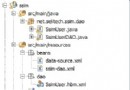
這張圖片描寫了在Java 8 HashMap中的外部數組,它既包括樹(桶0),也包括鏈表(桶1,2和3)。桶0是一個樹構造是由於它包括的節點年夜於8個。
內存開支
JAVA 7
應用HashMap會消費一些內存。在Java 7中,HashMap將鍵值對封裝成Entry對象,一個Entry對象包括以下信息:
指向下一個記載的援用
一個事後盤算的哈希值(整數)
一個指向鍵的援用
一個指向值的援用
另外,Java 7中的HashMap應用了Entry對象的外部數組。假定一個Java 7 HashMap包括N個元素,它的外部數組的容量是CAPACITY,那末額定的內存消費年夜約是:
sizeOf(integer)* N + sizeOf(reference)* (3*N+C)
個中:
整數的年夜小是4個字節
援用的年夜小依附於JVM、操作體系和處置器,但平日都是4個字節。
這就意味著內存總開支平日是16 * N + 4 * CAPACITY字節。
留意:在Map主動調劑年夜小後,CAPACITY的值是下一個年夜於N的最小的2的冪值。
留意:從Java 7開端,HashMap采取了延遲加載的機制。這意味著即便你為HashMap指定了年夜小,在我們第一次應用put()辦法之前,記載應用的外部數組(消耗4*CAPACITY字節)也不會在內存平分配空間。
JAVA 8
在Java 8完成中,盤算內存應用情形變得龐雜一些,由於Node能夠會和Entry存儲雷同的數據,或許在此基本上再增長6個援用和一個Boolean屬性(指定能否是TreeNode)。
假如一切的節點都只是Node,那末Java 8 HashMap消費的內存和Java 7 HashMap消費的內存是一樣的。
假如一切的節點都是TreeNode,那末Java 8 HashMap消費的內存就釀成:
N * sizeOf(integer) + N * sizeOf(boolean) + sizeOf(reference)* (9*N+CAPACITY )
在年夜部門尺度JVM中,上述公式的成果是44 * N + 4 * CAPACITY 字節。
機能成績
非對稱HashMap vs 平衡HashMap
在最好的情形下,get()和put()辦法都只要O(1)的龐雜度。然則,假如你不去關懷鍵的哈希函數,那末你的put()和get()辦法能夠會履行異常慢。put()和get()辦法的高效履行,取決於數據被分派到外部數組(桶)的分歧的索引上。假如鍵的哈希函數設計不公道,你會獲得一個非對稱的分區(不論外部數據的是多年夜)。一切的put()和get()辦法會應用最年夜的鏈表,如許就會履行很慢,由於它須要迭代鏈表中的全體記載。在最壞的情形下(假如年夜部門數據都在統一個桶上),那末你的時光龐雜度就會變成O(n)。
上面是一個可視化的示例。第一張圖描寫了一個非對稱HashMap,第二張圖描寫了一個平衡HashMap。
skewedHashmap
在這個非對稱HashMap中,在桶0上運轉get()和put()辦法會很消費時光。獲得記載K須要消費6次迭代。
在這個平衡HashMap中,獲得記載K只須要消費3次迭代。這兩個HashMap存儲了雷同數目的數據,而且外部數組的年夜小一樣。獨一的差別是鍵的哈希函數,這個函數用來將記載散布到分歧的桶上。
上面是一個應用Java編寫的極端示例,在這個示例中,我應用哈希函數將一切的數據放到雷同的鏈表(桶),然後我添加了2,000,000條數據。
public class Test {
public static void main(String[] args) {
class MyKey {
Integer i;
public MyKey(Integer i){
this.i =i;
}
@Override
public int hashCode() {
return 1;
}
@Override
public boolean equals(Object obj) {
…
}
}
Date begin = new Date();
Map <MyKey,String> myMap= new HashMap<>(2_500_000,1);
for (int i=0;i<2_000_000;i++){
myMap.put( new MyKey(i), "test "+i);
}
Date end = new Date();
System.out.println("Duration (ms) "+ (end.getTime()-begin.getTime()));
}
}
我的機械設置裝備擺設是core i5-2500k @ 3.6G,在java 8u40下須要消費跨越45分鐘的時光來運轉(我在45分鐘後停滯了過程)。假如我運轉異樣的代碼, 然則我應用以下的hash函數:
@Override
public int hashCode() {
int key = 2097152-1;
return key+2097152*i;
}
運轉它須要消費46秒,和之前比,這類方法好許多了!新的hash函數比舊的hash函數在處置哈希分區時更公道,是以挪用put()辦法會更快一些。假如你如今運轉雷同的代碼,然則應用上面的hash函數,它供給了更好的哈希分區:
@Override
public int hashCode() {
return i;
}
如今只須要消費2秒!
我願望你可以或許認識到哈希函數有多主要。假如在Java 7下面運轉異樣的測試,第一個和第二個的情形會更糟(由於Java 7中的put()辦法龐雜度是O(n),而Java 8中的龐雜度是O(log(n))。
在應用HashMap時,你須要針對鍵找到一種哈希函數,可以將鍵分散到最能夠的桶上。為此,你須要防止哈希抵觸。String對象是一個異常好的鍵,由於它有很好的哈希函數。Integer也很好,由於它的哈希值就是它本身的值。
調劑年夜小的開支
假如你須要存儲年夜量數據,你應當在創立HashMap時指定一個初始的容量,這個容量應當接近你希冀的年夜小。
假如你不如許做,Map會應用默許的年夜小,即16,factorLoad的值是0.75。前11次挪用put()辦法會異常快,然則第12次(16*0.75)挪用時會創立一個新的長度為32的外部數組(和對應的鏈表/樹),第13次到第22次挪用put()辦法會很快,然則第23次(32*0.75)挪用時會從新創立(再一次)一個新的外部數組,數組的長度翻倍。然後外部調劑年夜小的操作會在第48次、96次、192次…..挪用put()辦法時觸發。假如數據量不年夜,重建外部數組的操作會很快,然則數據量很年夜時,消費的時光能夠會從秒級到分鐘級。經由過程初始化時指定Map希冀的年夜小,你可以免調劑年夜小操作帶來的消費。
但這裡也有一個缺陷:假如你將數組設置的異常年夜,例如2^28,但你只是用了數組中的2^26個桶,那末你將會糟蹋年夜量的內存(在這個示例中年夜約是2^30字節)。
結論
關於簡略的用例,你沒有需要曉得HashMap是若何任務的,由於你不會看到O(1)、O(n)和O(log(n))之間的差別。然則假如可以或許懂得這一常常應用的數據構造面前的機制,老是有利益的。別的,關於Java開辟者職位來講,這是一道典范的面試成績。
關於年夜數據量的情形,懂得HashMap若何任務和懂得鍵的哈希函數的主要性就變得異常主要。
我願望這篇文章可以贊助你對HashMap的完成有一個深刻的懂得。