分析Java中HashMap數據構造的源碼及其機能優化。本站提示廣大學習愛好者:(分析Java中HashMap數據構造的源碼及其機能優化)文章只能為提供參考,不一定能成為您想要的結果。以下是分析Java中HashMap數據構造的源碼及其機能優化正文
存儲構造
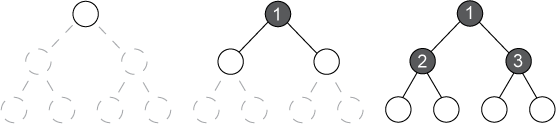
起首,HashMap是基於哈希表存儲的。它外部有一個數組,當元素要存儲的時刻,先盤算其key的哈希值,依據哈希值找到元素在數組中對應的下標。假如這個地位沒有元素,就直接把以後元素放出來,假如有元素了(這裡記為A),就把以後元素鏈接到元素A的後面,然後把以後元素放入數組中。所以在Hashmap中,數組其實保留的是鏈表的首節點。上面是百度百科的一張圖:
如上圖,每一個元素是一個Entry對象,在個中保留了元素的key和value,還有一個指針可用於指向下一個對象。一切哈希值雷同的key(也就是抵觸了)用鏈表把它們串起來,這是拉鏈法。
外部變量
//默許初始容量 static final int DEFAULT_INITIAL_CAPACITY = 16; //最年夜容量 static final int MAXIMUM_CAPACITY = 1 << 30; //默許裝載因子 static final float DEFAULT_LOAD_FACTOR = 0.75f; //哈希表 transient Entry<K,V>[] table; //鍵值對的數目 transient int size; //擴容的阈值 int threshold; //哈希數組的裝載因子 final float loadFactor;
在下面的變量中,capacity是指哈希表的長度,也就是table的年夜小,默許為16。裝載因子loadFactor是哈希表的“裝滿水平”,JDK的文檔是如許說的:
The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
年夜體意思是:裝載因子是哈希表在擴容之前能裝多滿的器量值。當哈希表中“鍵值對”的數目跨越以後容量(capacity)和裝載因子的乘積後,哈希表從新散列(也就是外部的數據構造重建了),而且哈希表的容量年夜約變成本來的兩倍。
從下面的變量界說可以看出,默許的裝載因子DEFAULT_LOAD_FACTOR 是0.75。這個值越年夜,空間應用率越高,但查詢速度(包含get和put)操作會變慢。明確了裝載因子以後,threshold也就可以懂得了,它其實等於容量*裝載因子。
結構器
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity) //盤算出年夜於指定容量的最小的2的冪
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity]; //給哈希表分派空間
useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
init();
}
結構器有好幾個,終究都邑挪用下面的這個。它接收兩個參數,一個是初始容量,還有一個是裝載因子。剛開端先斷定值合不正當,有成績的話會拋出異常。主要的是上面的capacity的盤算,它的邏輯是盤算出年夜於initialCapacity的最小的2的冪。其實目標就是要讓容量能年夜於等於指定的初始容量,但這個值還得是2的指數倍,這是一個症結的成績。這麼做的緣由重要是為了哈希值的映照。先來看一下HashMap中有關哈希的辦法:
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
hash()辦法從新盤算了key的哈希值,用了比擬龐雜的位運算,詳細邏輯我也不清晰,橫豎確定是比擬好的辦法,能削減抵觸甚麼的。
上面的indexFor()是依據哈希值獲得元素在哈希表中的下標。普通在哈希表中是用哈希值對表長取模獲得。當length(也就是capacity)為2的冪時,h & (length-1)是異樣的後果。而且,2的冪必定是偶數,那末減1以後就是奇數,二進制的最初一名必定是1。那末h & (length-1)的最初一名能夠是1,也能夠是0,可以平均地散列。假如length是奇數,那末length-1就是偶數,最初一名是0。此時h & (length-1)的最初一名只能夠是0,一切獲得的下標都是偶數,那末哈希表就糟蹋了一半的空間。所以HashMap中的容量(capacity)必定如果2的冪。可以看到默許的DEFAULT_INITIAL_CAPACITY=16和MAXIMUM_CAPACITY=1<<30都是如許的。
Entry對象
HashMap中的鍵值對被封裝成Entry對象,這是HashMap中的一個外部類,看一下它的完成:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
void recordAccess(HashMap<K,V> m) {
}
void recordRemoval(HashMap<K,V> m) {
}
}
這個類的完成照樣簡練易懂的。供給了getKey()、getValue()等辦法供挪用,斷定相等是請求key和value均相等。
put操作
先put了能力get,所以先看一下put()辦法:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
在這個辦法中,先斷定key能否為null,是的話挪用putForNullKey()辦法,這解釋HashMap許可key為null(其實value可以)。假如不是null,盤算哈希值而且獲得在表中的下標。然後到對應的鏈表中查詢能否曾經存在雷同的key,假如曾經存在就直接更新值(value)。不然,挪用addEntry()辦法停止拔出。
看一下putForNullKey()辦法:
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
可以看到,key為null時直接鄙人標0處拔出,異樣是存在就更新值,不然挪用addEntry()拔出。
上面是addEntry()辦法的完成:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
起首斷定能否要擴容(擴容會從新盤算下標值,而且復制元素),然後盤算數組下標,最初在createEntry()中應用頭插法拔出元素。
get操作
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
這個比put()簡略一些,異樣要斷定key是否是null,然後就是鏈表的遍歷查詢。
機能優化
HashMap是一個高效通用的數據構造,它在每個Java法式中都到處可見。先來引見些基本常識。你能夠也知 道,HashMap應用key的hashCode()和equals()辦法來將值劃分到分歧的桶裡。桶的數目平日要比map中的記載的數目要稍年夜,如許 每一個桶包含的值會比擬少(最好是一個)。當經由過程key停止查找時,我們可以在常數時光內敏捷定位到某個桶(應用hashCode()對桶的數目停止取模) 和要找的對象。
這些器械你應當都曾經曉得了。你能夠還曉得哈希碰撞會對hashMap的機能帶來災害性的影響。假如多個hashCode()的值落到統一個桶內的 時刻,這些值是存儲到一個鏈表中的。最壞的情形下,一切的key都映照到統一個桶中,如許hashmap就退步成了一個鏈表——查找時光從O(1)到 O(n)。我們先來測試下正常情形下hashmap在Java 7和Java 8中的表示。為了能完成掌握hashCode()辦法的行動,我們界說了以下的一個Key類:
class Key implements Comparable<Key> {
private final int value;
Key(int value) {
this.value = value;
}
@Override
public int compareTo(Key o) {
return Integer.compare(this.value, o.value);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass())
return false;
Key key = (Key) o;
return value == key.value;
}
@Override
public int hashCode() {
return value;
}
}
Key類的完成中規中矩:它重寫了equals()辦法而且供給了一個還算過得去的hashCode()辦法。為了不過度的GC,我將弗成變的Key對象緩存了起來,而不是每次都從新開端創立一遍:
class Key implements Comparable<Key> {
public class Keys {
public static final int MAX_KEY = 10_000_000;
private static final Key[] KEYS_CACHE = new Key[MAX_KEY];
static {
for (int i = 0; i < MAX_KEY; ++i) {
KEYS_CACHE[i] = new Key(i);
}
}
public static Key of(int value) {
return KEYS_CACHE[value];
}
如今我們可以開端停止測試了。我們的基准測試應用持續的Key值來創立了分歧的年夜小的HashMap(10的乘方,從1到1百萬)。在測試中我們還會應用key來停止查找,並丈量分歧年夜小的HashMap所消費的時光:
import com.谷歌.caliper.Param;
import com.谷歌.caliper.Runner;
import com.谷歌.caliper.SimpleBenchmark;
public class MapBenchmark extends SimpleBenchmark {
private HashMap<Key, Integer> map;
@Param
private int mapSize;
@Override
protected void setUp() throws Exception {
map = new HashMap<>(mapSize);
for (int i = 0; i < mapSize; ++i) {
map.put(Keys.of(i), i);
}
}
public void timeMapGet(int reps) {
for (int i = 0; i < reps; i++) {
map.get(Keys.of(i % mapSize));
}
}
}
成心思的是這個簡略的HashMap.get()外面,Java 8比Java 7要快20%。全體的機能也相當不錯:雖然HashMap裡有一百萬筆記錄,單個查詢也只花了不到10納秒,也就是年夜概我機械上的年夜概20個CPU周期。 相當使人震動!不外這其實不是我們想要丈量的目的。
假定有一個很低劣的key,他老是前往統一個值。這是最蹩腳的場景了,這類情形完整就不該該應用HashMap:
class Key implements Comparable<Key> {
//...
@Override
public int hashCode() {
return 0;
}
}
Java 7的成果是預感中的。跟著HashMap的年夜小的增加,get()辦法的開支也愈來愈年夜。因為一切的記載都在統一個桶裡的超長鏈表內,均勻查詢一筆記錄就須要遍歷一半的列表。是以從圖上可以看到,它的時光龐雜度是O(n)。
不外Java 8的表示要好很多!它是一個log的曲線,是以它的機能要好上好幾個數目級。雖然有嚴重的哈希碰撞,已經是最壞的情形了,但這個異樣的基准測試在JDK8中的時光龐雜度是O(logn)。零丁來看JDK 8的曲線的話會更清晰,這是一個對數線性散布:
為何會有這麼年夜的機能晉升,雖然這裡用的是年夜O符號(年夜O描寫的是漸近上界)?其實這個優化在JEP-180中曾經提到了。假如某個桶中的記載過 年夜的話(以後是TREEIFY_THRESHOLD = 8),HashMap會靜態的應用一個專門的treemap完成來調換失落它。如許做的成果會更好,是O(logn),而不是蹩腳的O(n)。它是若何任務 的?後面發生抵觸的那些KEY對應的記載只是簡略的追加到一個鏈表前面,這些記載只能經由過程遍歷來停止查找。然則跨越這個阈值後HashMap開端將列表升 級成一個二叉樹,應用哈希值作為樹的分支變量,假如兩個哈希值不等,但指向統一個桶的話,較年夜的誰人會拔出到右子樹裡。假如哈希值相等,HashMap希 望key值最好是完成了Comparable接口的,如許它可以依照次序來停止拔出。這對HashMap的key來講其實不是必需的,不外假如完成了固然最 好。假如沒有完成這個接口,在湧現嚴重的哈希碰撞的時刻,你就並別期望能取得機能晉升了。
這特性能晉升有甚麼用途?比喻說歹意的法式,假如它曉得我們用的是哈希算法,它能夠會發送年夜量的要求,招致發生嚴重的哈希碰撞。然後一直的拜訪這些 key就可以明顯的影響辦事器的機能,如許就構成了一次謝絕辦事進擊(DoS)。JDK 8中從O(n)到O(logn)的奔騰,可以有用地避免相似的進擊,同時也讓HashMap機能的可猜測性略微加強了一些。我願望這個晉升能終究壓服你的 老邁贊成進級到JDK 8來。
測試應用的情況是:Intel Core i7-3635QM @ 2.4 GHz,8GB內存,SSD硬盤,應用默許的JVM參數,運轉在64位的Windows 8.1體系 上。
總結
HashMap的根本完成就如下面所剖析的,最初做下總結: