Java聚集之全體構造。本站提示廣大學習愛好者:(Java聚集之全體構造)文章只能為提供參考,不一定能成為您想要的結果。以下是Java聚集之全體構造正文
1、Java中聚集
Java中聚集類是Java編程中應用最頻仍、最便利的類。聚集類作為容器類可以存儲任何類型的數據,固然也能夠聯合泛型存儲指定的類型(不外泛型僅僅在編譯期有用,運轉時是會被擦除的)。聚集類中存儲的僅僅是對象的援用,其實不存儲對象自己。聚集類的容量可以在運轉時代停止靜態擴大,而且還供給許多很便利的辦法,如求聚集的並集、交集等。
2、聚集類構造
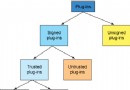
Java中的聚集包括多種數據構造,如鏈表、隊列、哈希表等。從類的繼續構造來講,可以分為兩年夜類,一類是繼續自Collection接口,這類聚集包括List、Set和Queue等聚集類。另外一類是繼續自Map接口,這重要包括了哈希表相干的聚集類。上面我們看一下這兩年夜類的繼續構造圖:
1、List、Set和Queue
圖中的綠色的虛線代表完成,綠色實線代表接口之間的繼續,藍色實線代表類之間的繼續。
(1)List:我們用的比擬多List包含ArrayList和LinkedList,這二者的差別也很顯著,從其稱號上便可以看出。ArrayList的底層的經由過程數組完成,所以其隨機拜訪的速度比擬快,然則關於須要頻仍的增刪的情形,效力就比擬低了。而關於LinkedList,底層經由過程鏈表來完成,所以增刪操作比擬輕易完成,然則關於隨機拜訪的效力比擬低。
我們先看下二者的拔出效力:
package com.paddx.test.collection;
import java.util.ArrayList;
import java.util.LinkedList;
public class ListTest {
public static void main(String[] args) {
for(int i=;i<;i++){
}
long start = System.currentTimeMillis();
LinkedList<Integer> linkedList = new LinkedList<Integer>();
for(int i=;i<;i++){
linkedList.add(,i);
}
long end = System.currentTimeMillis();
System.out.println(end - start);
ArrayList<Integer> arrayList = new ArrayList<Integer>();
for(int i=;i<;i++){
arrayList.add(,i);
}
System.out.println(System.currentTimeMillis() - end);
}
}
上面是當地履行的成果:
23
1227
可以看出,在這類情形下,LinkedList的拔出效力遠遠高於ArrayList,固然這是一種比擬極真個情形。我們再來比擬一下二者隨機拜訪的效力:
package com.paddx.test.collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.Random;
public class ListTest {
public static void main(String[] args) {
Random random = new Random();
for(int i=;i<;i++){
}
LinkedList<Integer> linkedList = new LinkedList<Integer>();
for(int i=;i<;i++){
linkedList.add(i);
}
ArrayList<Integer> arrayList = new ArrayList<Integer>();
for(int i=;i<;i++){
arrayList.add(i);
}
long start = System.currentTimeMillis();
for(int i=;i<;i++){
int j = random.nextInt(i+);
int k = linkedList.get(j);
}
long end = System.currentTimeMillis();
System.out.println(end - start);
for(int i=;i<;i++){
int j = random.nextInt(i+);
int k = arrayList.get(j);
}
System.out.println(System.currentTimeMillis() - end);
}
}
上面是我本機履行的成果:
5277
6
很顯著可以看出,ArrayList的隨機拜訪效力比LinkedList凌駕好幾個數目級。經由過程這兩段代碼,我們應當可以或許比擬清晰的曉得LinkedList和ArrayList的差別和順應的場景。至於Vector,它是ArrayList的線程平安版本,而Stack則對應棧數據構造,這二者用的比擬少,這裡就不舉例了。
(2)Queue:普通可以直接應用LinkedList完成,從上述類圖也能夠看出,LinkedList繼續自Deque,所以LinkedList具有雙端隊列的功效。PriorityQueue的特色是為每一個元素供給一個優先級,優先級高的元素會優先出隊列。
(3)Set:Set與List的重要差別是Set是不許可元素反復的,而List則可以許可元素反復的。斷定元素的反復須要依據對象的hash辦法和equals辦法來決議。這也是我們平日要為聚集中的元素類重寫hashCode辦法和equals辦法的緣由。我們照樣經由過程一個例子來看一下Set和List的差別,和hashcode辦法和equals辦法的感化:
package com.paddx.test.collection;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Set;
public class SetTest {
public static void main(String[] args) {
Person p1 = new Person("lxp",10);
Person p2 = new Person("lxp",10);
Person p3 = new Person("lxp",20);
ArrayList<Person> list = new ArrayList<Person>();
list.add(p1);
System.out.println("---------");
list.add(p2);
System.out.println("---------");
list.add(p3);
System.out.println("List size=" + list.size());
System.out.println("----朋分線-----");
Set<Person> set = new HashSet<Person>();
set.add(p1);
System.out.println("---------");
set.add(p2);
System.out.println("---------");
set.add(p3);
System.out.println("Set size="+set.size());
}
static class Person{
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
System.out.println("Call equals();name="+name);
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return name.equals(person.name);
}
@Override
public int hashCode() {
System.out.println("Call hashCode(),age="+age);
return age;
}
}
}
上述代碼的履行成果以下:
---------
---------
List size=3
----朋分線-----
Call hashCode(),age=10
---------
Call hashCode(),age=10
Call equals();name=lxp
---------
Call hashCode(),age=20
Set size=2
從成果看出,元素參加List的時刻,不履行額定的操作,而且可以反復。而參加Set之前須要先履行hashCode辦法,假如前往的值在聚集中已存在,則要持續履行equals辦法,假如equals辦法前往的成果也為真,則證實該元素曾經存在,會將新的元素籠罩老的元素,假如前往hashCode值分歧,則直接參加聚集。這裡記住一點,關於聚集中元素,hashCode值分歧的元素必定不相等,然則不相等的元素,hashCode值能夠雷同。
HashSet和LinkedHashSet的差別在於後者可以包管元素拔出聚集的元素次序與輸入次序堅持分歧。而TresSet的差別在於其排序是依照Comparator來停止排序的,默許情形下依照字符的天然次序停止升序分列。
(4)Iterable:從這個圖外面可以看到Collection類繼續自Iterable,該接口的感化是供給元素遍歷的功效,也就是說一切的聚集類(除Map相干的類)都供給元素遍歷的功效。Iterable外面包括了Iterator的迭代器,其源碼以下,年夜家假如熟習迭代器形式的話,應當很輕易懂得。
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
2、Map:
Map類型的聚集最年夜的長處在於其查找效力比擬高,幻想情形下可以完成O(1)的時光龐雜度。Map中最經常使用的是HashMap,LinkedHashMap與HashMap的差別在於前者可以或許包管拔出聚集的元素次序與輸入次序分歧。這二者與TreeMap的差別在於TreeMap是依據鍵值停止排序的,固然其底層的完成也有實質的差別,如HashMap底層是一個哈希表,而TreeMap的底層數據構造是一棵樹。我們如今看下TreeMap與LinkedHashMap的差別:
package com.paddx.test.collection;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.TreeMap;
public class MapTest {
public static void main(String[] args) {
Map<String,String> treeMap = new TreeMap<String,String>();
Map<String,String> linkedMap = new LinkedHashMap<String, String>();
treeMap.put("b",null);
treeMap.put("c",null);
treeMap.put("a",null);
for (Iterator<String> iter = treeMap.keySet().iterator();iter.hasNext();){
System.out.println("TreeMap="+iter.next());
}
System.out.println("----------朋分線---------");
linkedMap.put("b",null);
linkedMap.put("c",null);
linkedMap.put("a",null);
for (Iterator<String> iter = linkedMap.keySet().iterator();iter.hasNext();){
System.out.println("LinkedHashMap="+iter.next());
}
}
}
運轉上述代碼,履行成果以下:
TreeMap=a
TreeMap=b
TreeMap=c
----------朋分線---------
LinkedHashMap=b
LinkedHashMap=c
LinkedHashMap=a
從運轉成果可以很顯著的看出這TreeMap和LinkedHashMap的差別,前者是按字符串排序停止輸入的,爾後者是依據拔出次序停止輸入的。仔細的讀者可以發明,HashMap與TreeMap的差別,與之條件到的HashSet與TreeSet的差別是分歧的,在後續停止源碼剖析的時刻,我們可以看到HashSet和TreeSet實質上分離是經由過程HashMap和TreeMap來完成的,所以它們的差別天然也是雷同的。HashTable如今曾經很少應用了,與HashMap的重要差別是HashTable是線程平安的,不外因為其效力比擬低,所以平日應用HashMap,在多線程情況下,平日用CurrentHashMap來取代。
3、總結
本文只是從全體上引見了Java聚集框架及其繼續關系。除上述類,聚集還供給Collections和Arrays兩個對象類,另外,聚集中排序跟Comparable和Comparator慎密相干。在以後的文章中將對上述提的類在JDK中完成源碼停止具體剖析。